统计学习方法》笔记--提升方法(二)
AdaBoost算法流程:
输入:训练数据集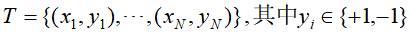 和弱学习方法;
和弱学习方法;
输出:最终分类器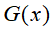 ;
;
- 初始化训练数据的权值分布(初始平均分配,D的下标和
![]() 的第一个下标表示训练的轮次)
的第一个下标表示训练的轮次)
![]()
- 对于第m次训练,
![]()
- 使用具有权值分布
![]() 的训练数据集学习,得到基本分类器
的训练数据集学习,得到基本分类器
![]()
- 计算
![]() 在训练数据集上分类误差率
在训练数据集上分类误差率
![]()
- 计算
![]() 的系数
的系数
![]()
- 更新训练数据集的权值
![]()
- 使用具有权值分布
- 将上述得到的弱分类器进行线性组合
![]()
最终得到分类器
![]()
AdaBoost实现的关键在
![]() 基本分类器的确定,
基本分类器的确定,
# 在权值分布为 D_m 的训练数据上,找出第 j 维度上使误差率最小的基本分类器
def _G(self, features, labels, weights):
m = len(features)
error = 100000.0 # 无穷大
best_v = 0.0
# 第 j 维的特征 features
features_min = min(features)
features_max = max(features)
# 根据第 j 维度上的最大小值和学习率,计算分类器的划分个数
n_step = (features_max - features_min + self.learning_rate) // self.learning_rate
direct, compare_array = None, None
for i in range(1, int(n_step)):
# 计算出基本分类器的 划分 阈值
v = features_min + self.learning_rate * i
if v not in features:
# 误分类计算,根据阈值的左边为正类或负类的划分,确定能使误分类率最小的划分方法
compare_array_positive = np.array([1 if features[k] > v else -1 for k in range(m)])
weight_error_positive = sum([weights[k] for k in range(m) if compare_array_positive[k] != labels[k]])
compare_array_nagetive = np.array([-1 if features[k] > v else 1 for k in range(m)])
weight_error_nagetive = sum([weights[k] for k in range(m) if compare_array_nagetive[k] != labels[k]])
if weight_error_positive < weight_error_nagetive:
weight_error = weight_error_positive
_compare_array = compare_array_positive
direct = 'positive'
else:
weight_error = weight_error_nagetive
_compare_array = compare_array_nagetive
direct = 'nagetive'
if weight_error < error:
error = weight_error
compare_array = _compare_array
best_v = v
return best_v, direct, error, compare_array
def fit(self, X, y):
self.init_args(X, y)
for epoch in range(self.clf_num):
best_clf_error, best_v, clf_result = 100000, None, None
# 根据特征维度, 选择误差最小的
for j in range(self.N):
features = self.X[:, j]
# 分类阈值,分类划分方法,分类误差,分类结果
v, direct, error, compare_array = self._G(features, self.Y, self.weights)
if error < best_clf_error:
best_clf_error = error
best_v = v
final_direct = direct
clf_result = compare_array
axis = j
if best_clf_error == 0:
break
# 计算 G(x) 系数 a
a = self._alpha(best_clf_error)
self.alpha.append(a)
# 记录分类器
self.clf_sets.append((axis, best_v, final_direct))
# 规范化因子
Z = self._Z(self.weights, a, clf_result)
# 权值更新
self._w(a, clf_result, Z)
根据书中的例子,训练数据如下表1-1
序号
1
2
3
4
5
6
7
8
9
10
x
0
1
2
3
4
5
6
7
8
9
y
1
1
1
-1
-1
-1
1
1
1
-1
表1-1训练数据集
假设弱分类器由 x<v 或 x>v 产生,其阈值v 使给分类器在训练数据集上分类误差率最低。
利用上述的代码对数据集进行训练,结果如下
![]()
图1-1 训练结果
得到的过程的结果与笔算的结果相同,则最终该训练数据集的最终分类器为
![]()
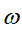 的第一个下标表示训练的轮次)
的第一个下标表示训练的轮次)
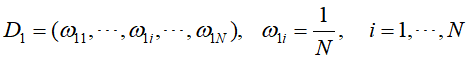
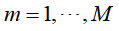
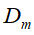 的训练数据集学习,得到基本分类器
的训练数据集学习,得到基本分类器
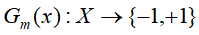
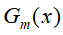 在训练数据集上分类误差率
在训练数据集上分类误差率
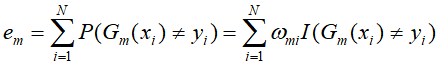
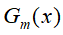 的系数
的系数
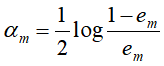
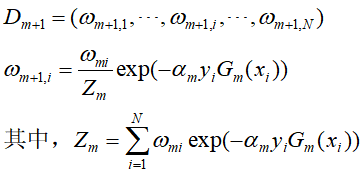
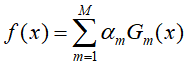
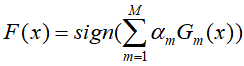
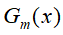 基本分类器的确定,
基本分类器的确定,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号