

一、环境
1、安装:默认选项安装即可
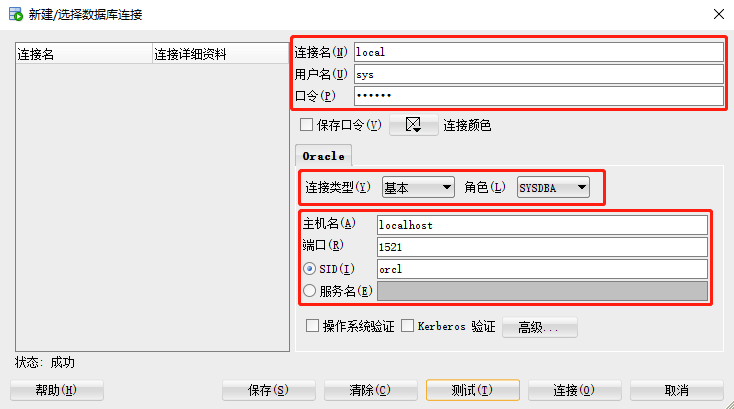
2、测试连接
3、启动与停止

4、navicat连接ora-28040问题
修改配置文件:盘符:\app\用户名\virtual\product\12.2.0\dbhome_1\network\admin\sqlnet.ora加上SQLNET.ALLOWED_LOGON_VERSION=8属性值
5、navicat连接ora-01017问题
sql developer正常连接,navicat不能正常连接:使用sql developer,右击连接->重设口令
6、navicat连接oracle无法打开命令列界面
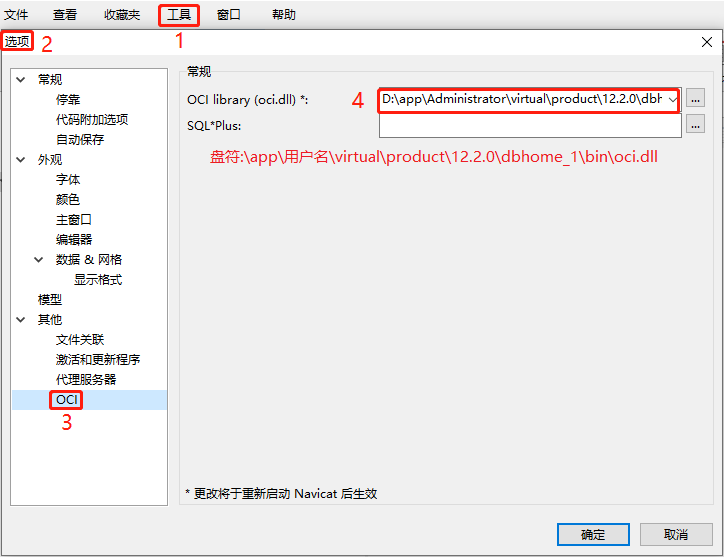
二、知识点
1、基本操作
一、表空间操作 --创建表空间 create tablespace 表空间名 datafile '数据文件.dbf' size 100m autoextend on next 10m; --删除表空间 drop tablespace 表空间名; --创建用户 create user c##用户名 identified by 口令 default tablespace 表空间名; --给用户授权 --oracle数据控中常用角色 connect--连接角色,基本角色 resource--开发者角色 dba--超级管理员角色 --给用户名授予角色 grant dba to c##用户名; 二、表操作 --创建表 create table 表名( 字段名 number(20),--整数类型,浮点类型number(9,2) 字段名 varchar2(10)--字符串类型 ); --修改表结构 --添加一列 alter table 表名 add (字段名 number(2)); --修改列类型 alter table 表名 modify 字段名 char(1); --修改列名称 alter table 表名 rename column 字段名 to 字段名; --删除一列 alter table 表名 drop column 字段名; 三、记录操作 --查询表中记录 select * from 表名; --添加一条记录 insert into 表名 (字段名,字段名) values (值,'值'); commit; --修改一条记录 update 表名 set 字段名 = '值' where 字段名 = 值; commit; 四、删除操作 --三个删除 --删除表中全部记录 delete from person; --删除表结构 drop table person; --先删除表,再次创建表。效果等同于删除表中全部记录。 --在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。 --索引可以提供查询效率,但是会影响增删改效率。 truncate table person; 五、序列的使用 --序列不真的属于任何一张表,但是可以逻辑和表做绑定。 --序列:默认从1开始,一次递增,主要用来给主键赋值使用。 --dual:虚表,只是为了不补全语法,没有任何意义。 create sequence s_person; select s_person.currval from dual; --添加一条记录 insert into person(pid,pname) values(s_person.nextval,'小明'); commit; select * from person;
2、查询
一、scott用户 --scott用户,密码tiger。 --解锁scott用户 alter user scott account unlock; --解锁scott用户的密码【此句也可以用来重置密码】 alter user scott identified by tiger; 二、函数 --单行函数:作用于一行,返回一个值。 --字符函数 select upper('yes') from dual;--YES select lower('YES') from dual;--yes --数值函数 select round(26.16,1) from dual;--四舍五入,后面的参数表示保留的位数 select trunc(26.16,1) from dual;--直接截取,不再看后面位数的数字是否大于5 select mod(10,3) from dual;--求余数 --日期函数 select sysdate+30 from dual;--当前系统时间,可做运算(单位:天) select months_between(sysdate,sysdate-365) from dual;--时间间隔月数 --转换函数 --日期转字符串 select to_char(sysdate,'fm yyyy-mm-dd hh24:mi:ss') from dual; --字符串转日期 select to_date('2020-10-14 10:6:7','fm yyyy-mm-dd hh24:mi:ss') from dual; --通用函数 --null值做算术运算结果都为null,nvl函数给为null值的字段赋默认值 select nvl(字段,默认值) from 表名; --多行函数【聚合函数】:作用于多行,返回一个值。 select count(1) from person;--查询总数,1代表主键 select sum(字段) from person;--查询总和 select max(字段) from person;--查询最大值 select min(字段) from person;--查询最小值 select avg(字段) from person;--查询平均值 三、条件表达式 --等值表达式 select pid, case pid when 1 then '第一名' else '淘汰' end 排名 from person; --mysql和oracle通用表达式,oracle中除了起别名,都用单引号 select pid, case when pid<2 then '第一名' else '淘汰' end "排名" from person; --oracle专用表达式 select pid, decode(pid, 1, '第一名', '淘汰') 排名 from person; 四、分组查询 --分组查询中,出现在group by后面的原始列,才能出现在select后面 --没有出现在group by后面的列,想在select后面,必须加上聚合函数。 --聚合函数有一个特性,可以把多行记录变成一个值。 select pdept,sum(pid) from person group by pdept; --分组查询条件语句,所有条件都不能使用别名来判断 select pdept,sum(pid) from person group by pdept having sum(pid)>6; --where是过滤分组前的数据,having是过滤分组后的数据。 --表现形式:where必须在group by之前,having是在group by之后。 select pdept,sum(pid) from person where pid<5 group by pdept having sum(pid)>3; 五、多表查询 --隐式内连接 select * from person,dept where pdept=did; --显示内连接 select * from person inner join dept on pdept=did;--inner可省略 --左外连接 select * from person left join dept on pdept=did;--列出所有的左表记录 --右外连接 select * from person right join dept on pdept=did;--列出所有的右表记录 --oracle专用外连接 select * from person,dept where dept.did=person.pdept(+);--列出所有的dept表记录 --自连接 select * from person p1,person p2 where P1.pid=P2.pdept; 六、子查询 --子查询的结果是单行单列的 select * from person where pid = (select sum(pdept) from person where pdept=1); --子查询的结果是多行单列的 select * from person where pid in (select pdept from person group by pdept); --子查询的结果是多行多列的 select * from (select * from person) p1,person p2 where P1.pid=P2.pdept; 七、分页 --rownum:给记录添加行号,rownum在order by之前执行,rownum在where之后执行 select * from ( select rownum rn,rownumTable.* from( select * from person order by pid ) rownumTable ) where rn>(#{num}-1)*#{size} and rn<=#{num}*#{size};--参数num:页数,参数size:每页条数
3、对象
一、视图 --视图的概念:视图就是提供一个查询的窗口,所有数据来自于原表。 --跨用户使用查询语句创建表 create table 表名 as select * from c##用户名.表名; --创建视图【必须有dba权限】 create view v_other_person as select * from other_person; --查询视图 select * from v_other_person; --修改视图【不推荐】 update v_other_person set pname='黄婷婷' where pid=10; --创建只读视图 create view v_other_person as select * from other_person with read only; --视图作用 --第一、屏蔽敏感字段 --第二、多表查询简单化 二、索引 --索引的概念:索引就是在表的列上构建一个二叉树 --达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。 --单列索引 --创建单列索引 create index i_person_pname on person(pname); --单列索引触发规则,条件必须是索引列中的原始值。 --单行函数,模糊查询,都会影响索引的触发。 select * from person where pname='孟美岐'; --复合索引 --创建复合索引 create index i_person_pname_pid on person(pname,pid); --复合索引中第一列为优先检索列 --如果要触发复合索引,必须包含有优先检索列中的原始值。 select * from person where pname='孟美岐' and pid=20;--触发复合索引 select * from person where pname='孟美岐' or pid=20;--不触发索引 select * from person where pname='孟美岐';--触发单列索引
4、编程
一、pl/sql编程语言 --pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。 --pl/sql编程语言比一般的过程化编程语言,更加灵活高效。 --pl/sql编程语言主要用来编写存储过程和存储函数等。 二、声明方法 --赋值操作可以使用:=也可以使用into查询语句赋值 declare i number(2):=10; s varchar2(10):='小明'; d_pmoney person.pmoney%type;--引用型变量 d_person person%rowtype;--记录型变量 begin dbms_output.put_line(i); dbms_output.put_line(s); select pmoney into d_pmoney from person where pid=1; dbms_output.put_line(d_pmoney); select * into d_person from person where pid=1; dbms_output.put_line(d_person.pid||','||d_person.pname||','||d_person.pmoney); end; 三、pl/sql中的if判断 declare i number(2) := 99; begin if i<60 then dbms_output.put_line('不及格'); elsif i<85 then dbms_output.put_line('及格'); else dbms_output.put_line('优秀'); end if; end; 四、pl/sql中的loop循环 --while循环 declare i number(2) := 1; begin while i<11 loop dbms_output.put_line(i); i:=i+1; end loop; end; --exit循环 declare i number(2) := 1; begin loop exit when i>10; dbms_output.put_line(i); i:=i+1; end loop; end; --for循环 declare begin for i in 1..10 loop dbms_output.put_line(i); end loop; end; 五、游标 --可以存放多个对象,多行记录 declare cursor ul is select * from person; li person%rowtype; begin open ul; loop fetch ul into li; exit when ul%notfound; dbms_output.put_line(li.pname); end loop; close ul; end; --带参游标 declare cursor ul(c_pid person.pid%type) is select * from person where pid>c_pid; li person%rowtype; begin open ul(1); loop fetch ul into li; exit when ul%notfound; dbms_output.put_line(li.pname); end loop; close ul; end; 六、存储过程 --存储过程:存储过程就是提前已经编译好的一段pl/sql语言,放置在数据库端 --可以直接被调用。这一段pl/sql一般都是固定步骤的业务。 create or replace procedure updatepersonpdeptbypidpro(p_pdept person.pdept%type,p_pid person.pid%type) is begin update person set pdept=p_pdept where pid=p_pid; end; --使用 declare begin updatepersonpdeptbypidpro(10,7); end; --out类型参数 --in和out类型参数的区别是什么? --凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。 create or replace procedure protestout(str out varchar2) is begin str:='孟美岐'; end; --使用 declare str varchar2(20); begin protestout(str); dbms_output.put_line(str); end; 七、存储函数 --存储过程和存储函数的参数都不能带长度 --存储函数的返回值类型不能带长度 create or replace function sumpersonpidfun(f_pid person.pid%type) return person.pid%type is res person.pid%type; begin select sum(nvl(pid,0)) into res from person where pid>f_pid; return res; end; --使用 declare begin dbms_output.put_line(sumpersonpidfun(0)); end; --存储函数和存储过程的区别 --语法区别:关键字不一样 --存储函数比存储过程多了两个return --本质区别:存储函数有返回值,而存储过程没有返回值 --如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数。 --即便是存储过程使用了out类型的参数,其本质也不是真的有了返回值, --而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。 --我们可以使用存储函数有返回值的特性,来自定义函数。 --而存储过程不能用来自定义函数。 八、触发器 --触发器,就是制定一个规则,在我们做增删改操作的时候, --只要满足该规则,自动触发,无需调用。 --语句级触发器:不包含有for each row的触发器。 --行级触发器:包含有for each row的就是行级触发器。 --加for each row是为了使用:old或者:new对象或者一行记录。 --语句级触发器 create or replace trigger t_person_insert after insert on person declare begin dbms_output.put_line('********person添加了一行新记录********'); end; --触发 insert into person(pid,pname,pdept) values(7,'测试',3); --行级触发器 --raise_application_error(-20001~-20999之间,'错误提示信息'); create or replace trigger t_person_update before update on person for each row declare begin if :old.pdept<:new.pdept then raise_application_error(-20001,'新部门编号不能大于原部门编号'); end if;end; --触发 update person set pdept=4 where pid=7; --触发器案例,id自增 create or replace trigger t_person_auid before insert on person for each row declare begin select s_person.nextval into :new.pid from dual; end; --触发 insert into person values(1,'测试自增',3);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号