
lua5.3字符串实现
TString结构体
我们平时在 lua 中使用到的字符串,在底层对应的数据结构是长什么样的,抱着好奇的心态去了解下。我们先写个最简单的字符串赋值语句
local name = "zhangsan"接着看看这行代码对应的指令:
main <tc.lua:0,0> (2 instructions at 00000000006c8490)
0+ params, 2 slots, 1 upvalue, 1 local, 1 constant, 0 functions
1 [1] LOADK 0 -1 ; "zhangsan"
2 [1] RETURN 0 1
constants (1) for 00000000006c8490:
1 "zhangsan"
locals (1) for 00000000006c8490:
0 name 2 3
upvalues (1) for 00000000006c8490:
0 _ENV 1 0这里有两条指令,一条是赋值指令,另一条是 return 指令,而第5行 constants(1) 的意思是常量表里头只用到了一个常量 "zhangsan" ,从上面的输出结果,可以知道,local name = "zhangsan"其实是从常量表中取出字符串 "zhangsan", 然后赋值到 0 号寄存器(对应变量 name),至于,字符串是怎么存到常量表中的,这个涉及到了 lua 的词法解析部分 llex.c,lparser.c,有兴趣的话,可以网上搜索下,应该会有不少介绍。
// llex.c 文件
TString *luaX_newstring (LexState *ls, const char *str, size_t l) {
lua_State *L = ls->L;
TValue *o; /* entry for 'str' */
TString *ts = luaS_newlstr(L, str, l); /* create new string */
...
return ts;
}
static void read_string (LexState *ls, int del, SemInfo *seminfo) {
...
seminfo->ts = luaX_newstring(ls, luaZ_buffer(ls->buff) + 1,
luaZ_bufflen(ls->buff) - 2);
}
static int llex (LexState *ls, SemInfo *seminfo) {
luaZ_resetbuffer(ls->buff);
for (;;) {
switch (ls->current) {
...
case '"': case '\'': { /* short literal strings */
read_string(ls, ls->current, seminfo);
return TK_STRING;
}
...
}这里只做简单介绍,我们在解析一个 lua 文件时,会从文件中一个字符一个字符的读取,然后按照 lua 设定的语法,对每个字符或字符串赋予不同的含义,比如有的字符 +,-,*,/ 就被解析成四则运算。local,function,for 这些,就被解析成关键字等等。而如果解析时,发现是一个字符串常量的话,我们从read_string() 看到,调用 luaS_newlstr()创建一个 TString 的结构体对象去表示这个字符串常量,比如我们上面 lua 代码里头的 "zhangsan",接着,我们再看看,TString 是长什么样子的。
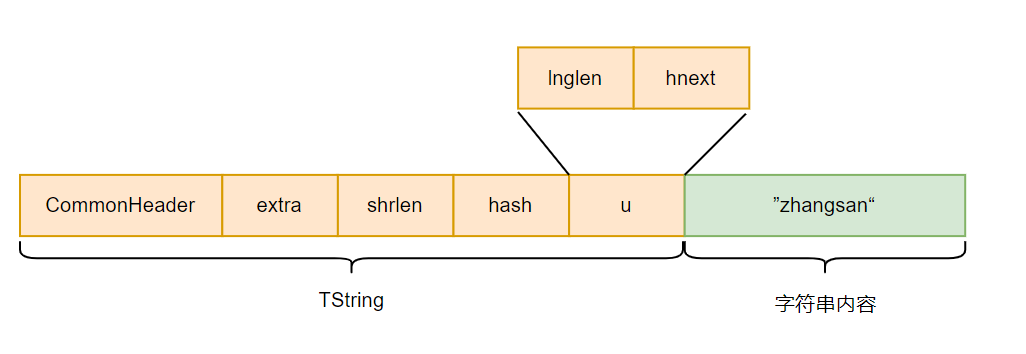
第一眼看这个结构体的时候,可能会有疑惑,字符串 "zhangsan" 存在哪,字符串的长度又存在哪。
/*
** Header for string value; string bytes follow the end of this structure
** (aligned according to 'UTString'; see next).
*/
typedef struct TString {
CommonHeader; // 需要进行GC的数据类型的通用头部结构
lu_byte extra; /* reserved words for short strings; "has hash" for longs */
lu_byte shrlen; /* length for short strings */
unsigned int hash;
union {
size_t lnglen; /* 长字符串长度 length for long strings */
struct TString *hnext; /* 指向下一个短字符串 linked list for hash table */
} u;
} TString;在这里先给出结论,字符串内容 "zhangsan" 其实是紧挨着 TString 之后存放的。TString 做为头部信息,主要用来方便获取字符串大小,gc相关,以及和其他字符串串联起来,构成字符串缓存池等作用。
lua字符串对象分为长字符串和短字符串,长度超过40的是长字符串对象,小于40个字节的是短字符串对象,短字符串对象会被缓存到全局变量G的 strt 哈希表中(数组+链表实现)。
如果当前TString 表示的是一个短字符串,长度用 shrlen 表示,因为短字符串长度不会超过40个字节,所以用一个无符号 char 表示长度足够了,hnext 字段就是在 g->strt 哈希表中使用到,用来构成链表,而 lnglen 字段则不会使用到。
如果当前TString 表示的是一个长字符串,那么 lnglen 表示长字符串长度,而 shrlen,hnext 字段不会被使用到。
获取字符串内容宏:
#define getstr(ts) \
check_exp(sizeof((ts)->extra), cast(char *, (ts)) + sizeof(UTString))从宏中看出,字符串内容紧跟着 TString 结构体后面。
字符串对外提供的创建接口
有 luaS_new(),luaS_newlstr(), luaS_createlngstrobj() 三个,前面两个接口会对字符串进行缓存,第三个接口是直接创建一个长字符串,不会对其进行缓存。
luaS_new函数实现
每次调用 luaS_new() 接口获取字符串对象时,不管是长字符串,还是短字符串,都会先去全局变量G的一个二维表中查询一下,如果查询到该字符串对象,就直接返回,如果查询不到,就会创建一份出来,返回给用户,与此同时也缓存到二维表中,加快下次访问速度。可以得出结论,这个二维表存在的目的,就是做一层缓存,加快访问字符串速度,而且只会存储最近访问的106个字符串。如图:
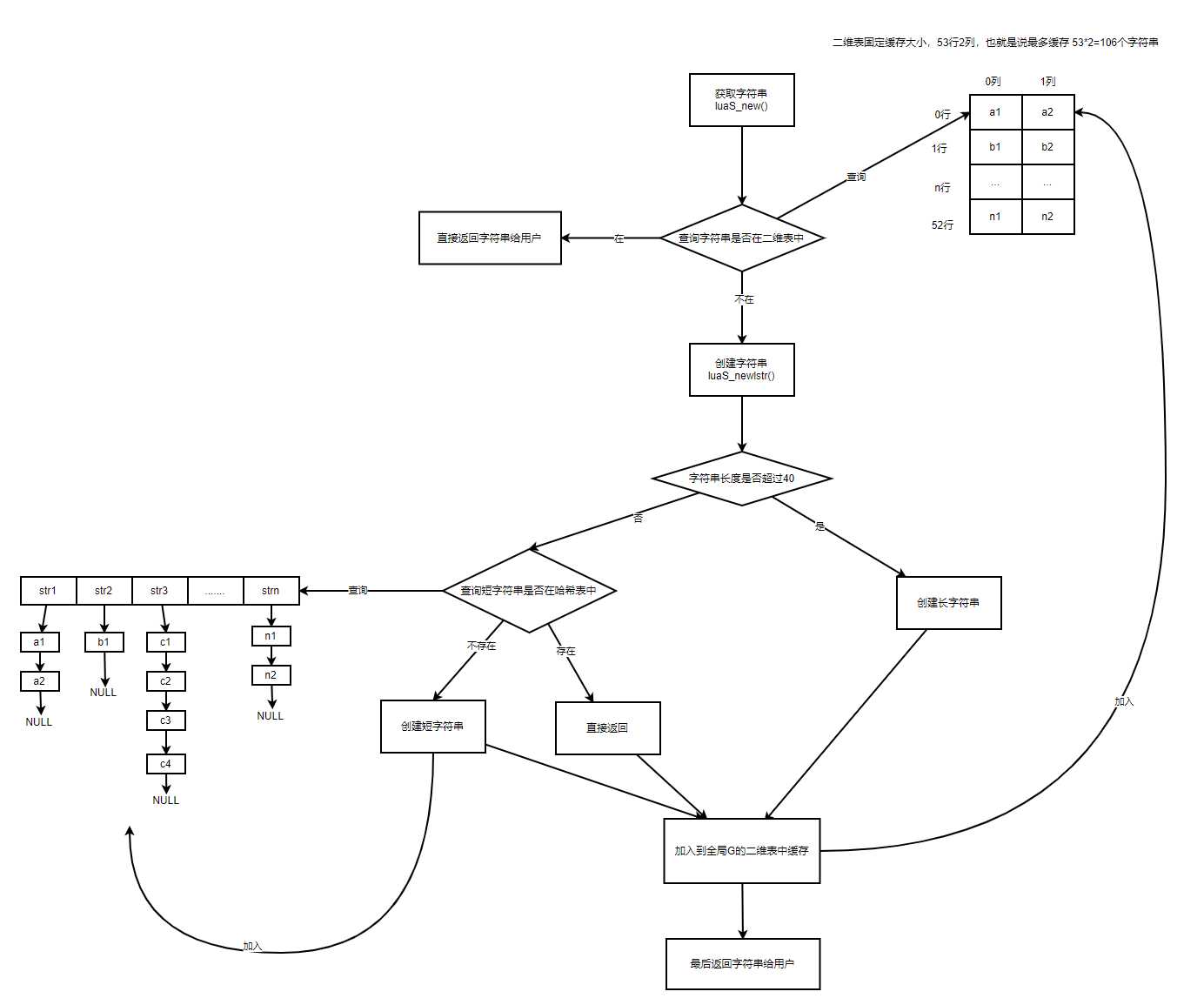
查询g->strcache[53][2]二维表过程
先根据字符串地址,对行号取模,获取对应的行号n,然后再去for循环查找对应的列,是否存在该字符串,如果存在,直接返回,如果不存在,则直接调用 luaS_newlstr() 函数创建新的字符串对象,然后把二维表的第n行第0列字符串移动到下一列,腾出的位置 [n][0] 插入新创建的字符串对象。下次再获取时,就可以直接从二维表中查找获取到字符串对象。
/*
* 创建字符串:如果在 global_state 的 strcache 中已经存在,就复用;否则就新建。
*/
TString *luaS_new (lua_State *L, const char *str) {
unsigned int i = point2uint(str) % STRCACHE_N; /* hash */
int j;
TString **p = G(L)->strcache[i];
for (j = 0; j < STRCACHE_M; j++) {
if (strcmp(str, getstr(p[j])) == 0) /* hit? */
return p[j]; /* 在 cache 中找到相同的字符串。that is it */
}
/* normal route */
for (j = STRCACHE_M - 1; j > 0; j--)
p[j] = p[j - 1]; /* 移动元素。move out last element */
/* 新元素插入到最前端。 new element is first in the list */
p[0] = luaS_newlstr(L, str, strlen(str));
return p[0];
}注意点,这里使用的是 point2uint(str) 来获取hash值,如果是两个相同的字符串计算的hash值,是不是一样的呢?答案是不一定,因为str 有可能是从堆分配的,这个时候,即使他们内容一样,但地址也是不一样的,得到的槽位索引 i 值会不一样,相当于一个字符串对象,会有两个槽位去缓存。如图: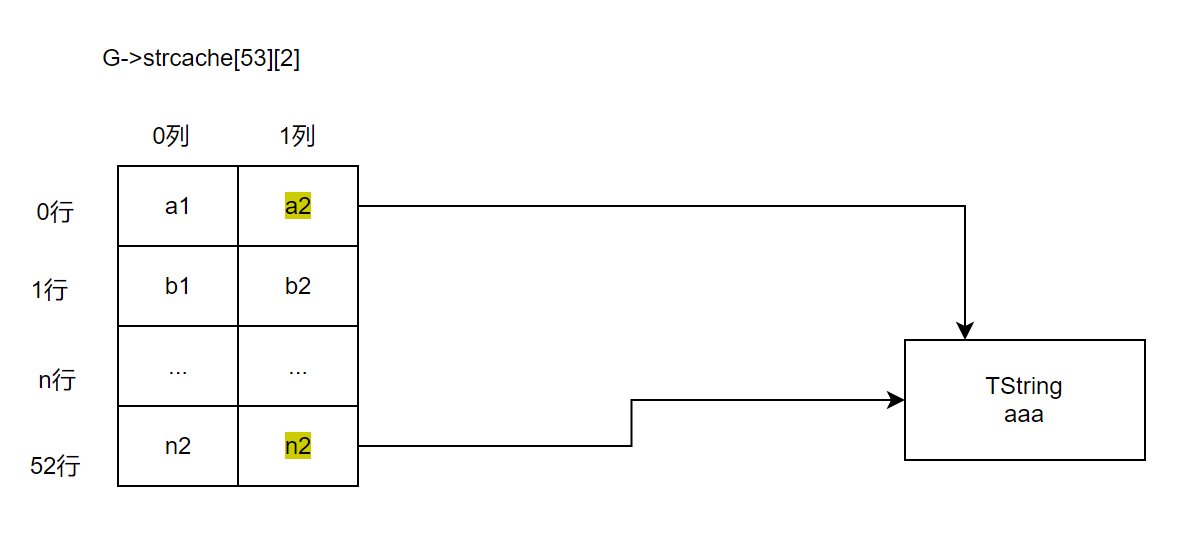
槽位a2,n2都去缓存了同一个字符串对象。所以这个 luaS_new() 接口,我们一般情况下,最好是字符串字面量那种,才去调用,这样 g->strcahe才会一个槽位对应一个字符串对象。
luaS_newlstr() 实现
通过这个接口获取字符串时,会先判断字符串是否是长字符串,还是短字符串(依据是字符串长度是否超过40)
长字符串的创建方式:先向系统中申请一块内存,大小为字符串长度+sizeof(结构体TString)。然后初始化 TString 结构体,并标记类型 tt 为长字符串后返回,不进行缓存。
短字符串创建方式:先去全局变量g的 strt 哈希表中查找是否存在,如果存在该字符串对象,直接返回,如果不存在,则从系统中申请一块内存,大小同样是字符串长度+sizeof(结构体TString)。然后初始化结构体 TString,并计算字符串的hash值,记录到 TString->hash 字段中,标记类型 tt 为短字符串。然后插入到哈希表 g->strt 中。
TString *luaS_newlstr (lua_State *L, const char *str, size_t l) {
if (l <= LUAI_MAXSHORTLEN) /* LUAI_MAXSHORTLEN 值为40 short string? */
return internshrstr(L, str, l); // 短字符串
else { // 长字符串
TString *ts;
if (l >= (MAX_SIZE - sizeof(TString))/sizeof(char))
luaM_toobig(L);
ts = luaS_createlngstrobj(L, l);
memcpy(getstr(ts), str, l * sizeof(char));
return ts;
}
}
g->strt 哈希表介绍
只要是短字符串都会在内部缓存起来,那里存储用到的数据结构就是 g->strt 哈希表(数组+链表,链地址法解决哈希槽位冲突)。查询过程也比较简单,计算出短字符串哈希值,然后模数组长度,看看在哪个槽位,然后循环遍历这个槽位下的链表,对比链表中的每个字符串,如果要创建的字符串对象在链表中存在,则直接返回,不存在,则先创建一个新的字符串结构体,然后插入到哈希表对应的槽位中。
g->strt 哈希表扩容
触发时机:
- 在查询哈希表中,不存在短字符串对象时,就会先去判断,缓存的短字符串对象个数是否超过了哈希表的长度,且哈希表长度没有超过 MAX_INT/2 大小时,就触发一次扩容,扩容大小为原先的2倍。
- 在创建初始化虚拟机时,会预先扩容,哈希表数组大小为128。
- 在gc时,会检查字符串对象个数是否小于哈希表大小的1/4,如果满足,就会对哈希表缩容,大小为原先的一半。
//internshrstr() 函数
if (g->strt.nuse >= g->strt.size && g->strt.size <= MAX_INT/2) {
luaS_resize(L, g->strt.size * 2);
...
}实现:
重置的实现也比较简单,先根据需要的大小,对数组部分进行原地扩容或者缩容。然后对数组的每一个槽位,不为NULL的链表取出来,然后把槽位置NULL,这一步很关键,因为如果不把槽位置空,对取出的字符串对象链表重新rehash,就有可能导致死循环,比如,某个槽位存的是链表a->b->c->NULL,如果不对槽位置NULL,就rehash,那么有可能a会rehash到之前的槽位,然后指向槽位的第一个元素a,这样就变成了自己指向自己,最终在槽位中形成的链表就是 c->b->a->a,那么下次查询字符串对象a时,就会出现死循环了。
如果g->strt不是原地扩容,而是创建一份新的内存来对旧的所有字符串对象来rehash,那么就不需要对旧的槽位置NULL了。当然原地扩容,这种扩容方式性能更好。
void luaS_resize (lua_State *L, int newsize) {
...
// 由于字符串所在位置是根据表长来计算的,但表长变成 newSize 时,需要将整个哈希槽位的源字符串重新排列,计算位置。
for (i = 0; i < tb->size; i++) { /* rehash */
TString *p = tb->hash[i];
tb->hash[i] = NULL; // 这个得先将槽位值NULL,才能对p链表重新rehash
while (p) { /* for each node in the list */
TString *hnext = p->u.hnext; /* save next 暂存 next 节点*/
unsigned int h = lmod(p->hash, newsize); /* new position 重新计算应该放到哪个哈希槽位中 */
p->u.hnext = tb->hash[h]; /* chain it. 节点 p 的 next 指向另一个槽位的第一个节点 */
tb->hash[h] = p; // 然后把 p节点指向另外一个槽位的开始位置
p = hnext;
}
}
...
}至于为啥要划分短字符串,和长字符串,之前看到网上有解释,5.2之前的版本是不区分长短字符串的,都会统一缓存到 g->strt 中,后面发现会出现hash dos攻击漏洞。大概意思就是有多个长字符串str1,str2 它们可以有相同长度,相同哈希值,但内容不相同,那么要获取str2时,如果运气差的话,就需要和str1对比,然后再和 str2 对比,对比两次。如果这种情况多了,出现成百上千个长度,哈希值都相同,但内容不同的长字符串,那么对比的次数会大大增加,对服务器性能造成不可想象的后果。所以后面5.3开始,长字符串,就不在进行缓存,这意味着长字符串对象,可能会同时存在多份。
有个点需要注意,在luaS_new() 接口对比字符串是否在二维数组缓存中时,是用 strcmp() API接口,因为在这个接口中,二维表缓存,是不区分长短字符串对象的,所以直接比较两个字符串的内容是否相同,而在 internshrstr() 接口中,判断字符串是否在哈希表缓存时,用的是 memcmp() 接口,因为能来到这里,说明要查找的字符串肯定是短字符串,所以也就知道缓存中字符串对象的长度,为了提高性能,先对比两者长度,再对比字符串内容是否相同。
hash字段
对于hash字段,我们知道,一个字符串对应一个hash值。而且再算多次hash值也是不会变的。而短字符串和长字符计算hash值的时机会不一样。
短字符串会在创建时计算一次,然后赋值给 hash,因为短字符串往往会做为一个表中的 key,所以预先计算 hash 值。
长字符串创建时,hash字段只是赋值为 g->seed,不会进行计算,因为长字符串计算哈希值,可能会相对短字符串消耗更多的时间,而且也不一定会做为表中的key,所以没必要预先计算,得需要的时候再计算一次,就好了,然后缓存到 hash 字段中。
extra字段
针对短字符串 ,标识当前字符串是不是 lua 的保留字。
针对长字符串 ,标识字符串是否已经计算过hash值,1计算过,0没有。
对比两个字符串是否相同
两个短字符对比,比较简单,因为短字符串只要被创建出来,都会被缓存起来,每次获取到的只有一份副本,所以,对比起来,只需要对比他们的类型是否是短字符串,然后再对比地址是否一样就可以了。
长字符串对比,因为不会被缓存,所以,只能先对比长度是否相同,相同情况下,再对比字符串内容是否相同,相同那么就证明两个长字符串是一样的。
那么怎么区分两个字符串是长字符串还是短字符串呢?我们在创建字符串对象时,会指定字符串的类型,短字符串用 LUA_TSHRSTR 表示,长字符串用 LUA_TLNGSTR 表示,所以,我们可以通过类型就知道字符串对象是长字符串还是短字符串,如果类型都不一样,那么它们就肯定就是不相同的字符串,类型相同,再通过调用 eqshrstr(), luaS_eqlngstr() 两个接口来进一步判断字符串是否相同。
小结
对于字符串的创建,提供了两个接口,luaS_new(),和 luaS_newlstr() ,对外部用户的则是 lua_pushstring(),和 lua_pushlstring(),那么什么时候用 lua_pushstring,什么时候用 lua_pushlstring呢?
可以根据是不是字符串字面量来决定,如果是字面量字符串,建议使用 lua_pushstring,如果是堆申请的字符串,则使用 lua_pushlstring。lua 的关键字,以及一些元方法的字符串字面量也基本是调用 luaS_new 来创建字符串对象的。
lua 字符串,在底层用TString结构体表示,而且调用创建接口 luaS_new 时,会先判断是否缓存是否有字符串对象,有就返回,没有就继续调用 luaS_newlstr() 接口,这个接口又会根据字符串长短来做一些划分,比如短字符,需要进行缓存,需要计算hash值,长字符串则直接从内存中申请,不缓存,hash值计算也是在需要做为表中 key 的时候,才会去计算一次。所以说,长字符串有可能同时存在多份,而短字符串只要存在一份。短字符在内部用哈希表缓存,用链地址法解决健冲突,扩容或者缩容时,就地对哈希表进行扩容缩容,而不是新创建一块内存,把旧的键值 rehash 过去。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号