lua5.3 table实现
数据结构
lua 中的 table 存储分为数组部分和哈希表部分。
数组部分就是一块连续的内存,每个元素类型都是 TValue,而哈希表部分,也是采用一块连续的内存块来存储每个节点Node,节点Node包含了key和value,如图:
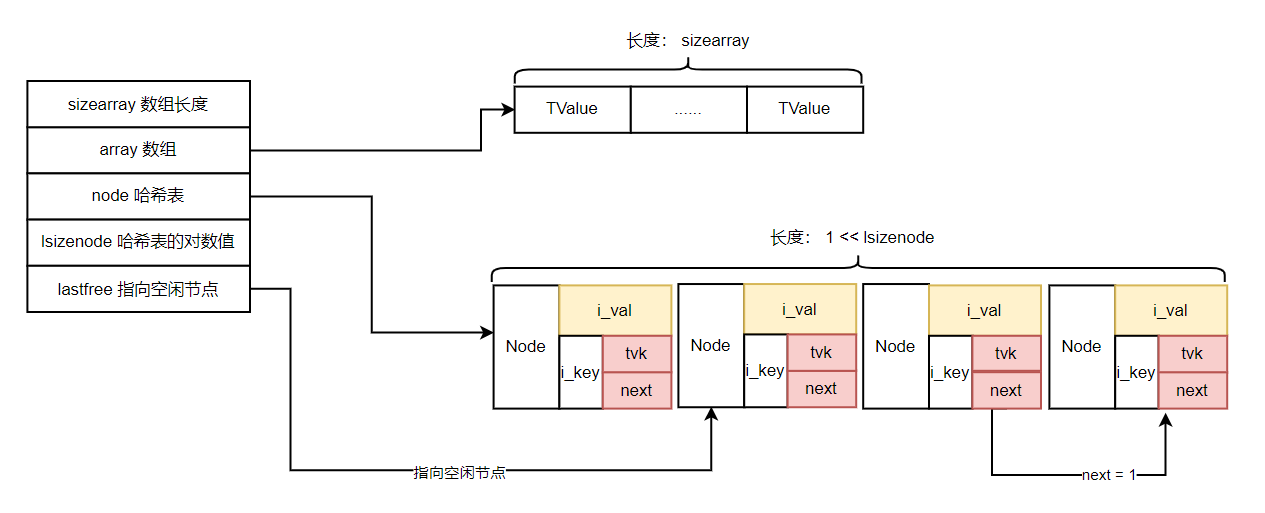
// hash 表中 node 的键数据结构
typedef union TKey {
struct {
TValuefields;
int next; /* for chaining (offset for next node) */
} nk;
TValue tvk;
} TKey;
/* copy a value into a key without messing up field 'next' */
#define setnodekey(L,key,obj) \
{ TKey *k_=(key); const TValue *io_=(obj); \
k_->nk.value_ = io_->value_; k_->nk.tt_ = io_->tt_; \
(void)L; checkliveness(L,io_); }
typedef struct Node {
TValue i_val;
TKey i_key;
} Node;
typedef struct Table {
CommonHeader; /* 公共头部 */
lu_byte flags; /* 每一个bit标志元方法是否存在。 1<<p means tagmethod(p) is not present */
lu_byte lsizenode; /* 哈希表长度是2的多少次幂。log2 of size of 'node' array */
unsigned int sizearray; /* 数组的长度。size of 'array' array */
TValue *array; /* 数组部分. array part */
Node *node; // 指向哈希表的起始位置
Node *lastfree; /* 指向哈希表的最后一个空闲位置。 any free position is before this position */
struct Table *metatable; /* 元表指针 */
GCObject *gclist; /* GC相关的链表 */
} Table;table创建
lua 层创建 table 很简单,就只需要一对花括号 {},就表示创建好一个空 table 对象。如果我们预先知道这个 table 大小,我们可以在创建 table 时,指定大小,比如,{a=1, b=false, c="hhh", 12, 5},这样在创建表的同时,预先分配了4个元素大小的槽位(hash表大小为3,数组大小为2),之后,才是对 table 进行赋值。我们可以通过 luac -l -l 来查看创建 table 对应的指令:
1 [3] NEWTABLE 0 2 3
2 [3] SETTABLE 0 -1 -2 ; "a" 1
3 [3] SETTABLE 0 -3 -4 ; "b" false
4 [3] SETTABLE 0 -5 -6 ; "c" "hhh"
5 [3] LOADK 1 -7 ; 12
6 [3] LOADK 2 -8 ; 5
7 [3] SETLIST 0 2 1 ; 1调用到 table 相关的api:luaH_new(),luaH_resize(),具体可以看 ltable.c 的实现。
这里主要想介绍 luaH_resize()一个细节,在预先分配 hash 表大小时,最终调用到 setnodevector 函数,里面设置 t->lastfree 指向 hash 表的最后一个元素位置+1 的地方,这个 t->lastfree 指针主要目的,是在插入一个新元素时,从哈希表的尾部向头部查找,是否还有空闲位置,有就插入,没有就触发扩容。但我突然想到,我们在预先分配表大小时,也已经知道要预先分配插入多少个元素了,为啥这里还是指向 最后一个元素+1的位置呢。不能跳过 size 元素位置吗,我们不是已经确定好要插入 3 个元素了吗。这是因为和 table 的设计有关,预先分配表的大小,和插入元素是分开两个步骤的,所以插入元素时,查找空闲位置,在最后一个位置查找是最合理的。
static void setnodevector (lua_State *L, Table *t, unsigned int size) {
if (size == 0) { /* no elements to hash part? */
t->node = cast(Node *, dummynode); /* use common 'dummynode' */
t->lsizenode = 0;
t->lastfree = NULL; /* signal that it is using dummy node */
}
else {
int i;
int lsize = luaO_ceillog2(size);
if (lsize > MAXHBITS || (1u << lsize) > MAXHSIZE)
luaG_runerror(L, "table overflow");
size = twoto(lsize);
t->node = luaM_newvector(L, size, Node);
for (i = 0; i < cast_int(size); i++) {
Node *n = gnode(t, i);
gnext(n) = 0;
setnilkey(n);
setempty(gval(n));
}
t->lsizenode = cast_byte(lsize);
t->lastfree = gnode(t, size); /* all positions are free */
}
}元素查找实现
对外提供查找元素的接口有:luaH_get(), luaH_getstr(), luaH_getshortstr(), luaH_getint()。
在查找元素时,我们可以根据 key 不同的类型,来选择不同的接口,加快查询效率,比如我们如果知道要查找的是一个 key 为字符串的值,且为短字符串,那么可以直接选择 luaH_getshortstr()接口,如果要查找的是数组元素,那么我们可以直接调用 luaH_getint()。
先说下 luaH_getint(key) 的实现思路:这个接口,用于查找 key 为整数对应的值,它优先去 table 的数组部分查找,对比 key 是否在数组长度范围内,如果在,直接返回对应的值。如果不在,就去哈希表中查找。lua 的数组,我们知道下标都是从1开始的,而不是从0,所以,这里传入的 key 也是当做是下标从1开始,但c语言数组下标是从0开始的,所以这里就会涉及一个转换,key 要 -1,才能去取对应的数组元素。
在哈希表中查找也比较简单,对 key 模上哈希表长度,看看落下哪个槽位中,然后对比槽位上的 key,如果不相同,那么就会查找这个槽位对应的链表下一个节点,直到找到元素或者没有下一个节点为止。
luaH_getstr(key) 因为 key 是字符串,所以只会在哈希表中查询,如果找到,就返回对应的值,没有找到就返回一个 luaO_nilobject。
hash计算槽位
数据(key-value)存储在哈希表部分时,key 的类型不止有整型,字符串,还可以是其他类型,比如指针,浮点数,bool 类型等,要计算它们分别落在哪个槽位,采用不同的方式计算。
- 整数类型,直接使用
- 浮点数,转成无符号整数
- 短字符串,直接用字符串的hash值
- 长字符串,判断是否已经计算过hash值,没有就计算一次
- bool,直接当成整数使用
- 其他类型,比如指针,函数指针,用户数据,直接使用它们对应的指针地址,转成无符号整数
通过以上的转换,得到了一个整数,或者无符号整数,然后再模哈希表长度,就知道 key 应该落在哪个槽位上了,具体可以看 mainposition() 实现细节。
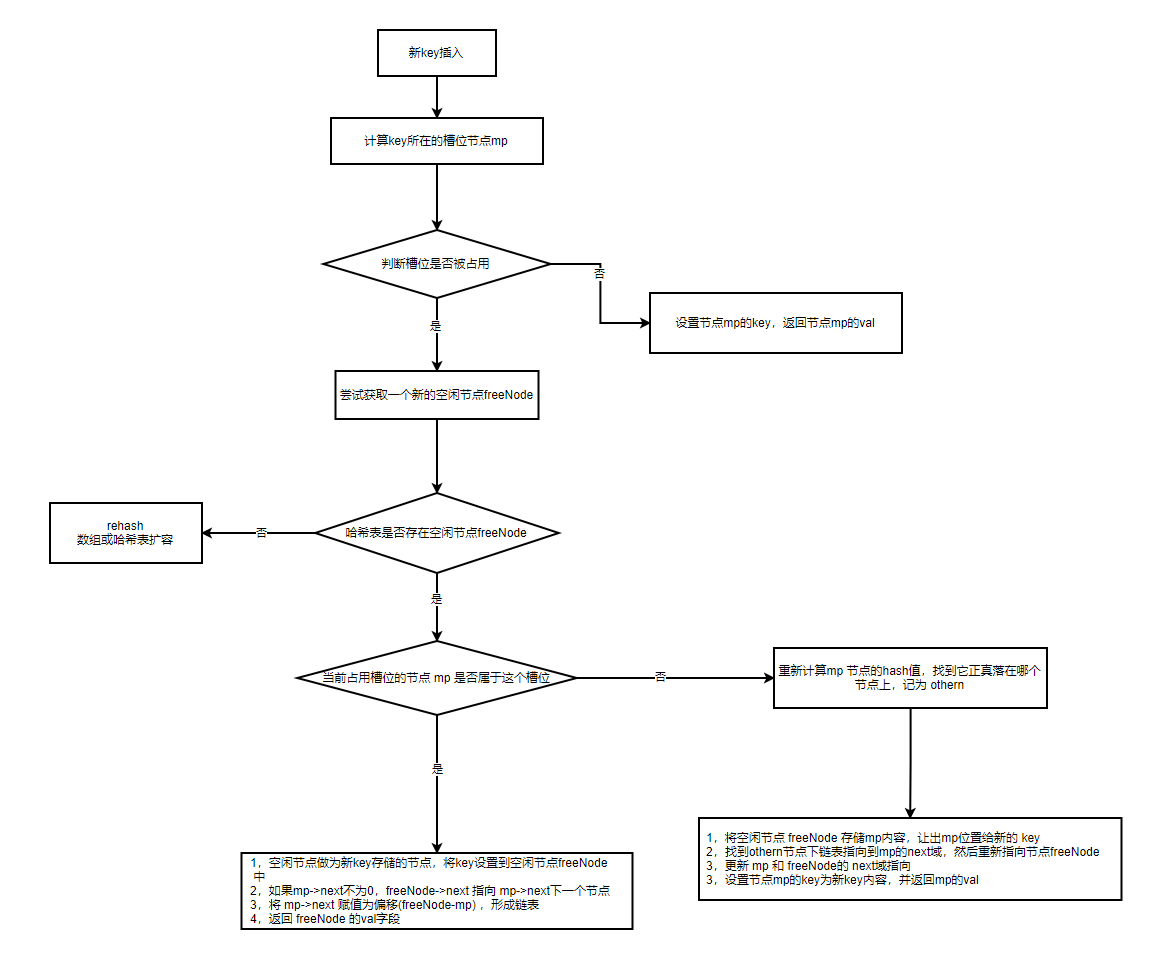
哈希表槽位冲突解决
在哈希表中获取一个新的槽位时,通过计算 key 的 hash 值,发现这个槽位被占了,那么就需要重新找一个空闲的位置来存放这个冲突的 key。
lua 采用的是线性探查法+链表法解决 key 槽位冲突问题,这个和上一次讲的 TString 哈希表缓存实现不一样。也就是说,在遇到冲突时,有2种情况要考虑:
(根据 lastfree 指针从哈希表尾部往头部遍历,找到一个空闲的节点 freeNode 后,将其做为待插入的位置。如果没有找到空闲节点,就走 rehash,重新扩容。)
- 如果当前占用这个槽位的节点 mp 计算哈希值后,也依然还是这个位置,就把冲突 key 放到空闲位置节点 freeNode 中,最后再把当前这个槽位节点 mp 的 next 字段存储 mp 和空闲节点 freeNode 的偏移量(可以简单理解为 next 指向空闲节点,采用链地址的思路)。
- 如果当前占用这个槽位的节点 mp ,本身不属于这个节点,而是通过之前 freeNode 获取到的话,那么此时需要让出来给新插入的 key,这个时候,就会把 mp 里存的 key/value 数据存到 freeNode 空闲节点中,然后新的 key 放入 mp 节点中。在改变节点存储时,我们还需要更新 mp 和 freeNode 节点的 next 域指向,具体可以看下代码实现
luaH_newkey()。
扩容实现
当我们在插入新 key 时,发现没有空闲节点时(依据是 lastfree 指针指到了哈希表的头部,它不会重新遍历一次),那么就会走 rehash。
rehash 主要流程有四步:
- 遍历数组部分,计算出了一个可以存储在数组里的键值分布位图 nums 中,按(0,2 0],(20,21],(21,22],.......(2i-1, 2i] ,来计算数组哪个位置不为空,有值,就在那个区间+1。
- 遍历哈希表部分,计算 key 为整数部分 ,value 不为 nil 的个数 ause,以及全部 value 非 nil 部分个数 totaluse,包含了整数
- 对于新插入的 key, totaluse+1, 表明要新增一个key,如果 key 是整数,那么也要把 key统计到位图中,
- 由前面3步,已经知道了整数部分元素个数,以及整数在位图中的分布情况,那么就可以通过位图计算出整数部分具体需要多大的内存空间,具体规则如下:
- 计算每个区间元素总数,如果元素总数超过区间 2i 的一半,也就是元素的利用率超过50%,那么就记录这个区间最大值 2i , 做为最后创建数组的长度大小。
- 注意,这个利用率超过50%,是指总的元素利用率,而不是连续区间的元素利用率,比如,位图区间分布:nums = {1, 1, 2, 1, 1, 15, 3},nums[0]在 (20,2 1] 中个数是1,nums[1]在(20,21] 中个数也是1,但在nums[3] 和 nums[4] 的个数为1,区间 24/2= 8,此时总的整数部分个数只有6个,小于8,说明在区间4,出现比较多的空位(我之前以为数组个数的利用率达到50%以上,是指连续区间,而不是所有区间的整数部分加起来50%。所以,我之前理解错了,它是计算总的空间利用率,这样的话,也就意味着,rehash后,数组内部还是可以有多个nil值存在),到了计算 nums[5] 时,此时区间 2^5/2=16,整数部分总数为21,远大于16,所以记录最终新的数组部分长度为16。而最后的 nums[6] 只有3个整数元素,rehash 后会被分配到哈希表中存储。
- 根据前面得到新的数组长度,以及哈希表个数,进行扩容,数组部分扩容比较简单,直接在数组后面分配足够的空间,哈希表则是重新申请一块内存,将旧的哈希表,重新 rehash 到新的内存中。
所以,一个整数是放入到数组部分,还是哈希表部分,得看整数是否在数组长度范围内,如果在,就放入数组部分,如果不在,就放到哈希表中,在放到哈希表时,还需要检查是否有空闲的槽位节点,如果没有就会触发 rehash,导致数组和哈希表里面的元素重新分配。
缩容实现
其实缩容实现和扩容实现一样,都是重新对 table 进行 rehash,那在什么情况下 table 会触发缩容呢,通过分析 luaH_newkey 函数,只有当 getfreepos(t) 为 NULL 时,才会触发 rehash,对表中的节点进行重新分配,这时,才有可能对表进行缩容。我之前一直以为在 lua gc 时,也会对表进行缩容处理,但我搜了下 lgc.c 文件,发现并没有对表进行 rehash 缩容处理,只存在对没再被引用的表进行 free,可能是因为 gc 的职责就是做释放对象的,至于表的缩容,原则上不应该由 gc 来管理。这说明,如果我们申请了一个很大的表,然后,对表里的一大半以上的元素置为 nil,这个表是不会进行缩容的,表占用的内存不会减少,但 key/value 是可 gc 对象的话,这部分会被释放掉,内存能减少,如果长时间持有这类大表,也会造成内存不能及时释放,需要注意。又如果,我们在删除完元素后,又不断添加新的元素,就有可能会触发 rehash,对表进行缩容。不过,这种频繁添加,删除元素,会导致 lua 的性能降低。因为 rehash,不管是扩容,还是缩容,开销还是有的。
遍历 Table
对外提供了一个遍历 table 所有元素的接口 luaH_next(),它的实现也很简单,就是先遍历数组部分,返回一个不为 nil 的元素以及下一个数组位置索引,下次迭代时,会根据传入的数组位置索引开始遍历,找到一个不为 nil 的值,就停止遍历,最后返回这个索引上的值,以及索引+1。
最后迭代数组索引的位置等于数组长度时,就开始遍历到哈希表部分,开始遍历哈希表时,会先去找一个值value 不为 nil 的节点,然后返回节点的 ey,和 value,下次继续迭代时,计算出 key 所在的槽位索引,如果槽位上的节点不是存放 key 的,就需要遍历槽位的 next 域,找到这个 key 正真所在的位置,然后根据这个位置找下一个 value 不为 nil 的节点,最后返回新的 key 和 value。一路迭代哈希表,直到遍历的key位置+1 超出了哈希表大小为止,就算遍历完了。
总结为,lua_next() 会根据栈顶值,来决定是遍历数组部分,还是哈希表部分。如果栈顶是nil,那么就会从数组的第一个元素开始迭代。但不管是迭代数组部分还是哈希表部分,最终都是按顺序去遍历迭代的。
当刚开始遍历时,传入的 key 是nil,返回的是元素 a1,和下一个数组索引1
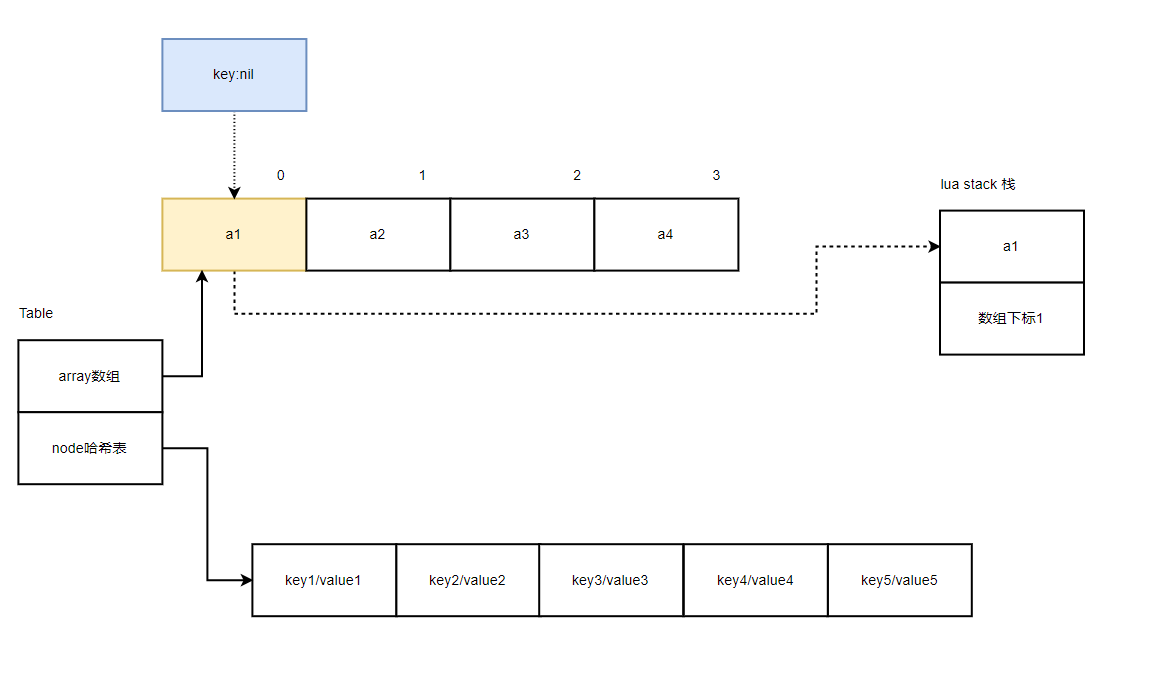
下一次迭代时,key传入的是1,访问的是数组 a2,返回的是a2,以及数组下标2
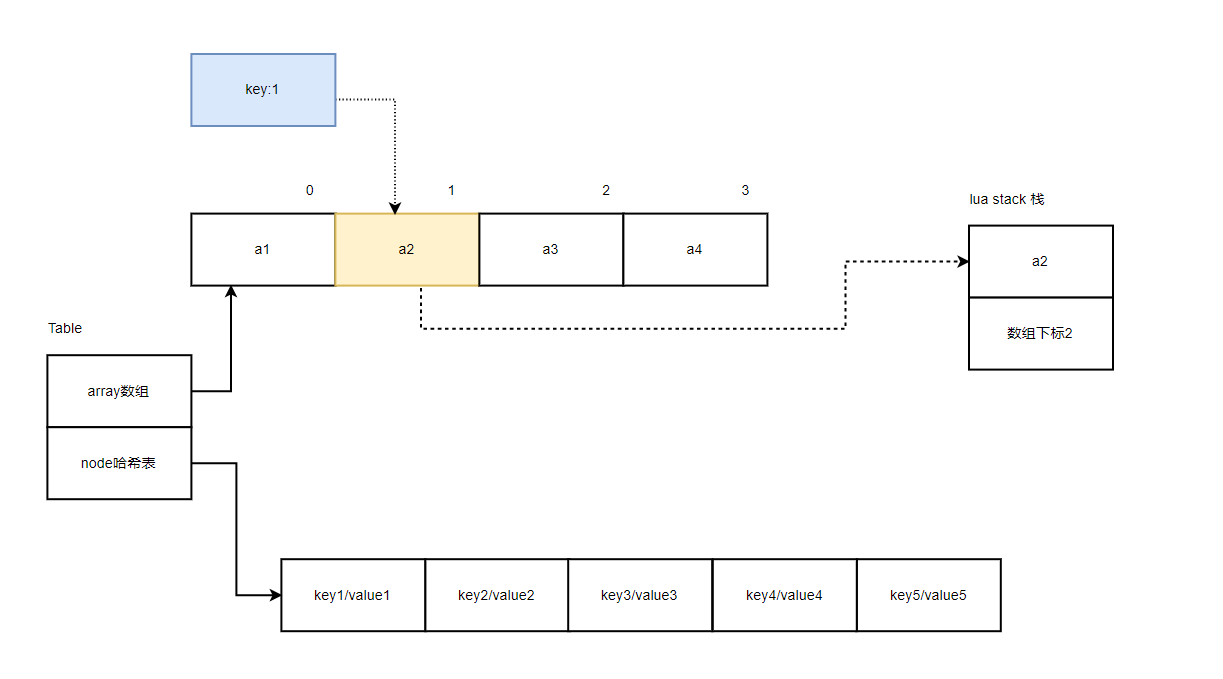
当迭代完数组最后一个元素,也就是 a4 时,lua栈得到的是数组的长度4,下次迭代时,发现4 >= 数组长度,就会遍历哈希表第一个元素
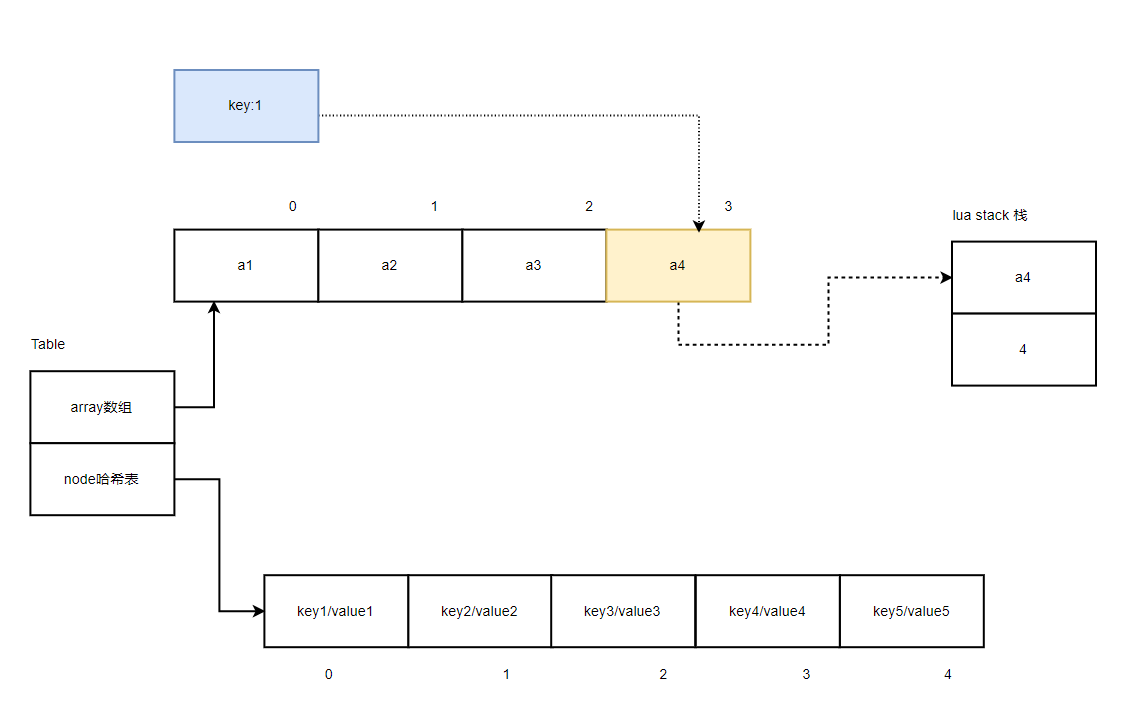
开始遍历哈希表:
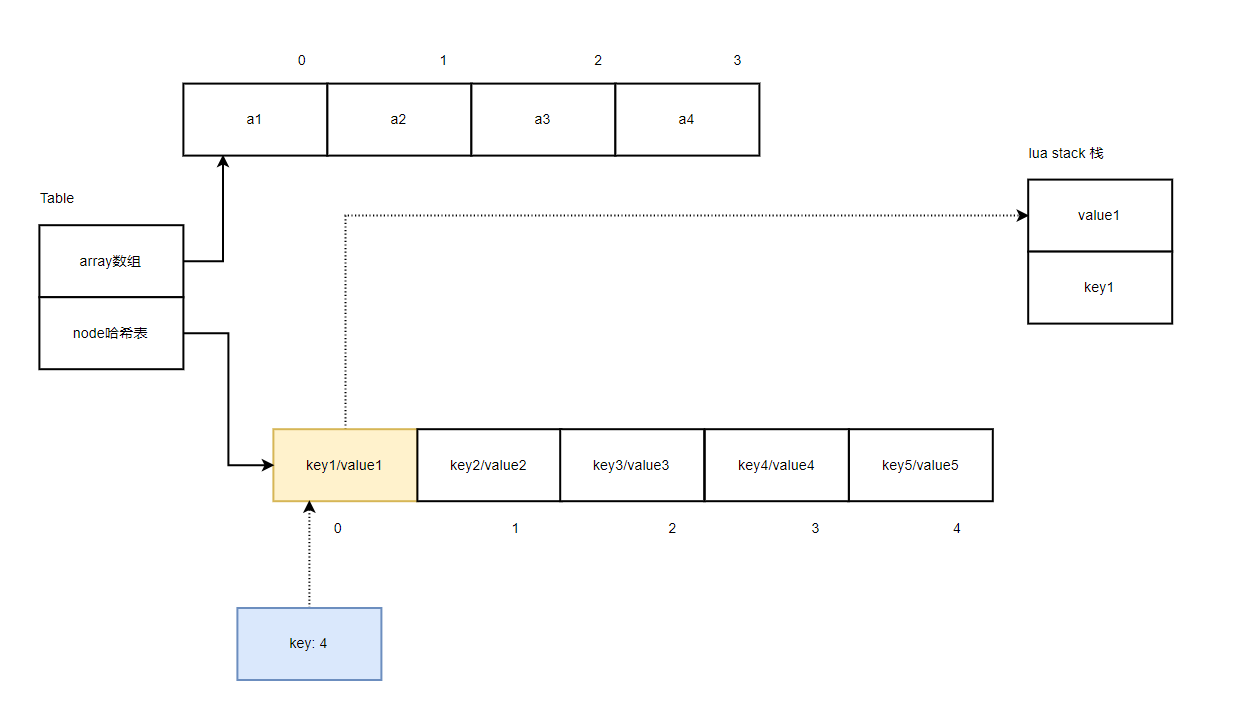
再迭代下一个哈希元素,根据 key1 的索引下标0+1,访问到 key2:

下次迭代,key 为 key2 时,因为不知道 key2 在哈希表哪个槽位下的,需要计算出 key2 的 hash 值去定位,如果计算 key2 的 hash 值不是在1号位置时,而是在3号位置(因为之前说过健冲突时,会找一个空闲的位置来存储新的健),我们不可能直接就从3号位置的下一个位置迭代吧,这样就会跳过位置2了,所以我们还是得通过下标为3的节点 next 域查找到1号位置,发现存的正好是 key2,好了,现在就可以通过key2的索引下标1,执行+1操作后,访问到 key3,如果不为 nil,就返回结果: key3/value3。后面的迭代过程就不多说了,都类似,看源码就可以了。
这里有个注意点,如果在遍历 table 时,一边添加元素,一边删除正在迭代的元素,有可能会出现报错。通过前面分析,我们知道,在插入元素时,有可能会触发 table 的扩容。而扩容前,把正在迭代的哈希 key 给删除了,那么扩容后,key 就会从 table 中移除。 给一个 table 不存在的 key 去迭代遍历哈希表部分,是会导致因找不到 key 而抛出异常。如下 luaG_runerror(L, "invalid key to 'next'"); 代码部分。
static unsigned int findindex (lua_State *L, Table *t, StkId key) {
unsigned int i;
if (ttisnil(key)) return 0; /* first iteration */
i = arrayindex(key);
if (i != 0 && i <= t->sizearray) /* is 'key' inside array part? */
return i; /* yes; that's the index */
else {
int nx;
Node *n = mainposition(t, key);
for (;;) { /* check whether 'key' is somewhere in the chain */
/* key may be dead already, but it is ok to use it in 'next' */
if (luaV_rawequalobj(gkey(n), key) ||
(ttisdeadkey(gkey(n)) && iscollectable(key) &&
deadvalue(gkey(n)) == gcvalue(key))) {
i = cast_int(n - gnode(t, 0)); /* key index in hash table */
/* hash elements are numbered after array ones */
return (i + 1) + t->sizearray;
}
nx = gnext(n);
if (nx == 0)
luaG_runerror(L, "invalid key to 'next'"); /* key not found 这里key不存在了,抛出异常 */
else n += nx;
}
}
}实验如下:
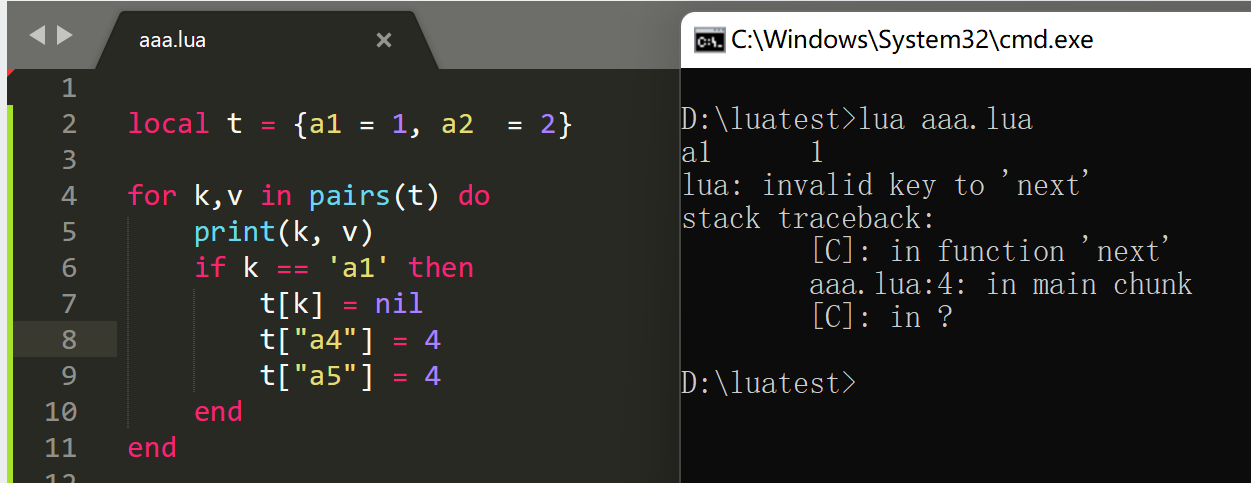
这个时候,我们就大概可以看到,在表 t 删除元素时,又添加新的元素,就有可能会触发表的扩容行为,然后导致当前正在迭代的 key 为 a1 的元素给删除了,下次传入 a1 时,表扩容完成后,就找不到 a1 这个 key 了,给一个不在哈希表的 key 去迭代,是会抛出异常的。此外,还有一种情况,也会导致这个报错。那就是在不扩容的时候,删除正在迭代的元素时,又新加了一个元素。
实验如下: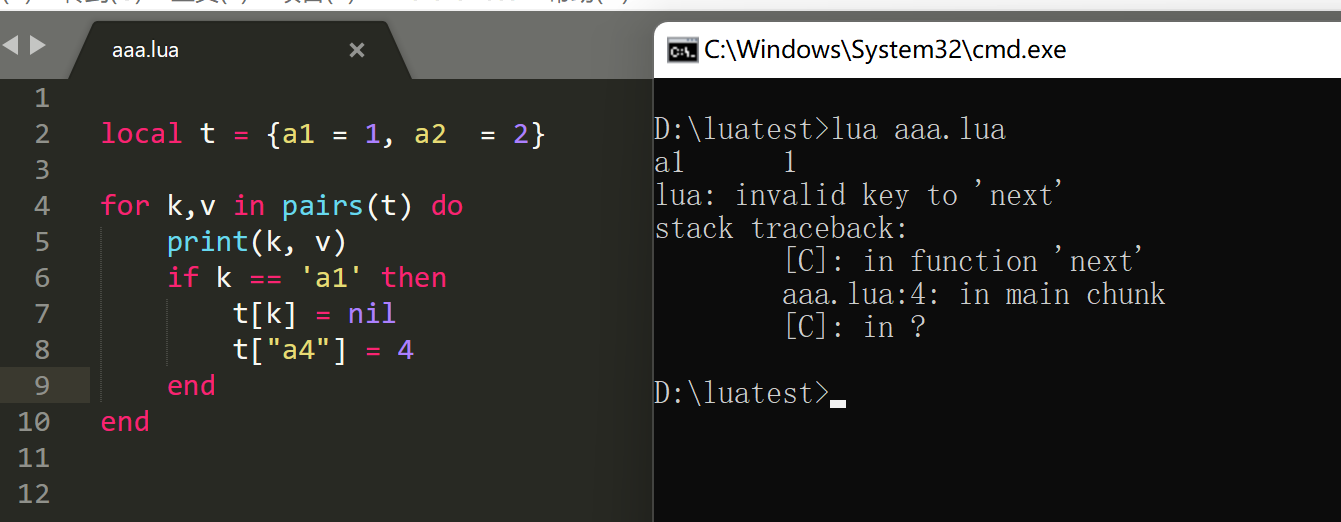
就是在迭代 key 为 a1 时,把 a1 所在的节点 val 值为 nil,再添加新的元素 (key=a4, value=4) 时,就有可能会替换掉 a1,那么迭代下一个元素时,会发现 a1 不存在了,同样会抛出 invalid key to 'next' 错误。
所以,在遍历哈希表部分时,建议不要先执行删除当前迭代到的元素,后添加新元素的操作,这样很有可能会有异常表现,特别是内网写代码没出现,到了线上一不小心就有可能出问题了。
删除table元素
那么表中的元素,置为 nil ,或者 table.remove 后,底层 table 是立马释放节点 key-value 的吗?答案是不一定,其实上层脚本,置 nil,那么底层 table 也同样是把 value 置为 nil ,只有在执行 gc 时,value 如果是可回收对象的话,会被回收,那么什么时候会删除 key ,和 gc key 呢,答案是:
- 在 rehash,重新分配哈希表时,判断如果旧的节点 value 为 nil,那么 key 就不会散落到新扩容的哈希表中,这样这个 dead key 也就不会再被访问到,同时 dead key 也会在后面被 gc 回收。
- 如果在运行过程中,这个表没有被 gc 回收,那么在新添加 key-value 时,有可能会被再访问到这个 value 已被置为 nil 的节点,那么这个节点就会被复用(在 luaH_newkey 时,复用节点)。这时,旧 key 如果是可gc对象的话,就会被gc回收。
求数组元素个数#table
获取数组元素个数接口 luaH_getn(),这个也比较简单,如果数组长度大于0,并且最后一个元素为空,说明,数组的有效长度,肯定是落在数组里边,就不用去哈希表里去计算了。在数组中采用二分查找法,找到一个边界值做为数组长度返回。如果数组长度大于0,且最后一个元素不为空,就去哈希表部分查找,同样也是采用二分查找,找到边界值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号