kubernetes
Kubernetes
一、kubernetes概述
1、kubernetes基本介绍
kubernetes,简称 K8s,是用 8 代替 8 个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes 的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes 提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在 build 或 release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
Kubernetes 是 Google 开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在 Kubernetes 中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
-
k8s是谷歌在2014年开源的容器化集群管理系统
-
使用k8s进行容器化应用部署
-
使用k8s利用应用的扩展
-
k8s目标是让部署容器化应用更加简洁和高效
2、kubernetes 功能和架构
2.1.概述
Kubernetes 是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes 能够进行应用的自动化部署和扩缩容。在 Kubernetes 中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes 积累了作为 Google 生产环境运行工作负载 15 年的经验,并吸收了来自于社区的最佳想法和实践。
2.2.k8s功能
-
自动装箱
基于容器对应用运行环境的资源配置要求自动部署应用容器
-
自我修复(自愈能力)
当容器失败时,会对容器进行重启。
当所部署的Node节点有问题时,会对容器进行重新部署和重新调度。
当容器未通过监控检查时,会关闭此容器直到容器正常运行,才会对外提供服务。
-
水平扩展
通过简单的命令、用户UI界面或基于CPU等资源使用情况,对应用容器进行规模扩大或规模剪裁
-
服务发现
用户不需要使用额外的服务发现机制,就能够基于Kubernets自身能力实现服务发现和负载均衡
-
滚动更新
可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
-
版本回退
可以根据应用部署情况,对引用容器运行的应用,进行历史版本即使回退。
-
秘钥和配置管理
在不需要重新构建镜像的情况下,可以部署和更新秘钥和应用配置,类似热部署
-
存储编排
自动实现存储系统挂载及引用,特别对有状态应用实现数据持久化非常重要。存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph等)、公共存储服务。
-
批处理
提供一次性任务,定时任务,满足批量数据处理和分析的场景。
2.3.应用架构部署分类
-
无中心节点架构
ClusterFS
-
有中心节点架构
HDFS
K8S
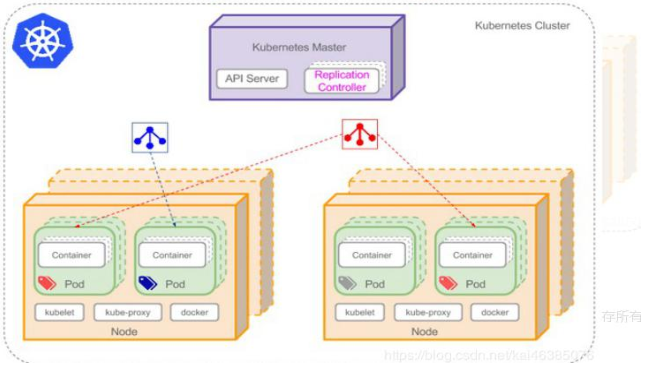
2.4.k8s集群架构
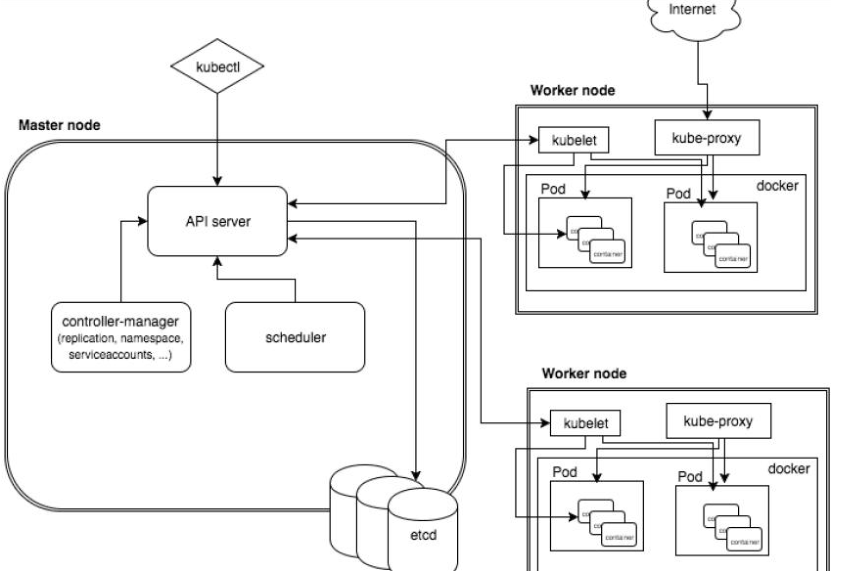
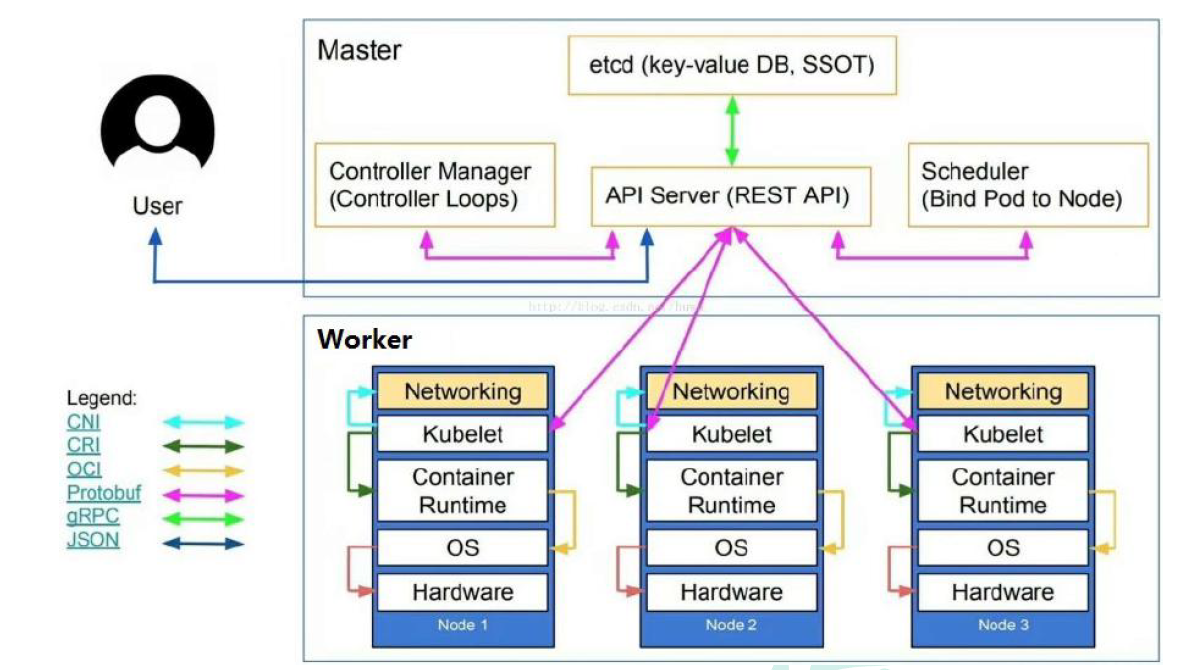
要做一个k8s集群,首先里面要包含一个master(主控节点)和node(工作节点)。
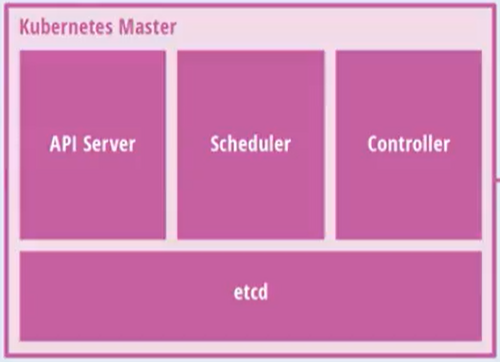
master中的组件:
-
API Server
可以理解为集群统一入口,以restful方式提供操作,交给etcd来存储
- 提供认证、授权、访问控制、API注册和发现等机制
-
scheduler
做节点调度,选择node节点应用部署
-
controller-manager
处理集群中常规后台任务,一个资源应对一个控制器
-
etcd
存储系统,用来保存集群相关的数据。
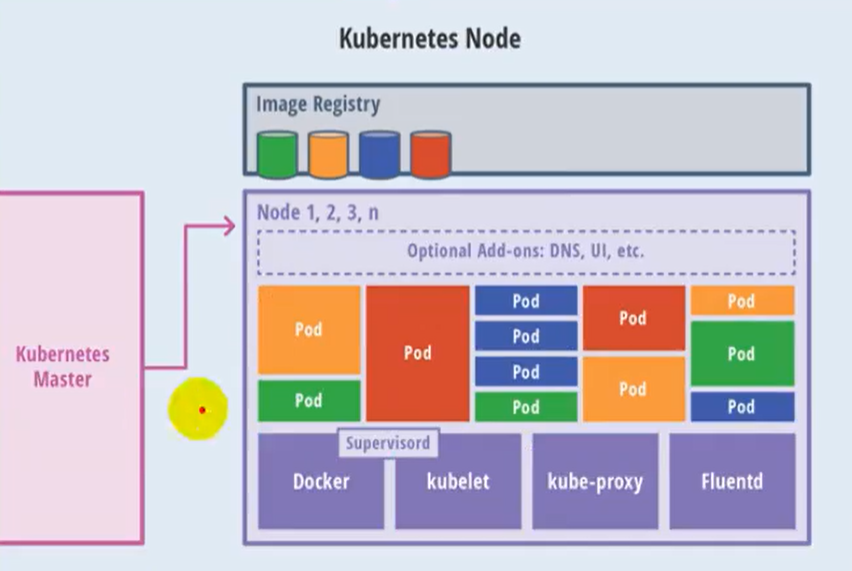
node节点中的组件
-
kubelet
master派到node节点中的代表,管理本机容器
- 一个集群中每个节点上运行的代理,它保证容器都运行在Pod中
- 负责维护容器的生命周期,同时也负责Volume(CSI) 和 网络(CNI)的管理
-
kube-proxy
提供网络代理,负载均衡等操作
容器运行环境
- 容器运行环境是负责运行容器的软件
- Kubernetes支持多个容器运行环境:Docker、containerd、cri-o、rktlet以及任何实现Kubernetes CRI (容器运行环境接口) 的软件
fluentd
是一个守护进程,它有助于提升 集群层面日志
2.5.k8s核心概念
-
pod
是k8s中最小的部署单元,一组容器的集合,一个pod中的容器是共享网络的,生命周期是短暂的。
-
controller
确保预期的pod副本数量。
无状态应用部署
- 无状态就是指不需要依赖于网络或者ip
有状态应用部署
- 有状态需要特定条件
确保所有的node运行同一个pod
支持一次性任务和定时任务
-
Service
定义一组pod的访问规则
Pod的负载均衡,提供一个或多个Pod的稳定访问地址
支持多种方式[ClusterIP、NodePort、LoadBalancer]
-
Volume
声明在Pod容器中可访问的文件目录
可以被挂载到Pod中一个或多个容器指定路径下
支持多种后端存储抽象【本地存储、分布式存储、云存储】
-
Deployment
定义一组Pod副本数目,版本等
通过控制器【Controller】维持Pod数目【自动回复失败的Pod】
通过控制器以指定的策略控制版本【滚动升级、回滚等】
- Label
标签,用于对象自愿查询、筛选

-
Namespace
命名空间,逻辑隔离
一个集群内部的逻辑隔离机制【鉴权、资源】
每个资源都属于一个namespace
同一个namespace所有资源不能重复
不同namespace可以资源名重复
-
API
通过Kubernetes的API来操作整个集群同时我们可以通过 kubectl 、ui、curl 最终发送 http + json/yaml 方式的请求给API Server,然后控制整个K8S集群,K8S中所有的资源对象都可以采用 yaml 或 json 格式的文件定义或描述。
如下:使用yaml部署一个nginx的pod

完整流程
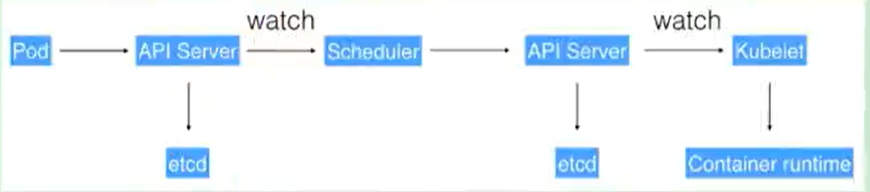
- 通过Kubectl提交一个创建RC(Replication Controller)的请求,该请求通过APlserver写入etcd
- 此时Controller Manager通过API Server的监听资源变化的接口监听到此RC事件
- 分析之后,发现当前集群中还没有它所对应的Pod实例
- 于是根据RC里的Pod模板定义一个生成Pod对象,通过APIServer写入etcd
- 此事件被Scheduler发现,它立即执行执行一个复杂的调度流程,为这个新的Pod选定一个落户的Node,然后通过API Server讲这一结果写入etcd中
- 目标Node上运行的Kubelet进程通过APiserver监测到这个"新生的Pod.并按照它的定义,启动该Pod并任劳任怨地负责它的下半生,直到Pod的生命结束
- 随后,我们通过Kubectl提交一个新的映射到该Pod的Service的创建请求
- ControllerManager通过Label标签查询到关联的Pod实例,然后生成Service的Endpoints信息,并通过APIServer写入到etod中,
- 接下来,所有Node上运行的Proxy进程通过APIServer查询并监听Service对象与其对应的Endponts信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能er
二、kubernetes集群搭建
1.搭建k8s环境平台规划
单master集群
单个master节点,然后管理多个node节点
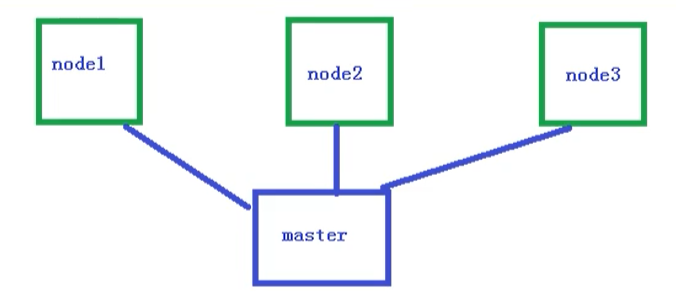
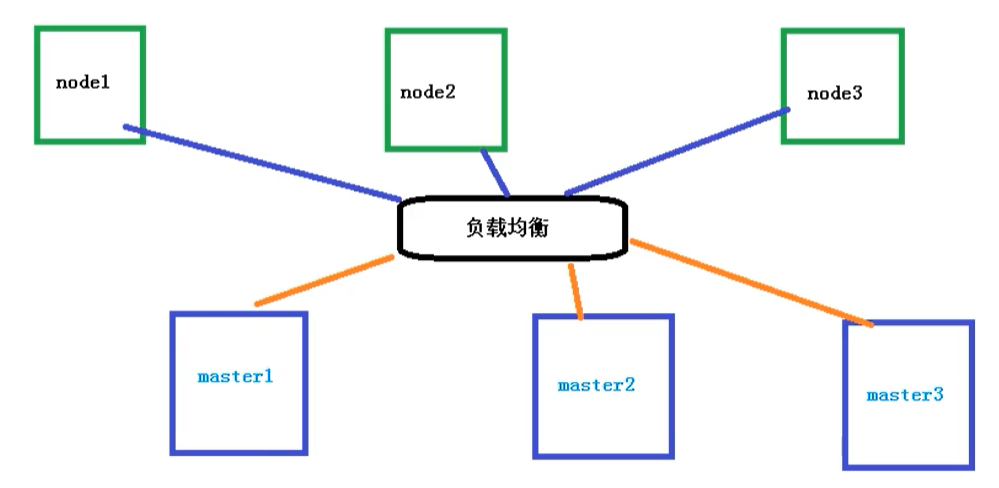
多master集群
多个master节点,管理多个node节点,同时中间多了一个负载均衡的过程
服务器硬件配置要求
测试环境
master:2核 4g 20g
node: 4核 8g 40g
生产环境
master:8核 16G 100G
node: 16核 64G 200G
目前生产部署Kubernetes集群主要有两种方式:
-
kubeadm
kubeadm是k8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群
-
二进制包
从github下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护。
2.用kubeadm方式搭建k8s集群
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。这个工具能通过两条指令完成一个Kubernetes集群的部署:
创建一个master节点
kubeadm init
将一个Node节点加入到当前集群中
kubeadm join <master节点ip:端口>
2.1 安装要求
Kubernetes集群需要瞒住一下几个条件:
- 一台或多台机器,操作系统centos7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
- 集群中所有机器之间网络互通
- 可以访问外网,需要拉取镜像
- 禁止swap分区
2.2.准备环境
| 角色 | IP |
|---|---|
| master | 192.168.245.132 |
| node1 | 192.168.245.133 |
| node2 | 192.168.245.134 |
初始化环境
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久关闭
setenforce 0 # 临时关闭
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭
# 根据规划设置主机名【master节点上操作】
hostnamectl set-hostname k8smaster
# 根据规划设置主机名【node1节点操作】
hostnamectl set-hostname k8snode1
# 根据规划设置主机名【node2节点操作】
hostnamectl set-hostname k8snode2
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.245.132 k8smaster
192.168.245.133 k8snode1
192.168.245.134 k8snode2
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
安装docker
首先配置一下Docker的阿里yum源
cat >/etc/yum.repos.d/docker.repo<<EOF [docker-ce-edge] name=Docker CE Edge - \$basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg EOFyum方式安装docker
# yum安装 yum -y install docker-ce-18.06.1.ce-3el7 # 查看docker版本 docker --version # 启动docker systemctl enable docker && systemctl start docker配置docker镜像
cat >> /etc/docker/daemon.json << EOF { "registry-mirrors": ["你自己的地址,可以到阿里云上申请"] } EOF
安装Kubernetes
添加yum的k8s软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF安装kubeadm,kubelet和kubectl
# 安装kubelet、kubeadm、kubectl,同时指定版本 yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0 # 设置开机启动 systemctl enable kubelet
2.3.部署kubernetes Master
在master节点上执行以下命令
kubeadm init --apiserver-advertise-address=192.168.245.132 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
参数说明
* --apiserver-advertise-address:当前master节点的ip
* --image-repository:指定阿里云镜像
* --kubernetes-version: 指定我们前面安装的版本
* --service-cidr和--pod-network-cidr:只要不和我们apiserver-advertise-address设置的ip冲突就行
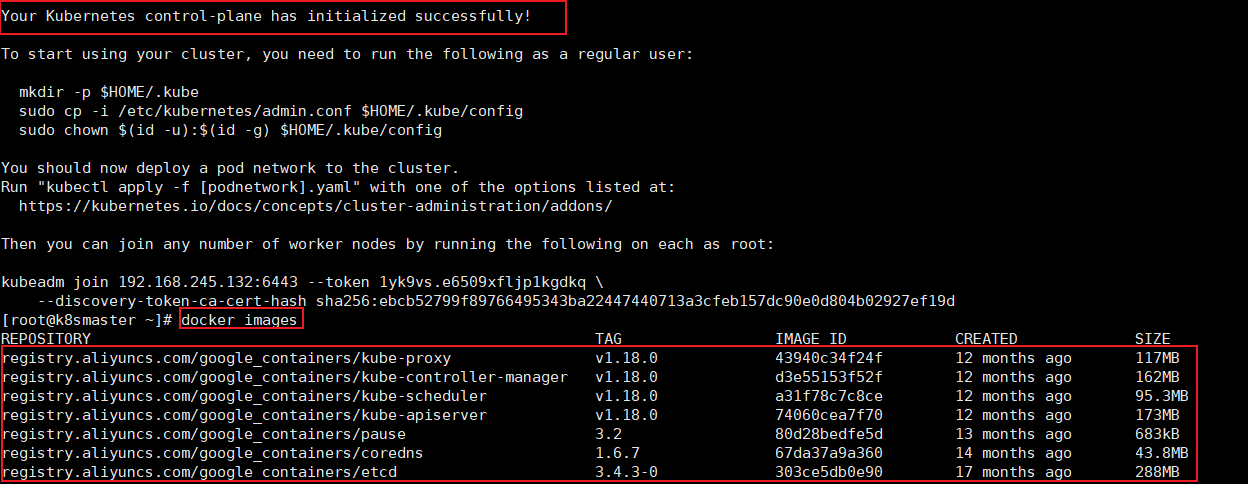
出现红框所示就表示成功
使用kubectl工具[master节点上操作]
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
执行完成后,使用以下命令来查看我们正在运行的节点
kubectl get nodes

可以看到,已经有一个master节点已经运行,但是还处于未就绪状态。
下面,我们将Node节点加入到master节点上
将node节点加入到kubernetes Node[Slave节点]
2.4.加入kubernetes Node
下面,我们将node1和node2加入到master中,执行kubeadm init输出的kuebeadm join命令:
注意,以下命令是在master初始化完成后,每个人的都不一样,需要复制自己生成的
kubeadm join 192.168.245.132:6443 --token xps8ub.rd83du9he1cofd2n --discovery-token-ca-cert-hash sha256:ebcb52799f89766495343ba22447440713a3cfeb157dc90e0d804b02927ef19d
默认有效期为24小时,当过期后,这个token就不能用了,可以用一下命令重新生成
kubadm create token --print-join-command
当我们把两个节点加入进来后,就可以去Master节点执行下面命令查看情况
kubectl get nodes
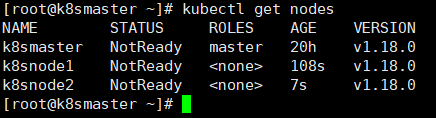
可以看出,node1和node2已经加入到了k8smaster中了。此时,STATUS还是未就绪状态,还不能对外进行访问,需要部署CNI网络插件才能访问,下面,我们来部署CNI插件
2.5.部署CNI网络插件
下载网络配置
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。
# 添加
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
##①首先下载v0.13.1-rc2-amd64 镜像
##参考博客:https://www.cnblogs.com/pyxuexi/p/14288591.html
##② 导入镜像,命令,,特别提示,3个机器都需要导入,3个机器都需要导入,3个机器都需要导入,3个机器都需要导入,重要的事情说3遍。不然抱错。如果没有操作,报错后,需要删除节点,重置,在导入镜像,重新加入才行。本地就是这样操作成功的!
docker load < flanneld-v0.13.1-rc2-amd64.docker
#####下载本地,替换将image: quay.io/coreos/flannel:v0.13.1-rc2 替换为 image: quay.io/coreos/flannel:v0.13.1-rc2-amd64
# 查看状态 【kube-system是k8s中的最小单元】
kubectl get pods -n kube-system
如果无法下载,可以直接访问上面的地址,在linux中直接创建kube-flannel.yml文件
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.13.1-rc2
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.13.1-rc2
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
然后执行kubectl apply -f kube-flannel.yml命令即可
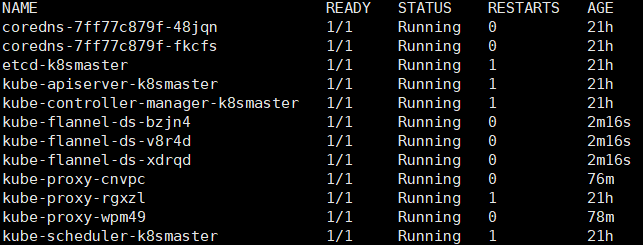
查看状态【kube-system是k8s中的最小单元】
kubectl get pods -n kube-system
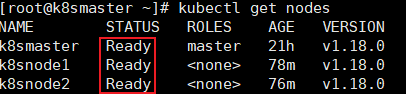
运行完成后,我们查看[状态](kubectl get nodes)可以发现,已经变成Ready状态了。
如果上述操作完成过后,还有节点处于NotReady状态,可以在Master将该节点删除
# master节点将该节点删除
kubectl delete node k8snode1
# 重置k8snode1
kubeadm reset
# 重置完成后在加入
kubeadm join 192.168.245.132:6443 --token xps8ub.rd83du9he1cofd2n --discovery-token-ca-cert-hash sha256:ebcb52799f89766495343ba22447440713a3cfeb157dc90e0d804b02927ef19d
2.6.测试kubernetes集群
在kubernetes集群中创建一个pod,验证是否正常运行:
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
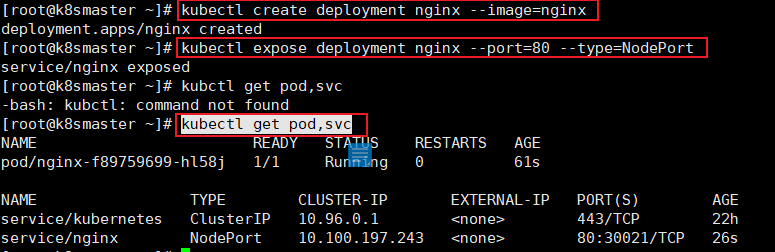

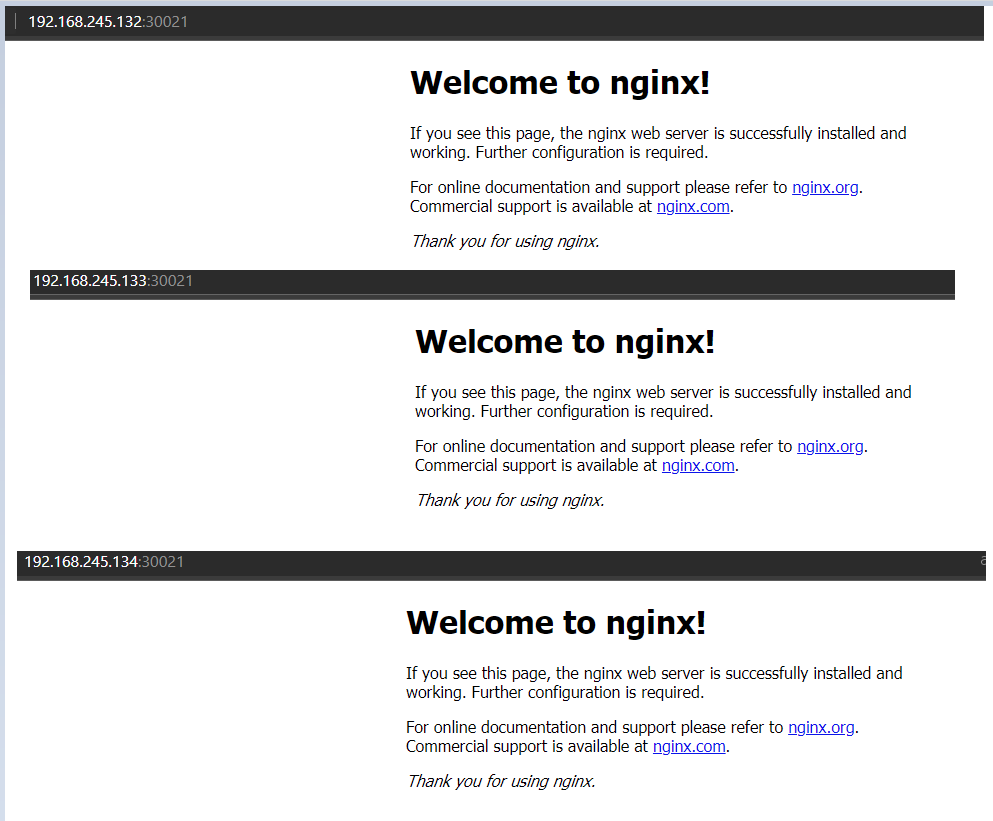
访问地址:http:NodeIP:Port,上面kubectl get pod,svc 中PORT有80:30021映射,用工作节点的ip+80映射过后的地址就可以访问了
例子:192.168.245.132:30021
2.7.安装总结
-
安装三台虚拟机,linux版本为centos7.x
-
对三个安装之后的虚拟机进行初始化操作
-
在三个节点分别安装docker kubelet kubeadm kubectl
-
在master节点中执行
kubeadm init命令进行初始化 -
在node节点上执行
kubeadm join命令把node节点加入到当前集群中 -
配置网络插件
3.使用二进制的方式搭建k8s集群
1.安装要求
在开始之前,部署 Kubernetes集群机器需要满足以下几个条件:
(1) 一台或多台机器,操作系统Cent0s7.x-86x64
(2) 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
(3) 集群中所有机器之间网络互通
(4) 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
(5) 禁止swap分区
2.操作系统初始化
和上面用kubeadm方式一样
3.为etcd和apiservcer自签证书及Etcd集群部署
3.1 准备cfssl证书生成工具
cfssl是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用。
找任意一台服务器操作,这里使用master节点
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
3.2.生成Etcd证书
1、自签证书颁发机构(CA)
创建工作目录
mkdir -p ~/TLS/{etcd,k8s}
ls
自签CA:
cat > ca-config.json<< EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json<< EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
生成证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -ls *pem ca-key.pem ca.pem
2、使用自签CA签发Etcd HTTPS证书
cat > server-csr.json<< EOF
{
"CN": "etcd",
"hosts": [
"192.168.245.135",
"192.168.245.136",
"192.168.245.137"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
注:上述文件 hosts 字段中 IP 为所有 etcd 节点的集群内部通信 IP,一个都不能少!为了方便后期扩容可以多写几个预留的 IP。
生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server ls server*pem server-key.pem server.pem
3.3.部署Etcd集群
从github下载二进制文件
wget https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
一下节点1上操作,简化操作,将节点1生成的所有文件拷贝到节点2和节点3
(1) 创建工作目录并解压二进制包
mkdir –p /opt/etcd/{bin,cfg,ssl}
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
(2) 创建etcd 配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.245.135:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.245.135:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.245.135:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.245.135:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.245.135:2380,etcd-2=https://192.168.245.136:2380,etcd-3=https://192.168.245.137:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
ETCD_NAME:节点名称,集群中唯一
ETCD_DATA_DIR:数据目录
ETCD_LISTEN_PEER_URLS:集群通信监听地址
ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址
ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址
ETCD_INITIAL_CLUSTER:集群节点地址
ETCD_INITIAL_CLUSTER_TOKEN:集群 Token
ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new 是新集群,existing 表示加入已有集群
(3) systemd 管理 etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd --cert-file=/opt/etcd/ssl/server.pem --key-file=/opt/etcd/ssl/server-key.pem --peer-cert-file=/opt/etcd/ssl/server.pem --peer-key-file=/opt/etcd/ssl/server-key.pem --trusted-ca-file=/opt/etcd/ssl/ca.pem --peer-trusted-ca-file=/opt/etcd/ssl/ca.pem --logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
(4) 拷贝刚才生成的证书
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/
(5) 启动并设置开机启动
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
(6) 将上面节点1所有生成的文件拷贝到2和3
scp -r /opt/etcd/ root@192.168.245.136:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.245.136:/usr/lib/systemd/system/
scp -r /opt/etcd/ root@192.168.245.137:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.245.137:/usr/lib/systemd/system/
(7) 在节点n1 和节点 n2 分别修改etcd.conf 配置文件中的的节点名和当前服务器IP
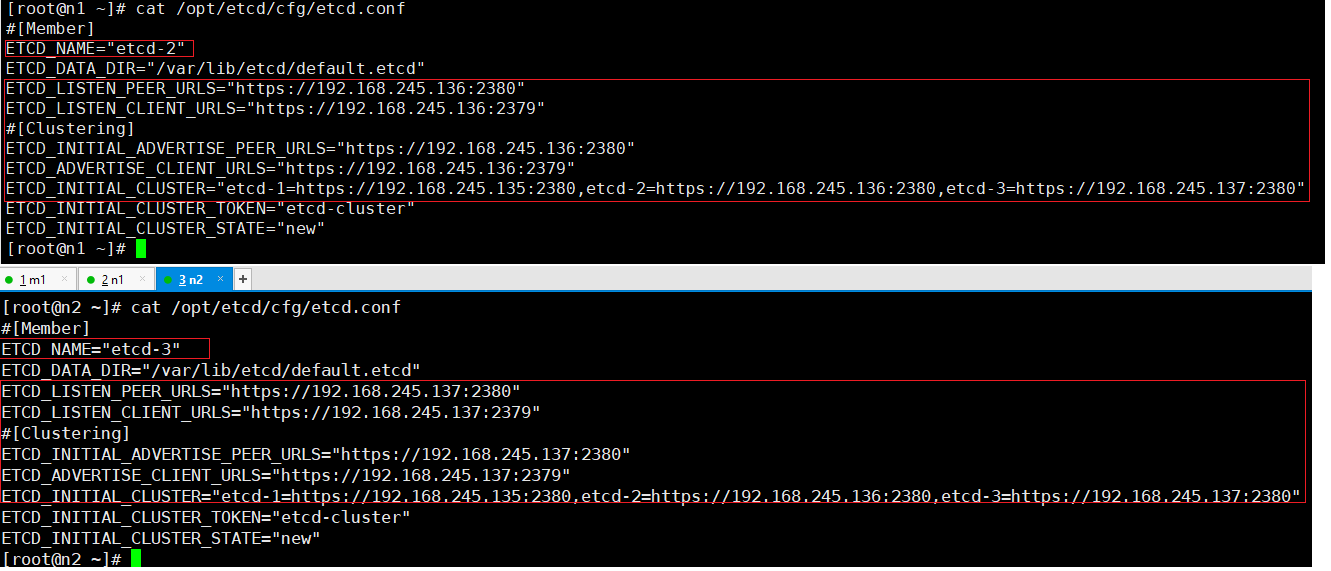
(8) 然后执行以下命令启动etcd服务器
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
(9) 查看集群状态
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.245.135:2379,https://192.168.245.136:2379,https://192.168.245.137:2379" endpoint status --write-out=table

注意:etcd启动失败的错误,大多数情况下都是与data-dir 有关系,data-dir 中记录的信息与 etcd启动的选项所标识的信息不太匹配造成的,有两种解决版办法:
- 删除data-dir文件(可以查看etcd的cfg文件夹中有一个etcd.conf文件,里面配置了DATA_DIR目录)
- 复制其他节点的data-dir的信息,以此为基础上以 --force-new-cluster 的形式强行拉起一个,然后以添加新成员的方式恢复这个集群,这是目前的几种解决办法
3.4.生成apiserver证书
cd TLS/k8s
############################
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
#################################
cat > ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
##########################
#生成证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -ls *pem
使用自签 CA 签发 kube-apiserver HTTPS 证书 创建证书申请文件:
cat > server-csr.json << EOF
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.245.135",
"192.168.245.136",
"192.168.245.137",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
ls server*pem
下载二进制文件
wget https://dl.k8s.io/v1.18.17/kubernetes-server-linux-arm64.tar.gz
解压二进制包
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
tar zxvf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
cp kube-apiserver kube-scheduler kube-controller-manager /opt/kubernetes/bin
cp kubectl /usr/bin/
部署kube-apiserver
cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF
> KUBE_APISERVER_OPTS="--logtostderr=false \\
> --v=2 \\
> --log-dir=/opt/kubernetes/logs \\
> --etcd-servers=https://192.168.245.135:2379,https://192.168.245.136:2379,https://192.168.245.137:2379 \\
> --bind-address=192.168.245.135 \\
> --secure-port=6443 \\
> --advertise-address=192.168.245.135 \\
> --allow-privileged=true \\
> --service-cluster-ip-range=10.0.0.0/24 \\
> --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\
> --authorization-mode=RBAC,Node \\
> --enable-bootstrap-token-auth=true \\
> --token-auth-file=/opt/kubernetes/cfg/token.csv \\
> --service-node-port-range=30000-32767 \\
> --kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \\
> --kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \\
> --tls-cert-file=/opt/kubernetes/ssl/server.pem \\
> --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \\
> --client-ca-file=/opt/kubernetes/ssl/ca.pem \\
> --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\
> --etcd-cafile=/opt/etcd/ssl/ca.pem \\
> --etcd-certfile=/opt/etcd/ssl/server.pem \\
> --etcd-keyfile=/opt/etcd/ssl/server-key.pem \\
> --audit-log-maxage=30 \\
> --audit-log-maxbackup=3 \\
> --audit-log-maxsize=100 \\
> --audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
> EOF
注:上面两个\ \ 第一个是转义符,第二个是换行符,使用转义符是为了使用 EOF 保留换 行符。
–logtostderr:启用日志
—v:日志等级
–log-dir:日志目录
–etcd-servers:etcd 集群地址
–bind-address:监听地址
–secure-port:https 安全端口
–advertise-address:集群通告地址
–allow-privileged:启用授权
–service-cluster-ip-range:Service 虚拟 IP 地址段
–enable-admission-plugins:准入控制模块
–authorization-mode:认证授权,启用 RBAC 授权和节点自管理
–enable-bootstrap-token-auth:启用 TLS bootstrap 机制
–token-auth-file:bootstrap token 文件
–service-node-port-range:Service nodeport 类型默认分配端口范围
–kubelet-client-xxx:apiserver 访问 kubelet 客户端证书
–tls-xxx-file:apiserver https 证书
–etcd-xxxfile:连接 Etcd 集群证书
–audit-log-xxx:审计日志
将配置文件拷贝到配置文件夹的路径中:
cp ~/TLS/k8s/ca*pem ~/TLS/k8s/server*pem /opt/kubernetes/ssl/
创建上述配置文件中token文件
cat > /opt/kubernetes/cfg/token.csv << EOF
74a577029316ec2d154df2df47a68679,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
格式:token,用户名,UID,用户组, token可自行替换
head -c 16 /dev/urandom | od -An -t x | tr -d ' '
systemd 管理 apiserver
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf
ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动并设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl enable kube-apiserver
systemctl status kube-apiserver
授权允许kubelet-bootstrap用户允许请求证书
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
4.安装Docker
4.1.下载docker
https://download.docker.com/linux/static/stable/x86_64/docker-19.03.9.tgz
(1)解压二进制包
tar zxvf docker-19.03.9.tgz
mv docker/* /usr/bin
(2) systemd 管理docker
cat > /usr/lib/systemd/system/docker.service << EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
(3) 创建配置文件
mkdir /etc/docker
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://vgiqiiwr.mirror.aliyuncs.com"]
}
EOF
(4) 启动并设置开机启动
systemctl daemon-reload
systemctl start docker
systemctl enable docker
5.部署master组件
需要kube-apiserver,kube-controller-manager,kube-scheduler,docker,etcd
前面已经安装了apiserver、docker、etcd 现在安装kube-controller-manager、kube-scheduler
5.1.部署kube-controller-manager
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect=true \\
--master=127.0.0.1:8080 \\
--bind-address=127.0.0.1 \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.244.0.0/16 \\
--service-cluster-ip-range=10.0.0.0/24 \\
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--experimental-cluster-signing-duration=87600h0m0s"
EOF
–master:通过本地非安全本地端口 8080 连接 apiserver。
–leader-elect:当该组件启动多个时,自动选举(HA)
–cluster-signing-cert-file/–cluster-signing-key-file:自动为 kubelet 颁发证书的 CA,与 apiserver 保持一致
systemd 管理 controller-manager
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf
ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动并设置开机启动
systemctl daemon-reload
systemctl start kube-controller-manager
systemctl enable kube-controller-manager
systemctl status kube-controller-manager
5.2.部署kube-scheduler
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF
KUBE_SCHEDULER_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--leader-elect \
--master=127.0.0.1:8080 \
--bind-address=127.0.0.1"
EOF
–master:通过本地非安全本地端口 8080 连接 apiserver。
–leader-elect:当该组件启动多个时,自动选举(HA)
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf
ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动并设置开启启动
systemctl daemon-reload
systemctl start kube-scheduler
systemctl enable kube-scheduler
systemctl status kube-scheduler

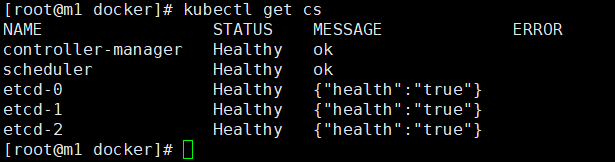
查看集群状态
kubectl get cs
授权kubelet-bootstrap用户允许请求证书
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
6.部署node组件
需要安装kubelet,kube-proxy,docker,etcd
将kubernetes-server-linux-amd64.tar.gz上传到136 和 137上
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
tar zxvg kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
cp kubelet kube-proxy /opt/kubernetes/bin
cp kubectl /usr/bin/
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=m1 \\
--network-plugin=cni \\
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\
--cert-dir=/opt/kubernetes/ssl \\
--pod-infra-container-image=lizhenliang/pause-amd64:3.0"
EOF
–hostname-override:显示名称,集群中唯一
–network-plugin:启用CNI
–kubeconfig:空路径,会自动生成,后面用于连接apiserver
–bootstrap-kubeconfig:首次启动向apiserver申请证书
–config:配置参数文件
–cert-dir:kubelet证书生成目录
–pod-infra-container-image:管理Pod网络容器的镜像
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
将master一些配置文件拷贝到node节点上
生成bootstrap.kubeconfig文件
apiVersion: v1
clusters:
- cluster:
certificate-authority: /opt/kubernetes/ssl/ca.pem
server: https://192.168.245.135:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubelet-bootstrap
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: kubelet-bootstrap
user:
token: 74a577029316ec2d154df2df47a68679
systemd管理kubelet
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
生成kube-proxy.kubeconfig文件
生成kube-proxy证书(在master上操作)
# 切换到工作目录
cd TLS/k8s
# 创建证书请求文件
cat > kube-proxy-csr.json << EOF {
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}]
}
EOF
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
# 生成 kubeconfig 文件:
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=https://192.168.245.135:6443 \
--kubeconfig=kube-proxy.config
kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# 拷贝到配置文件指定路径:
cp kube-proxy.kubeconfig /opt/kubernetes/cfg/
# 拷贝到node节点上
scp ca.pem kube-proxy*.pem root@192.168.245.136:/opt/kubernetes/ssl/
scp ca.pem kube-proxy*.pem root@192.168.245.137:/opt/kubernetes/ssl/
#systemd 管理 kube-proxy(在node上操作)
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 在node的/opt/kubernetes/cfg文件夹下
cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
EOF
# kube-proxy.conf
KUBE_PROXY_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
kube-proxy.conf
KUBE_PROXY_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
#kube-proxy-config.yml
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
address: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig
hostnameOverride: n2
clusterCIDR: 10.0.0.0/24
mode: ipvs
ipvs:
scheduler: "rr"
iptables:
masqueradeAll: true
# kube-proxy.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority: /opt/kubernetes/ssl/ca.pem
server: https://192.168.245.135:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubelet-bootstrap
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: kubelet-proxy
user:
client-certificate: /opt/kubernetes/ssl/kube-proxy.pem
client-key: /opt/kubernetes/ssl/kube-proxy-key.pem
systemctl daemon-reload
systemctl start kube-proxy
systemctl enable kube-proxy
查看请求证书(master)
kubectl get csr

批准申请
kubectl certificate approve "上面查看请求证书中NAME中的值"
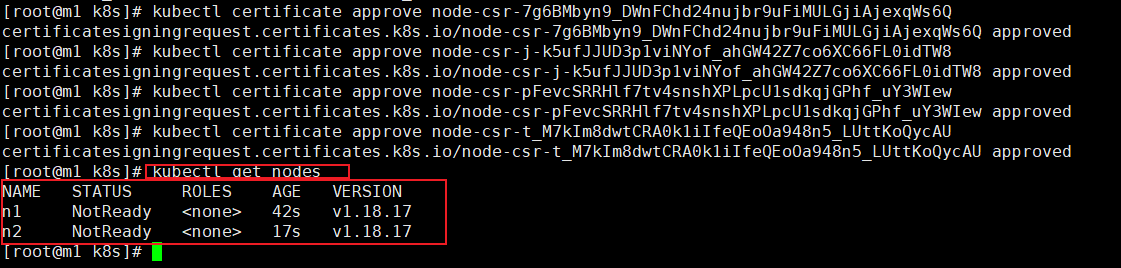
可以看到加入到当前节点的n1 n2
7.部署集群网络CNI插件
wget https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-amd64-v0.8.6.tgz
mkdir /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
执行
kubectl apply -f kube-flannel.yml
这里将文件上传到了master的root目录
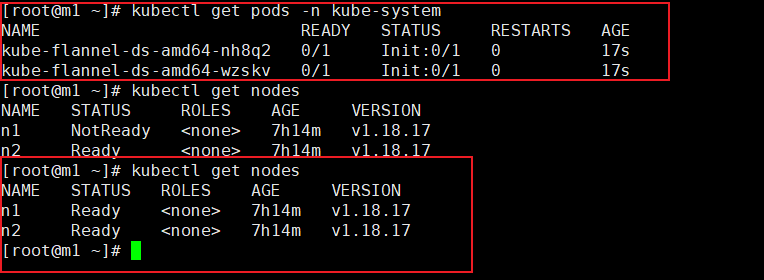
成功,CNI也搭建好了!!!
如果出现一下情况

可以执行一下命令
# 查看日志
kubectl logs kube-flannel-ds-amd64-nh8q2(这里是上面的NAME) -n kube-system
# 得到如下信息
error: You must be logged in to the server (the server has asked for the client to provide credentials ( pods/log kube-flannel-ds-amd64-nh8q2))
kubelet配置文件配置默认用户权限如下
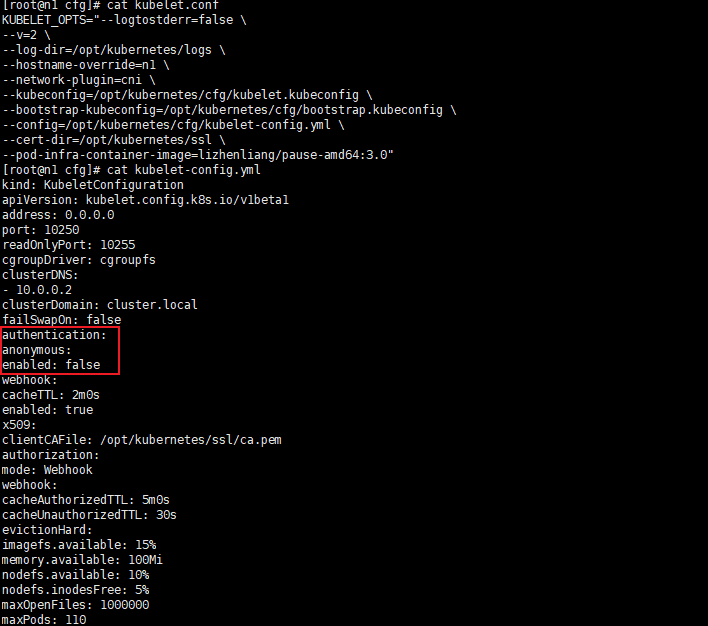
处理方法
anonymous用户绑定一个cluster-admin的权限
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
测试kubernetes集群
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
4.Kubeadm和二进制方式对比
Kubeadm方式搭建K8S集群
- 安装虚拟机,在虚拟机安装Linux操作系统【3台虚拟机】
- 对操作系统初始化操作
- 所有节点安装Docker、kubeadm、kubelet、kubectl【包含master和slave节点】
- 安装docker、使用yum,不指定版本默认安装最新的docker版本
- 修改docker仓库地址,yum源地址,改为阿里云地址
- 安装kubeadm,kubelet 和 kubectl
- k8s已经发布最新的1.19版本,可以指定版本安装,不指定安装最新版本
yum install -y kubelet kubeadm kubectl
- 在master节点执行初始化命令操作
kubeadm init- 默认拉取镜像地址 K8s.gcr.io国内地址,需要使用国内地址
- 安装网络插件(CNI)
kubectl apply -f kube-flannel.yml
- 在所有的node节点上,使用join命令,把node添加到master节点上
- 测试kubernetes集群
二进制方式搭建K8S集群
- 安装虚拟机和操作系统,对操作系统进行初始化操作
- 生成cfssl 自签证书
ca-key.pem、ca.pemserver-key.pem、server.pem
- 部署Etcd集群
- 部署的本质,就是把etcd集群交给 systemd 管理
- 把生成的证书复制过来,启动,设置开机启动
- 为apiserver自签证书,生成过程和etcd类似
- 部署master组件,主要包含以下组件
- apiserver
- controller-manager
- scheduler
- 交给systemd管理,并设置开机启动
- 如果要安装最新的1.19版本,下载二进制文件进行安装
- 部署node组件
- docker
- kubelet
- kube-proxy【需要批准kubelet证书申请加入集群】
- 交给systemd管理组件- 组件启动,设置开机启动
- 批准kubelet证书申请 并加入集群
- 部署CNI网络插件
- 测试Kubernets集群【安装nginx测试】
三、kubernetes核心技术
k8s集群命令行工具kubectl
1、kubectl概述
kubectl 是 是 s Kubernetes 集群的命令行工具,通过 kubectl 能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。
2、kubectl命令的语法
kubectl [command] [TYPE] [NAME] [flags]
(1) command: 指定要对资源的操作,如:create、get、describe和delte
(2) TYPE:指定资源类型,资源类型是大小写敏感的,开发中能够以单数、负数和缩略的形式,例如:
kubectl get pod pod1
kubectl get pods pod1
kubectl get po pod1
(3) NAME:指定资源的名称,名称也大小写敏感。如果省略名称,则会显示所有的资源,例如
kubectl get pods
(4) flagsL指定可选的参数。例如,可用-s或者-server参数指定Kubernetes API server的地址和端口
3、kubectl help获取更多信息
kubectl --help
Basic Commands (Beginner):
create Create a resource from a file or from stdin.
expose 使用 replication controller, service, deployment 或者 pod 并暴露它作为一个 新的 Kubernetes
Service
run 在集群中运行一个指定的镜像
set 为 objects 设置一个指定的特征
Basic Commands (Intermediate):
explain 查看资源的文档
get 显示一个或更多 resources
edit 在服务器上编辑一个资源
delete Delete resources by filenames, stdin, resources and names, or by resources and label selector
Deploy Commands:
rollout Manage the rollout of a resource
scale Set a new size for a Deployment, ReplicaSet or Replication Controller
autoscale 自动调整一个 Deployment, ReplicaSet, 或者 ReplicationController 的副本数量
Cluster Management Commands:
certificate 修改 certificate 资源.
cluster-info 显示集群信息
top Display Resource (CPU/Memory/Storage) usage.
cordon 标记 node 为 unschedulable
uncordon 标记 node 为 schedulable
drain Drain node in preparation for maintenance
taint 更新一个或者多个 node 上的 taints
Troubleshooting and Debugging Commands:
describe 显示一个指定 resource 或者 group 的 resources 详情
logs 输出容器在 pod 中的日志
attach Attach 到一个运行中的 container
exec 在一个 container 中执行一个命令
port-forward Forward one or more local ports to a pod
proxy 运行一个 proxy 到 Kubernetes API server
cp 复制 files 和 directories 到 containers 和从容器中复制 files 和 directories.
auth Inspect authorization
Advanced Commands:
diff Diff live version against would-be applied version
apply 通过文件名或标准输入流(stdin)对资源进行配置
patch 使用 strategic merge patch 更新一个资源的 field(s)
replace 通过 filename 或者 stdin替换一个资源
wait Experimental: Wait for a specific condition on one or many resources.
convert 在不同的 API versions 转换配置文件
kustomize Build a kustomization target from a directory or a remote url.
Settings Commands:
label 更新在这个资源上的 labels
annotate 更新一个资源的注解
completion Output shell completion code for the specified shell (bash or zsh)
Other Commands:
alpha Commands for features in alpha
api-resources Print the supported API resources on the server
api-versions Print the supported API versions on the server, in the form of "group/version"
config 修改 kubeconfig 文件
plugin Provides utilities for interacting with plugins.
version 输出 client 和 server 的版本信息
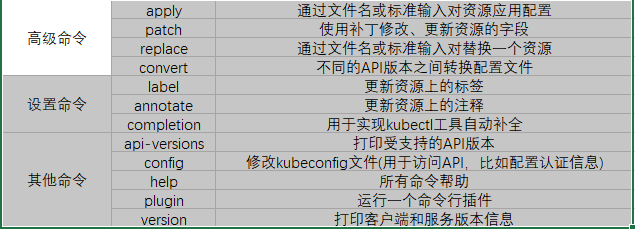
4、kubectl子命令使用分类
(1)基础命令

(2)部署和集群管理命令

(3)故障和调试命令

(4)其他命令
资源编排(YAML)文件
1、概述
k8s集群中资源管理和资源对象编排部署都可以通过声明样式(YAML)文件来解决,也就是可以把需要对资源对象操作编辑到YAML格式文件中,我们把这种资源清单文件,通过kubectl命令直接使用资源清单文件就可以实现对大量资源对象进行编排部署了
2、YAML文件书写格式
(1) YAML介绍
YAML:仍是一种标记语言。为了强调这种以数据作为中心,而不是以标记语言为重点。YAML是一个可读性高,用来表达数据序列的格式。
(2) YAML基本语法
- 使用空格作为缩进
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 低版本缩进时不允许使用Tab键,只允许使用空格
- 使用#标识注释,从这个字符一直到行尾,都会被解释器忽略
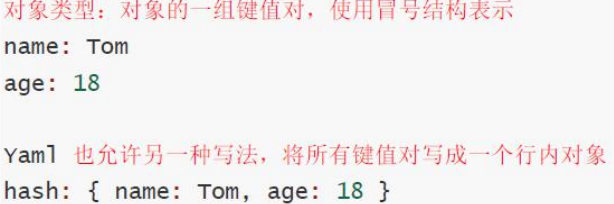
(3) YAML支持的数据结构
-
对象
键值对的集合,又称为映射(mapping)/哈希(hashes)/字典(dictionary)
-
数组
一组按次序排列的值,又称为序列(sequence) / 列表 (list)

-
纯量(scalars)
单个的、不可再分的值

3、资源清单描述方法
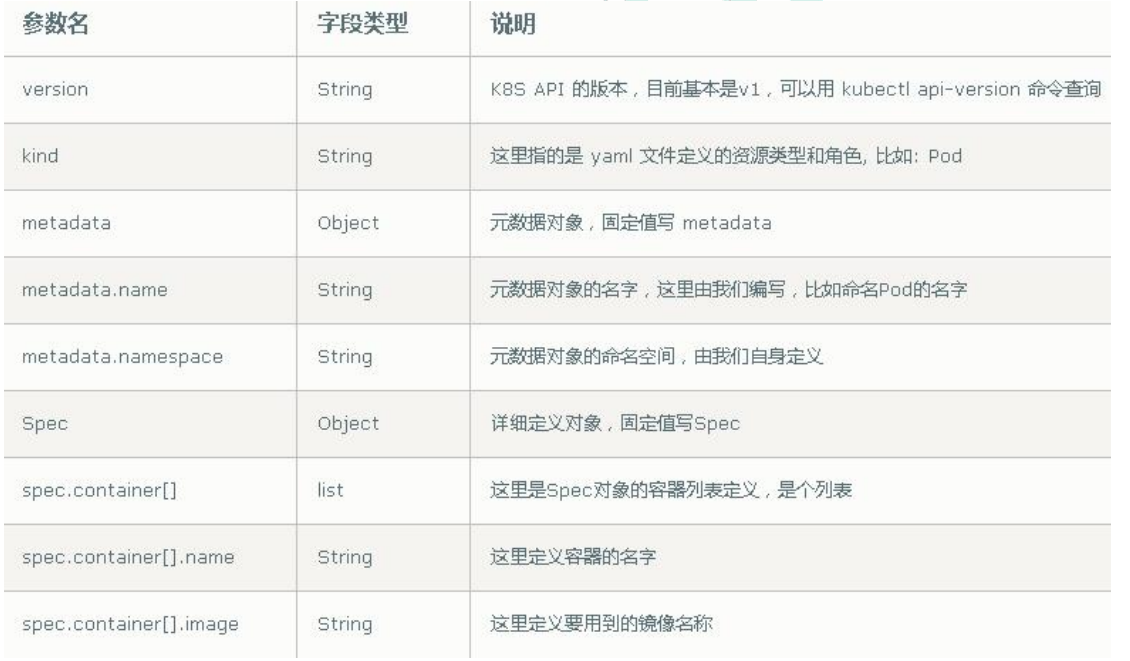
(1)在k8s中,一般使用YAML格式的文件来创建符合我们预期期望的Pod,这样的YAML文件称为资源清单
(2)必须存在的属性
(3)spec主要对象
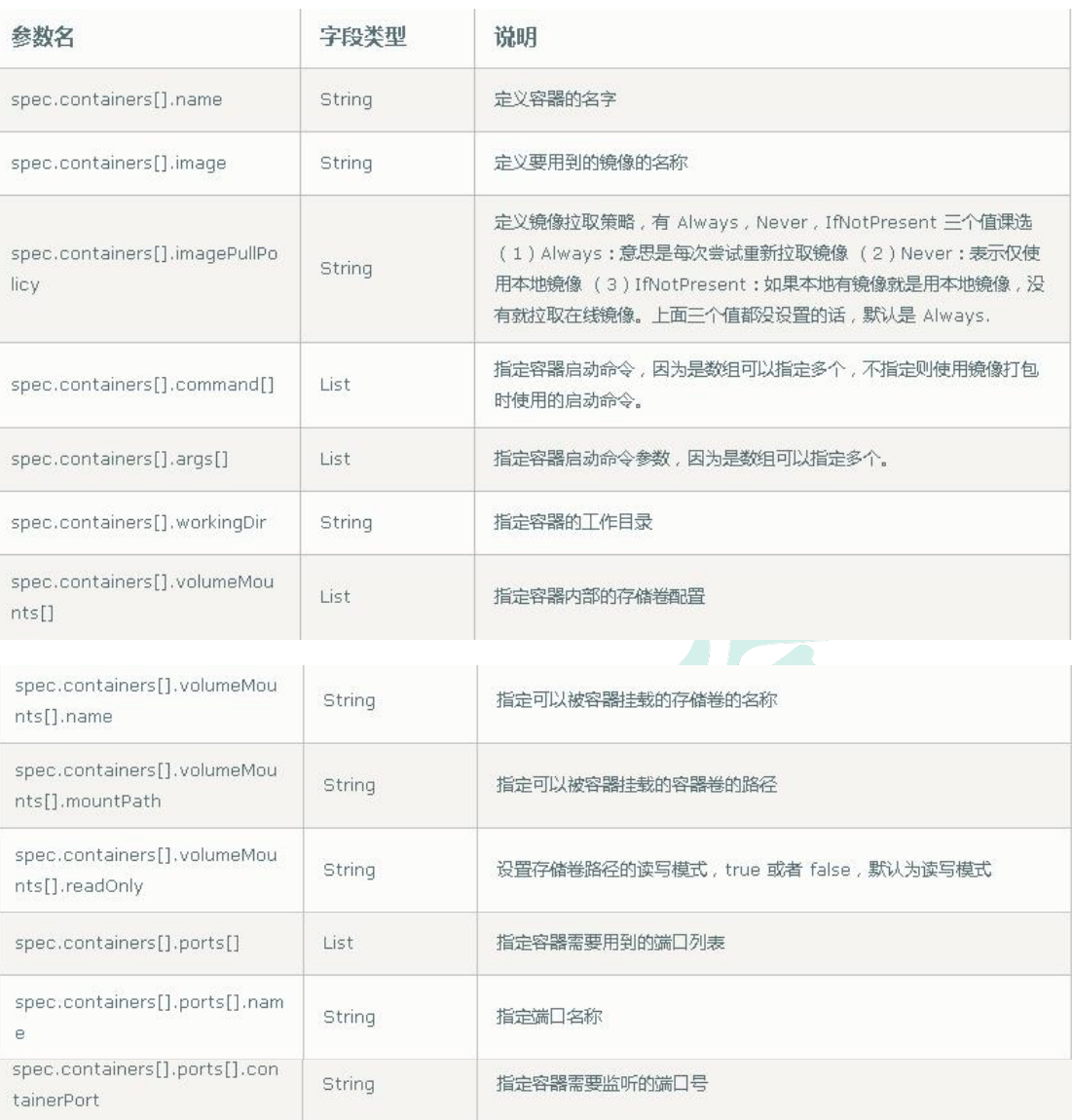
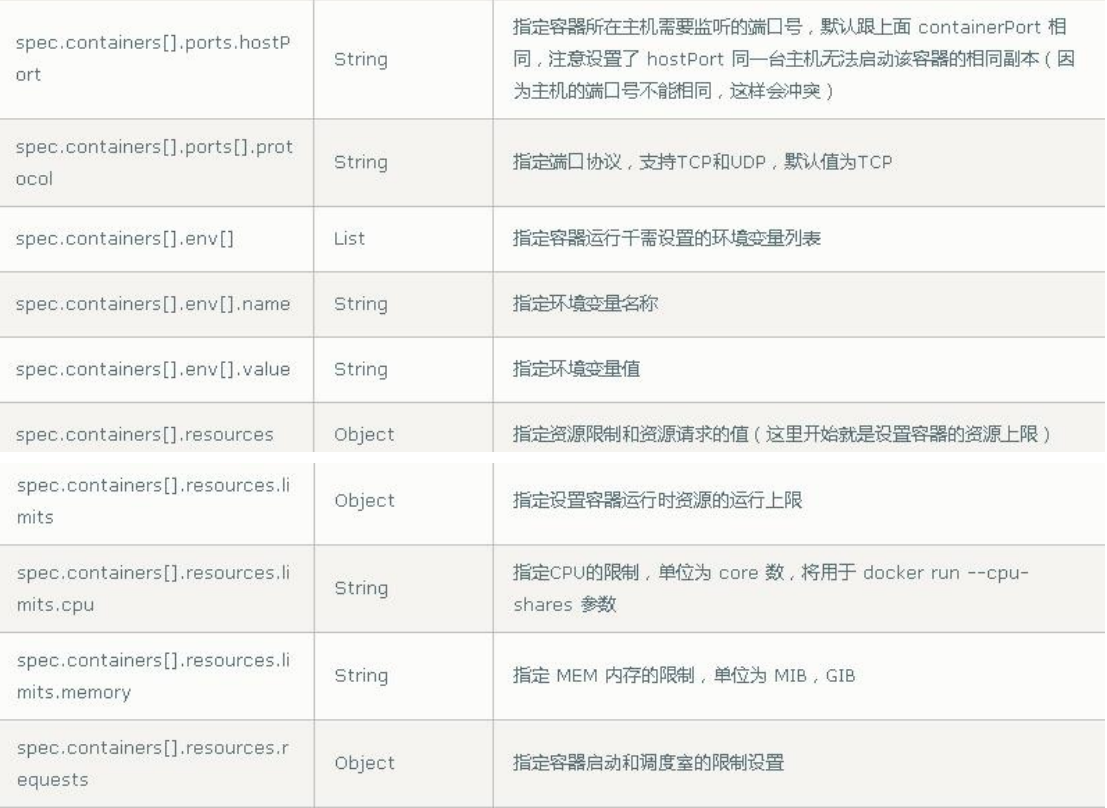
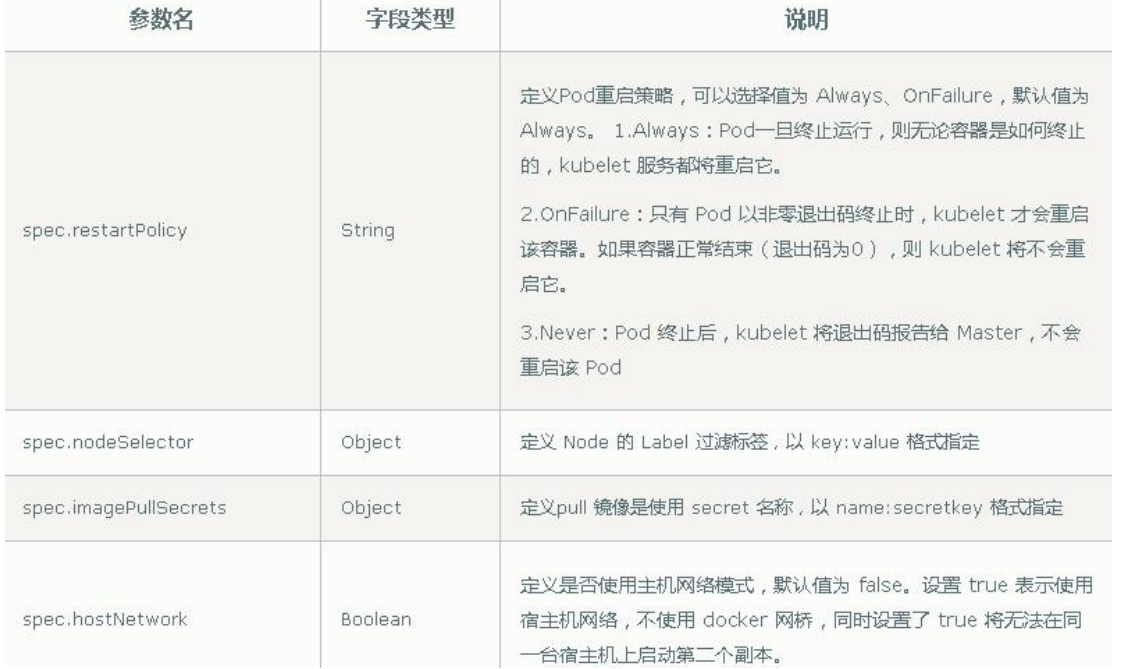
(4)额外的参数
(5)举例说明
-
创建一个namespace
apiVersion: V1 kind: Namespace metadata: name: test -
创建一个pod
apiversion: v1 kind: Pod metadata: name: pod1 spec: containers: - name: nginx-containers image: nginx:latest
YAML文件组成部分
主要分为两部分,一个是控制器的定义和被控制的对象
控制器定义

被控制对象
包含一些镜像、版本、端口等
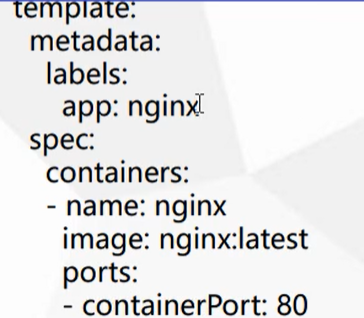
属性说明
在一个YAML文件的控制器定义中,有很多属性名称
| 属性名称 | 介绍 |
|---|---|
| apiVersion | API版本 |
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | Pod模板 |
| metadata | Pod元数据 |
| spec | Pod规格 |
| containers | 容器配置 |
如何快速编写YAML文件
一般来说,我们很少自己手写YAML文件,因为这里面涉及到了很多内容,我们一般都会借助工具来创建
使用kubectl create命令
这种方式一般用于资源没有部署的时候,我们可以直接创建一个YAML配置文件
# 尝试运行,并不会真正的创建镜像
kubectl create deployment web --image=nginx -o yaml --dry-run
或者我们可以输出到一个文件中
kubectl create deployment web --image=nginx -o yaml --dry-run > hello.yaml
然后我们就在文件中直接修改即可
使用kubectl get命令导出yaml文件
kubectl get deploy nginx -o=yaml --export > nginx.yaml

k8s核心技术——Pod
1、概述
Pod 是 k8s 系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在 k8s 上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展 Pod 对象功能的,比如控制器对象是用来管控 Pod 对象的,Service 或者Ingress 资源对象是用来暴露 Pod 引用对象的,PersistentVolume 资源对象是用来为 Pod提供存储等等,k8s 不会直接处理容器,而是 Pod,Pod 是由一个或多个 container 组成。
Pod 是 Kubernetes 的最重要概念,每一个 Pod 都有一个特殊的被称为”根容器“的 Pause容器。Pause 容器对应的镜 像属于 Kubernetes 平台的一部分,除了 Pause 容器,每个 Pod还包含一个或多个紧密相关的用户业务容器

(1)Pod vs 应用
每个pod都是应用的一个实例,有专用的IP
(2)Pod vs 容器
一个Pod可以由多个容器,彼此间共享网络和存储资源,每个Pod中有一个Pause容器保存所有的容器状态,通过管理pause容器,达到管理pod中所有容器的效果
(3)Pod vs 节点
同一个Pod中的容器总会被调度到相同Node节点,不同节点间Pod的通行基于虚拟二层网络技术实现
(4)Pod vs Pod
不同的Pod和静态Pod
2、Pod特性
资源共享
一个 Pod 里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如namespace,cgroups 或者其他的隔离资源。
多个容器共享同一 network namespace,由此在一个 Pod 里的多个容器共享 Pod 的 IP 和端口 namespace,所以一个 Pod 内的多个容器之间可以通过 localhost 来进行通信,所需要注意的是不同容器要注意不要有端口冲突即可。不同的 Pod 有不同的 IP,不同 Pod 内的多个容器之前通信,不可以使用 IPC(如果没有特殊指定的话)通信,通常情况下使用 Pod的 IP 进行通信。
一个 Pod 里的多个容器可以共享存储卷,这个存储卷会被定义为 Pod 的一部分,并且可以挂载到该 Pod 里的所有容器的文件系统上。
生命周期短暂
Pod 属于生命周期比较短暂的组件,比如,当 Pod 所在节点发生故障,那么该节点上的 Pod会被调度到其他节点,但需要注意的是,被重新调度的 Pod 是一个全新的 Pod,跟之前的Pod 没有半毛钱关系。
平坦的网络
K8s 集群中的所有 Pod 都在同一个共享网络地址空间中,也就是说每个 Pod 都可以通过其他 Pod 的 IP 地址来实现访问。
3、Pod基本概念
- 最小部署的单元
- Pod里面是由一个或多个容器组成【一组容器的集合】
- 一个pod中的容器是共享网络命名空间
- Pod是短暂的
- 每个Pod包含一个或多个紧密相关的用户业务容器
4、Pod存在的意义
-
创建容器使用docker,一个docker对应一个容器,一个容器运行一个应用进程
-
Pod是多进程设计,运用多个应用程序,也就是一个Pod里面有多个容器,而一个容器里面运行一个应用程序

- Pod的存在是为了亲密性应用
- 两个应用之间进行交互
- 网络之间的调用【通过127.0.0.1 或 socket】
- 两个应用之间需要频繁调用
Pod是在K8S集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。同时Pod对多容器的支持是K8S中最基础的设计理念。在生产环境中,通常是由不同的团队各自开发构建自己的容器镜像,在部署的时候组合成一个微服务对外提供服务。
Pod是K8S集群中所有业务类型的基础,可以把Pod看作运行在K8S集群上的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前K8S的业务主要可以分为以下几种:
- 长期伺服型:long-running
- 批处理型:batch
- 节点后台支撑型:node-daemon
- 有状态应用型:stateful application
上述的几种类型,分别对应的小机器人控制器为:Deployment、Job、DaemonSet 和 StatefulSet (后面将介绍控制器)
5、Pod实现机制
主要有一下两大机制
- 共享网络
- 共享存储
共享网络
容器本身之间相互隔离的,一般是通过 namespace 和 group 进行隔离,那么Pod里面的容器如何实现通信?
- 首先需要满足前提条件,也就是容器都在同一个namespace之间
关于Pod实现共享网络机制,首先会在Pod会创建一个根容器: pause容器,然后我们在创建业务容器 【nginx,redis 等】,在我们创建业务容器的时候,会把它添加到 info容器 中而在 info容器 中会独立出 ip地址,mac地址,port 等信息,然后实现网络的共享
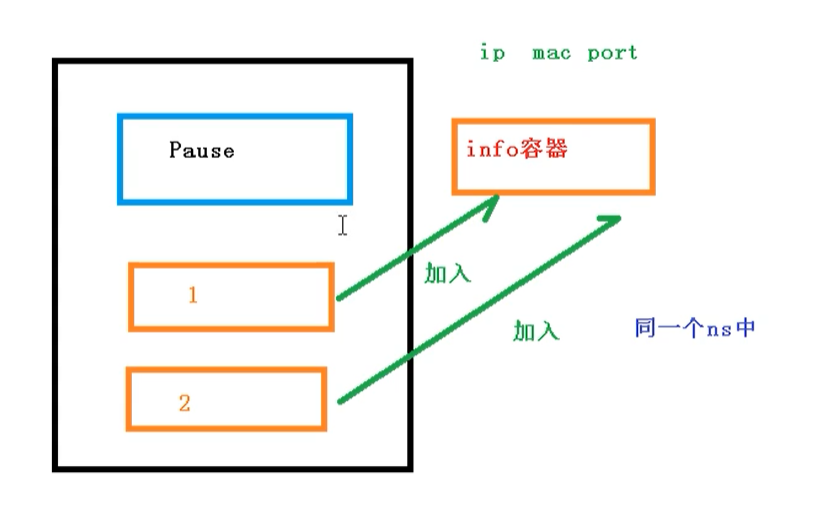
完整步骤如下
- 通过 Pause 容器,把其它业务容器加入到Pause容器里,让所有业务容器在同一个名称空间中,可以实现网络共享
共享存储
Pod持久化数据,专门存储到某个地方中
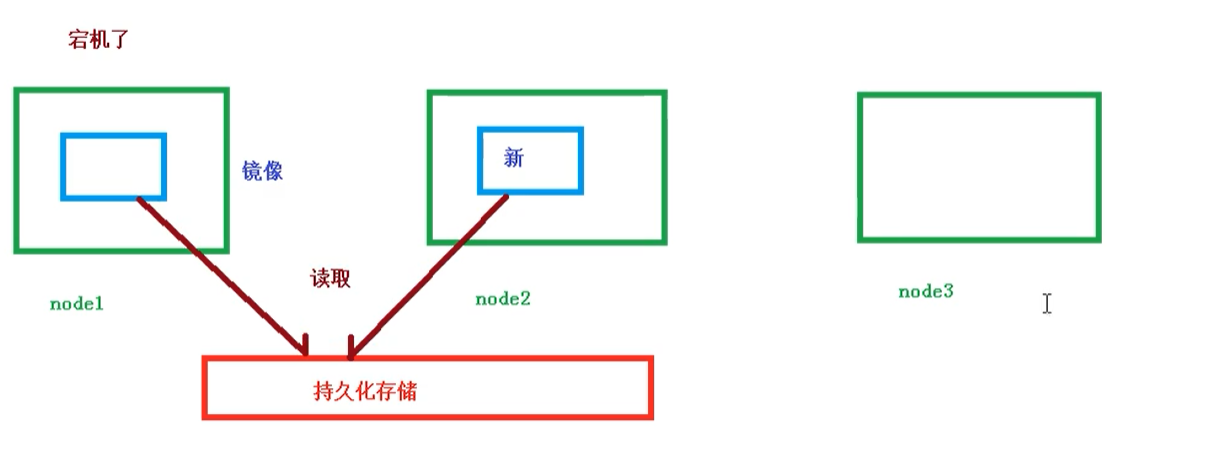
使用 Volumn数据卷进行共享存储,案例如下所示

6、Pod镜像拉取策略
用实例来说明,拉取策略就是imagePullPolicy
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx:1.14
imagePullPolicy: Always
拉取策略主要分为一下几种:
- ifNotPresent: 默认值,镜像在宿主机上不存在在拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Never:Pod永远不会拉取这个镜像
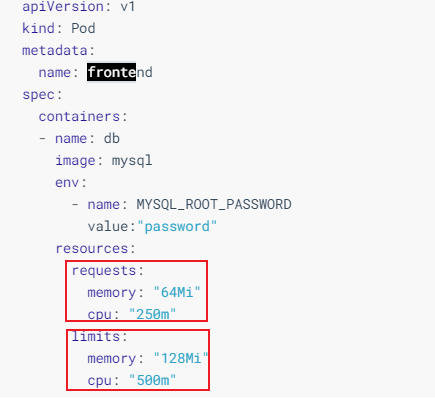
7、Pod资源限制
也就是我们Pod在进行调度的时候,可以对调度的资源进行限制,例如我们限制 Pod调度是使用的资源是 2C4G,那么在调度对应的node节点时,只会占用对应的资源,对于不满足资源的节点,将不会进行调度
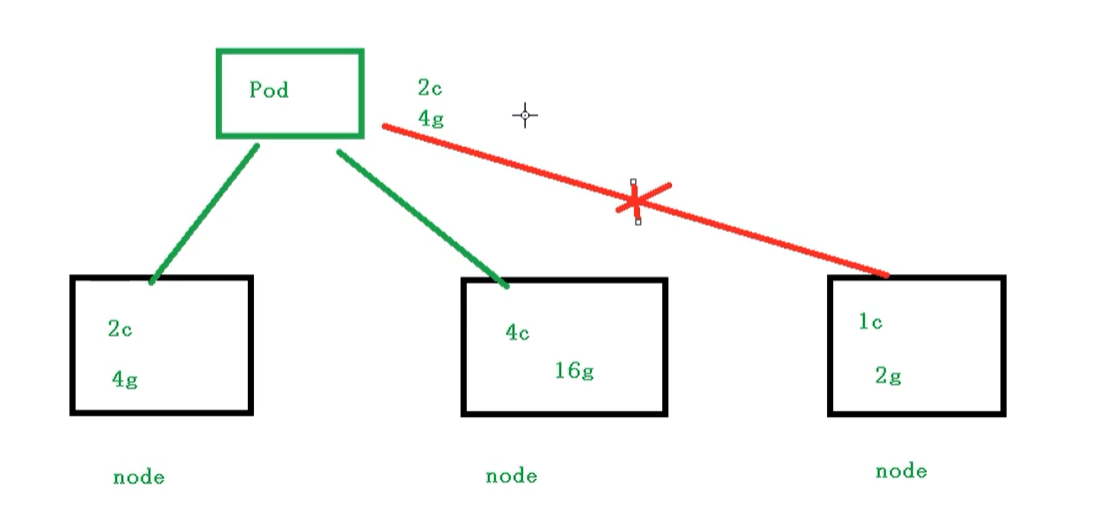
示例
我们在下面的地方进行资源的限制
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value:"password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
这里分为了两部分
- requests:表示调度所需要的资源
- linits:表示最大所占用的资源
8、Pod重启机制
因为Pod中包含了很多个容器,假设某个容器出现问题了,那么就会触发Pod重启机制
apiVersion: v1
kind: Pod
metadata:
name: dns-tes
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never
重启策略主要分为一下三种
- Always:当容器终止退出后,总是重启容器,默认策略【Nginx等,需要不断提供服务】
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器
- Never:当容器终止退出时,从不重启容器【批量任务】
9、Pod健康检查
通过容器检查,原来我们使用下面的命令来检查
kubectl get pod
但是有的时候,程序可能出现了 Java 堆内存溢出,程序还在运行,但是不能对外提供服务了,这个时候就不能通过 容器检查来判断服务是否可用了
这个时候就可以使用应用层面的检查
# 存活检查,如果检查失败,将杀死容器,根据Pod的restartPolicy【重启策略】来操作
livenessProbe
# 就绪检查,如果检查失败,Kubernetes会把Pod从Service endpoints中剔除
readinessProbe
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy;sleep 30;rm -rf /tmp/healthy
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initalDelaySeconds: 5
periodSeconds: 5
Probe支持以下三种检查方式:
- http Get:发送HTTP请求,返回200-400范围状态码为成功
- exec:执行shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
10、Pod调度策略
创建Pod流程
- 首先创建一个pod,然后创建一个API Server和Etcd【把床架你出来的信息存储到Etcd中】
- 然后创建Scheduler,监控API Server是否有新的Pod,如果有的话,会通过调度算法,把Pod调度某个node上
- 在node节点,会通过kubelet --apiserver读取到etcd 拿到分配在当前node节点上的pod,然后通过docker来创建容器
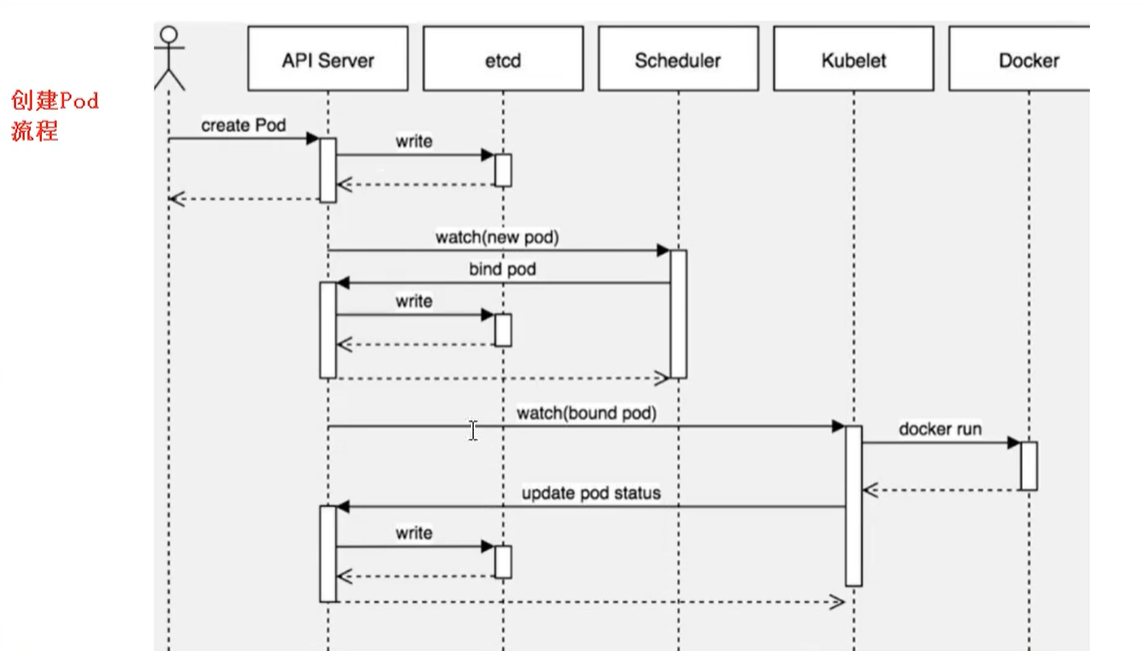
影响Pod调度的属性
Pod资源限制对Pod的调度会有影响
根据requests找到足够node节点进行调度
节点选择器标签影响Pod调度
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
nodeSelector:
env_role: dev
containers:
- name: nginx
image: nginx:1.15
nodeSelector:
env_role: dev
上面这段yaml会影响pod调度
关于节点选择器,其实就是有两个环境,然后环境之间说用的资源配置不同
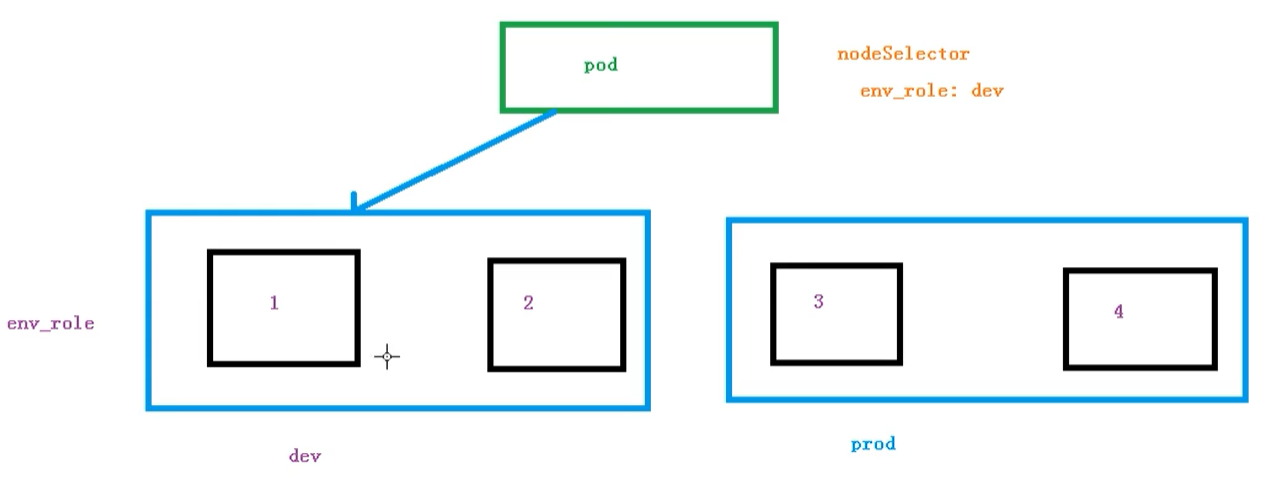
我们可以通过以下命令,给我们的节点新增标签,然后节点选择器就会进行调度了
kubectl label node node1 env_role=prod
节点亲和性
节点亲和性nodeAffinity和之前nodeSelector基本一样,根据节点上标签约束来决定Pod调度到哪些节点上
- 硬亲和性:约束条件必须满足
- 软亲和性:尝试满足,不保证

支持常用操作符:IN、NotIn、Exists、Gt、Lt、DoesNotExists
反亲和性:就是和亲和性刚刚相反,如 NotIn、DoesNotExists等
11、污点和污点容忍
概述
nodeSelector和NodeAffinity,都是Pod调度到某些节点上,属于Pod的属性,是在调度的时候实现的。
Taint污点:节点不做普通分配调度,是节点属性
场景
- 专用节点【限制ip】
- 配置特定硬件的节点【固态硬盘】
- 基于Tain驱逐【在node1不放,在node2放】
查看污点情况
kubectl describe node n1 | grep Taint

污点值有三个
- NoSchedule:一定不会被调度
- PerferNoSchedule:尽量不被调度【也有被调度的几率】
- NoExcute:不会调度,并且会驱逐Node已有Pod
为节点添加污点
kubectl taint node [node] key=value:污点的三个值
举例
kubectl tain node k8snode1 env_role=yes;NoSchedule
删除污点
kubectl taint node k8snode1 env_role:NoSchedule-

演示
我们现在创建多个Pod,查看最后分配到Node上的情况
首先我们创建一个nginx的pod
kubectl create deployment web --image=nginx
然后使用命令查看
kubectl get pods -o wide

可以看到,这个Pod已经被分配到k8snode1节点上了
我们把pod复制5份,在查看pod情况
kubectl scale deployment web --replicas=5
我们可以发现,因为master节点存在污点的情况,所以节点都被分配到了 node1 和 node2节点上

可以使用下面命令,把刚刚我们创建的pod都删除
kubectl delete deployment web
现在给了更好的演示污点的用法,我们现在给node1节点打上污点
kubectl taint node k8snode1 env_role=yew:NoSchedule
然后查看污点是否成功添加
kubectl describe node k8snode1 | grep Taint

然后我们在创建一个pod
# 创建nginx pod
kubectl create deployment web --image=nginx
# 复制五次
kubectl scale deployment web --replicas=5
然后再进行查看
kubectl get pods -o wide
我们能够看到现在所有的pod都被分配到了 k8snode2上,因为刚刚我们给node1节点设置了污点

最后我们可以删除刚刚添加的污点
kubectl taint node k8snode1 env_role:NoSchedule-
污点容忍
污点容忍就是某个节点可能被调度,也可能不被调度
spec:
tolerations:
- key: "keys"
operator: "Equal"
value: "value"
effect: "NoSchedule"
containers:
- name: webdemo
image: nginx
k8s核心技术——Controller
什么是Controller
Controller是在集群上管理和运行容器的对象,Controller是实际存在的,Pod是虚拟机
Pod和Controller的关系
Pod是通过Controller实现应用运维,比如弹性伸缩,滚动升级等
Pod和Controller之间是通过label标签来建立关系,同时Controller又被称为控制器工作负载
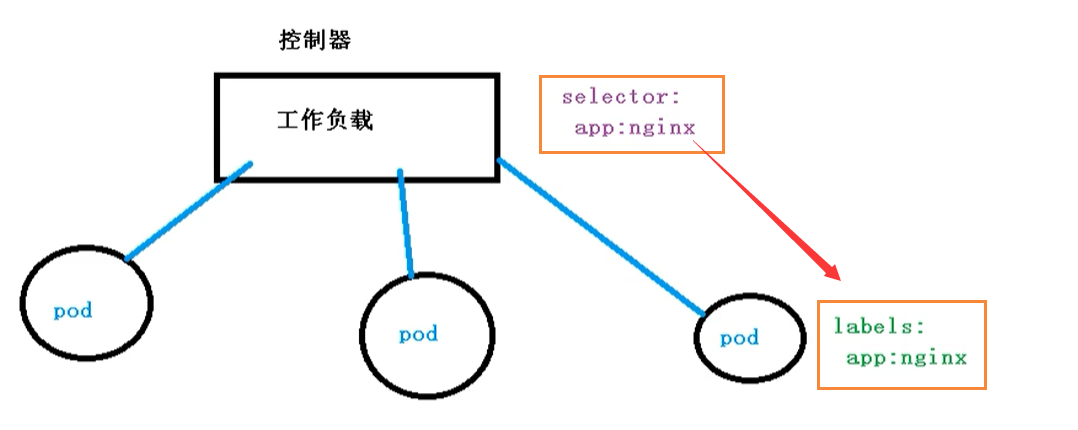
Deployment控制器应用
- Deployment控制器可以部署无状态应用
- 管理Pod和ReplicaSet
- 部署,滚动升级等功能
- 应用场景:web服务,微服务
Deployment表示用户对k8s集群的一次更新操作。Deployment是一个比RS(Replica Set,RS)应用模型更广的API对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。滚动审计一个服务,实际是创建一个新的RS,然后逐渐将新RS中副本数增加到理想状态,将就RS中的副本数减少到0的符合操作。
这样一个符合操作用一个RS是不好描述的,所以用一个更通用的Deployment来描述。以k8s的发展方向,未来对有长期伺服型的业务的管理,都会通过Deployment来管理。
Deployment部署应用
之前我们也使用Deployment部署引用,如一下代码
kubectl create deployment web --image=nginx
但是上述代码不能进行很好的复用,因为每次我们都需要重新输入代码,所以都是通过YAML进行配置的,我们可以尝试使用上面的代码创建爱你一个镜像【只是尝试,不会创建】
kubectl create deployment web --image=nginx --dry-run -o yam l> nginx.yaml
然后输出一个yaml配置文件nginx.yml,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
可以看到selector和label就是我们Pod和Controller之间建立关系的桥梁
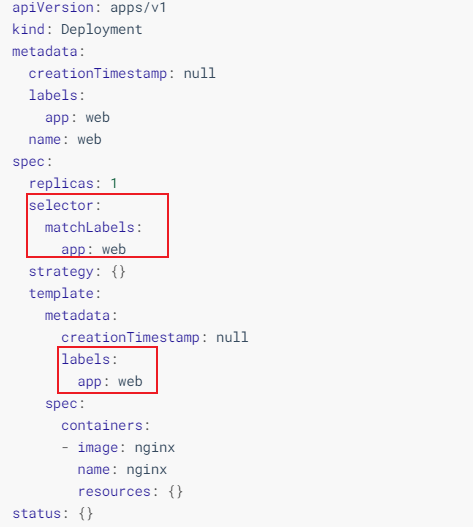
使用yaml创建Pod
通过刚刚的代码,已经生成了YAML文件,下面我们就可以使用该配置文件快速创建Pod镜像了。
kubectl apply -f nginx.yaml

但是因为这个方式创建的Pod,只能在集群内部进行访问,所需还需要对外暴露端口
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1
参数解释:
- -- port:就是我们内部的端口号
- --target:就是暴露外面访问的端口号
- --name:名称
- --type:类型
同理,我们可以导出对应的配置文件
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web -o yaml > web1.yaml
得到的web1.yaml如下
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2021-04-09T09:43:51Z"
labels:
app: web
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:labels:
.: {}
f:app: {}
f:spec:
f:externalTrafficPolicy: {}
f:ports:
.: {}
k:{"port":80,"protocol":"TCP"}:
.: {}
f:port: {}
f:protocol: {}
f:targetPort: {}
f:selector:
.: {}
f:app: {}
f:sessionAffinity: {}
f:type: {}
manager: kubectl
operation: Update
time: "2021-04-09T09:43:51Z"
name: web
namespace: default
resourceVersion: "101563"
selfLink: /api/v1/namespaces/default/services/web
uid: 69ce8d91-df14-42b2-8a7c-c953f6783090
spec:
clusterIP: 10.97.53.171
externalTrafficPolicy: Cluster
ports:
- nodePort: 30576
port: 80
protocol: TCP
targetPort: 80
selector:
app: web
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
然后我们可以通过下面你的命令来查看对外暴露的服务
kubectl get pods,svc
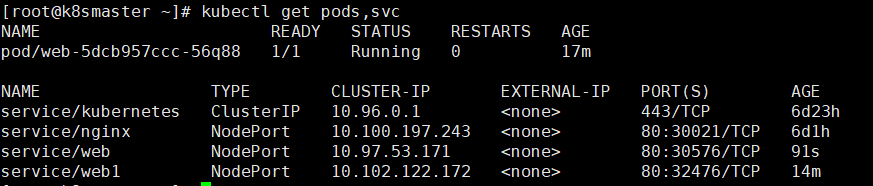
进行访问192.168.245.132:32476
升级回滚和弹性伸缩
- 升级: 假设从版本为1.14 升级到 1.15 ,这就叫应用的升级【升级可以保证服务不中断】
- 回滚:从版本1.15 变成 1.14,这就叫应用的回滚
- 弹性伸缩:我们根据不同的业务场景,来改变Pod的数量对外提供服务,这就是弹性伸缩
应用升级和回滚
首先我们先创建一个 1.14版本的Pod
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.14
name: nginx
resources: {}
status: {}
执行以下命令,创建Pod
kubectl apply -f nginx.yaml
这样,使用docker images命令,就能看到成功拉取到1.14版本镜像
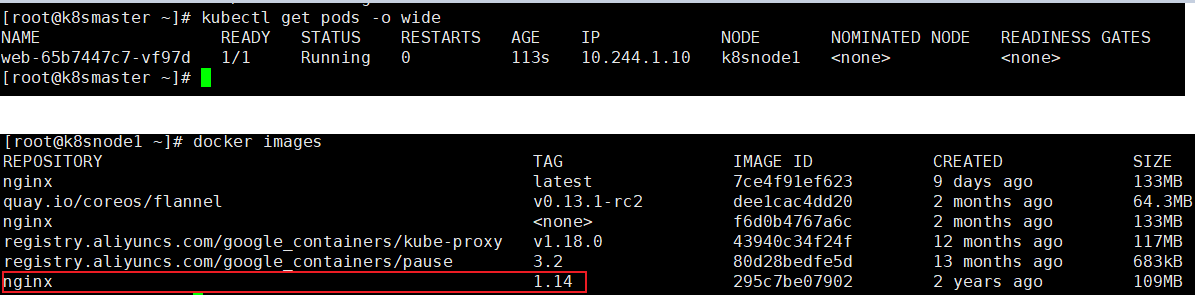
使用以下命令进行升级
kubectl set image deployment web nginx=nginx:1.5
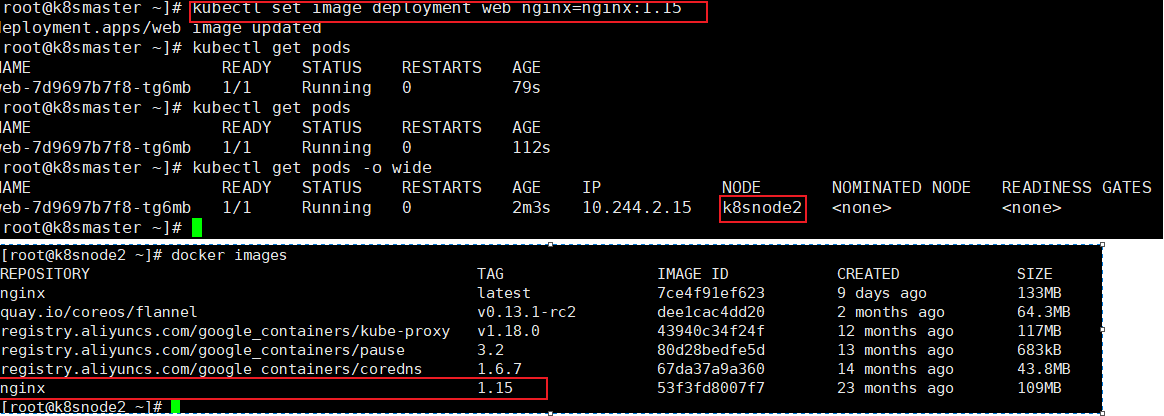
- 首先是开始的nginx 1.14版本的Pod在运行,然后 1.15版本的在创建
- 然后在1.15版本创建完成后,就会暂停1.14版本
- 最后把1.14版本的Pod移除,完成我们的升级
我们在下载 1.15版本,容器就处于ContainerCreating状态,然后下载完成后,就用 1.15版本去替换1.14版本了,这么做的好处就是:升级可以保证服务不中断
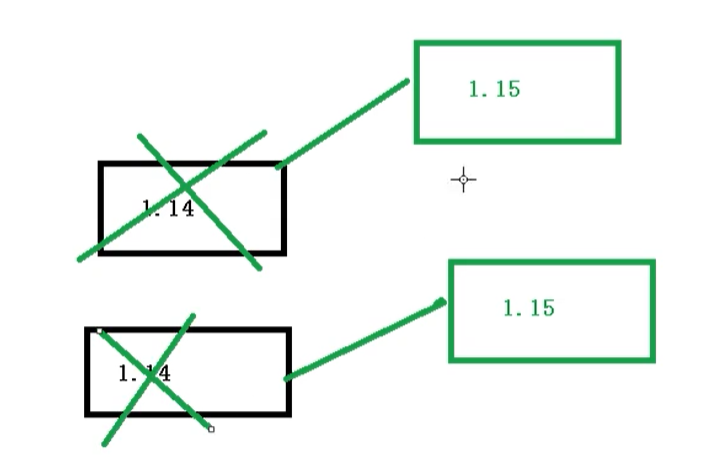
从上面的图可以看到,已经成功拉取到1.15版本的nginx了
查看升级状态
以下命令可以查看升级状态
kubectl rollout status deployment web

查看历史版本
kubectl rollout history deployment web
应用回滚
回滚到上一个版本
kubectl rollout undo deployment wb
然后查看状态
kubectl rollout status deployment web
同时我们还可以回滚到指定版本
kubectl rollout undo deployment web --to-version=2
弹性伸缩
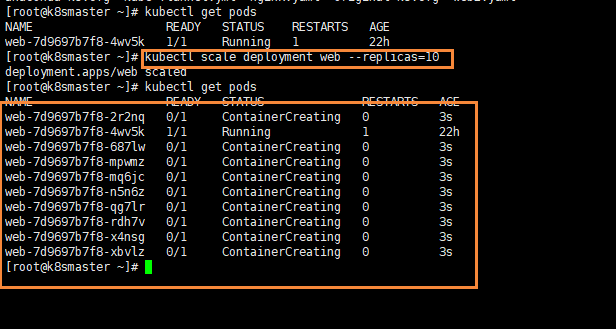
弹性伸缩,也就是我们通过命令一下创建多个副本
kubectl scale deployment web --replicas=0
可以看到,我们一下创建了10个副本
k8s核心技术——Service
前言
前面我们了解到 Deployment 只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。一个Pod只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的IP启动一个新的Pod,因此不能以确定的IP和端口号提供服务。
要稳定地提供服务需要服务发现和负载均衡能力。服务发现完成的工作,是针对客户端访问的服务,找到对应的后端服务实例。在K8S集群中,客户端需要访问的服务就是Service对象。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。
在K8S集群中,微服务的负载均衡是由kube-proxy实现的。kube-proxy是k8s集群内部的负载均衡器。它是一个分布式代理服务器,在K8S的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的kube-proxy就越多,高可用节点也随之增多。与之相比,我们平时在服务器端使用反向代理作负载均衡,还要进一步解决反向代理的高可用问题。
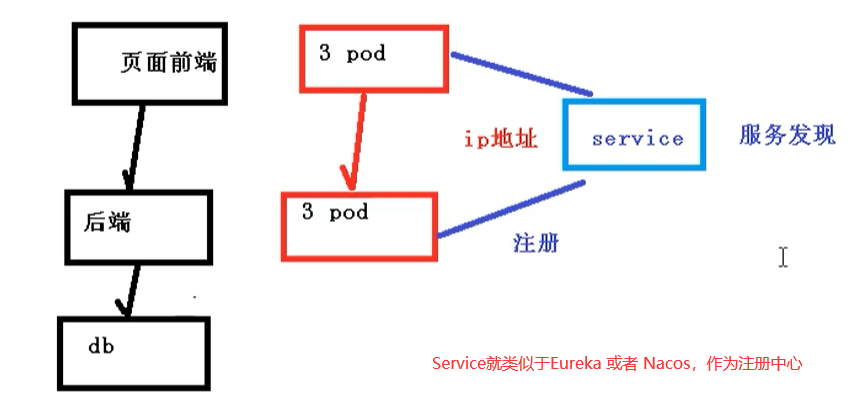
Service存在的意义
防止pod失联【服务发现】
因为Pod每次创建都对应一个IP地址,而这个IP地址是短暂的,每次随着Pod的更新都会变化,假设当我们的前端页面有多个Pod时候,同时后端也多个Pod,这个时候,他们之间的相互访问,就需要通过注册中心,拿到Pod的IP地址,然后去访问对应的Pod。
定义Pod访问策略【负载均衡】
页面前端的Pod访问到后端的Pod,中间会通过Service一层,而Service在这里还能做负载均衡,负载均衡的策略有很多种实现策略,例如:
- 随机
- 轮询
- 响应比
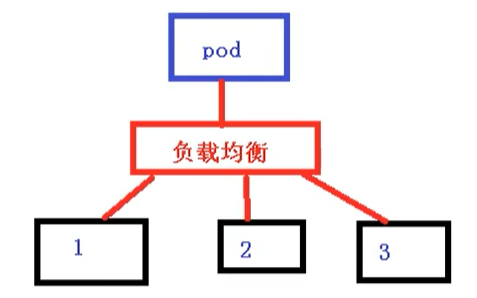
Pod和Service的关系
这里Pod 和 Service 之间还是根据 label 和 selector 建立关联的 【和Controller一样】
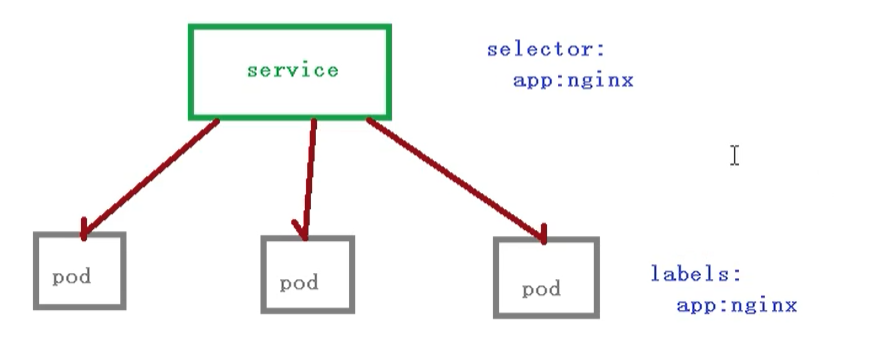
我们在访问service的时候,其实也是需要有一个ip地址,这个ip肯定不是pod的ip地址,而是 虚拟IP vip
Service常用类型
常用类型有三种:
- ClusterIP:集群内部访问
- NodePort:对外访问应用使用
- LoadBalancer:对外访问应用使用,共有云
例子
我们可以导出一个文件 包含service的配置信息
kubectl expose deployment web --port=80 --target-port=80 --dry-run -o yaml > service.yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
status:
loadBalancer: {}
如果我们没有做设置的话,默认使用的是第一种方式 ClusterIp,也就是只能在集群内部使用,我们可以添加一个type字段,用来设置我们的service类型
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
type: NodePort
status:
loadBalancer: {}
修改完命令后,我们使用创建一个pod
kubectl apply -f service.yaml
然后能够看到,已经成功修改为 NodePort类型了,最后剩下的一种方式就是LoadBalanced:对外访问应用使用公有云node一般是在内网进行部署,而外网一般是不能访问到的,那么如何访问的呢?
- 找到一台可以通过外网访问机器,安装nginx,反向代理
- 手动把可以访问的节点添加到nginx中
如果我们使用LoadBalancer,就会有负载均衡的控制器,类似于nginx的功能,就不需要自己添加到nginx上
k8s核心技术——控制器Controller详解
Statefulset
Statefulset主要是用来部署有状态应用
对于StatefulSet中的Pod,每个Pod挂载自己独立的存储,如果一个Pod出现故障,从其他节点启动一个同样名字的Pod,要挂载上原来的Pod的存储继续已它的状态提供服务。
无状态应用
原来使用deployment,部署的都是无状态的应用,那什么是无状态应用?
- 认为Pod都是一样的
- 没有顺序要求
- 不考虑应用在哪个node上运行
- 能够进行随意伸缩和扩展
有状态应用
上述的因素都需要考虑到
- 让每个Pod独立
- 让每个Pod独立,保持Pod启动顺序和唯一性
- 唯一的网络标识符,持久存储
- 有序,比如mysql的主从
适合StatefulSet的业务包括数据库服务MySQL和PostgreSQL,集群化管理服务Zookeeper、etcd等有状态服务
StatefulSet的另一种典型应用场景是作为一种比普通容器更稳定可靠的模拟虚拟机的机制。传统的虚拟机正是一种有状态的宠物,运维人员需要不断的维护它,容器刚开始流行时,我们用来模拟虚拟机使用,所有状态都被保存在容器里,而这已被证明是非常不安全、不可靠的。
使用StatefulSet,Pod仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供高可靠性,StatefulSet做的只是将确定的Pod与确定的存储关联起来保证状态的连续性。
部署有状态应用
无头Service,ClusterIp:none
这里就需要使用StateFulSet部署有状态应用。
apiVsersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulSet
namespace: default
spec:
serviceName: nginx
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
查看pod,能发现每个pod都有唯一的名称

查看service,发现是无头service

这里有状态的约定,肯定不是简简单单通过名称来进行约定,而是更加复杂的操作
- deployment:是有身份的,有唯一标识
- statefulset:根据主机名 + 按照一定规则生成域名
每个pod有唯一的主机名,并且有唯一的域名
- 格式:主机名称.service名称.名称空间.svc.cluster.local
- 举例:nginx-statefulset-0.default.svc.cluster.local
DaemonSet
DaemonSet 即后台支撑型服务,主要是用来部署守护进程
长期伺服型和批处理型的核心在业务应用,可能有些节点运行多个同类业务的Pod,有些节点上又没有这类的Pod运行;而后台支撑型服务的核心关注点在K8S集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类Pod运行。节点可能是所有集群节点,也可能是通过 nodeSelector选定的一些特定节点。典型的后台支撑型服务包括:存储、日志和监控等。在每个节点上支撑K8S集群运行的服务。
守护进程在我们每个节点上,运行的是同一个pod,新加入的节点也同样运行在同一个pod里面
- 例子:在每个node节点安装数据采集工具
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-test
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
containers:
- name: logs
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: varlog
mountPath: /tmp/log
volumes:
- name: varlog
hostPath:
path: /var/log
这里是一个FileBeat镜像,主要是为了做日志采集
进入某个 Pod里面,进入
kubectl exec -it ds-test-cpwdf bash
通过该命令后,我们就能看到我们内部收集的日志信息了

Job和CronJob
一次性任务 和 定时任务
- 一次性任务:一次性执行完就结束
- 定时任务:周期性执行
Job是K8S中用来控制批处理型任务的API对象。批处理业务与长期伺服业务的主要区别就是批处理业务的运行有头有尾,而长期伺服业务在用户不停止的情况下永远运行。Job管理的Pod根据用户的设置把任务成功完成就自动退出了。成功完成的标志根据不同的 spec.completions 策略而不同:单Pod型任务有一个Pod成功就标志完成;定数成功行任务保证有N个任务全部成功;工作队列性任务根据应用确定的全局成功而标志成功。
Job
job即一次性任务

使用下面命令,能够看到目前已经存在的Job
kubectl get jobs
在计算完成后,通过命令查看,能够发现该任务已经完成.
我们可以通过查看日志,查看到一次性任务的结果
kubectl logs pi-qpqff

CronJob
定时任务,cronjob.yaml如下所示
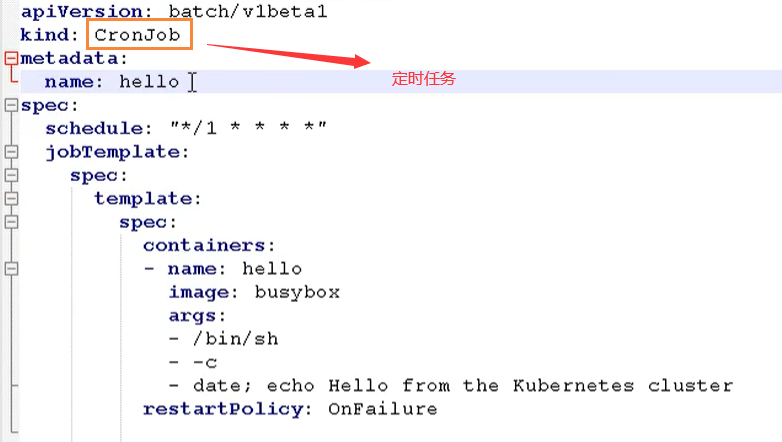 这里面的命令就是每个一段时间,这里是通过 cron 表达式配置的,通过 schedule字段
这里面的命令就是每个一段时间,这里是通过 cron 表达式配置的,通过 schedule字段
然后下面命令就是每个一段时间输出
我们首先用上述的配置文件,创建一个定时任务
kubectl apply -f cronjob.yaml
创建完成后,我们就可以通过下面命令查看定时任务
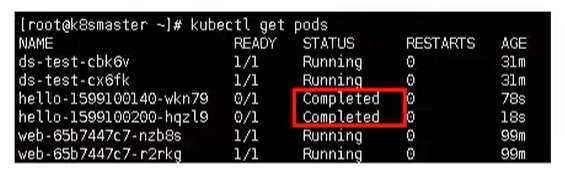
kubectl get cronjobs

我们可以通过日志进行查看
kubectl logs hello-1599100140-wkn79

然后每次执行,就会多出一个 pod
删除svc 和 statefulset
使用下面命令,可以删除我们添加的svc 和 statefulset
kubectl delete svc web
kubectl delete statefulset --all
Replication Controller
Replication Controller 简称 RC,是K8S中的复制控制器。RC是K8S集群中最早的保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动新的Pod副本;多于指定数目,RC就会杀死多余的Pod副本。
即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有一个Pod在运行。RC是K8S中较早期的技术概念,只适用于长期伺服型的业务类型,比如控制Pod提供高可用的Web服务。
Replica Set
Replica Set 检查 RS,也就是副本集。RS是新一代的RC,提供同样高可用能力,区别主要在于RS后来居上,能够支持更多种类的匹配模式。副本集对象一般不单独使用,而是作为Deployment的理想状态参数来使用
k8s配置管理
Secret
Secret的主要作用就是加密,然后存在etcd里面,让Pod容器以挂载Volume方式进行访问
场景:用户名和密码进行加密
一般场景的是对某个字符串进行base64编码进行加密
echo -n 'admin' | base64

变量形式挂载到Pod
- 创建secret加密数据的yaml文件scret.yaml
apiVersion:v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmu2N2Rm
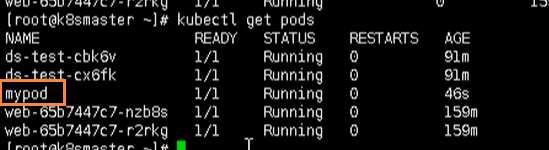
然后使用下面命令创建爱你一个pod
kubectl create -f secret.yaml
通过get命令查看
kubect get pods
然后我们通过下面的命令,进入到我们的容器内部
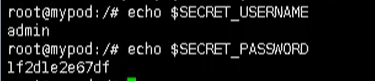
kubect exec -it mypod bash
然后我们就可以输出我们的值,这就是以变量的形式挂载到我们的容器中
/ 输出用户
echo $SECRET_USERNAME
/ 输出密码
echo #SECRET_PASSWORD
最后我们删除这个pod,可以使用以下命令
kubectl delete -f secret-val.yaml
数据卷形式挂载
首先我们创建一个secret-val.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: foo
mountPath: "/etc/foo" #挂载目录
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret 名称
创建Pod
# 根据配置创建容器
kubectl apply -f secret-val.yaml
# 进入容器
kubectl exec -it mypod bash
# 查看
ls /etc/foo

ConfigMap
configMap作用是存储不加密的数据到etcd中,让Pod以变量或数据卷Volume挂载到容器中
应用场景:配置文件
创建配置文件
首先创建一个配置文件redis.properties
redis.host=127.0.0.1
redis.port=6379
redis.password=123456
创建ConfigMap
我们使用命令创建configMap
kubectl create configmap redis-config --from-file=redis.properties
然后查看详细信息
kubectl describe cm redis-config
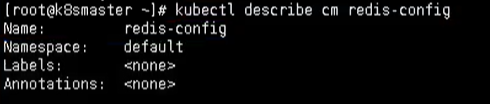
Volume数据卷形式挂载
首先我们需要创建一个cm.yaml
apiVersion: v1
kind: Pod
metadata:
name: muypod
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh","-c","cat /etc/config/redis.properties"]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: redis-config
restartPolicy: Never
然后使用该yaml创建我们的pod
/ 创建
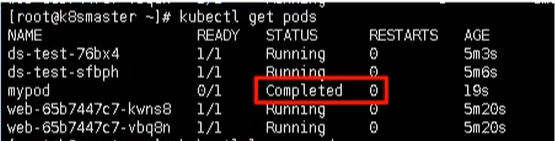
kubectl apply -f cm.yaml
/ 查看
kubectl get pods
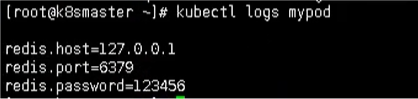
最后通过命令就看查看结果了
kubectl logs mypod
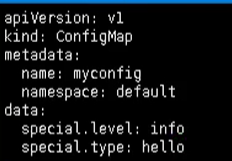
以变量的形式挂载Pod
首先我们也有一个 myconfig.yaml文件,声明变量信息,然后以configmap创建
然后我们就可以创建我们的配置文件
# 创建pod
kubectl apply -f myconfig.yaml
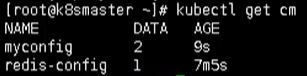
# 获取
kubectl get cm
然后我们创建完该pod后,我们就需要在创建一个 config-var.yaml 来使用我们的配置信息
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: busybox
image: busybox # 容器
command: ["/bin/sh", "-c" ,"echo $(LEVEL) $(type)"] # 输出配置信息
env:
- name: LEVEL
valueFrom:
configMapKeyRef:
name: myconfig # 挂载
key: special.level
- name: TYPE
valueFrom:
configMapKeyRef:
name: myconfig
key: special.type
restartPolicy: Never
最后我们查看输出
kubectl logs mypod

k8s 集群安全机制
概述
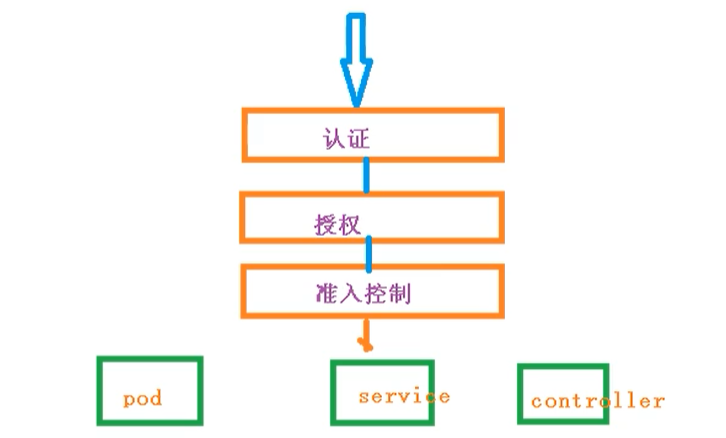
当我们访问k8s集群时,需要进过三个步骤完成
- 认证
- 鉴权【授权】
- 准入控制
进行访问的时候,都需要经过apiserver,apiserver做统一协调,比如门卫
- 访问过程中,需要证书、token或者用户名和密码
- 如果访问Pod需要serviceAccount
认证
对外不暴露8080端口,只能内部访问,对外使用的端口6443
客户端身份证常用方式
- https证书认证,基于ca证书
- http token认证,通过token来识别用户
- http基本认证,用户名+密码认证
鉴权
基于RBAC进行鉴权操作
基于角色访问控制
准入控制
就是准入控制器的列表,如果列表有请求内容就通过,没有的话就拒绝
RBAC介绍
基于角色的访问控制,为某个角色设置访问内容,然后用户分配该角色后,就拥有该角色的访问权限
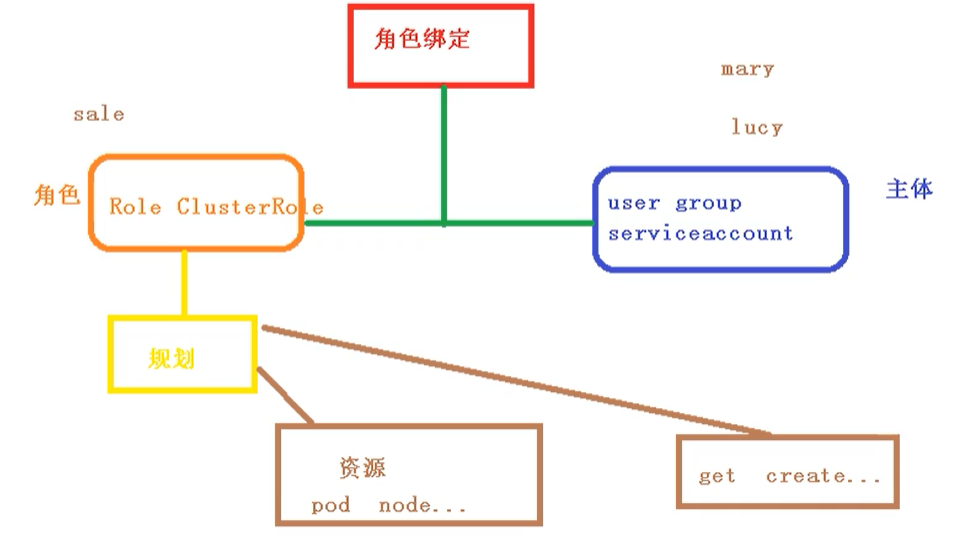
k8s中有默认的几个角色
- role:特定命名空间访问权限
- ClusterRole:所有命名空间的访问权限
角色绑定
- roleBinding:角色绑定到主体
- clusterRole:所有命名空间的访问权限
主体
- user:用户
- group:用户组
- serviceAccount:服务帐号
RBAC实现鉴权
- 创建爱你命名空间
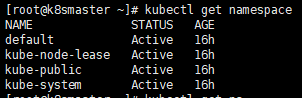
创建命名空间
首先查看已经存在的命名空间
kubectl get namespace
然后创建一个自己的命名空间roledemo
kubectl create ns roledemo
命名空间创建Pod
为什么要创建命名空间?因为如果不创建命名空间的话,默认是在default下
kubectl run nginx --image=nginx -n roledemo
创建角色
通过rbac-role.yaml进行创建
kind: Role
apiversion: rbac.authorization.k8s.io/v1
metadata:
namespace: ctnrs
name:pod-reader
rules:
apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get","watch","list"]
tip:这个角色只对pod有get、list权限
然后通过yaml创建role
# 创建
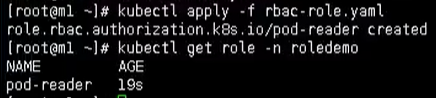
kubectl apply -f rbac-role.yaml
# 查看
kubectl get role -n roledemo
创建角色绑定
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name:read-pods
namespace: roletest
subjects:
kind: User
name: lucy #Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role # this must be Role or ClusterRole
name: pod-reader $ this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io
然后创建我们的角色绑定
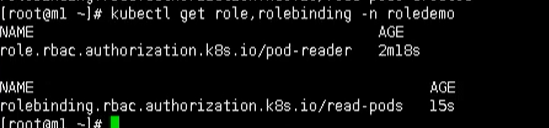
# 创建角色绑定
kubectl apply -f rbac-rolebinding.yaml
# 查看角色绑定
kubectl get role,rolebingding -n roledemo
使用证书识别身份
Ian得有一个rbac-user.sh证书脚本
cat > mary-scr.json <<EOF
{
“CN”:"mary",
"hosts":[],
"key": {
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing"
}
]
}
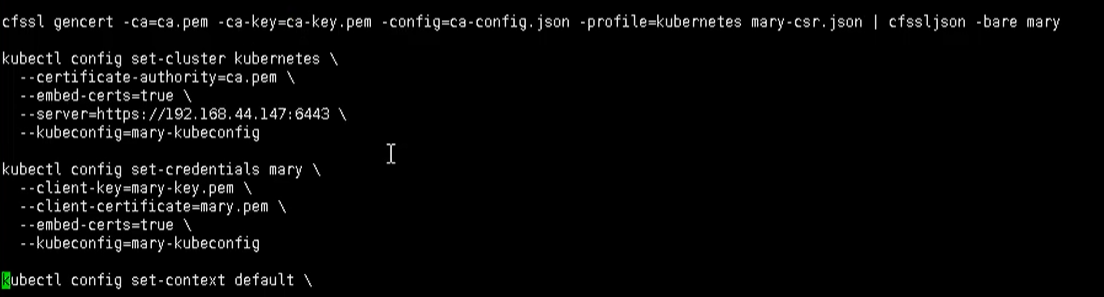
这里包含了很多证书文件,在TLS目录下,需要复制过来
通过下面命令执行我们的脚本
./rbac-user.sh
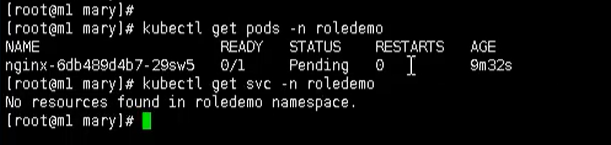
测试
# 用get命令查看pod 【有权限】
kubectl get pods -n roledemo
# 用get命令查看svc 【没权限】
kubectl get svc -n roledemo
K8s核心技术——Ingress
前言
我们原来需要将端口号对外暴露,通过ip+端口号就可以进行访问
原来是使用Service中的NodePort来实现
- 在每个节点上都会启动端口
- 在访问的时候通过任何节点,通过ip+端口号就能实现访问
但是NodePort还存在一些缺陷
- 因为端口号不能重复,所以每个端口只能使用一次,一个端口对应一个应用
- 实际访问中都是用域名,根据不同域名跳转到不同端口服务中
Ingress和Pod关系
pod和ingress是通过service进行关联的,而ingress作为统一入口,由service关联一组pod中
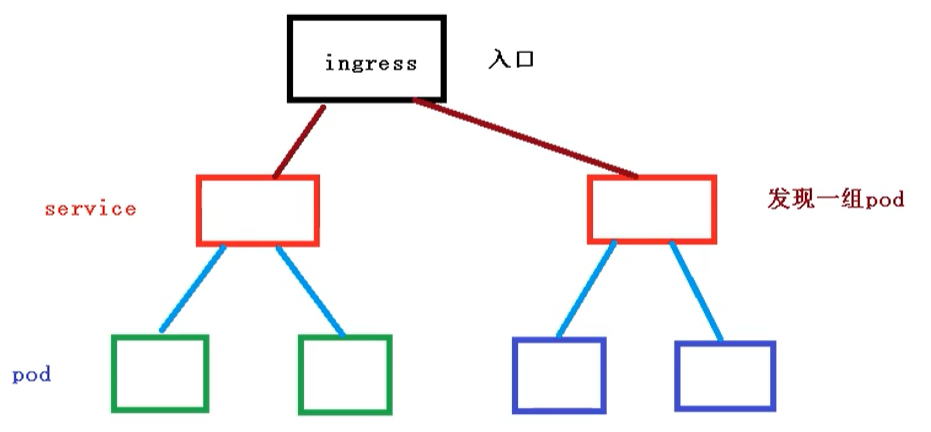
- 首先service就是关联我们的pod
- 然后ingress作为入口,首先需要到service,然后发现一组pod
- 发现pod后,就可以负载均衡等操作
Ingress工作流程
在实际的访问中,我们都是需要维护很多域名,a.com和b.com
然后不同的域名对应的不同的Service,然后service管理不同的pod
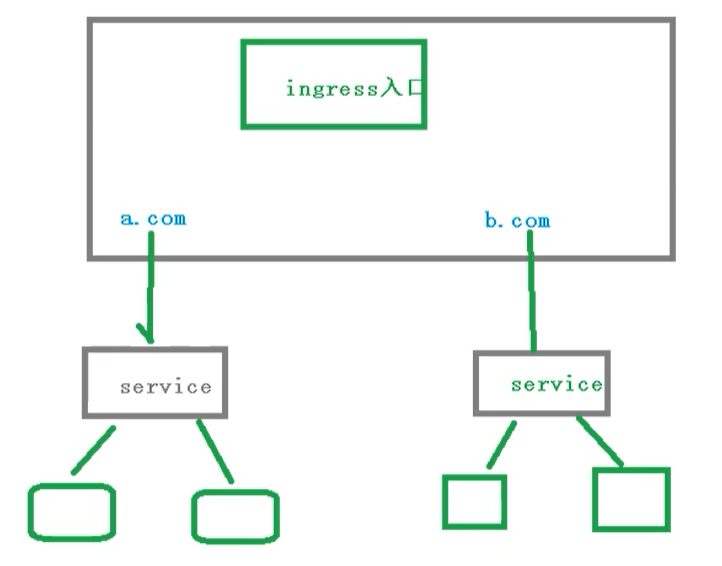
需要注意,ingress不是内置的组件,需要单独安装
使用Ingress
步骤如下所示
- 部署ingress Controller【需要下载官方的】
- 创建ingress规则【对哪个Pod、名称空间配置规则】
创建Nginx Pod
创建一个nginx应用,然后对外暴露端口
# 创建pod
kubectl create deployment web --image=nginx
# 查看
kubectl get pods
对外暴露端口
kubectl expose deployment web --port=80 --target-port=80 --type:NodePort
部署ingress controller
下面我们来通过yaml的方式,部署我们的ingress,配置文件如下所示
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/port-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
这个文件里面,需要注意的是hostNetwork.true,改成true是为了让后面访问到
kubectl apply -f ingress-con.yaml
通过这种方式, 其实我们在外面就能访问,这里还需要在外面添加一层
kubectl apply -f ingress-con.yaml
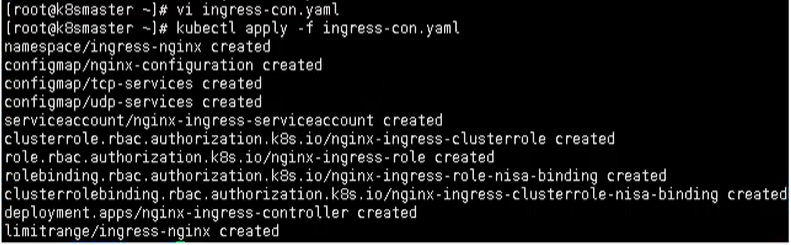
通过下面命令,查看是否成功部署ingress
kubectl get pods -n ingress-nginx

创建ingress规则文件
创建ingress规则文件,ingress-h.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: example.ingredemo.com # 域名
http:
- path: /
backend:
serviceName: web
servicePort: 80 # 访问的service端口号
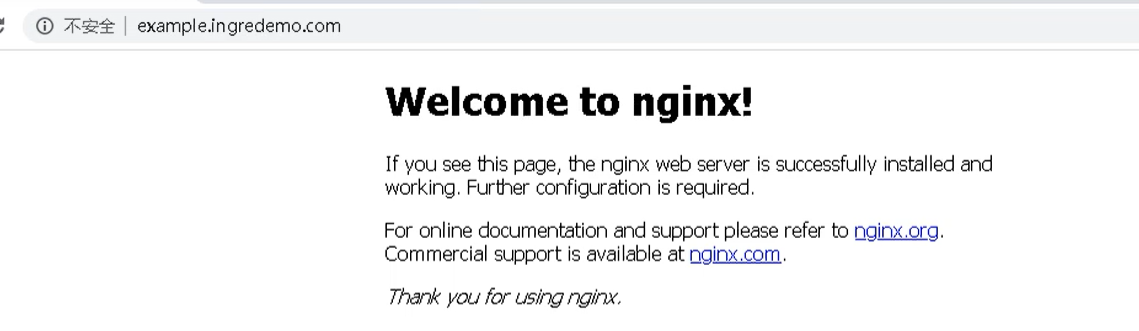
添加域名访问规则
在windows的hosts文件,添加域名访问规则【因为我们没有域名解析,只能这样做】
192.168.245.132 example.ingredemo.com
最后通过域名就能访问
K8s核心技术——Helm
Helm就是一个包管理工具【类似于npm】
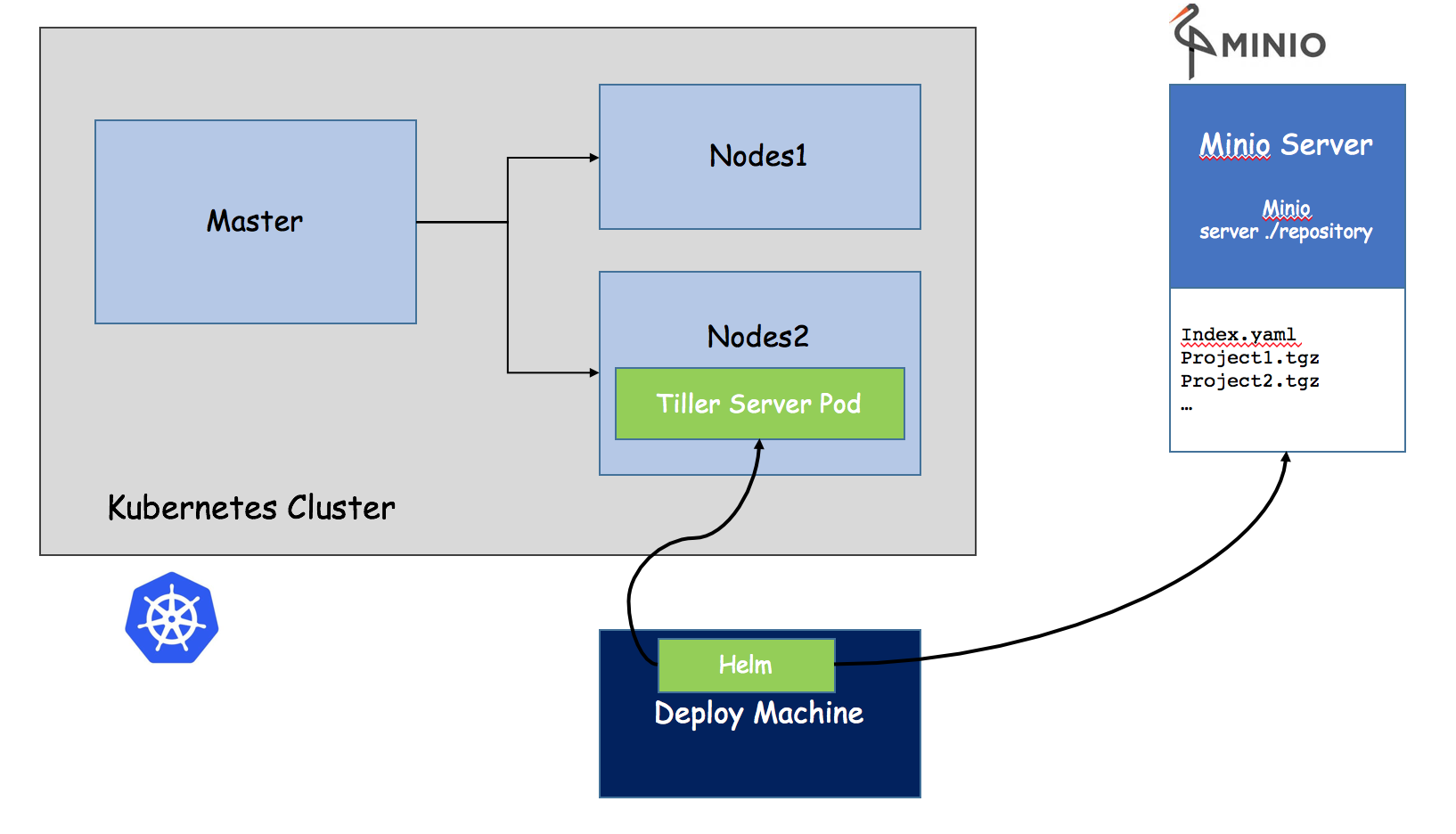
为什么引入Helm
首先在原来项目中都是基于yaml文件来进行部署发布的,而目前项目大部分微服务化或者模块化,会分成很多个组件来部署,每个组件可能对应一个deployment.yaml,一个service.yaml,一个Ingress.yaml还可能存在各种依赖关系,这样一个项目如果有5个组件,很可能就有15个不同的yaml文件,这些yaml分散存放,如果某天进行项目恢复的话,很难知道部署顺序,依赖关系等,而所有这些包括。
- 基于yaml配置的几种存放
- 基于项目的打包
- 组件间的依赖
但是这种方式部署,会有什么问题呢?
- 如果使用之前部署单一应用,少数服务的应用,比较合适
- 但如果部署微服务项目,可能有几十个服务,每个服务都有一套yaml文件,需要维护大量的yaml文件,版本管理特别不方便
Helm的引入,就是为了上面这些问题的
- 使用Helm可以把这些YAML文件作为整体管理
- 实现YAMLa能高效复用
- 使用helm应用级别的版本管理
Helm介绍
Helm是一个kubernetes的包管理工具,就像Linux下的包管理器,如yum/apt等,可以很方便的将之前打包好的yaml文件部署到Kubernetes上
Helm有三个重要概念
- helm:一个命令行客户端工具,主要用于Kubernetes应用chart的创建、打包、发布和管理
- Chart:应用描述,一系列用于描述k8s资源相关文件的集合
- Release:基于Chart的部署实体,一个chart被Helm运行后将会生成对应的release,将在k8s中创建爱你出真实的运行资源对象。也就是应用级别的版本管理。
- Repository:用于发布和存储Chart的仓库
Helm组件及架构
Helm采用客户端/服务端架构,有如下组件组成
- Helm CLI是Helm客户端,可以在本地执行
- Tiller是服务端组件,在Kubernetes集群上运行,并管理Kubernetes应用程序
- Repository是Chart仓库,Helm客户端HTTP协议来访问仓库中Chart索引文件和压缩包
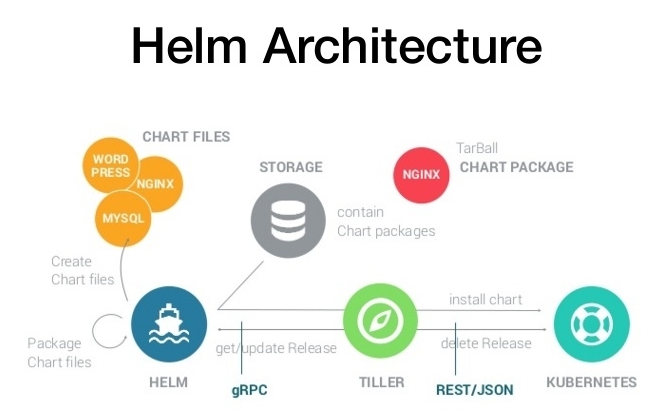
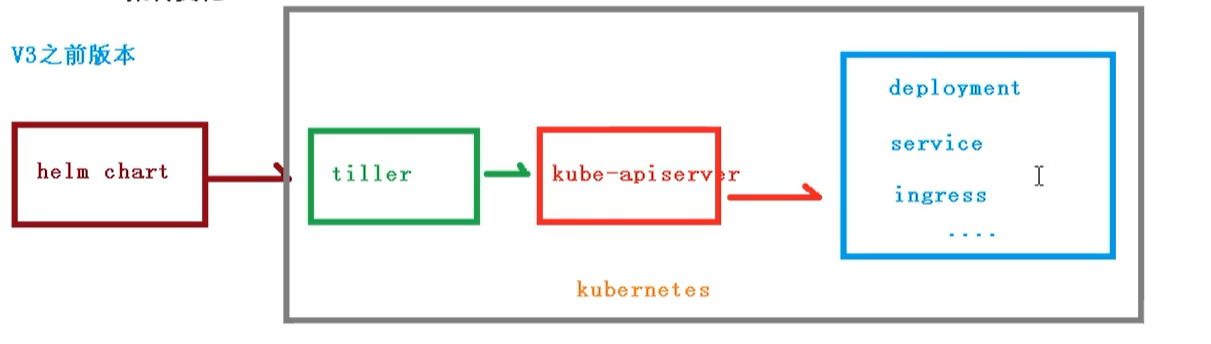
Helm v3变化
2019年1113日,Helm团队发布了Helm v3的第一稳定版本
该版本主要变化如下
- 架构变化
- 最明显的变化是Tiller的删除
- v3版本删除Tiller
- relesase可以在不同命名空间重用
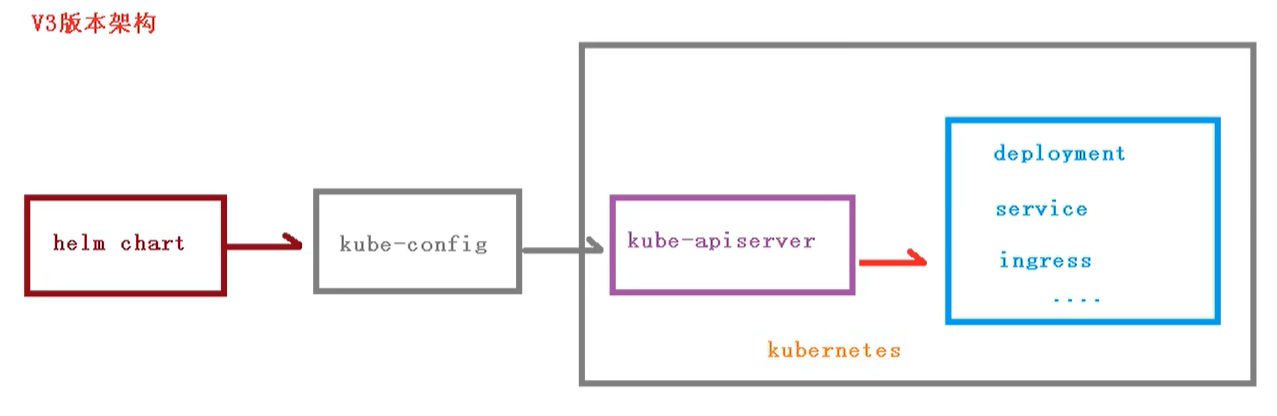
v3之前
v3版本
Helm配置
首先需要去官网下载
- 第一步,下载helm安装压缩文件,上传到linux系统中
- 第二步,解压helm压缩文件,把解压后的helm目录复制到usr/bin目录中
- 使用命令:helm
我们都知道yum需要配置yum源,那么helm也需要配置helm源
Helm仓库
添加仓库
helm repo add 仓库名 仓库地址
例如
# 配置微软源
helm repo add stable http://mirror.azure.cn/kubernetes/charts
# 配置阿里源
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 配置google源
helm repo add google https://kubernetes-charts.storage.googleapis.com/
# 更新
helm repo update
然后可以查看我们添加的仓库地址
# 查看全部
helm repo list
# 查看某个
helm search repo stable
或者可以删除我们添加的源
helm repo remove stable
helm基本命令
- chart install
- chart upgrade
- chart rollback
使用helm快速部署应用
使用命令搜索应用
首先我们使用命令,搜索我们需要安装的应用
# 搜索 weave仓库
helm search repo weave
根据搜索内容选择安装
helm install ui aliyun/weave-scope
可以通过下面命令,来下载yaml文件【如果】
kubectl apply -f weave-scope.yaml
安装完成后,通过下面命令即可查看
helm status ui
但是我们通过查看svc状态,发现没有对爱过你暴露端口

所以我们需要修改service的yaml文件,添加NodePort
kubectl edit svc ui-weave-scope
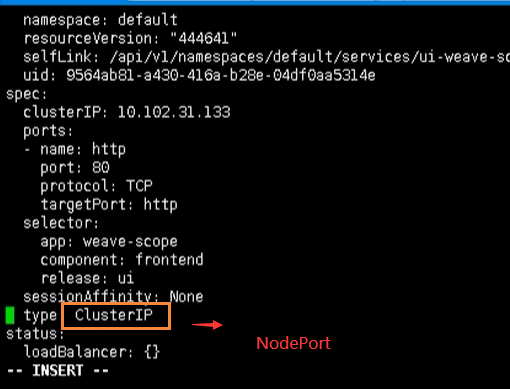
这样就可以对外暴露端口了

然后通过ip+32185即可访问
如果自己创建Chart
使用命令,自己创建Chart
helm create mycahrt
创建完成后,我们就能看到当前文件夹,创建爱你一个mychart目录

目录格式
- templates: 编写yaml文件存放到这个目录
- values.yaml:存放的是全局的yaml文件
- chart.yaml: 当前chart属性配置信息
在templates文件夹创建两个文件
我们创建一下两个
- deployment.yaml
- service.yaml
我们可以通过下面命令创建yaml文件
# 导出deployment.yaml
kubectl create deployment web1 --image=nginx --dry-run -o yaml > deployment.yaml
# 导出service.yaml 【可能需要创建 deployment,不然会报错】
kubectl expose deployment web1 --port=80 --target-port=80 --type=NodePort --dry-run -o yaml > service.yaml
安装mychart
执行命令创建
helm install web1 mychart
应用升级
当我们修改了mychart中的东西后,就可以进行升级操作
helm upgrade web1 mychart
chart模板使用
通过传递参数,动态渲染模板,yaml内容动态从传入参数生成

刚刚我们创建mychart的时候,看到有values.yaml文件,这个文件就是一些全局的变量,然后在templates中能取到变量的值,下面我们可以利用这个,来完成动态模板
- values.yaml 定义变量和值
- 具体yaml文件,获取定义变量值
- yaml文件中大体有几个地方不同
- image
- tag
- label
- port
- port
- replicas
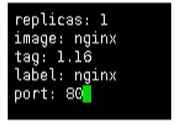
定义变量和值
在values.yaml定义变量和值
获取变量和值
通过表达式形式 使用全区变量{{.Values.变量名称}}
例如:{{.Release.Name}}
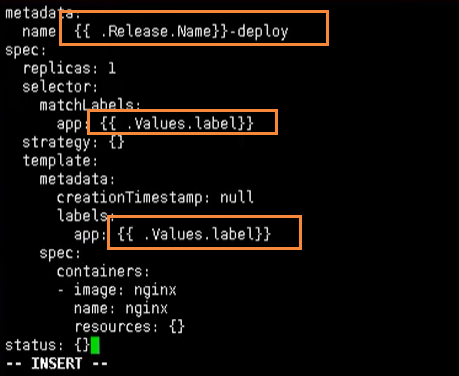
安装应用
在我们修改玩上述的信息后,就可以尝试的创建应用了
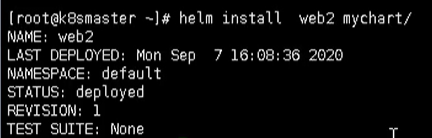
helm install --dry-run web2 mycahrt
K8s持久化存储
前言
之前我们有提到数据卷:emptydir,是本地存储,pod重启,数据就不存在了,需要对数据持久化存储
对于数据持久化存储【pod重启,数据还存在】,有两种方式
- nfs:网络存储【通过一台服务器来存储】
步骤
持久化服务器上操作
- 找一台新的服务器nfs服务端,安装nfs
- 设置挂载路径
使用命令安装nfs
yum install -y nfs-utils
首先创建存放数据的目录
mkdir -p /data/nfs
设置挂载路径
# 打开文件
vim /etc/exports
# 添加如下内容
/data/nfs *(rw,no_root_squash)
执行完成后,即部署我们的持久化服务器
Node节点上操作
然后需要在k8s集群node节点上安装nfs,这里需要在node1和node2节点上安装
yum install -y nfs-utils
执行完成后,会自动帮我们挂载上
启动nfs服务端
下面回到nfs服务端,启动nfs服务
systemctl start nfs
k8s集群部署应用
最后我们在k8s集群上部署应用,使用nfs持久化存储
# 创建一个pv文件夹
mkdir pv
cd pv
然后创建一个yaml文件 nfs-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep1
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: wwwroot
nfs:
server: 192.168.245.138
path:/data/nfs
通过这种方式,就挂载到了刚刚我们的nfs数据节点下的/data/nfs目录
最后变成了:/usr/share/nginx/html -> 192.168.245.138/data/nfs内容是对应的
通过这个yaml,创建爱你一个pod
kubectl apply -f nfs-nginx.yaml
创建完成后,也可以查看日志
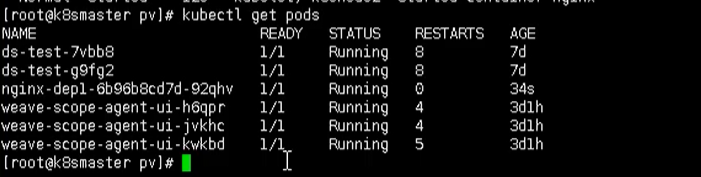
kubectl describe pod nginx-dep1

可以看到,我们的pod已经成功创建出来了,同时下图也是处于Running状态
下面我们就可以进行测试了,比如现在nfs服务节点上添加数据,然后在看是否存在pod中
# 进入pod中查看
kubectl exec -it nginx-dep1 bash

PV和PVC
对于上述的方式,我们都知道,我们的ip和端口号是直接放在我们的容器上的,这样管理起来可能不方便
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep1
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: wwwroot
nfs:
server: 192.168.245.138
path: /data/nfs
所以这里就需要用到 pv 和 pvc的概念了,方便我们配置和管理我们的 ip 地址等元信息
- PV:持久化存储,对存储的资源进行抽象,对外提供可以调用的地方【生产者】
- PVC:用于调用,不需要关心内部实现细节【消费者】
PV 和 PVC 使得 K8S 集群具备了存储的逻辑抽象能力。使得在配置Pod的逻辑里可以忽略对实际后台存储 技术的配置,而把这项配置的工作交给PV的配置者,即集群的管理者。存储的PV和PVC的这种关系,跟 计算的Node和Pod的关系是非常类似的;PV和Node是资源的提供者,根据集群的基础设施变化而变 化,由K8s集群管理员配置;而PVC和Pod是资源的使用者,根据业务服务的需求变化而变化,由K8s集 群的使用者即服务的管理员来配置。
实现流程
- PVC绑定PV
- 定义PVC
- 定义PV【数据卷定义,指定数据存储服务器的ip、路径、容量和匹配模式】
举例
创建一个pvc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep1
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: wwwroot
persistentVolumeClaim:
claimName: my-pvc
___
第一部分是定义一个 deployment,做一个部署
- 副本数:3
- 挂载路径
- 调用:是通过pvc的模式
然后定义pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
然后在创建一个pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
nfs:
path: /k8s/nfs
server: 192.168.245.138
然后创建pod
kubectl apply -f pv.yaml
通过下面命令,查看pv和pvc之间的绑定关系
kubectl get pv,pvc

到这里为止,我们就完成了我们 pv 和 pvc的绑定操作,通过之前的方式,进入pod中查看内容
kubectl exec -it nginx-dep1 bash
然后查看 /usr/share/nginx/html

也同样能看到刚刚的内容,其实这种操作和之前我们的nfs是一样的,只是多了一层pvc绑定pv的操作
四、k8s集群资源监控
监控指标
一个好的系统,主要监控以下内容
- 集群监控
- 节点资源利用率
- 节点数
- 运行pods
- Pod监控
- 容器指标
- 应用程序【程序占用CPU、内存】
监控平台
使用普罗米修斯【prometheus】+ Grafana 搭建监控平台
- proetheus[【定时搜索被监控服务的状态】
- 开源的
- 监控、报警、数据库
- 以HTTP协议周期性抓取被监控组件状态
- 不需要复杂的集成过程,使用http接口接入即可
- Grafana
- 开源的数据分析和可视化工具
- 支持多种数据源
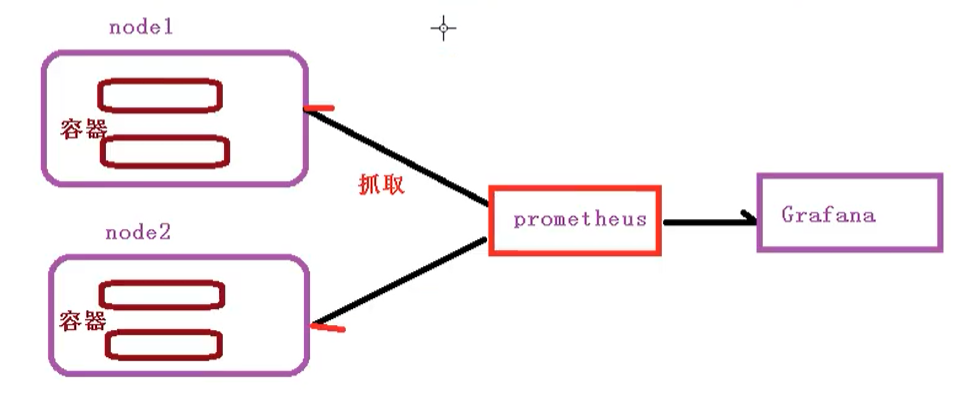
部署prometheus
首先需要部署一个守护进程
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
containers:
- image: prom/node-exporter
name: node-exporter
ports:
- containerPort: 9100
protocol: TCP
name: http
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: node-exporter
name: node-exporter
namespace: kube-system
spec:
ports:
- name: http
port: 9100
nodePort: 31672
protocol: TCP
type: NodePort
selector:
k8s-app: node-exporter
执行以下命令
kubectl create -f node-exporter.yaml
执行完成,发现报错

这是因为版本不一致的问题,因为发布的正式版本,而这个属于测试版本
找到第一行,修改内容如下
# 修改前
apiVersion: extensions/v1
# 修改后 【正式版本发布后,测试版本就不能使用了】
apiVersion: apps/v1
创建完成后的效果

然后通过yaml的方式部署prometheus

- configmap:定义一个configmap:存储一些配置文件【不加密】
- prometheus.deploy.yaml:部署一个deployment【包括端口号,资源限制】
- prometheus.svc.yaml:对外暴露的端口
- rbac-setup.yaml:分配一些角色的权限
下面我们进入目录中,首先部署rbac-setup.yaml
kubectl create -f rbac-setup.yaml
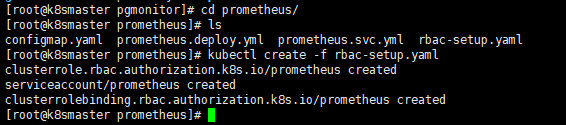
然后分别部署
# 部署configmap
kubectl create -f configmap.yaml
# 部署deployment
kubectl create -f prometheus.deploy.yml
# 部署svc
kubectl create -f prometheus.svc.yml
部署完成后,我们使用下面命令查看
kubectl get pods -n kube-system
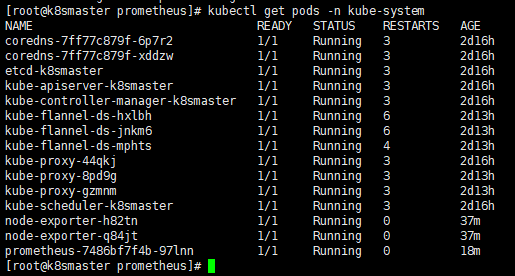
在我们部署完成后,就可以看到prometheus的pod了,然后通过以下命令,能够看到对应的端口
kubectl get svc -n kube-system

通过这个,我们可以看到prometheus对外暴露的端口为3003,访问页面就可以看到对应的图形化界面
http://192.168.245.138:3003
在上面我们部署完prometheus后,我们还需要来部署grafana
kubectl create -f grafana-deploy.yaml
执行完成后,发现下面的问题
error: unable to recognize "grafana-deploy.yaml": no matches for kind "Deployment" in version "extensions/v1beta1"
我们需要修改如下内容
# 修改
apiVersion: apps/v1
# 添加selector
spec:
replicas: 1
selector:
matchLabels:
app: grafana
component: core
修改完成后,我们继续执行上述代码
# 创建deployment
kubectl create -f grafana-deploy.yaml
# 创建svc
kubectl create -f grafana-svc.yaml
# 创建 ing
kubectl create -f grafana-ing.yaml
我们能看到,我们的grafana正在创建
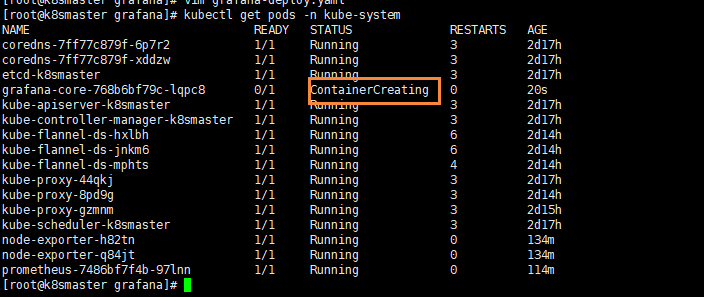
配置数据源
下面我们需要开始打开Grafana,然后配置数据源,导入数据显示模板
kubectl get svc -n kube-system

我们可以通过 ip + 30431 访问我们的 grafana 图形化页面

然后输入账号和密码:admin admin
进入后,我们就需要配置 prometheus 的数据源
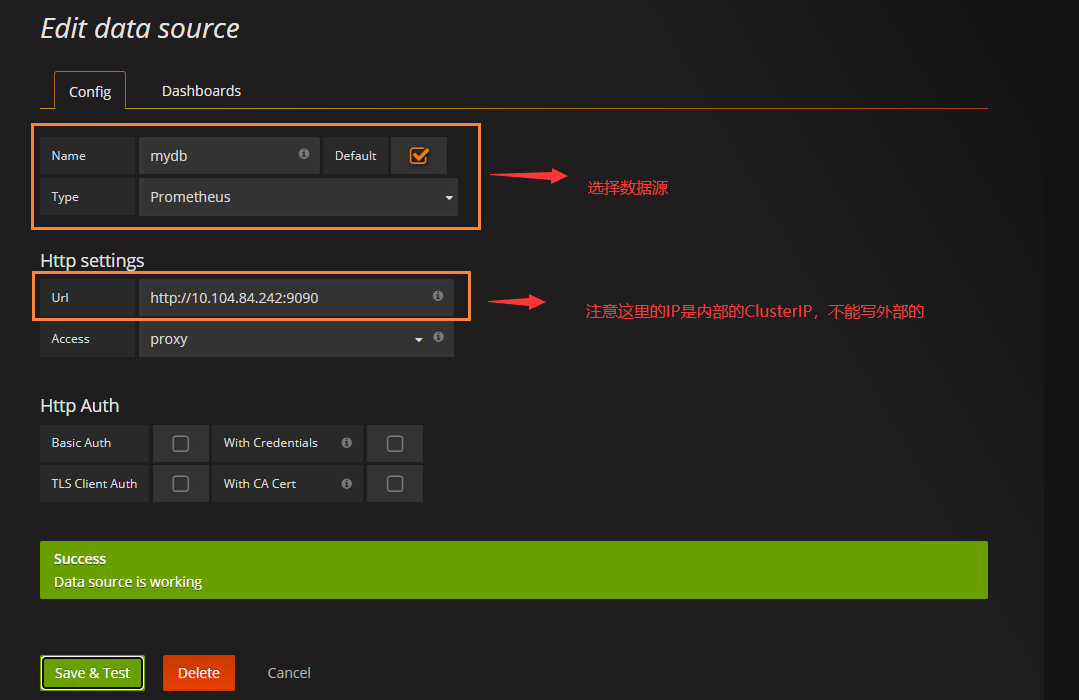
和 对应的IP【这里IP是我们的ClusterIP】

设置显示数据的模板
选择Dashboard,导入我们的模板
然后输入 315 号模板
然后选择 prometheus数据源 mydb,导入即可
导入后的效果如下所示
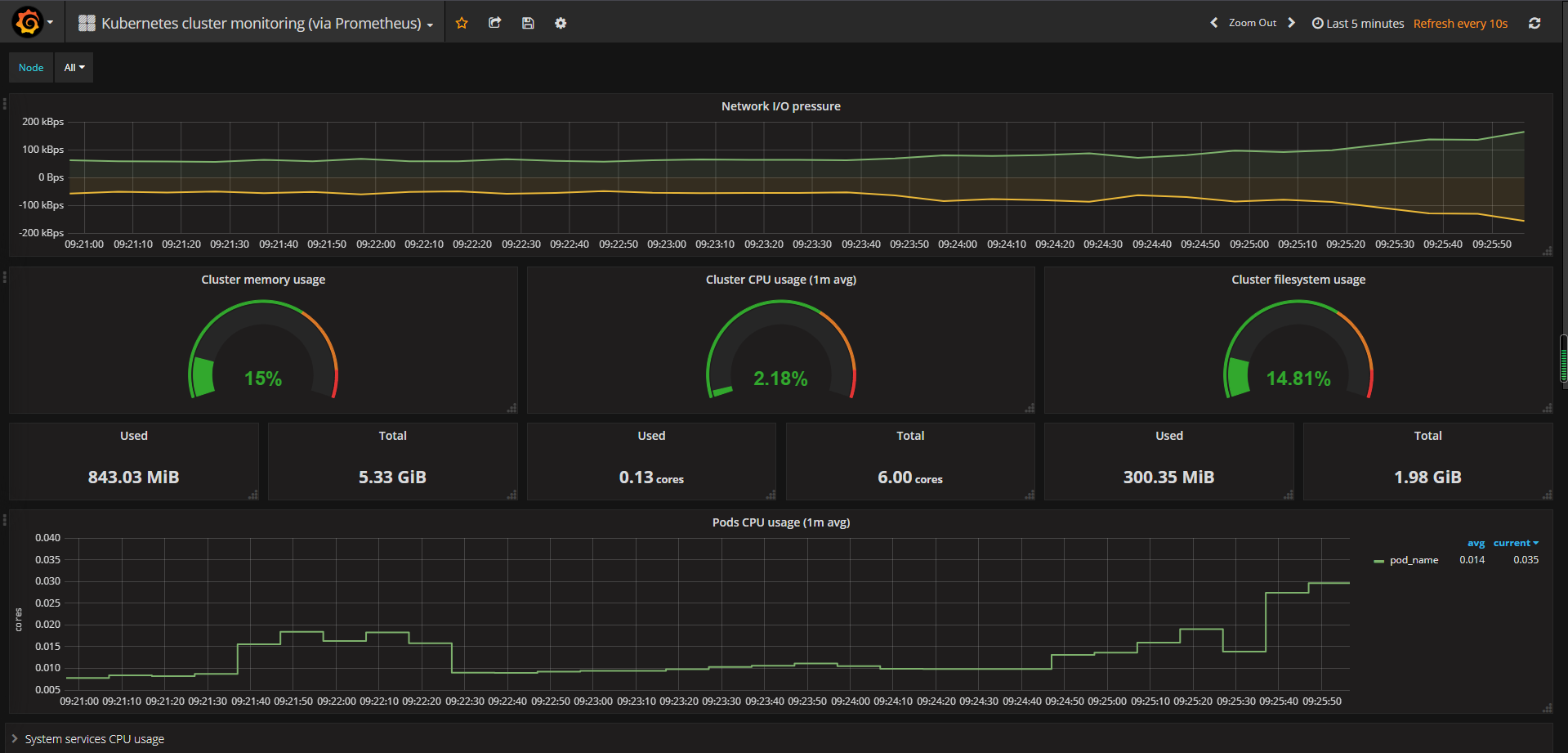
五、k8s搭建高可用集群
前言
之前我们搭建的集群,只有一个master节点,当master节点宕机的时候,通过node将无法继续访问,而master主要是管理作用,所以整个集群将无法提供服务
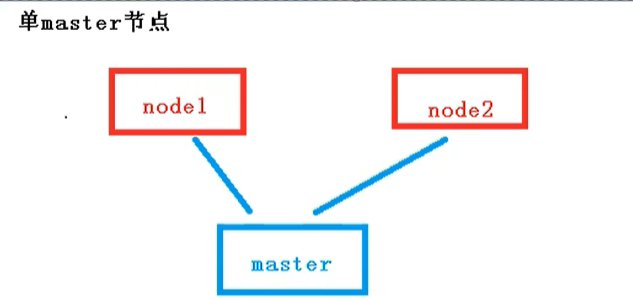
高可用集群
下面我们就需要搭建一个多master节点的高可用集群,不会存在单点故障的问题。
但是node和master之间,需要存在一个LoadBalancer组件,作用如下:
- 负载
- 检查master节点的状态
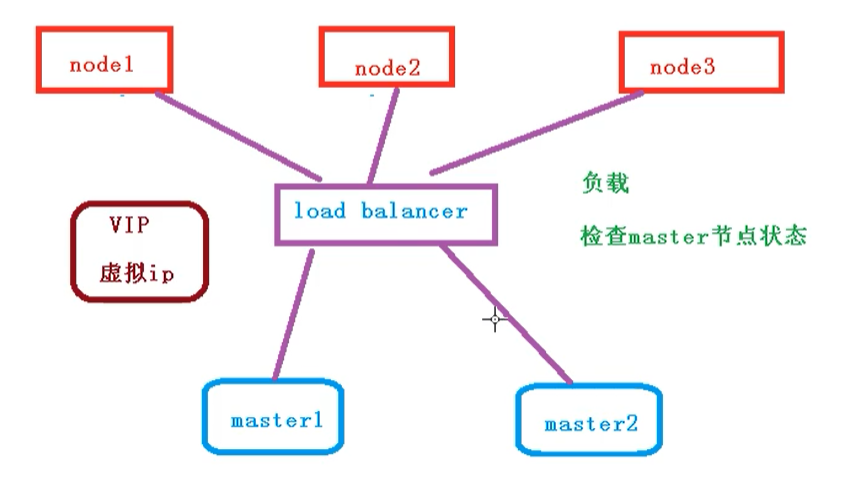
对外有一个统一的VIP:虚拟ip来对外进行访问
高可用集群技术细节
高可用集群技术细节如下所示:
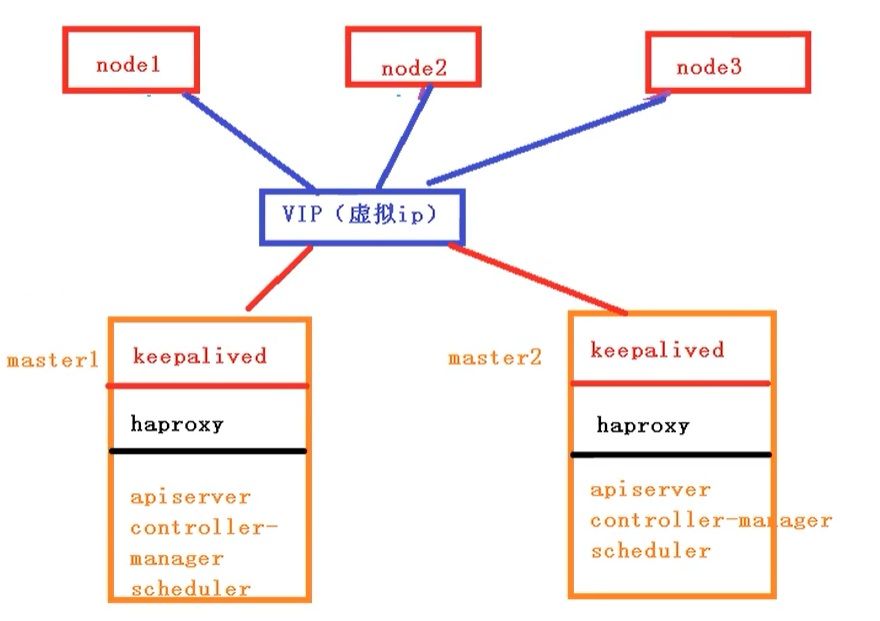
- keepalived:配置虚拟ip,检查节点的状态
- haproyx:负载均衡服务【类似于nginx】
- apiserver
- controller
- manager
- scheduler
高可用集群步骤
采用2个master接地那,一个node节点来搭建高可用集群,下面给出了每个节点需要做的事情

初始化操作
我们需要在这三个节点上进行操作
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
# 永久关闭
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 临时关闭
setenforce 0
# 关闭swap
# 临时
swapoff -a
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 根据规划设置主机名【master1节点上操作】
hostnamectl set-hostname master1
# 根据规划设置主机名【master2节点上操作】
hostnamectl set-hostname master1
# 根据规划设置主机名【node1节点操作】
hostnamectl set-hostname node1
# r添加hosts
cat >> /etc/hosts << EOF
192.168.44.158 k8smaster
192.168.44.155 master01.k8s.io master1
192.168.44.156 master02.k8s.io master2
192.168.44.157 node01.k8s.io node1
EOF
# 将桥接的IPv4流量传递到iptables的链【3个节点上都执行】
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
部署keepAlived
下面我们需要在所有的master节点【master1和master2】上部署keepAlive
安装相关包
# 安装相关工具
yum install -y conntrack-tools libseccomp libtool-ltdl
# 安装keepalived
yum install -y keepalived
配置master节点
添加master1的配置
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 250
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.44.158
}
track_script {
check_haproxy
}
}
EOF
添加master2的配置
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.44.158
}
track_script {
check_haproxy
}
}
EOF
启动和检查
在两台master节点都执行
# 启动keepalived
systemctl start keepalived.service
# 设置开机启动
systemctl enable keepalived.service
# 查看启动状态
systemctl status keepalived.service
启动后查看master的网卡信息
ip a s ens33
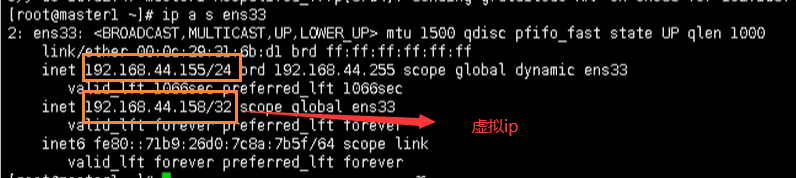
部署haproxy
haproxy主要做负载的作用,将我们的请求分担到不同的node节点上
安装
在两个master节点安装 haproxy
# 安装haproxy
yum install -y haproxy
# 启动haproxy
systemctl start haproxy
# 开机自启
systemctl enable haproxy
启动后,我们查看对应的端口是否包含16443
netstat -tunlp | grep haproxy

配置
两台master节点的配置均相同,配置中声明了后端代理的两个master节点服务器,指定了haproxy运行的端口为16443等,因此16443端口为集群的入口
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master01.k8s.io 192.168.44.155:6443 check
server master02.k8s.io 192.168.44.156:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
安装Docker、Kubeadm、kubectl
所有节点安装Docker/kubeadm/kubelet ,Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker
安装Docker
K8S/18_Kubernetes搭建高可用集群
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
然后yum方式安装docker
# yum 安装
yum -y install docker-ce
# 查看docker版本
docker --version
# 启动docker
systemctl enable docker
systemctl start docker
配置docker的镜像
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://vgiqiiwr.mirror.aliyuncs.com"]
}
EOF
然后重启Docker
systemctl restart docker
添加kubernetes软件源
配置yum的k8s软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装kubeadm、kubelet和kubectl
与版本更新频繁,这里指定版本号部署:
# 安装kubelet、kubeadm、kubectl,同时指定版本号
yum -y install kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机启动
systemctl enable kubelet
部署Kubernetes Master【master节点】
创建kubeadm配置文件
在具有vip的master上进行初始化操作,这里为master1
# 创建文件夹
mkdir /usr/local/kubernetes/manifests -p
# 到manifests目录
cd /usr/local/kubernetes/manifests/
# 新建yaml文件
vi kubeadm-config.yaml
yaml内容如下所示:
apiServer:
certSANs:
- master1
- master2
- master.k8s.io
- 192.168.44.158
- 192.168.44.155
- 192.168.44.156
- 127.0.0.1
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "master.k8s.io:16443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.16.3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.1.0.0/16
scheduler: {}
然后我们在 master1 节点执行
kubeadm init --config kubeadm-config.yaml
执行完成后,就会在拉取我们的进行了【需要等待...】

按照提示配置环境变量,使用kubectl工具
# 执行下方命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查看节点
kubectl get nodes
# 查看pod
kubectl get pods -n kube-system
按照提示保存以下内容,一会儿要使用
kubeadm join master.k8s.io:16443 --token jv5z7n.3y1zi95p952y9p65 \
--discovery-token-ca-cert-hash sha256:403bca185c2f3a4791685013499e7ce58f9848e2213e27194b75a2e3293d8812 \
--control-plane
--control-plane: 只有在添加master节点的时候才有
查看集群状态
# 查看集群状态
kubectl get cs
# 查看pod
kubectl get pods -n kube-system
安装集群网络
从官方地址获取到flannel的yaml,在master1上执行
# 创建文件夹
mkdir flannel
cd flannel
# 下载yaml文件
wget -c https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
安装flannel网络
kubectl apply -f kube-flannel.yml
检查
kubectl get pods -n kube-system
master2节点加入集群
复制秘钥及相关文件
从master1复制秘钥及相关文件到master2
# ssh root@192.168.44.156 mkdir -p /etc/kubernetes/pki/etcd
# scp /etc/kubernetes/admin.conf root@192.168.44.156:/etc/kubernetes
# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.44.156:/etc/kubernetes/pki
# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.44.156:/etc/kubernetes/pki/etcd
master2加入集群
执行在master1上init后输出的join命令,需要带上参数--control-plane表示把master控制节点加入集群
kubeadm join master.k8s.io:16443 --token ckf7bs.30576l0okocepg8b --discovery-token-ca-cert-hash sha256:19afac8b11182f61073e254fb57b9f19ab4d798b70501036fc69ebef46094aba --control-plane
检查状态
kubectl get node
kubectl get pods --all-namespaces
加入Kubernetes Node
在node1上执行
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
kubeadm join master.k8s.io:16443 --token ckf7bs.30576l0okocepg8b --discovery-token-ca-cert-hash sha256:19afac8b11182f61073e254fb57b9f19ab4d798b70501036fc69ebef46094aba
集群网络重新安装,因为添加了新的node节点
检查状态
kubectl get node
kubectl get pods --all-namespaces
测试kubernetes集群
在kubernetes集群中创建一个pod,验证是否正常运行:
# 创建nginx deployment
kubectl create deployment nginx --image=nginx
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看状态
kubectl get pod,svc
然后我们通过任何一个节点,都能够访问我们的nginx页面
六、Kubernetes容器交付介绍
如何在k8s及群众部署Java项目
容器交付流程
- 开发代码阶段
- 编写代码
- 编写Dockerfile【打镜像做准备】
- 持续交付/集成
- 代码编译打包
- 制作镜像
- 上传镜像仓库
- 应用部署
- 环境准备
- Pod
- Service
- Ingress
- 运维
- 监控
- 故障排查
- 应用升级
k8s部署Java项目流程
- 制作镜像【Dockerfile】
- 上传到镜像仓库【Dockerhub、阿里云、网易】
- 控制器部署镜像【Deployment】
- 对外暴露应用【Service、Ingress】
- 运维【监控、升级】
k8s部署Java项目
准备Java项目
依赖环境
在打包java项目的时候,我们首先需要两个环境
- java环境
- maven环境
然后把java项目打包成jar包
mvn clean install

编写DockerFile文件
Dockerfile 内容如下所示
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ADD ./target/daemonjenkins.jar demojenkins.jar
ENTRYPOINT ["java","-jar","/daemonjenkins.jar","&"]
制作镜像
在我们创建好Dockerfile文件后,我们就可以制作镜像了
我们首先将我们的项目,放到我们的服务器上
然后执行下面命令打包镜像
docker build -t java-demo-01:latest
等待一段后,即可制作完成我们的镜像
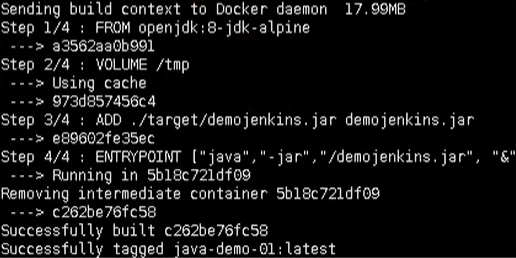
最后通过下面命令,即可查看我们的镜像了
docker images;
启动镜像
在我们制作完成镜像后,我们就可以启动我们的镜像了
docker run -d -p 8111:8111 java-demo-01:latest -t
启动完成后,我们通过浏览器进行访问,即可看到我们的java程序
http://192.168.177.130:8111/user
推送镜像
下面我们需要将我们制作好的镜像,上传到镜像服务器中【阿里云、DockerHub】
首先我们需要到 阿里云 容器镜像服务,然后开始创建镜像仓库
然后选择本地仓库
我们点击我们刚刚创建的镜像仓库,就能看到以下的信息
登录镜像服务器
使用命令登录
docker login --username=xxxxx@163.com registry.cn-shenzhen.aliyuncs.com
然后输入刚刚我们开放时候的注册的密码
镜像添加版本号
下面我们为镜像添加版本号
# 实例
docker tag [ImageId] registry.cn-shenzhen.aliyuncs.com/mogublog/java-project-01:[镜像版本号]
# 举例
docker tag 33f11349c27d registry.cn-shenzhen.aliyuncs.com/mogublog/java-project-01:1.0.0
操作完成后

推送镜像
在我们添加版本信息后,我们就可以推送我们的镜像到阿里云了
docker push registry.cn-shenzhen.aliyuncs.com/mogublog/java-project-01:1.0.0

查看阿里云镜像服务,就能看到推送上来的镜像了
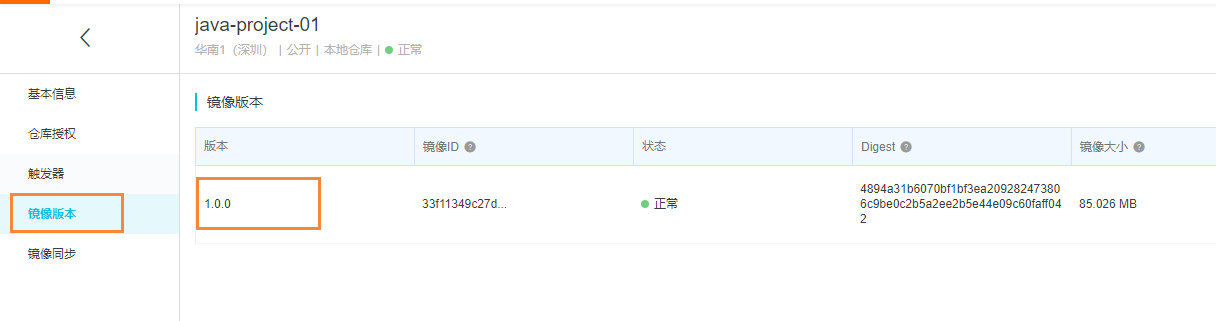
控制部署镜像
在我们推送镜像到服务器后,就可以通过控制器部署镜像了
首先我们需要根据刚刚的镜像,导出yaml
# 导出yaml
kubectl create deployment javademo1 --image=registry.cn-
shenzhen.aliyuncs.com/mogublog/java-project-01:1.0.0 --dry-run -o yaml > javademo1.yaml
导出后的 javademo1.yaml 如下所示
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: javademo1
name: javademo1
spec:
replicas: 1
selector:
matchLabels:
app: javademo1
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: javademo1
spec:
containers:
- image: registry.cn-shenzhen.aliyuncs.com/mogublog/java-project-01:1.0.0
name: java-project-01
resources: {}
status: {}
然后通过下面命令,通过yaml创建我们的deployment
# 创建
kubectl apply -f javademo1.yaml

或者我们可以进行扩容,多创建几个副本
kubectl scale deployment javademo1 --replicas=3
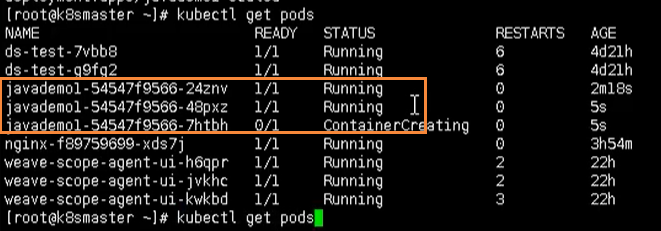
然后我们还需要对外暴露端口【通过service或者Ingress】
# 对外暴露端口
kubectl expose deployment javademo1 --port=8111 --target-port=8111 --type=NodePort
# 查看对外端口号
kubectl get svc

然后通过下面的地址访问
# 对内访问
curl http://10.106.103.242:8111/user
# 对外访问
http://192.168.177.130:32190/user
七、 使用kubeadm-ha脚本一键安装K8S
前情提示
以前安装k8s集群的时候使用的是k8s官网的教程 使用的镜像源都是国外的 速度慢就不说了 还有一些根本就下载不动 导致安装失败 最后在朋友的建议下使用一个开源的一键安装k8s的脚本就好了起来了 Github地址:https://github.com/TimeBye/kubeadm-ha
环境准备
官网的安装说明也很简单但是还有些细节还是没有提到,所以这里补充了一些细节
硬件系统要求
- Master节点:2C4G +
- Worker节点:2C4G +
使用centos7.7安装请按上面配置准备好3台centos,1台作为Master节点,2台Worker节点
本方式为1主2worker的配置
这是我的各个节点的配置
| 主机名 | ip | 配置 |
|---|---|---|
| k8s-master | 192.168.177.130 | 2C4G |
| k8s-node1 | 192.168.177.131 | 2C2G |
| k8s-node2 | 192.168.177.132 | 2C2G |
centos准备
在安装之前需要准备一些基础的软件环境用于下载一键安装k8s的脚本和编辑配置
centos网络准备
安装时需要连接互联网下载各种软件 所以需要保证每个节点都可以访问外网
ping www.baidu.com
建议关闭centos的防火墙
systemctl stop firewalld && systemctl disable firewalld && systemctl status firewalld
同时需要保证各个节点间可以相互ping通
ping 其他节点ip
CentOS软件准备
用 ssh 连接到 Master 节点上安装 Git
yum install git -y
部署k8s前配置
下载部署脚本
在Master节点clone安装脚本 脚本地址
git clone --depth 1 https://github.com/TimeBye/kubeadm-ha
进入到下载的部署脚本的目录
sudo ./install-ansible.sh
修改安装的配置文件
由于我是一个master两个node的方式构建的centos所以我们需要修改example/hosts.s-master.ip.ini 文件
vi example/hosts.s-master.ip.ini
具体要修改的就是ip 和密码 其他的保持默认
我的hosts.s-master.ip.ini 文件预览
; 将所有节点信息在这里填写
; 第一个字段 为远程服务器内网IP
; 第二个字段 ansible_port 为节点 sshd 监听端口
; 第三个字段 ansible_user 为节点远程登录用户名
; 第四个字段 ansible_ssh_pass 为节点远程登录用户密码
[all]
192.168.177.130 ansible_port=22 ansible_user="root" ansible_ssh_pass="moxi"
192.168.177.131 ansible_port=22 ansible_user="root" ansible_ssh_pass="moxi"
192.168.177.132 ansible_port=22 ansible_user="root" ansible_ssh_pass="moxi"
; 单 master 节点不需要进行负载均衡,lb节点组留空。
[lb]
; 注意etcd集群必须是1,3,5,7...奇数个节点
[etcd]
192.168.177.130
192.168.177.131
192.168.177.132
[kube-master]
192.168.177.130
[kube-worker]
192.168.177.130
192.168.177.131
192.168.177.132
; 预留组,后续添加master节点使用
[new-master]
; 预留组,后续添加worker节点使用
[new-worker]
; 预留组,后续添加etcd节点使用
[new-etcd]
; 预留组,后续删除worker角色使用
[del-worker]
; 预留组,后续删除master角色使用
[del-master]
; 预留组,后续删除etcd角色使用
[del-etcd]
; 预留组,后续删除节点使用
[del-node]
;-------------------------------------- 以下为基础信息配置 ------------------------------------;
[all:vars]
; 是否跳过节点物理资源校验,Master节点要求2c2g以上,Worker节点要求2c4g以上
skip_verify_node=true
; kubernetes版本
kube_version="1.18.14"
; 负载均衡器
; 有 nginx、openresty、haproxy、envoy 和 slb 可选,默认使用 nginx
; 为什么单 master 集群 apiserver 也使用了负载均衡请参与此讨论: https://github.com/TimeBye/kubeadm-ha/issues/8
lb_mode="nginx"
; 使用负载均衡后集群 apiserver ip,设置 lb_kube_apiserver_ip 变量,则启用负载均衡器 + keepalived
; lb_kube_apiserver_ip="192.168.56.15"
; 使用负载均衡后集群 apiserver port
lb_kube_apiserver_port="8443"
; 网段选择:pod 和 service 的网段不能与服务器网段重叠,
; 若有重叠请配置 `kube_pod_subnet` 和 `kube_service_subnet` 变量设置 pod 和 service 的网段,示例参考:
; 如果服务器网段为:10.0.0.1/8
; pod 网段可设置为:192.168.0.0/18
; service 网段可设置为 192.168.64.0/18
; 如果服务器网段为:172.16.0.1/12
; pod 网段可设置为:10.244.0.0/18
; service 网段可设置为 10.244.64.0/18
; 如果服务器网段为:192.168.0.1/16
; pod 网段可设置为:10.244.0.0/18
; service 网段可设置为 10.244.64.0/18
; 集群pod ip段,默认掩码位 18 即 16384 个ip
kube_pod_subnet="10.244.0.0/18"
; 集群service ip段
kube_service_subnet="10.244.64.0/18"
; 分配给节点的 pod 子网掩码位,默认为 24 即 256 个ip,故使用这些默认值可以纳管 16384/256=64 个节点。
kube_network_node_prefix="24"
; node节点最大 pod 数。数量与分配给节点的 pod 子网有关,ip 数应大于 pod 数。
; https://cloud.google.com/kubernetes-engine/docs/how-to/flexible-pod-cidr
kube_max_pods="110"
; 集群网络插件,目前支持flannel,calico
network_plugin="calico"
; 若服务器磁盘分为系统盘与数据盘,请修改以下路径至数据盘自定义的目录。
; Kubelet 根目录
kubelet_root_dir="/var/lib/kubelet"
; docker容器存储目录
docker_storage_dir="/var/lib/docker"
; Etcd 数据根目录
etcd_data_dir="/var/lib/etcd"
升级内核
修改完配置文件后建议升级内核
ansible-playbook -i example/hosts.s-master.ip.ini 00-kernel.yml
内核升级完毕后重启所有节点 在master node1 node2上执行
开始部署k8s
等待所有的节点重启完成后进入脚本目录
cd kubeadm-ha
执行一键部署命令
ansible-playbook -i example/hosts.s-master.ip.ini 90-init-cluster.yml
查看节点运行情况
kubectl get nodes
等待所有节点ready 即为创建成功
NAME STATUS ROLES AGE VERSION
192.168.28.128 Ready etcd,worker 2m57s v1.18.14
192.168.28.80 Ready etcd,master,worker 3m29s v1.18.14
192.168.28.89 Ready etcd,worker 2m57s v1.18.14
集群重置
如果部署失败了,想要重置整个集群【包括数据】,执行下面脚本
ansible-playbook -i example/hosts.s-master.ip.ini 99-reset-cluster.yml
部署kuboard
安装Docker
因为我们需要拉取镜像,所以需要在服务器提前安装好Docker,首先配置一下Docker的阿里yum源
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
然后yum方式安装docker
# yum安装
yum -y install docker-ce
# 查看docker版本
docker --version
# 开机自启
systemctl enable docker
# 启动docker
systemctl start docker
配置docker的镜像源
mkdir /etc/docker
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://vgiqiiwr.mirror.aliyuncs.com"]
}
EOF
重启Docker
systemctl restart docker
安装Kuboard【可选】
简介
Kuboard 是一款免费的 Kubernetes 图形化管理工具,力图帮助用户快速在 Kubernetes 上落地微服务。
Kuboard文档:https://kuboard.cn/
安装
在master节点执行
kubectl apply -f https://kuboard.cn/install-script/kuboard.yaml
kubectl apply -f https://addons.kuboard.cn/metrics-server/0.3.7/metrics-server.yaml
查看 Kuboard 运行状态
kubectl get pods -l k8s.kuboard.cn/name=kuboard -n kube-system
输出结果如下所示。注意:如果是 ContainerCreating 那么需要等待一会
NAME READY STATUS RESTARTS AGE
kuboard-74c645f5df-cmrbc 1/1 Running 0 80s
访问Kuboard
Kuboard Service 使用了 NodePort 的方式暴露服务,NodePort 为 32567;您可以按如下方式访问 Kuboard。
# 格式
http://任意一个Worker节点的IP地址:32567/
# 例如,我的访问地址如下所示
http://192.168.177.130:32567/
页面如下所示:
第一次访问需要输入token 我们获取一下 token, 在master节点执行
echo $(kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep kuboard-user | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d)
获取到的 token,然后粘贴到框中,我的 token 格式如下:
eyJhbGciOiJSUzI1NiIsImtpZCI6ImY1eUZlc0RwUlZha0E3LWZhWXUzUGljNDM3SE0zU0Q4dzd5R3JTdXM2WEUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJvYXJkLXVzZXItdG9rZW4tMmJsamsiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoia3Vib2FyZC11c2VyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYzhlZDRmNDktNzM0Zi00MjU1LTljODUtMWI5MGI4MzU4ZWMzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmt1Ym9hcmQtdXNlciJ9.MujbwGnkL_qa3H14oKDT1zZ5Fzt16pWoaY52nT7fV5B2nNIRsB3Esd18S8ztHUJZLRGxAhBwu-utToi2YBb8pH9RfIeSXMezFZ6QhBbp0n5xYWeYETQYKJmes2FRcW-6jrbpvXlfUuPXqsbRX8qrnmSVEbcAms22CSSVhUbTz1kz8C7b1C4lpSGGuvdpNxgslNFZTFrcImpelpGSaIGEMUk1qdjKMROw8bV83pga4Y41Y6rJYE3hdnCkUA8w2SZOYuF2kT1DuZuKq3A53iLsvJ6Ps-gpli2HcoiB0NkeI_fJORXmYfcj5N2Csw6uGUDiBOr1T4Dto-i8SaApqmdcXg
最后即可进入kuboard的dashboard界面
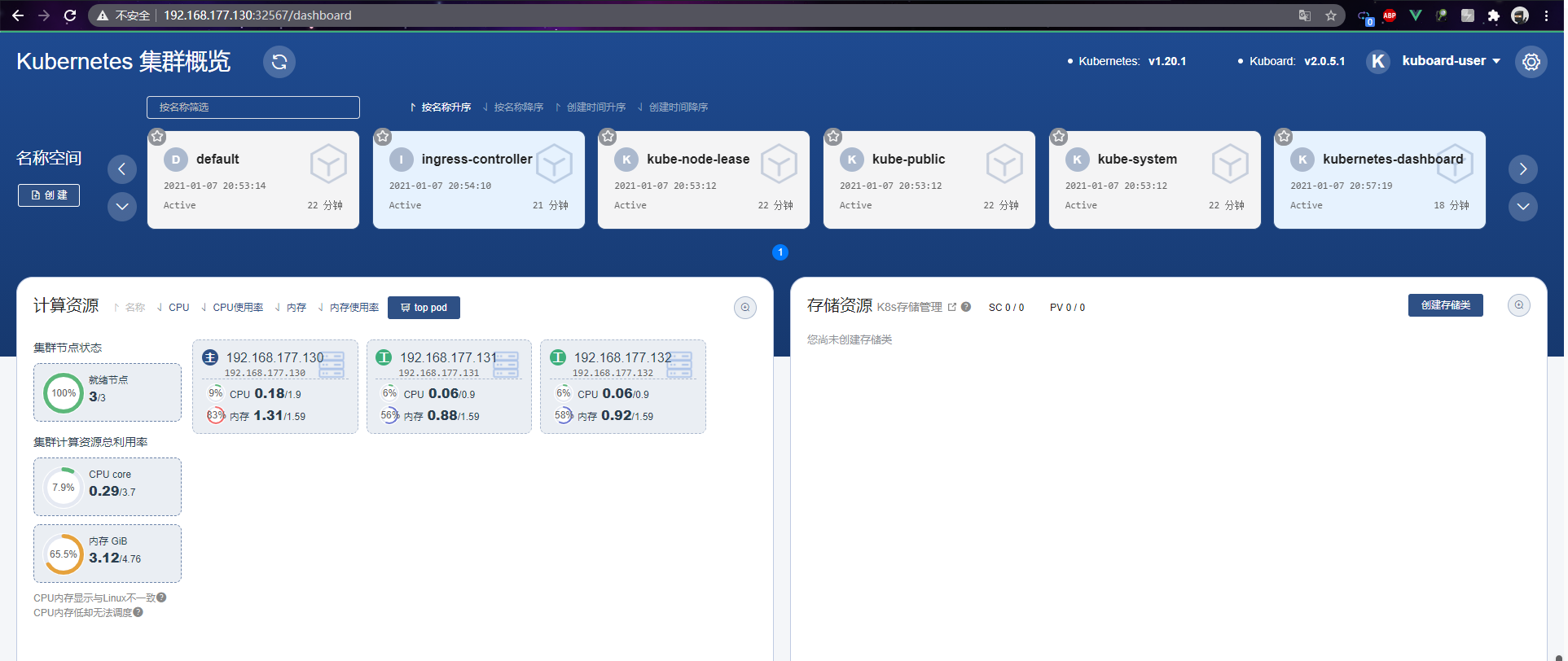
卸载Kuboard
当我们 kuboard 不想使用的时候,我们就可以直接卸载
kubectl delete -f https://kuboard.cn/install-script/kuboard.yaml
kubectl delete -f https://addons.kuboard.cn/metrics-server/0.3.7/metrics-server.yaml
Rancher部署【可选】
kuboard和rancher建议部署其中一个
helm安装
使用helm部署rancher会方便很多,所以需要安装helm
curl -O http://rancher-mirror.cnrancher.com/helm/v3.2.4/helm-v3.2.4-linux-amd64.tar.gz
tar -zxvf helm-v3.2.4-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin
验证
helm version
输入以下内容说明helm安装成功
version.BuildInfo{Version:"v3.2.4", GitCommit:"0ad800ef43d3b826f31a5ad8dfbb4fe05d143688", GitTreeState:"clean", GoVersion:"go1.13.12"}
添加rancher chart仓库
helm repo add rancher-stable http://rancher-mirror.oss-cn-beijing.aliyuncs.com/server-charts/stable
helm repo update
安装rancher
helm install rancher rancher-stable/rancher \
--create-namespace \
--namespace cattle-system \
--set hostname=rancher.local.com
等待 Rancher 运行:
kubectl -n cattle-system rollout status deploy/rancher
输出信息:
Waiting for deployment "rancher" rollout to finish: 0 of 3 updated replicas are available...
deployment "rancher" successfully rolled out
八、 Kubernetes可视化界面kubesphere
前言
kubernetes也提供了默认的dashboard页面,但是功能不是很强大,这里就不使用了
这里采用kubesphere打通全部的devops链路,通过kubesphere集成了很多套件
简介
KubeSphere是一款面向云原生设计的开源项目,在目前主流容器调度平台Kubernetes之上构建的分布式多租户容器管理平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大降低开发、测试、运维的日常工作的复杂度。
安装
前提条件
https://kubesphere.com.cn/docs/quick-start/minimal-kubesphere-on-k8s/
- Kubernetes 版本必须为 “1.15.x,1.16.x,1.17.x 或 1.18.x”;
- 确保您的计算机满足最低硬件要求:CPU > 1 核,内存 > 2 G;
- 在安装之前,需要配置 Kubernetes 集群中的默认存储类;
- 当使用
--cluster-signing-cert-file和--cluster-signing-key-file参数启动时,在 kube-apiserver 中会激活 CSR 签名功能。 请参阅 RKE 安装问题; - 有关在 Kubernetes 上安装 KubeSphere 的前提条件的详细信息,请参阅前提条件。
安装helm
下面我们需要在 master 节点安装 helm
Helm是Kubernetes的包管理器。包管理器类似于我们在 Ubuntu 中使用的 apt。Centos 中使用的 yum 或者Python 中的 pip 一样,能快速查找、下载和安装软件包。Helm由客户端组件helm和服务端组件Tiller组成,能够将一组K8S资源打包统一管理,是查找、共享和使用为Kubernetes构建的软件的最佳方式。
安装3.0的 helm 首先我们需要去 官网下载
- 第一步,下载helm安装压缩文件,上传到linux系统中
- 第二步,解压helm压缩文件,把解压后的helm目录复制到 usr/bin 目录中
- 使用命令:helm
部署KubeSphere
安装前
如果您的服务器无法访问 GitHub,则可以分别复制 kubesphere-installer.yaml 和 cluster-configuration.yaml 中的内容并将其粘贴到本地文件中。然后,您可以对本地文件使用 kubectl apply -f 来安装 KubeSphere。
同时查看k8s集群的默认存储类
kubectl get storageclass

如果没有默认存储类,那么就需要安装默认的存储类,参考博客:Kubernetes配置默认存储类
因为我安装的是 nfs,所以在安装了 nfs 服务器启动
systemctl start nfs
开始安装
如果无法正常访问github,可以提前把文件下载到本地
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
如果下载到了本地,可以这样安装
# 安装
kubectl apply -f kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
# 卸载
kubectl delete -f kubesphere-installer.yaml
kubectl delete -f cluster-configuration.yaml
检查安装日志
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
然后在查看pod运行状况
kubectl get pod -n kubesphere-system
能够发现,我们还有两个容器正在创建
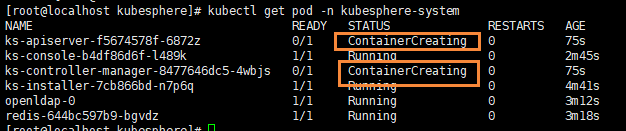
使用 kubectl get pod --all-namespaces 查看所有 Pod 是否在 KubeSphere 的相关命名空间中正常运行。
kubectl get pods --all-namespaces
能够发现所有的节点已经成功运行
如果是,请通过以下命令检查控制台的端口:
kubectl get svc/ks-console -n kubesphere-system
能够看到我们的服务确保在安全组中打开了端口 30880,并通过 NodePort(IP:30880)

使用默认帐户和密码(admin/P@88w0rd)访问 Web 控制台。
# 图形化页面 admin P@88w0rd
http://192.168.177.130:30880/
登录控制台后,您可以在组件中检查不同组件的状态。如果要使用相关服务,可能需要等待某些组件启动并运行。
错误排查
错误1
kubesphere无法登录,提示account is not active
kubesphere 安装完成后会创建默认账户admin/P@88w0rd,待ks-controller-manager启动就绪,user controller 会将 user CRD中定义的password加密,user会被转换为active状态,至此账户才可以正常登录。
当安装完成后遇到默认账户无法登录,看到account is not active相关错误提示时,需要检查ks-controller-manager的运行状态和日志。常见问题及解决方式如下:
kubectl -n kubesphere-system get ValidatingWebhookConfiguration users.iam.kubesphere.io -o yaml >> users.iam.kubesphere.io.yaml
kubectl -n kubesphere-system get secret ks-controller-manager-webhook-cert -o yaml >> ks-controller-manager-webhook-cert.yaml
# edit ca as pr
kubectl -n kubesphere-system apply -f ks-controller-manager-webhook-cert.yaml
kubectl -n kubesphere-system apply -f users.iam.kubesphere.io.yaml
# restart
kubectl -n kubesphere-system rollout restart deploy ks-controller-manager
九、 Kubernetes配置默认存储类
前言
今天在配置Kubesphere的时候,出现了下面的错误
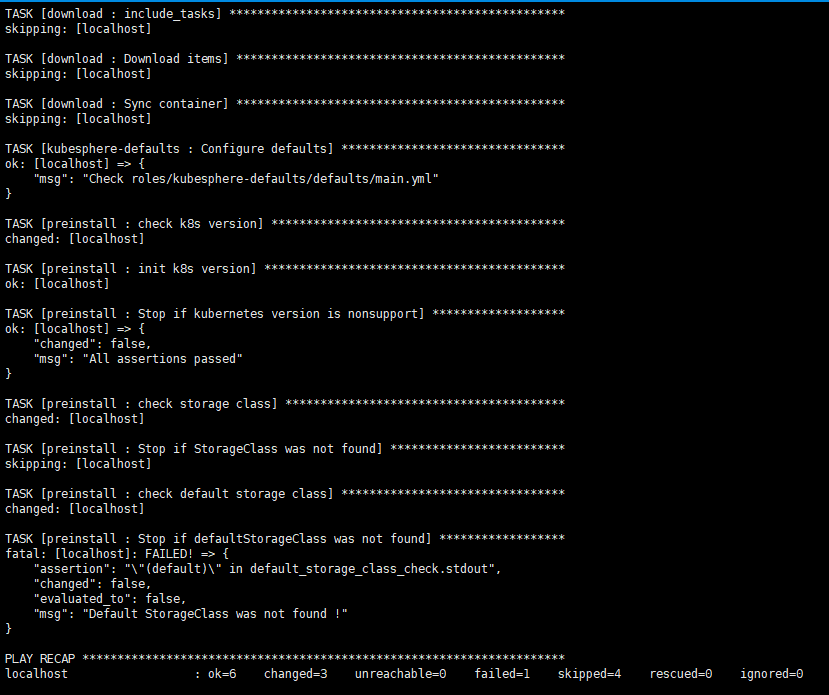
经过排查,发现是这个原因

我通过下面命令,查看Kubernetes集群中的默认存储类
kubectl get storageclass
发现空空如也,所以问题应该就出现在这里了~,下面我们给k8s集群安装上默认的存储类
安装nfs
我们使用的是nfs来作为k8s的存储类
首先找一台新的服务器,作为nfs服务端,然后进行 nfs的安装 【服务器:192.168.177.141】
然后使用命令安装nfs
yum install -y nfs-utils
首先创建存放数据的目录
mkdir -p /data/k8s
设置挂载路径
# 打开文件
vim /etc/exports
# 添加如下内容
/data/k8s *(rw,no_root_squash)
node节点上安装
然后需要在k8s集群node节点上安装nfs,这里需要在 node1 和 node2节点上安装
yum install -y nfs-utils
执行完成后,会自动帮我们挂载上
启动nfs
在node节点上配置完成后,我们就接着到刚刚nfs服务器,启动我们的nfs
systemctl start nfs
配置StorageClass
要使用StorageClass,我们就得安装对应的自动配置程序,比如上面我们使用的是nfs,那么我们就需要使用到一个 nfs-client 的自动配置程序,我们也叫它 Provisioner,这个程序使用我们已经配置的nfs服务器,来自动创建持久卷,也就是自动帮我们创建PV
自动创建的 PV 以${namespace}-${pvcName}-${pvName}这样的命名格式创建在 NFS 服务器上的共享数据目录中
而当这个 PV 被回收后会以archieved-${namespace}-${pvcName}-${pvName}这样的命名格式存在 NFS 服务器上。
当然在部署nfs-client之前,我们需要先成功安装上 nfs 服务器,上面已经安装好了,服务地址是192.168.177.141,共享数据目录是/data/k8s/,然后接下来我们部署 nfs-client 即可,我们也可以直接参考 nfs-client 文档,进行安装即可。
配置Deployment
首先配置 Deployment,将里面的对应的参数替换成我们自己的 nfs 配置(nfs-client.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.177.141
- name: NFS_PATH
value: /data/k8s
volumes:
- name: nfs-client-root
nfs:
server: 192.168.177.141
path: /data/k8s
替换配置
将环境变量 NFS_SERVER 和 NFS_PATH 替换,当然也包括下面的 nfs 配置,我们可以看到我们这里使用了一个名为 nfs-client-provisioner 的serviceAccount,所以我们也需要创建一个 sa,然后绑定上对应的权限:(nfs-client-sa.yaml)
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
我们这里新建的一个名为 nfs-client-provisioner 的ServiceAccount,然后绑定了一个名为 nfs-client-provisioner-runner 的ClusterRole,而该ClusterRole声明了一些权限,其中就包括对persistentvolumes的增、删、改、查等权限,所以我们可以利用该ServiceAccount来自动创建 PV。
创建StorageClass对象
nfs-client 的 Deployment 声明完成后,我们就可以来创建一个StorageClass对象了:(nfs-client-class.yaml)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: course-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
我们声明了一个名为 course-nfs-storage 的StorageClass对象,注意下面的provisioner对应的值一定要和上面的Deployment下面的 PROVISIONER_NAME 这个环境变量的值一样
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: course-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
创建资源对象
在我们准备好上述的配置文件后,我们就可以开始创建我们的资源对象了
kubectl create -f nfs-client.yaml
kubectl create -f nfs-client-sa.yaml
kubectl create -f nfs-client-class.yaml
创建完成后,使用下面命令来查看资源状态
kubectl get pods
# 查看存储类
kubectl get storageclass

我们可以设置这个 course-nfs-storage 的 StorageClass 为 Kubernetes 的默认存储后端,我们可以用 kubectl patch 命令来更新
kubectl patch storageclass course-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
执行完命令后,我们默认存储类就配置成功了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号