db dba experience / dba skill / performance / xingneng / specification / guifan
s
- mysql 和 oracle 性能建议
下面是一个简单的表格,展示在具有 16 个核心和 32GB 内存的硬件配置下,MySQL 和 Oracle 中可能需要关注的一些配置和优化方面的建议:
| 配置/优化方面 | MySQL 参考建议 | Oracle 参考建议 |
|---|---|---|
| 内存配置 | 调整 innodb_buffer_pool_size,确保充分利用内存。 |
设置 sga_target 和 pga_aggregate_target 以适应系统内存。 |
| 并行查询 | 根据硬件核心数配置并行度,适当调整 innodb_parallel_read_threads 和 innodb_parallel_write_threads。 |
配置适当的并发度,考虑使用并行查询优化大型查询。 |
| 查询优化 | 利用索引优化查询,通过 EXPLAIN 分析查询计划。 |
定期分析查询执行计划,考虑创建索引以提高查询性能。 |
| 存储引擎配置 | 针对 InnoDB 存储引擎,调整参数如 innodb_io_capacity 和 innodb_flush_method。 |
根据硬件性能调整存储参数,考虑表空间布局和 I/O 通道的配置。 |
| 并发连接管理 | 调整 MySQL 连接池配置,确保适当的并发连接管理。 | 配置 Oracle 连接池,优化并发连接以充分利用多核心处理能力。 |
| 底层系统环境 | [root@tc ~]# echo deadline > /sys/block/sda/queue/scheduler # 临时更改调度算法参考 | [root@tc ~]# echo deadline > /sys/block/sda/queue/scheduler # 临时更改调度算法参考 |
请注意,这只是一些建议,具体的配置和优化需要根据具体的数据库负载和性能测试结果进行调整。在任何情况下,都建议在生产环境之前在测试环境中进行全面的性能测试,以确保配置的合理性和系统的稳定性。
请列出你在从事DBA生涯中,最难以 忘怀的一次误操作
http://www.itpub.net/viewthread.php?tid=911086&highlight=
http://diegoball.iteye.com/blog/495568
DBA应该具备的品质:
1、有兴趣,爱学习,爱思考
2、要有良好的心里素质,遇大事情不荒乱
3、要胆大心细
4、要有一个良好的习惯,如同过马路一 样,一停二看三通过
数据库系统最怕什么,我觉得就两点:
1。不可靠的硬件。
2。误操作。
第一点就不用解释了,第二点是该文的内容,主要是从ITPUB的精华贴——
[精 华] 请列出你在从事DBA生涯中,最难以忘怀的一次误操作 中摘录各位网友的经验和教训,常看看以警惕自己。
#2
一次一个session占用内存很大,这个session id比较大,所以以为是用户进程,kill,
则库立刻down 了,查日志后,才知道是一个后台进程,但详细是哪个进程,现在忘记了.
好的是库起来了,这个故障,我一直牢记于心.
现在做任何操作 是,都要检查正确后再敲回车.
#3
在linux平台上,一次不小心操作,把oradata下所有的东西全删除了。
至今铭刻于心
#5
一次误删了个表,最后恢复了,丢了一天数据.加了一晚上班,至今记得.
人越累的时候就越容易犯错误,我就是在最后快下班的 几分钟犯的错误.
#7
俺的
tar -cvf *.log
直接把前面几个online redo log tar进了最后一个online redo里面。。。幸好不是current的
#8
在一次测试过程中,把一个在本机执行的删除所有非系统用户的脚本,错误的粘到一个开发数据库的sqlplus窗口中。
幸好在30秒内就意识到了错误,及时中止了脚本的运行,只删除了一个无关紧要的用户
#10
我最惨,有一次把一个表一不小心给truncate了,上千万条记录一眨眼就没了;提心吊胆的陪了3天也没有把这个表搞定;最后不 了了之了
#11
1、半夜加班,系统上线和数据迁移一起,在开始前进行了冷备文件,当上线和数据迁移要完的时候,
当时不知道怎么想的可能 是半夜脑壳发昏,就在解压TAR把当前数据文件覆盖了,
辛好当时意识到了中止了解压,并且被覆盖的数据文件还没有数据。当时赶快把数据文件离 线,删除,重建,不然要被旁边的同事海揍
2、如同前面8楼,最近复制粘贴很容易搞错窗口。辛好还没出大问题,不过已经深深警惕了
#13
used to have a script written by someone else to run in default directoy,
it will delete all the dump file, logs, etc,
one day by mistake run it under $ORACLE_HOME... end up the binary was gone
luckily it was after work and dev environment, Call NOC to restore everything asap ( within 1hr)...
lesson: never run script if you donot read it carefully and know exactly what it is
#14
我的,开了两个PLSQL DEVELOPE窗口,一个生产的,一个非生产的,同名用户,同表空间名,结果非生产的建用户脚本在生产中跑了一下,
非生产是grant limit tablespace to XXX的,结果在生产中跑了以后,生产中的用户变成LIMIT了,结果程序出错,表空间不足。
导致应 用出错半个小时后才处理好。
这个太惨痛了,建议所有的使用多个环境的人,并且操作多个PLSQL DEVELOPE的人尽量只开一个窗口操作,或者是操作生产的时候,用只读的查询用户。
#15
2004年一次下午17点左右在schema A 下一个表上增加一个字段(对于在schema A范围来说这个字段增加当时是不会有问题的),
一加上去,系统load立即狂飙……
结果在schema B 下有一个包,里面有引用schema A 的这个表,没check倚赖关系以为A 和 B 之间没有联系,结果这个包编译不过去被大量进程尝试编译,
最 后只有杀掉该相关应用所有进程重新连接才恢复。
这次故障导致我们一个无故障最长时间的团队免费去海南旅游三天的机会丧失。
当时的教训 就是任何ddl的变化都需要check这个对象可能被引用的对象,
现在已经延伸到任何频繁被访问的sql了,基本频繁访问的应用要做ddl都要 深夜才能做了。
#16
越是简单的事情越是容易犯错!
误操作往往就在不经意间产生
#22
當時,那幾天都是很疲勞的。在開發環境作數據文件分佈調整時,先cp完某個表空間所有文件到其他地方,然後作*匹配rm了此表空間 在此目錄的數據文件。
但是rename時發現居然有一數據文件沒cp過來,忘了說了,此表空間是system表空間。
沒辦法,開發人 員明天還要使用這個環境。幸虧之前有一備份,不過當時磁盤空間不是很充裕,足足折騰了一夜才搞定!
想起來都後怕哦,幸虧不是正式環境了!
再 以後,就很少用cp,rm了,特別是rm *..,一般是此類操作用mv來完成。需要rm的東西,一般mv到一臨時目錄了,再rm了!
呵呵,可 能都有點謹慎過頭了哦!
#23
业务系统升级,熬了两天两夜,最后的时候不知道按错那个键了(当时脑袋一片空白),全白费了,
幸好,有做笔记的习惯,脚 本都整理好了,恢复重新做,1个多小时就搞定了:)。
#24
rm -rf /opt/ora92/* 在测试库中本来想删除数据库,结果错误的把ORACLE软件删除了.
郁闷啊,幸好不是生产库
#28
客户业务系统上线后由于存在部分性能问题,我对一个表作了dbms_stats....造成一个sql(涉及多个大表)执行计划改 变(性能特差)主机基本瘫痪了两个小时。
最后给sql加hint才解决问题!
一个sql搞死一个数据库!
#29
不小心用rm -rf /home目录下的所有文件,/home目录下放的账务系统的app。一看删除的路径的不对,已经来不及了。
#30
偶的教训不是很深刻,不过意义很重大。
删除一些trace文件,然后就直接删除rm orcl*,结果通过vpn到生产的,网络太慢,命令刚刚慢慢的显示出来,
看都没看直接按回车,结果执行的命令却是rm orcl *,
因 为orcl和星号中间有个空格,所以把这个目录下面所有的内容全部删除了。出了一身冷汗,试想,如过是删除数据文件目录下的内容,那立马死敲敲了
到现在为止,每次都要等命令完全显示出来,从头到尾看一遍再执行。
不过,大多数错误都是在很繁忙或者很疲劳的情况下发生的,呵呵,看来 dba应该多休息才是。
#39
让我最难忘记的一次
我在一个表空间上添加一个数据文件,对于DBA来说是再平常再简单的不过一件事了, 可是由于添加一个数据文件,差点当机
由于系统用得是raw device,我在添加一个数据文件时,事先没有检查这个LV是否存在,简单地看了当前的数据库中的数据文件所用的LV序号,
就以简单序号+1 的方式添加了,结果也算是不走运,正好没有这个LV,ORACLE或者说UNIX操作系统当作了一个一般的文件来创建了.
由于是创建在 /dev/vgxx 中,所以这时搞得UNIX的根目录没有了空间,这个数据文件刚创建完成,其他用户就无法登录了,无法创建新的连接了.
因为 根目录没有空间了 .
更不幸的是已经断开了这个操作系统连接.新的连接又无法创建.急呀
不过不幸中万幸是一个同事正好有一个连接还在上面,所以马上过去直接su - . 接下来的事大家都知道了, 所以搞得现在一提起要加数据文件,就怕得要死
#40
你这个错误的确恐怖,哈哈,我也要记住别犯,我一哥们前一阵也是把根给弄满了,
当时我俩一起去做系统检查,他从一个卷复 制文件到另一个卷,结过巧错了,弄到根卷了,
幸亏我也正连在上面,巧了我正改几个系统参数,一改发现改不了,提示没空间了,当时我的冷汗就下来 了,
因为还在生产时间,根卷一满,os随时会 hang,数据库也玩玩了,脑子里急速回忆我是不是又干了什么白痴的事,想想今天很清醒啊,不可能阿,
赶紧检查,发现根里多了个目录,问他,果 然是他弄来的,赶紧删了,没影响到系统,如果当时我不在或者没有在改那个参数,又是个事故,
埃,现在总结得出,任何生产库上的大操作,能等到晚 上做最好晚上做,做的时候最好一个人干,一个人看,
两个人都确认了再回车,这样出问题的几率就小点……
至于我的误操作么,多了,从一开始的 update算法写错,把几千万的帐户蒸发掉(幸亏有备份,没有真的蒸发),到cd一个目录,敲错了没进去就开始rm,
或者做批量操作时候连的 数据库多了,连这个数据库去做的时候没连对,跑到另外一个数据库执行了……,不敢回忆阿,
还好,我所有的都有备份,没有造成经济损失,不然我早 就不用干这一行了,失败,现在年纪大了,才谨慎些了
#41
有一次ssh了n次
连接到了一个省平台,当时还以为在测试机上,执行了shutdown immediate
等了几秒钟没反应,马上意识到搞错了。
立即取消。
还好发现的早,没把数据库搞Down
以后制定了一系列规范防止这些低级错误
#44
在线移动数据文件,dd时把其他的覆盖了另外一个数据文件啊.
结果可想而知.从带库中花了几个小时才把这一个datafile恢复回来.还好有备份啊.
#45
记的最深的一次,业务判断逻辑出错导致sq写错l 后果就可想而知,数据出错,那都是钱来的
经过半个晚上的数据修复,终 于搞好
现在写这些sql时很小心,很仔细,还让同事帮忙检查
#53
做exp导出时,导到了user.dbf文件,还是生产库,结果生产服务器宕了3天才恢复好..
#63
导入数据出错
将配置好用户配置要导入到生产库中,结果由于生产库中两个用户名太像,结果导到正在用的那个用户下,一堆存储过程失效,导致业务中断……
#66
tar cvf 后面两个参数写反了,结果前面的数据文件没了。
#72
我最蠢的一次是,刚刚接触oracle,还不知道备份恢复的概念,数据库运行在非归档,冷备时少了一个文件(别的同事做的备份),
过了几天恢复数据库,用当时的冷备恢复,结果数据库起不来,丢失的文件还包括很多重要应用字典数据,没办法,
重新输如这些字典数据, 花了三天三夜。
还有几个月前,做测试,连到了生产库,把几个表空间删除了,出了一身冷汗!幸好是晚上,没有什么应用,及时恢复了数据库。
#74
偶遇到的严重事故:其实也不是人为造成的。9i的库,由于需要move tbs来降低HWM,
然后再做alter index rebuild online,脚本连续跑了1个过月了,都没事情。某天突然发生问题,
alertlog中无报错,应用访问数据库 效率奇低,查了n多原因,未见异常,但是已经造成业务中断3小时。
得到客户同意后,做完数据库全备,中午12点重启数据库解决该问题。 -_-!!
事后发现其实在凌晨2点的时候有一个trc文件生成,看里面一堆的天书代码,发现类似一个object id,
去查 object id,object果然是被重建索引,估计是rebuild online的时候失败,
到白天业务高峰期间smon还在清理临时 段,因此业务堵塞。
另外一个省也是类似的事情,也是做rebuild online,但是估计中途失败了,再次做rebuild online的时候报错ora-8106的错误,
按照oerr的指示,进行rename SYS_JOURNAL_nnnnn 表,数据库一下子猛报ora-600的错误,且切出来大量的udump文件,害怕了,
重新rename回,600错误不再报,但是估计smon 又开始忙活……8点开始业务高峰来了……再次堵塞……一个字:“等”!-_-!!
到11点,smon清理完毕,恢复正常。
教训:(1)做rebuild online的时候一定要谨慎!!特别是大表的索引!(2)不要全信oerr的提示-_-!!
#86
刚开始接触Linux tar -vzvf
tar -xzvf 后面的搞错了 ,备份全没了
马上重 新备份 ,汗啊!
#89
最惨的一次是和公司的一个傻哥们一起出差,那个哥们不知道出于什么考虑,将主服务器和备份服务器的IP反
了一下,但是tnsnames没做修改,我准备重做备服的时候,使用了drop user cascade,把所有的用户都干了一
遍,刚刚干完,所有科室上夜班的护士小妹妹都给我打电话,说科室里的电脑全部不能用了,当时急的不行了,
还好习惯还不错,来的前一天做了一个全库冷备,立刻进行了恢复,不过也丢失了一整天的数据.
一个小时以后,所有的院领导以及信息科的工作 人员都出现在我的面前,并质问我原因,我只能一脸无奈的
告诉他们刚刚来了只熊猫,那只熊猫烧了把香,然后数据就全丢了。然后给了他们一个卖瑞星的兄弟的电话,
那个兄弟连夜驱车200公里赶到目的地,到场以后首先确实了一下那个烧香的熊猫的存在,然后指出了那只熊
猫的巨大危害性,最后建议他们购买一套全院级的杀毒软件。大院长听取汇报后当即指示,立刻购买一套全
院级的杀毒软件,第二天一早就在购买合同上签字盖章.
这个事情造成四个后果,
第一,我在所有删除性操作以前都要核实一下对象的 准确性,
第二,我从此拒绝和那个傻哥们一起出差,
第三,那个卖杀毒软件的兄弟会经常联系我,看看我有没有犯类似的错误。
第 四,兄弟越多越好
#92
原来接手一个部门的所有数据库,结果漏了一个,也没人告诉我,所以我不知道这个数据库存在。
一天一个程序人员误按了一个 按钮,把大量的数据全部删除,找到我后,发现数据库没有归档,也没有任何备份。
结果是程序人员补了几天的数据,我的奖金也直接泡汤
#93
和数据库无关,去客户那里做升级,白天交易时间(证券),由于不熟悉客户机房里设备的摆放,以为屏幕下的键盘就是这台主机的,
直 接ctrl+alt+del启动(无盘站)结果这个键盘控制的是另外机架的主机,是乾隆转码机器,吓了一身冷汗,尽快重启。
教训:去客户那里一 定先熟悉环境,最好和客户一起做。
#94
有一次大厦停电,通知半夜12点停电,我就懒得去动数据库了,没有备份,结果第二天早上,磁盘阵列启动不了了。
丢了周五 一天的数据。我才发现:不能想当然的认为什么都不用做,这个错误让我更加记住了大家常说的:备份重于一切。呵呵……
#97
在cx700的存储navisphere管理界面,配置一个存储;同事接过去打开了生产环境另外一个存储的ie窗口;
我 又接手过来,一恍惚看这个存储的配置与我打开的一样,就开始做删除STORAGE GROUP的操作;
还好我旁边另外一个同事看主机名不对,制 止了我继续删除(我当时对他讲解了一下配置存储的步骤然后开始操作);
删除了lun就丢生产环境的crm数据了;
这个事情很可怕,那 天人状态不怎么好; 以后做事情越是知道状态不好,越要加倍谨慎;
还有么,以前删除文件用相对路径来删除, ../path 方式,误删除了测试环境的oracle程序;(以后都用绝对路径了)
以前的错误都没有这次存储的错误可怕;
#103
RAW磁盤的連接文件, 整理的時候, 下RM命令加*, 把正在運行的一個實例的REDO LOG FLIE的連接文件刪除了.
當時就感覺出錯誤了. 那個實例當時還沒有DOWN. 還來切換REDO LOG時候找不到文件就DOWN了.
幸 好RAC其他實例正常運行, 用戶和其他部門都沒有感覺到.
還來把那個連接文件重新建立, 又可以啟動了. 自此下RM命令很小心.
#108
我到是没有,不过以前俺们公司,有一个程序员写好的脚本,一个实施人员去执行,
脚本里面带了
delete * from xxx;
commit;
啥备份,归档都没有.
结果我们公司全部人员出动,
抱着笔记本,台式机,
去北京某区县所有的机关单位上门录了一星期人员信息.
至今记忆犹 新.
#110
呵呵,哥们列举一次绝对毁灭性的操作:
重建表空间后文件系统里有些数据文件没有用了
我打算清理空间本来语句 已经是这样写:
rm -rf ts_tab_test*
由于网络有延迟,导致了手欠,多敲了一个空格
写成了rm -rf ts_tab_test *
结果这个目录下所有的数据文件都被我删除了
绝对崩溃
#113
做DBA真有些不容易
有些时侯感觉是在练心里
一次领导问我好dba有啥条件,俺回答:
1、有兴趣,爱学习,爱思考
2、要有良好的心里素质,遇大事情不荒乱
3、要 胆大心细
4、要有一个良好的习惯,如同过马路一样,一停二看三通过。
有过一次,我们的应用管理员为提高自已统计拥金语句的查询速度
自己自做主张在一张表上又建了一个索引
没过几分钟,tuxedo 的队列就开始阻塞,前台营帐某一应用物别的慢
问一下应用管理员最近有什么变动,他回答说:没有
问题报到我这里,简单查一下,相应的应 用几乎都在一条语句停留时间较长
看一下该语句的执行计划,发现走的索引不对
同时查了一下ddl trigger的log,发现应用管理员在几分钟前在这个表上建了一索引
drop掉新加的索引问题解决
应用管理员无语,领导发表了一 通评论.
#114
俺有个同事也蛮搞笑的,一次在一个目录下发现有个*开头的文件,就写了个rm -rf *.后缀
结果可想而知了吧
#120
我有一次本来要删除测试库的,结果差点删除生产库的一个表的所有数据,还好强行ctrl_alt_delete,最后回滚了,哈 哈,居然一条数据都没有删除。
确实是快下班,比较累。
以后不能在心急的时候维护数据库。
#131
安装数据库的时候
su -
chmod 777 -R /oracle
多输入一个空格
chmod 777 -R / oracle
许 多系统文件属性变坏
Unix瘫痪
这个错误犯了两次
#134
看错数据库 truncate了几个关键业务表,当时电话不停的在耳边响,幸好没乱了方寸。
如果做不完全恢复代价太 大,最后从log表中恢复了数据,没影响到生产,不过也出了一身冷汗,
从此做任何操作都很小心。
#136
我的一次,双机,os升级,先在备机上 update,patch什么的都打完后,在terminal里爽爽的敲reboot的时候发现把主机给起了。
冒冷汗的同时想起那个 terminal是 telnet到主机上的...结果库还起不来,冷静地检查了一把,发现主机正跑着alter trablespace begin backup....,
赶紧把中断的备份都给end backup了,弄得现在一要重起都习惯性的先打hostname。
#137
我也说一下,刚进现在的公司不久,做一个数据仓库项目,同事周日加了一天班把数据抽到一个大表空间里,大概100G,第二天因为 临时表空间增长很快,
决定重建,这个临时表空间的开头和那个大表空间名字是一样的,只是后面加了一个_temp,
当时也是因为事情比 较多,认为这是很简单的,结果输入名字就忘了输入_temp,把大表空间删除了,
同事白加了一个星期天,虽然没影响什么进度(数据可以重抽), 但这次教训是深刻的.
个人教训:
1.rm的时候一定不要用*之类的,要用的话要看好再用,否则会有意想不到的效果.
2.人在类的时候最容易出错误, 所以每一次回车都要看好.
#142
打patch,2个点开了4个窗口,两个用于操作,两个用于监控。
由于几天连续升级了很多点,这是最后的两个点了,胜 利在望,大家思想也都松懈下来,我一边升级一边和旁边两个同事侃大山,
正侃着最近的美国大片呢,手工make的脚本一下子粘在了那个刚打完的那 个点上,然后enter回车...........,于是又一次体验了指尖发麻、大脑空白
的感觉,后来一直在想吸毒是不是也是这种感觉啊
#151
(05年的事)刚换新东家的时候,入职第一天,服务部那听说开发部来了一个搞DB的,之后就马上过来找帮忙,说客户那边的查询很 慢,需要解决方法。
偶就做了一个优化脚本dbms_stats,加 index,很dw的做法。后来发现查询快了,但是整个业务流程慢了,又被投诉,原来还是业务+查询混合使用的系统。
后来把index删除了,然后想了其它方法。
总结:在动DB之前一定要知道这DB的具体用途,在给DB加东西的时候,一定要多了解!!!
很多人把DBA当作神,但自己不可忘记自己不 是神,一定要切合实际,要深入到真实环境中!!!
而大伙说的查询系统是整个业务系统里的一个子系统,提供查询的,偶以为是DSS之类的查询系统。
被经验误导,从此之后到任何DB的东西都 问得清清楚楚。不动不熟悉的系统~
#152
删除日志时,输入rm * .log,因为星号*与log之间有空格,所以删除了该目录下所有的文件,吓得我出了一身汗
#153
使用EXP/IMP进行迁移时,没有看好里面得表,导致导入数据库中得数据全乱了
#156
测试库导入数据,不小心把正式库给drop了
#157
刚工作一年的时候,开发给了一段脚本就是给账户表某个字段修改长度(alter table account_t modify...),
我当时太累了,发了的脚本也没有说明何时操作,我就直接在生产库上执行了。
可想而知,大部分存储过程都失效, 全省业务暂停2小时,嘿嘿。。。领导以后就给了我称号“破坏王”。
#159
truncate一张很大的表。。。
估计是人品好,CANCEL了一把,居然数据一点都没少。。。
#160
为了给员工做培训,我把正式库的数据导入到测试库上,但是不知道谁修改我机器上的盘点系统的配置文件,
结果显示的是测 试库,实际上是正式库,IMP过程中其实已经表现异常了,但没意识到,
幸好,这个DMP的时间点只差2个小时,当时的中间的操作也没多少.
#161
另外一次说不上失误,但是影响很麻烦.
06年旧服务器上的数据库老是莫名其妙损坏,基本上1周2次,刚好有次恢复后,以为备份没有用了,就把备份,包括日
志文件也删除了,结果第3天又坏了, 并且为了保证别的部门运行,我们把备份推后了,结果中间缺了一段,那次,安排
把数据补录进去,整整花了好几天晚上.
#163
主机和笔记本的oracle服务名一样,连接错误,通过业务程序把数据库给初始化了,那个惨
#169
想的还很周到
常出问题的有几种:
1、操作时 主环境与测试环境没仔细看,疏忽了
2、用crt等终端软件连入主机操作时,不新开窗口,
由一台主机去telnet另外一台主机,有时提示符并没有主机名
一些人常常看看crt的标题而忽视了在哪台机器上
从而命令在不该执行的机器上执行了。
提示:每次telnet都用新的窗口,养成良好的习惯
3、拷贝、粘贴语句很容易产生误操作。
有时dba自己也不知剪贴板是不是自己要执行的语句
很多的情况下还会出现你执行完copy操作后拷不出来语句的情况
比如从一个pdf文件拷一个你要执行的语句
没拷出来,而剪贴板中可能存在的是rm、truncate、drop这样的语句
如果语句再带上个;号及回车就更惨了。
提示:这样操作时记着把ultraedit或notepad打开,确认一下剪贴板中的内容
4、酒后操作、疲劳驾驶
提示:脑子真反应不过来时就别撑着了,歇一会,冲杯咖啡都不错。
其它提示:
1、做危险操作时最好拉上一个人,多一双眼睛会少很多危险。
2、如操作复杂且可能会影响到生产系统,最好把你的操作 方案在测试环境测一下
3、最好不要白天做drop,truncate等危险操作,晚上即使做错也有补救时间
4、任何时侯做好备份对 DBA都是非常非常重要的,特别的时侯真是救命的稻草。
5、我在生产系统要做drop表,除非十分确认是无用的表。不然都会先做rename操 作,过一段时间再做drop操作。
#175
说一个刚做DBA的时候的事儿,大家别笑啊,
一边在本机上做实验的时候一边监控生产库,机器钟开了N个黑窗 口,。。。,累了,
本机上改完配置后需要重启库,shutdown immediate,2分钟没有反应,
脑袋“嗡”的一下,知道发 生什么事情了,马上重新连接一个session,shutdown abort ;
然后通知应用人员,数据库发生误操作,需要马上重启应 用,,,OK,数据库起来,应用起来,新数据进来,,,
前后总共宕机时间13分钟,不过在线数据没有丢失,因为应用端有写CACHE机制。
结 果还好,没有被追究责任,算作一次维护操作。
经验:以后每次敲完命令,按回车之前,停一秒钟
#177
mv、rm、shutdown、commit、truncate、drop、del、等操作之前,深呼吸,然后问问自己,你做的 没错吧。
没错就回车吧。
#183
我就是犯了類似的錯誤,把system01.dbf給壞了一部分!盡管馬上按ctrl+c,
還好是EBS剛准備上線的 那一次,幸好有前一天的冷備!
那次知道了,為什麼DBA一定要有經驗的!
做DBA不光是只要技朮的,心態和性格很重要!
#185
没有作任何备份,把系统格了....
丢失公司门户网站近半年的各类数据
#187
我最难忘的: root 用户 在根目录下 rm -rf abc *,abc 和*之间有个空格,结果把os删除了。
已 经成为佳话。
什么事情都可能发生的。
好像就是05年的今天搞的。
从此,整个人好像变了一样,做什么事情,都三思而后行了。
#188
也是开了多个窗口,一个窗口建库,另一个窗口是生产的库。搞错了,在生产的服务器上直接shutdown了,立刻电话就上来了。
好在没有造成太大影响,也是提心吊胆的。多窗口危险很大!!!
#189
在公司生产系统目前还没有误操作,估计有一回就该换人了
有的一次是在上海IBM 实验中心做RAC性能的测试(环境都是我们自己搭的)
当时我在用DD测试一个LV读写速度的时候,没很在意具体 LV对应的情况
做完以后意识到这个LV已经被数据库使用了
回头ALERT看
晕
居然是SYSTEM用的LV
那 次时间以后导致测试进度延迟一天
还好没有太麻烦IBM的兄弟
要不NND不好交待了啊
回到生产以后
日常维护不用有写权限的用户登陆
有类似要求操作
多拉个兄弟一起看着
#192
记忆深刻的一次是
grep rman- backup.log >> backup.log。
初学shell的时候,想把backup.log中的rman-类型的错误,都放到backup.log最下面。
这个脚本,一般情况下, 也没有问题。
但是,文件中数据一多,问题来了,因为并不是先全部过滤后写文件的,是一边过滤一边写,追加的信息马上就再追加,文件一下就把 /home目录给占满了。
最近的一次,很寒
瞒自信的把一个机器的电源拔了,结果拔错了。。。。
错误犯了很多,不一一说了。
#198
check一张表被哪些对象使用,用什么方法呢。有什么SQL可以查看的?呵呵,谢谢了
记得有一次Create index也造成类似的问题。所以许多操作都要放在晚上才行。
--------------------------------------------------------------------------------
可以用這個︰
/* Formatted on 2007/12/05 11:41 (Formatter Plus v4.8.7) */
SELECT SELECT object_id
FROM public_dependency
CONNECT BY PRIOR object_id = referenced_object_id
START WITH referenced_object_id =
(SELECT object_id
FROM SYS.dba_objects
WHERE owner = '%'
AND object_name = '%'
AND object_type = '%')
ddl完了記得對 有依賴關係的pl/sql對象recompile。
俺最慘的一次是上了10几個小時夜班後正準備下班,點進VM執行init 0,
卻忘記有從這個VM窗口 telnet到生產環境cp參數文件而且等數據庫狀態監控報警後才反應過來...
還好是RAC,但也造成不小影響,從此下任何指令前先 CHECK過。
另外個人總結在unix下盡量用tab得到文件名和路徑名有助于避免空格錯誤。
#207
一个省级数据库,那时候我才没学oracle多久,然后就我一个人在机房。
那是一台windows的服务器,我不知怎 么想的,就在服务器上用 windows优化大师清理了一下注册表。
因为是晚上,我清完以后重启了一下服务器,然后那个oracle的监听服务 就启不起来了,
当时就吓的我一身汗,后来发现我用rman target / 是可以连接到数据库的,才知道问题不大。
最后发现原 来是优化大师把注册表中listen的服务的一些键值给删除了,后来手工加上就又好了。
从这次问题以后我就对windows优化大师再也不感兴 趣了。
#208
一次TUXEDO服务出现严重堵塞,前台叫得又急。一看是数据库的TX锁堵塞,我查找堵塞别人的SESSION,然后找出它们的 PID,在操作系统上直接 KILL了,
结果有一个是数据库核心进程(这个进程产生了TS类型的enqueue,而不是TX的enqueue, 当时没有仔细看)。
数据库马上DOWN 了,吓出一身冷汗,马上重启数据库,重启服务,业务中断10分钟。
以后再怎么急,也要确认一下要KILL的SESSION是否是用户进程。
#210
9i的 rac ,7x24 业务
删除一个分区表的分区时,没有加update global indexes,导致索引失效,
甲方要求用delete,组织按部分delete时,有个表千万的记录,和另外一个小表名字很像,结果大表删除 时没有加条件限制,很久没有结束,然后终止,
这时一个instance crash,不久另外一个crash。当时查了一下好像service guard有问题,非常想自己启动一下,还是没有做,让客户找小机工程师来看。
小机工程师也没有看出什么问题,重启后好了。
业务停止了2个多小时。
是做dba以来最惊心动魄的一夜。
教训就是:
充分准备,测试。
另外,看前面兄弟说的事情,很多是手误或者大脑不清醒。dba干活经常是深更半夜,而且有时是连续作战,到后面脑子肯定不好使了。
所以我 基本上有这么个习惯,在干活前先把步骤理一遍,具体到每一个命令。
如果有测试环境,先在测试环境做一下。
然后就照着这个step做,最好是复制粘贴。操作时,关闭其他所有shell窗口,将操作窗口的日志保存;
这样操作过程都可以记录,如果 在操作过程中发生意外,意外都是不可知的,有大有小,有时比计划做的事情还麻烦。
这样意外昨晚后,不至于漏掉要做的步骤,比如如果并行建索引, 完了要改为非并行。总体操作是受控的。
事情完成了,写报告也比较方便。
非常赞同使用iso9000的管理方法:
记下要做的,
按所写的做,
写下所做的。
#215
在LINUX下输入了FSCK直接回车敲了几下,导致LINUX系统挂掉,数据库也一样的挂了
#216
05年 一次做了一夜火车后直接到公司就遇到故障,重起数据库报错,数据文件找不到了,晕乎乎的就写了一个脚本准备offline 然后恢复,
但是文件 名字是从文档中copy出来的,结果copy串行了,幸好offline 这一步就发现了,出了一身汗,手都发抖了。
而且后来发现数据文件找不 到是因为双机切换的时候一个卷没有同步过来
07 年 DG维护, switch over , ip 也switch了但是忘了修改 listener.ora 结果原来的primary 上操作lsnr 的时候把新的primary 的lsnr停掉了。
别人的错误,truncate 表,drop 表,错误dbms_stats
总结错误:
小心!细心!
养成好习惯 ! sqlplus 里面使用 prompt 提示是那个数据库,避免操作错误, rm 前先ls pwd 看看,
执行重大操作比如shutdown ,drop ,truncate 等操作都先hostname ,select instance_name from v$instance之类的检查
制定规范!!! 流程,权限,以及 ddl trigger 等,操作尽可能作测试后再 放到product
希望大家都说说好的避免错误的措施,避免睡不好觉
#225
靠,我前2天想对一个操作 ,进行跟踪,但是找不到他的sid,后来弄了个system级别的跟踪,因为应用是tuxedo,长连接.
第二天客户udump小的日志 20G,搞的数据库hang住了。哎,这个真的要小心。
#234
当时刚毕业,还是再做程序员,因为程序升级,导致数据库表和seq也有些变化,用insert into() select * from A这样的语法按时间导入到新的表中,
因为对between and的理解模糊,导致少了一天的记录,是某部机关的日志信息,我是一个月一个月导的,所以每个月的最后一天信息都没有导入,
我自信满满的把原 表 truncate掉了,后来项目经理细心,发现少记录了,把我很K了一次......
#235
一不小心把UPS的关了,导致主机停电,幸好数据库可以正常启起来
#244
有一次半夜被call到机房,头有些晕沉,想找一台windows telnet上db去检查检查,因为用了屏幕切换器,一个ctrl+alt+del组合键下去,
一台db服务器被我reboot了(linux 下没有屏弊掉ctrl+alt+del三键重启),吓出一身冷汗来,幸亏是一个小型dw应用,晚上不会用得到。
此后,凡是在linux下跑的oracle,装好os后我一律最先将/etc/inittab里的ca::ctrlaltdel:/sbin /shutdown -t3 -r now这一行给屏弊掉。
#255
一次在AIX下给客户rename datafile,文件太多,弄到windows下用excel编辑,然后做个脚本去rename,结果有两个数据文件名字相同,
大小写不一 样,在 execel里为了文件名清晰,用了个UPPER函数,rename以后,mv 脚本就把其中一个覆盖掉了,还好有备份,回复了5个小时。
之 后再也不敢用excel做这些脚本了。
#258
一次做数据库的重建工作,按用户导出了所有的数据。
数据量挺大的,忙了很久。突然,脑袋发昏了,本来一个导入操作,鼠 标粘贴出来了一个导出。结果一个大的dmp文件变成了0k。
还好,有一个全库的导出在另外一个目录。 教训就是:以后所有重要的导出数据,全部必须是400。
#264
RAC环境,dd裸设备的时候,本来只打算清空data diskgroup的,结果不小心清空了所有raw disk,ocr和vt当场挂掉了,
不过是测试环境,哈哈,要是prod我可以直接卷铺盖走人
#266
尤记得那年我还很冲动,测试环境中发现表空间不够了,就加了一个文件。一会有人打电话说生产库总报一个提示。
马上去 看,发现我的数据文件竟然加在生产库上!而且路径类似windows的,非常奇怪,冷汗!
靠,原来写错tns串了,见鬼的是测试环境和生产环境 网络竟然是互通的!
生产环境是rac,裸设备,9i……后来只好把这个本地文件脱机,数据倒没有丢失,但总有个删不掉的脱机文件!
好 在用户还很傻,不知道发生了什么,后来找个理由升级成10g了,
我心里的石头才算放下了。
从此以后我从来没有犯错。
#273
开了多个窗口,把生产库里面最重要的表truncate了,本来想truncate测试库的。
这下子,惨了。。。
还没备份。。。
一个礼拜都不好意思。
#274
一次在ibm p570上安装rac,由于客户网络有问题,结果失败,在
删除rac时rm -inittab*.crsd等几个rac的启动文件,一不留神吧AIX的一个文件删了,结果系统起不来了。
后来多亏ibm的工程师恢复了系 统。结果晚上3点才收工。
#275
第一件:想truncate测试库的数据,结果成正式库了。
第二件:晚上迷糊糊的把DG的主库写成READONLY 了。最后第二天业务系统登录不进去了都(幸好是测试阶段)
第三件:想把某一普通用户下的表全部删除,结果登录的是SYSTEM。。。后果可想而 知。。。。。
#283
最近一次是需要新建一个用户测试环境,当时没看清要求,结果数据导入的是另外一个环境的数据,
而中间件又是其他一个环 境的中间件,其中数据结构基本一样,数据也是一些不一样。
然后用户开始测,测试了20天,过后发现有些功能不对啊,然后查出来是中间件数据库不 一致,然而数据库是我导入的数据,就是这里导错了。
也不能重新建立环境了,用户已经测试了20天了,当时郁闷得要死,被老大还算客气的教育了一 下,最后保留数据库,换了中间件,
还有一次 我登陆了生产用户没退出来,然后自己做测试,写PL/SQL,还贴到生产上面去执行了,
过 后发现是生产环境,马上检查脚本,还好只是一些输出的脚本,没有DML,后来想起来,真的很怕。
我还删除过UAT环境的中间件,就是rm -rf,现在我喜欢用rm -ir...........,或者很小心。。
教训就是一定要小心,要清醒,看3遍在做。。。用完生产环境就马上退 出来。。
#284
在我接触oracle的第一个月整垮了一个数据库
当时对备份和恢复没有任何概念
一个新系统中午上线的,然后 下午6点开发人员的存储过程有问题,误更新了一张表,需要帮他们恢复数据。
数据库是处在归档模式,当时不知道闪回表为何物,更是不知道Rman 位何物.只记得当时慌慌张张的去网上查资料,也没搞出个所以然来!
我忽然想起3点半我做了一个备份,心想能恢复到3点半也不错啊!
shutdown 数据库,呵呵当时居然还知道shutdown还原!覆盖备份的数据文件!
startup数据库,报600错误,当时不知道600为何物,还有一 大串的[][][][][]和数字。
心想应该是覆盖有问题吧!又重新覆盖了一遍,这次是连安装目录一起覆盖,妈的,居然还是ora-600,
一 些表居然可以查询出来,想exp出来,一导出就报错,数据库就关闭了!就这样启动关闭往往复复!搞到凌晨一点也没搞定。丢了6个小时的数据。
最 终数据库都起不来了!第二天重建!
第二天开发人员去仓库手动恢复数据,一条条的补,搞了两三天吧!
过了N天才明白当时的备份是错误的,我是在数据库启动的情况下复制数据文件的,不知道这算是冷备还是热备!反正是不能恢复的备!
又过了N 天又明白了用闪回是能多么轻易的恢复数据!懊悔啊!
现在我明白了,没把握,就别动他,先确定,再行动。
#286
一个db2数据库,前台程序挺烂,经常需要我delete from table where 操作。
那天早上一到, 还没进入工作状态,接了个电话需要删除些记录,晕了头了后面忘记加where条件了,
一个关键表数据没了,紧接着电话一个接一个的打来。还好生 产库-查询库是做了数据复制的,几分钟后把数据同步回来了。
如果再晚上几分钟查询库同步一次数据也没了。后来想想还是很担心,再后来没有出过大 错误了。
#288
入行一年多的时候,有次扩测试环境数据库程序和数据所在卷空间的时候没经验,按了ctrl+c,卷丢失,重建卷,安装程序,恢复 数据,
12个小时,那天也是13号,从下午2点搞到凌晨2点
写下你职业生涯中最难以忘怀的误操作。。
http://www.dangkai.com/ArticlePage/Article59549.htm
http://bbs.chinaunix.net/thread-2076933-1-1.html
Seker
一次删除用户时,去 /home/$USER 看了下,没任何用户自建文件
于是 userdel -rf USERNAME
回车后,没见出现 shell#
脑子瞬间空白~~手去按CTRL+C
已经晚了,,,
cat /etc/passwd 用户的HOME被改过。。。
还好有备份。。但也损失了部分数据。。。
从此,再也不敢用 userdel -rf
loesprite
我写了个脚本批量修改十几台服务器的eth0:1,结果在mv命令忘记加-i的参数,结果破坏了oracle集群,关键服务停止近3个小时……
批注:脚本一定要多测试
skylove
ghost用得太多。。。有次在备份资料的时候,想偷懒用ghost搞定(win平台,非热备份)。。。结果。。。结果。。。两块硬盘太象了。。。
批注:这种傻事我也干过,幸好是自己的PC
kiever
新到公司不久,本来打算将IDC一台闲置的服务器扛回去,就按照标签上的IP地址找到后发现服务器无法登陆,问了其他人也没有密码,就直接拔了电源。
结果不到5分钟,接到上头电话,关键服务器无法访问。
最后才搞明白,服务器上的IP标签贴错了,我停了不该停的服务器。那个郁闷啊!!!
批注:所以,配置资料的整理很重要
lasama
在搭建一个邮件系统的测试环境时,由于邮件系统的管理系统的URL使用的是绝对路径而非相对路径(托管多个域),然后我在测试环上想登陆后台管理一下,结果直接登陆到在线系统上去了,点点鼠标,几百个用户就被我delete掉了..........直到偶然抬头一看IE的地址栏,即时血液倒流............
niao5929
在SYBASE数据库中使用DELETE命令,跟错了条件,删除了很多有用记录,好在上传的记录被及时导回,要不然就惨了
C.J
编了两天两夜的 linux (第一次lfs), 做了个tar后, 删除原来的文件,发现tar解开出错。。。
批注:对于做lfs这样的事,打击是太大了
donalxm
就前几天,rm -rf *,按ctrl+C的时候已经迟了,敲入任何命令都返回 Command notfound.幸亏之前备份了一些资料,/etc/fstab自动mount另一块硬盘(win2000,备份的服务器)的资料只是只读,要不然要多吐一升血
xcrossbow
从年前使用dd时覆盖掉mbr中认识了sysrescue中的gpart救星!
呵呵!
07年底,想把一个img写到优盘时,用了如下糟糕的命令
dd if=./xxx.img of=/dev/sda
由于一直记得我的Thinkpad T43是并口硬盘,因该识别为hda,自以为第一个优盘是sda了,打完后重启才意识到问题!
幸亏了解并用过sysrecue盘,参考以前看的linux server hack2中的使用gpart恢复分区一节,找到了数据分区,救出了数据,好悬!
一点经验:
1 、 dd 命令 带of=xxx时,一定要神智清楚,工作情绪最好时用批注:这个真的很重要
2、sysrescue救援盘和oreilly 的linux server hack I & II建议您备一份,真的可以救命的欧!
vermouth
似乎大多数都是平时权限过大的问题,要养成不到万不得已不用root的习惯!
highmag
1. ghost disk to disk for clone windows 2000 server, but src anddst...
2. path at /, run rm *lib -rf
simbalwd
SCOUnix系统上,为了增加一个文件系统,结果用divvy把有用分区上的文件系统给一个一个删除掉,最后还自信满满的install,结果不一会儿就满屏的字符,系统自动关机了。导致生产系统停止服务三天,还好不是关键应用。找了以前的备份,花了整整一个礼拜的时间才把丢掉的数据给补回来,那段时间看到我们做业务的,头都抬8起来。
itxiaofei
删除某变量路径下的目录,结果此变量为空
rm -rf $abc 实际就变成了 rm -rf /
从这以后,rm要带r都必须先确认目录,变量都必须判断一次
批注:我的一个脚本也干过同样的傻事
sanyork
前年夏天管一个小的机房,机房里面有四个机架二十多台服务器,安装了两个空调,一个1.5匹的和一个5匹的,白天上班机房有中央空调,为了省电,白天只开1.5匹的,下班的时候忘记了开那个5匹的空调,结果1.5匹的那个空调由于负荷太大罢×工了,后来机房里所有的服务器全部死机了,打开机房,里面温度有六十多度,不过那些IBM的服务器硬件质量还不错,所有的机器都发出报警声,没有造成硬件损坏,重新启动后就好了。
批注:遇到过同样的事,拿着纸箱扇风给交换机降温
ShadowStar
本来服务器使用bond连接到的switch,手欠改为bridge了。
改完就往机房跑,半路上接到电话,服务器区全部断网了。
批注:真的是手欠
yuanchuang
误操作到是有,但还没到难以忘怀的地步。
那时,一个版本刚编码完,进行单元测试,大家都需要测试,都挺忙,那时也不知脑子中在搞啥,在一台Solaris上执行rm -rf/,我还奇怪为啥还有确认?这事没给我留下太深的印象,所以细节都忘了。
verysnap
本来只是想编译个程序的……
$make love
donot know how to make love,stop.
批注:这个是来逗乐的
Dalamar
经常在十几台机器之间来回切换,有次rm -rf ./* 清个文件夹,结果执行完发现rm到其他机器上去了....
从此以后执行重要命令之前先ifconfig看下ip
批注:在错误的目标机器上执行命令的傻事也干过,幸好没什么后果
pnshe
有次在虚拟机做测试,错把测试数据库当成虚拟机init 0,同事马上报服务器宕,服务器在IDC机房,我哭啊。
Dalamar
还有次,刚用Oracle不久. 开发服务器磁盘满了,然后同事去查全部.log文件.
找到三个redo1/2/3.log文件,问我能不能删.
我也没注意,说删吧删吧. 结果就把数据库搞挂了....
tech_linux
工作第一年,删除数据库表内数据. where条件后是ID=, 结果删到最后一个时走神, 没写id=,直接写了个数.三秒钟,七百多万条数据被我删了. 当时全脑空白,后听同事说我脸色惨白!! 恢复一夜,还是丢失部分数据,关键服务,核心数据库.
批注:某次在MySQL下delete数据,回滚刚才输入的命令修改where条件,诸如name=aaaand id=1,本来计划用退格删除1换个其他的,网络突然出现问题,手欠,多按了好几下退格,还按了回车,网络正常了一看,正好把andid=1退掉,数据删了一堆,幸好有备份!
xxyyy
一次工程实施,一个超市开业,经过一个多月的数据初始化,好不容易把所有商品都弄好了,离开门只有5分钟了,超市门口庆典已经开始了,聚集了很多顾客等着开门呢,我突然接到他们超市的人说有一个商品的价格弄错了,要我手工修改数据库改过来,我就照做了,但是我写的update语句忘了写where条件了,执行后我发现执行的很慢,十几万条数据啊,所有的商品的价格都已一样的了,此时我足足愣了2分钟,一言不发,一身冷汗。我赶紧打电话给他们经理说能否晚开门5分钟我恢复备份数据库,他们不答应晚开门,但可以限制10分钟后才让收银台收款,我才终于将心放到肚子里了。
8年过去了,现在想起来都有些怕,万一没有数据库备份,我如何负责?我如何能负责得起啊!!!!!
haterw
scp libc-2.6.so xxx@yyy:/tmp
mv /tmp/libc-2.6.so /lib
ln -sf libc-2.6.so libc.so.6
批注:这是教人搞破坏
freett
基本浏览一下上面所有的
得出一教训
备份 备份 再备份!!!
能不用root 尽量不用root
批注:完全同意!
bigbomb
linux+mysql的虚拟主机
mysql的用户表中执行了
delete from user;
忘记加where条件,结果把所有用户信息删掉,还好搞IT的人都很宽容,尽管电话打爆,可没有一人投诉,至此以后得出一个教训--“做什么都要小心,改什么都要做备份“
zhangxiangod
修复一个硬盘 本来是fsck.ext2 /dev/hdb1 心不在赝 打成了mkfs.ext2 /dev/hdb1结果就不用说了
flashkkk
我最无辜的一次:
rm *.txt ----却变成了rm * .txt 。就多了一个空格阿!!!
cai_bird
1、电信原始话单数据,rm *.tmp,写成了rm * tmp,靠,这么rm的这么慢,ls一看,几十G数据没了。
2、sybase数据库,单步提交,update一用户资料表没带where,回车后脑子一片空白,敲了几个rollback,旁边看着的老大说,rollback没用的,准备通宵吧。
批注:肯定用的是UNIX,Linux root用户的rm是rm-i的alias,当然,象我这样的猪头用rm从来是rm -rf的,恶劣的习惯!
s
问题1:db mysql / mysql cluster 5.7.19 / performance , 数据库底层若表碎片化严重,导致表索引走向偏差,致使该表读写速度变慢,影响业务运行
解决1:数据库表重组
-
-- mysql 性能监控工具 MySQL Enterprise Monitor:Oracle提供的商业MySQL性能监控工具。 Percona Monitoring and Management:由Percona提供的开源MySQL性能监控工具,包括智能监控、诊断和管理工具。 VividCortex:一种基于云的MySQL性能监控工具,提供实时监控、查询分析和报告生成等功能。 Mytop:一个基于命令行的实时MySQL监视器,用于查看服务器进程活动、查询统计等。 MySQLTuner:一个基于Perl的MySQL性能调优脚本,可帮助检查服务器配置并提供优化建议。 Pt-visual-explain:一个基于Perl的MySQL查询计划分析工具,可帮助优化查询性能。 pt-mysql-summary:一个基于Perl的MySQL概要统计工具,用于查看MySQL服务器健康状况、配置信息和性能指标。 Nagios:一种基于开源的网络监控工具,可用于实时监测MySQL服务器的健康状况和性能指标。 Zabbix:一种基于开源的网络监控工具,可用于实时监测MySQL服务器的健康状况和性能指标。 Cacti:一种基于开源的网络监控工具,可用于收集MySQL服务器性能数据并生成有用的报告。 Prometheus:一种开源的监控系统,提供了强大的时序数据库和查询语言,可用于收集并分析MySQL服务器的性能数据。 Grafana:一种开源的数据可视化工具,可用于通过图表和仪表盘展示MySQL服务器的性能指标。 MySQL Performance Schema:MySQL自带的一种性能监控工具,可用于跟踪MySQL服务器运行时的各种性能指标和操作。 MySQL profiling:MySQL自带的一种性能剖析工具,可用于分析和优化MySQL查询语句的性能。 Query Analytics:阿里云RDS提供的一种MySQL性能监控工具,提供实时监控、诊断和管理功能,可监控云上MySQL实例的性能。 pt-query-digest:一个基于Perl的MySQL查询日志分析工具,可用于分析查询日志,发现慢查询和性能问题。 mtop:一个基于命令行的MySQL进程监控工具,可用于查看活动的MySQL连接、查询、线程等信息。 MySQL tuner script:一个基于Perl的MySQL性能调优脚本,可帮助检查服务器配置并提供优化建议。 mydumper:一个开源的MySQL数据备份工具,可用于备份MySQL数据库并生成可读的备份文件。 MySQL Workbench:MySQL官方提供的一种数据库设计和管理工具,可用于可视化和管理MySQL数据库的性能和健康状态。 Nagios Core:一个基于开源的网络监控工具,可用于实时监测MySQL服务器的健康状况和性能指标。 Zabbix:一种基于开源的网络监控工具,可用于实时监测MySQL服务器的健康状况和性能指标。 Cacti:一种基于开源的网络监控工具,可用于收集MySQL服务器性能数据并生成有用的报告。 DPA:SolarWinds提供的商业数据库性能监控工具,可实时监测MySQL数据库性能。 Monyog:由Webyog提供的一种MySQL性能监控工具,提供实时监控、诊断和管理工具等功能。 OpenNMS:一种基于开源的网络监控工具,可用于实时监测MySQL服务器的健康状况和性能指标。 Sysbench:一种基于命令行的性能基准测试工具,可用于测试MySQL服务器的性能。 DBATools:一个基于PowerShell的数据库管理和自动化工具包,可用于监控和管理MySQL服务器。 pt-stalk:一个基于Perl的MySQL问题或奔溃跟踪工具,可用于分析并解决MySQL问题或奔溃问题。 MySQL Slow Query Log Analyzer:一个基于Web的MySQL慢查询日志分析工具,可用于分析并了解MySQL慢查询性能问题。
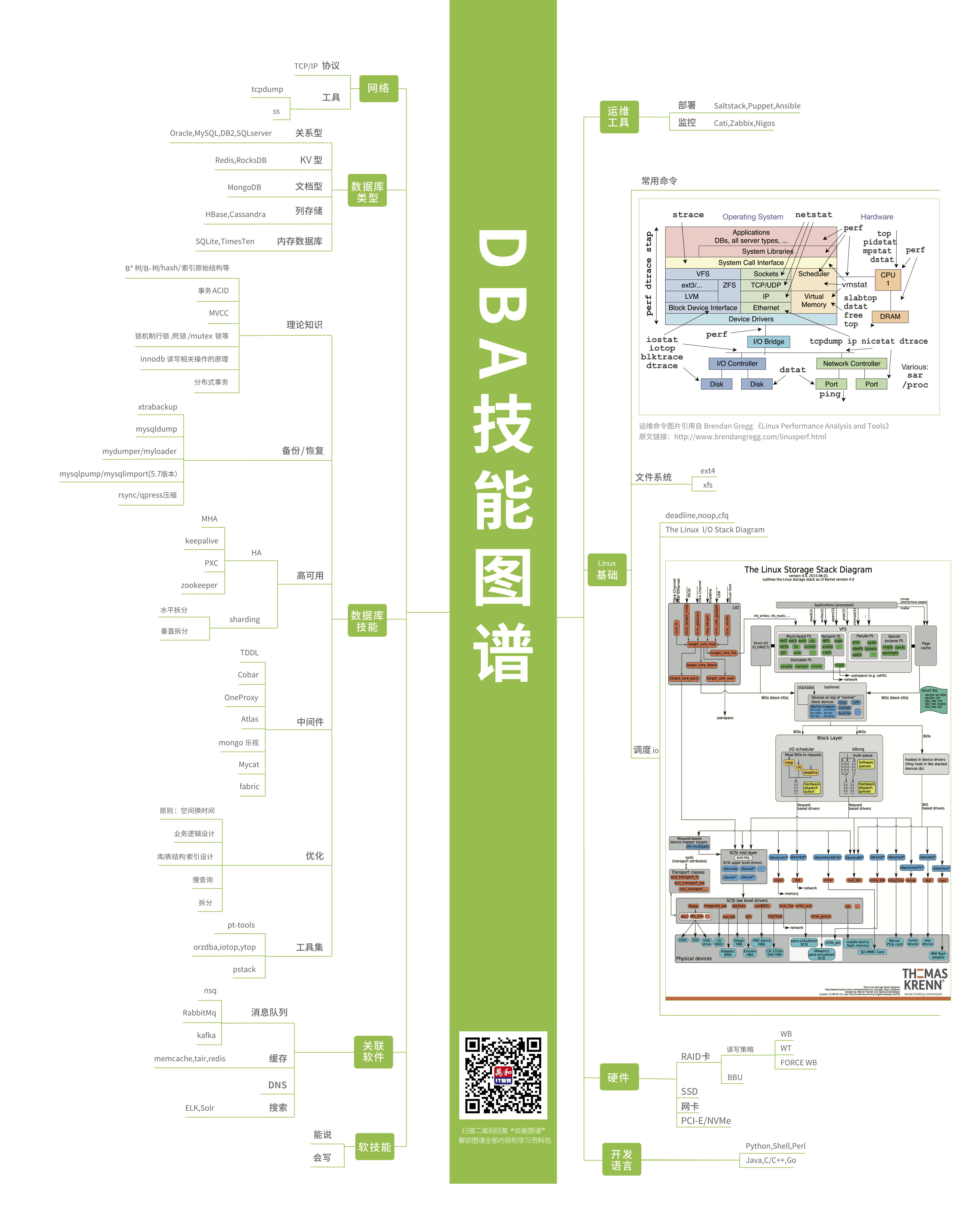
-DBA技能图谱
- performance / 数据库性能
MySQL索引失效带来的性能瓶颈:本文将介绍MySQL索引失效的原因、如何检测索引失效以及如何修复索引失效问题。 一、MySQL索引失效的原因 MySQL索引失效的原因有很多,下面列举几个比较常见的原因。 1.数据量太大 如果数据库中的数据量太大,索引可能会失效。这是因为当查询条件返回的数据太多时,MySQL会选择放弃使用索引而使用全表扫描。 2.索引列数据类型不匹配 如果索引列的数据类型与查询条件的数据类型不匹配,索引也会失效。例如,如果索引列的数据类型是VARCHAR,而查询条件是INT,MySQL将无法使用该索引。 3.索引列被函数处理 如果查询条件中包含函数,那么MySQL将无法使用索引。例如,如果查询条件是“SELECT * FROM my_table WHERE YEAR(created_at) = 2022”,MySQL将无法使用索引。 4.索引列使用了函数 如果索引列中使用了函数,MySQL将无法使用该索引。例如,如果索引列是“CONCAT(first_name, ' ', last_name)”而查询条件是“WHERE first_name = 'Tom'”,MySQL将无法使用该索引。 5.索引列过多 如果表中有太多的索引列,索引的效率将降低。这是因为MySQL需要在多个索引中进行选择,导致查询变慢。 6.查询条件中使用了OR 如果查询条件中使用了OR,MySQL将无法使用索引。例如,“SELECT * FROM my_table WHERE age = 20 OR age = 30”,MySQL将无法使用索引。 7.索引列上存在NULL值 如果索引列上存在NULL值,MySQL将无法使用该索引。这是因为NULL值不能与其他值进行比较。 二、如何检测MySQL索引失效 如果查询速度变慢,我们应该首先考虑是否存在索引失效的问题。下面介绍几种检测MySQL索引失效的方法。 1.使用EXPLAIN EXPLAIN命令可以帮助我们分析查询语句的执行计划,从而找出索引失效的原因。例如,我们可以运行“EXPLAIN SELECT * FROM my_table WHERE age = 20”来查看MySQL是否使用了索引。如果MySQL使用了索引,我们会在Extra列中看到“Using index”。 2.使用慢查询日志 MySQL慢查询日志可以记录执行时间超过指定阈值的SQL语句,从而帮助我们找出可能存在索引失效的查询语句。可以通过修改MySQL配置文件中的slow_query_log参数来开启慢查询日志。然后通过分析慢查询日志来确定哪些查询语句执行时间过长,并检查是否存在索引失效的情况。 3.使用监控工具 MySQL有很多监控工具可以帮助我们分析数据库的性能瓶颈。其中一些工具可以分析查询语句的执行计划,并找出可能存在索引失效的问题。例如,Percona Toolkit和pt-query-digest可以帮助我们分析查询语句的执行计划,并找出可能存在索引失效的问题。 三、如何修复MySQL索引失效 一旦确定了MySQL索引失效的原因,我们可以采取一些措施来修复这个问题。下面列举一些常见的修复措施。 1.优化查询语句 如果查询语句不够优化,MySQL可能会放弃使用索引。我们可以通过重构查询语句来解决这个问题。例如,我们可以尽可能地避免使用OR,避免在索引列上使用函数,避免在查询条件中使用NULL值等等。 2.添加索引 如果某个查询语句没有使用索引,我们可以考虑为相应的列添加索引。但是要注意不要过度添加索引,因为这会影响MySQL的性能。 3.优化数据表结构 如果数据表结构不够优化,索引的效率也会受到影响。我们可以考虑优化数据表结构,例如将大型文本字段拆分为多个字段,将多个表拆分为多个表等等。 4.调整MySQL配置参数 MySQL有许多配置参数可以影响索引的效率。我们可以根据具体情况调整这些参数,例如key_buffer_size、innodb_buffer_pool_size等等。 总结 MySQL索引失效是影响数据库性能的一个重要因素,需要我们注意。本文介绍了MySQL索引失效的原因、如何检测索引失效以及如何修复索引失效问题。在实际应用中,我们应该遵循优化查询语句、添加索引、优化数据表结构和调整MySQL配置参数等原则,来优化MySQL的性能。
- mysql specification / guifan
数据命名规范
所有数据库对象名称必须使用小写字母并用下划线分割。 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。 数据库对象的命名要能做到见名识意,并且最后不要超过 32 个字符。 临时库表必须以 tmp 为前缀并以日期为后缀,备份表必须以 bak 为前缀并以日期 (时间戳) 为后缀。 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
数据库基本设计规范
1、所有表必须使用 InnoDB 存储引擎
没有特殊要求(即 InnoDB 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎 MySQL 5.5 之前默认使用 Myisam,5.6 以后默认的为 InnoDBInnoDB支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
2、数据库和表的字符集统一使用 UTF8MB4
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效。
3、所有表和字段都需要添加注释
使用 comment 从句添加表和列的备注 从一开始就进行数据字典的维护。
4、尽量控制单表数据量的大小,建议控制在 500 万以内
500 万并不是 MySQL 数据库的限制,过大会造成修改表结构、备份、恢复都会有很大的问题,可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
5、谨慎使用 MySQL 分区表
分区表在物理上表现为多个文件,在逻辑上表现为一个表 谨慎选择分区键,跨分区查询效率可能更低 建议采用物理分表的方式管理大数据。
6、尽量做到冷热数据分离,减小表的宽度
MySQL 限制每个表最多存储 4096 列,并且每一行数据的大小不能超过 65535 字节 减少磁盘 IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的 IO)更有效的利用缓存,避免读入无用的冷数据 经常一起使用的列放到一个表中(避免更多的关联操作)
7、禁止在表中建立预留字段
预留字段的命名很难做到见名识义 预留字段无法确认存储的数据类型,所以无法选择合适的类型 对预留字段类型的修改,会对表进行锁定
8、禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机 IO 操作,文件很大时,IO 操作很耗时 通常存储于文件服务器,数据库只存储文件地址信息。。
9、禁止在线上做数据库压力测试
10、禁止从开发环境,测试环境直接连接生成环境数据库
数据库字段设计规范
1. 优先选择符合存储需要的最小的数据类型
原因
列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少也越少,在遍历时所需要的 IO 次数也就越多, 索引的性能也就越差
方法
1、将字符串转换成数字类型存储,如:将 IP 地址转换成整形数据
MySQL 提供了两个方法来处理 IP 地址 inet_aton 把 ip 转为无符号整型 (4-8 位) inet_ntoa 把整型的 ip 转为地址 插入数据前,先用 inet_aton 把 IP 地址转为整型,可以节省空间。显示数据时,使用 inet_ntoa 把整型的 IP 地址转为地址显示即可。
2、对于非负型的数据(如自增 ID、整型 IP)来说,要优先使用无符号整型来存储,因为无符号相对于有符号可以多出一倍的存储空间。 SIGNED INT -2147483648~2147483647 UNSIGNED INT 0~4294967295
VARCHAR (N) 中的 N 代表的是字符数,而不是字节数。使用 UTF8 存储 255 个汉字 Varchar (255)=765 个字节。过大的长度会消耗更多的内存
2. 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
建议把 BLOB 或是 TEXT 列分离到单独的扩展表中 MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。 而且对于这种数据,MySQL 还是要进行二次查询,会使 SQL 性能变得很差,但是不是说一定不能使用这样的数据类型。 如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表中,查询时一定不要使用 select * 而只需要取出必要的列,不需要 TEXT 列的数据时不要对该列进行查询。 TEXT 或 BLOB 类型只能使用前缀索引 因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
3. 避免使用 ENUM 类型
修改 ENUM 值需要使用 ALTER 语句 ENUM 类型的 ORDER BY 操作效率低,需要额外操作 禁止使用数值作为 ENUM 的枚举值
4. 尽可能把所有列定义为 NOT NULL
原因
索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。 进行比较和计算时要对 NULL 值做特别的处理。
5. 使用 TIMESTAMP(4 个字节)或 DATETIME 类型(8 个字节)存储时间
TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07。 TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高,超出 TIMESTAMP 取值范围的使用 DATETIME 类型存储。 经常会有人用字符串存储日期型的数据(不正确的做法):
缺点 1:无法用日期函数进行计算和比较。
缺点 2:用字符串存储日期要占用更多的空间。
6. 同财务相关的金额类数据必须使用 decimal 类型
非精准浮点:float,double 精准浮点:decimal
Decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。可用于存储比 bigint 更大的整型数据。
索引设计规范
1. 限制每张表上的索引数量,建议单张表索引不超过 5 个
索引并不是越多越好!索引可以提高效率同样也可以降低效率;索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。 因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能
2. 禁止给表中的每一列都建立单独的索引
5.6 版本之前,一个 SQL 只能使用到一个表中的一个索引,5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好
3. 每个 InnoDB 表必须有个主键
InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种 InnoDB 是按照主键索引的顺序来组织表的。 不要使用更新频繁的列作为主键,不适用多列主键(相当于联合索引) 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。主键建议使用自增 ID 值。
常见索引列建议
出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。 并不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。 多表 JOIN 的关联列。
如何选择索引列的顺序
建立索引的目的是:
希望通过索引进行数据查找,减少随机 IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
区分度最高的放在联合索引的最左侧(区分度 = 列中不同值的数量 / 列的总行数)。 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO 性能也就越好)。 使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)。
避免建立冗余索引和重复索引
因为这样会增加查询优化器生成执行计划的时间。 重复索引示例:primary key (id)、index (id)、unique index (id) 冗余索引示例:index (a,b,c)、index (a,b)、index (a)
优先考虑覆盖索引
对于频繁的查询优先考虑使用覆盖索引。
覆盖索引
就是包含了所有查询字段 (where,select,ordery by,group by 包含的字段) 的索引
覆盖索引的好处:
避免 InnoDB 表进行索引的二次查询 InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了 IO 操作,提升了查询效率。 可以把随机 IO 变成顺序 IO 加快查询效率 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
索引 SET 规范
尽量避免使用外键约束。 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。 外键可用于保证数据的参照完整性,但建议在业务端实现。 外键会影响父表和子表的写操作从而降低性能。
数据库 SQL 开发规范
- 建议使用预编译语句进行数据库操作
预编译语句可以重复使用这些计划,减少 SQL 编译所需要的时间,还可以解决动态 SQL 所带来的 SQL 注入的问题 只传参数,比传递 SQL 语句更高效 相同语句可以一次解析,多次使用,提高处理效率。
- 避免数据类型的隐式转换
隐式转换会导致索引失效。如:
select name,phone from customer where id = '111';
3. 充分利用表上已经存在的索引
避免使用双 % 号的查询条件。 如 a like '%123%',(如果无前置 %,只有后置 %,是可以用到列上的索引的) 一个 SQL 只能利用到复合索引中的一列进行范围查询 如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到,在定义联合索引时,如果 a 列要用到范围查找的话,就要把 a 列放到联合索引的右侧。 使用 left join 或 not exists 来优化 not in 操作, 因为 not in 也通常会使用索引失效。
4. 数据库设计时,应该要对以后扩展进行考虑
5. 程序连接不同的数据库使用不同的账号,禁止跨库查询
为数据库迁移和分库分表留出余地 降低业务耦合度 避免权限过大而产生的安全风险
6. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
消耗更多的 CPU 和 IO 以网络带宽资源 无法使用覆盖索引 可减少表结构变更带来的影响
7. 禁止使用不含字段列表的 INSERT 语句
如:
insert into values ('a','b','c');应使用:
insert into t(c1,c2,c3) values ('a','b','c');8. 避免使用子查询,可以把子查询优化为 JOIN 操作
通常子查询在 in 子句中,且子查询中为简单 SQL (不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
子查询性能差的原因:
- 子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。 特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。 由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
9. 避免使用 JOIN 关联太多的表
对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。 在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。 如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。 同时对于关联操作来说,会产生临时表操作,影响查询效率 MySQL 最多允许关联 61 个表,建议不超过 5 个。
10. 减少同数据库的交互次数
数据库更适合处理批量操作 合并多个相同的操作到一起,可以提高处理效率
11. 对应同一列进行 or 判断时,使用 in 代替 or
In 的值不要超过 500 个, in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
12. 禁止使用 order by rand () 进行随机排序
会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。 推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
13. WHERE 从句中禁止对列进行函数转换和计算
对列进行函数转换或计算时会导致无法使用索引。不推荐
where date(create_time)='20190101'
推荐
where create_time >= '20190101' and create_time < '20190102'14. 在明显不会有重复值时使用 UNION ALL 而不是 UNION
UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作。 UNION ALL 不会再对结果集进行去重操作。
15. 拆分复杂的大 SQL 为多个小 SQL
大 SQL:逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL 。 MySQL:一个 SQL 只能使用一个 CPU 进行计算。 SQL 拆分后可以通过并行执行来提高处理效率。
数据库操作行为规范
1. 超 100 万行的批量写(UPDATE、DELETE、INSERT)操作,要分批多次进行操作
大批量操作可能会造成严重的主从延迟 主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况 Binlog 日志为 row 格式时会产生大量的日志 大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因。
避免产生大事务操作
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对 MySQL 的性能产生非常大的影响。 特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
2. 对于大表使用 pt-online-schema-change 修改表结构
避免大表修改产生的主从延迟 避免在对表字段进行修改时进行锁表 对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。 pt-online-schema-change 它会首先建立一个与原表结构相同的新表,并且在新表上进行表结构的修改,然后再把原表中的数据复制到新表中,并在原表中增加一些触发器。 把原表中新增的数据也复制到新表中,在行所有数据复制完成之后,把新表命名成原表,并把原来的表删除掉,把原来一个 DDL 操作,分解成多个小的批次进行。
3. 禁止为程序使用的账号赋予 super 权限
当达到最大连接数限制时,还运行 1 个 有 super 权限的用户连接 super 权限只能留给 DBA 处理问题的账号使用。
4. 对于程序连接数据库账号,遵循权限最小原则
程序使用数据库账号只能在一个 DB 下使用,不准跨库 程序使用的账号原则上不准有 drop 权限。
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号