Hadoop搭建之伪分布式搭建
伪分布式搭建:所有的角色都安装在一台机器上,主要用于快速使用,模拟分布式场景。
参考网址:
https://www.cnblogs.com/jhxxb/p/10562460.html
https://www.cnblogs.com/qingyunzong/p/8496127.html#_label4_4
1.前提条件
(0)规划安装目录
主节点 nameNode resourceManager
从节点 dataNode nodeManager
(由于是一台虚拟机,没有设置secondaryNameNode)
规划安装目录:/opt/hadoop/apps
规划数据目录:/opt/hadoop/data
mkdir -p /opt/hadoop/apps mkdir -p /opt/hadoop/data
(1)JDK
小贴士:/etc/profile是系统环境变量;~/.bashrc是个人环境变量(如果是普通用户,推荐配置)
#1.解压包
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/hadoop/apps
#2.配置环境变量
vim ~/.bashrc
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
#3.使得环境变量生效
source ~/.bashrc
#4.验证
java -version #如果显示为Linux自带OpenJdk(如下),需要先卸载
#[root@localhost apps]# java -version
#openjdk version "1.8.0_242"
#OpenJDK Runtime Environment (build 1.8.0_242-b08)
#OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)
#参考网址:https://blog.csdn.net/qq_35535690/article/details/81976210
rpm -qa|grep java
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.242.b08-1.el7.x86_64
(2)修改主机名和hosts文件
参考网址:https://blog.csdn.net/shmily_lsl/article/details/81164404
小贴士:
主机名hostname和/etc/hosts是不一样的,hostname是主机名称,hosts是主机名和IP的映射关系,后者不能设置主机名。之所以有这样的错觉,是因为:
当主机名为localhost或者localhost.localdomain时(hostname命令可以查看主机名),系统会根据实际IP,去匹配hosts文件中的IP,将主机名设置为对应hosts里面的主机名。
例如:hostname为localhost,本机IP为192.168.56.100,当hosts文件设置 192.168.56.100 master时,我们看到的hostname就变成了master
第一步、修改主机名
cat /etc/redhat-release #查看操作系统版本
#1.操作系统是Centos6
#1.1永久生效,重启生效
vim /etc/sysconfig/network
NETWORKING=yes GATEWAY=192.168.56.1 HOSTNAME=master #添加这一行
#1.2临时生效
hostname master
#2.操作系统是Centos7
hostnamectl set-hostname #会修改/etc/hostname 、/etc/machine-info 两个文件
# 参考网址 http://www.361way.com/centos7-hostnamectl/3816.html
#注意:不记得命令可以敲 hostnamectl --help
保险起见:1.1和2都执行一遍
第二步、修改hosts文件
vim /etc/hosts 192.168.56.100 master
(3)免密登录
参考网址:SSH原理 https://www.jianshu.com/p/33461b619d53
# 设置SSH远程登录免密,在ssh localhost本地免密登录中,既是客户端,又是服务端;客户端需要保留私钥,服务端需要保留公钥并命名为authorized_keys。
当客户端发起登录时,客户端将公钥发给服务端,服务端收到公钥后在authorized_keys中查找,如果找到,则会生产随机数R,用公钥对其加密,返回给客户端。
客户端收到后,用私钥解密。然后将解密得到的R和session_id用md5加密发送给服务端;服务端同样用md5对其进行(R,session_id)加密,如果得到的值相等,则可免密登录。
# ssh-keygen 用于生成公钥,私钥;公钥是由私钥产生,公钥用于加密和验签,私钥用于解密和签名
# rsa算法用于加密解密,数字签名,但是速度慢;dsa用于数字签名,签名和解密的速度快,加密和验签速度慢
cd ~/.ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #-t指定算法,默认为rsa -P指定私钥,一般不指定 -f指定生成的密钥,默认是id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys # 将公钥追加到authorized_keys中
(4)关闭防火墙
#永久关闭防火墙 systemctl disable firewalld #临时关闭防火墙 systemctl stop firewalld #注意:如果系统报错java.io.IOException: Got error, status message , ack with firstBadLink as 192.168.56.102:50010 #可能是由于没有关闭防火墙导致的,第一条命令不会及时生效,所以还需要第二条命令
1.搭建
(1)解压包并配置环境变量
#1.解压包
unzip hadoop-2.7.1.zip -d /opt/hadoop/apps
#2.配置环境变量
vim ~/.bashrc
export HADOOP_HOME=/opt/hadoop/apps/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#3.使得环境变量生效
~/.bashrc
(2)配置HDFS
A.修改hadoop-env.sh
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161
B.修改core-site.xml
<configuration> <property> <!--指定HDFS中namenode的地址 --> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <!--指定Hadoop运行时产生文件的目录 --> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data/hadoopdata/tmp</value> </property> </configuration>
C.修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop/data/namenode</value> <description>为了保证元数据的安全一般配置多个不同目录</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/data/datanode</value> <description>datanode 的数据存储目录</description> </property> <property> <name>dfs.replication</name> <value>1</value> <description>HDFS 的数据块的副本存储个数, 默认是3</description> </property> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>true</value> <description>默认为true,namenode 连接 datanode 时会进行 host 解析查询;如果是false,则会按照IP进行解析</description> </property> </configuration>
D.启动及验证
#如果命令没有执行权限,需要赋予执行的权限
chmod +x /opt/hadoop/apps/hadoop-2.7.1/bin/*
chmod +x /opt/hadoop/apps/hadoop-2.7.1/sbin/*
# 第一次使用需要先格式化一次。之前若格式化过请先停止进程,然后删除文件再执行格式化操作
hdfs namenode -format
# 启动 namenode
hadoop-daemon.sh start namenode
# 启动 datanode
hadoop-daemon.sh start datanode
# 验证,查看 jvm 进程
jps4728 NameNode
4776 DataNode
4813 Jps
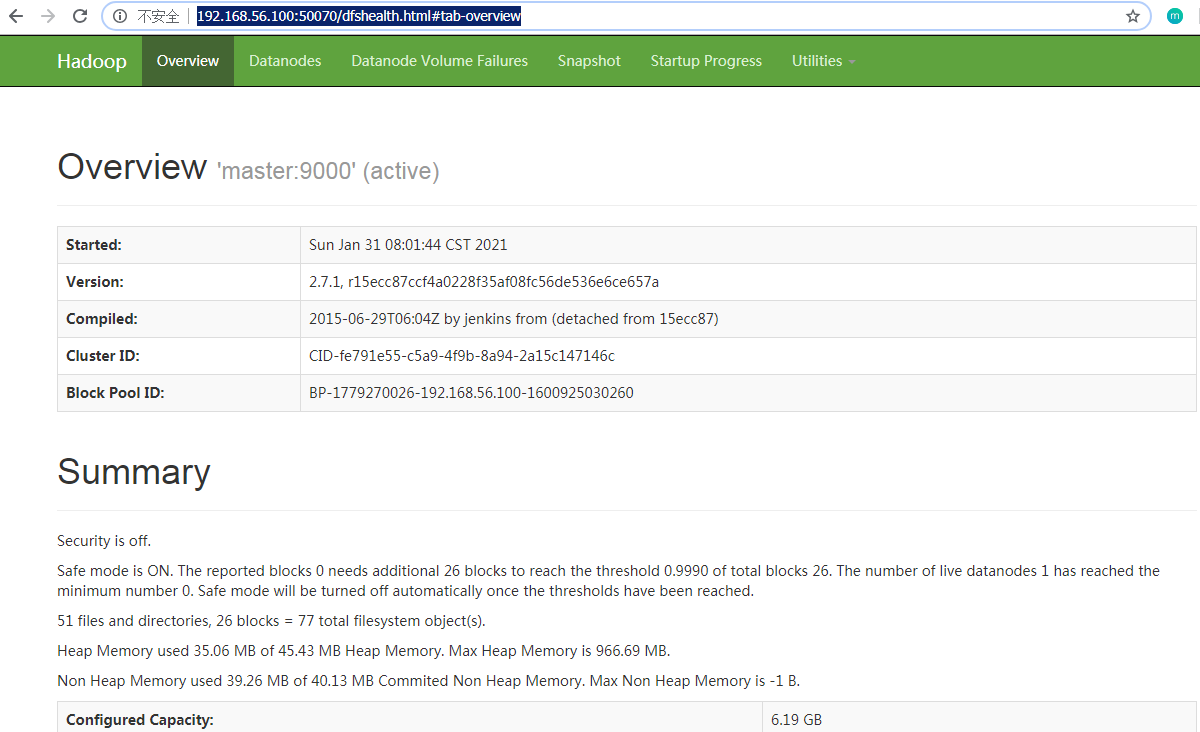
http://192.168.56.100:50070/dfshealth.html#tab-overview
(3)配置YARN
A.修改yarn-env.sh
# 配置 JDK 路径
# some Java parameters
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161
B.修改yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> <description>指定resourcemanager节点</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description> </property> </configuration>
C.启动及验证
# 启动 resourcemanager
yarn-daemon.sh start resourcemanager
# 启动 nodemanager
yarn-daemon.sh start nodemanager
# 查看 JVM 进程
jps
5875 ResourceManager
5925 NodeManager
5957 Jps
4728 NameNode
4776 DataNode

(4)配置MapReduce
A.修改mapred-env.sh
# 配置 JDK 路径
export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161
# when HADOOP_JOB_HISTORYSERVER_HEAPSIZE is not defined, set it.
B.修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration> <!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
C.启动及验证
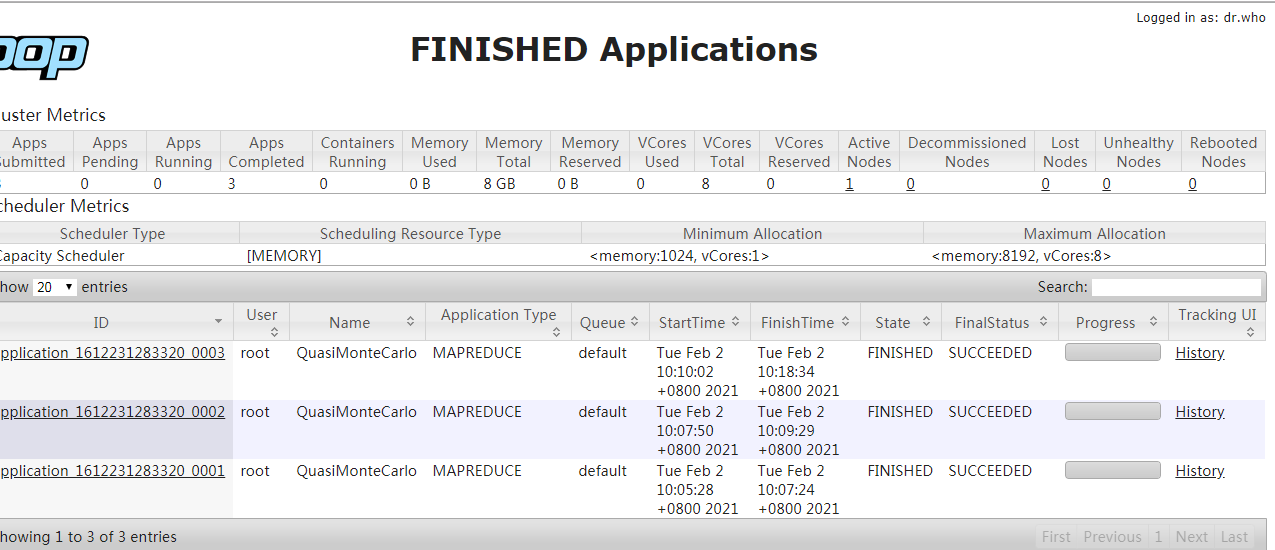
运行一个mapreduce任务
#计算圆周率 表示2个map任务,每个任务生成10个点,点越多,计算结果越精确
hadoop jar /opt/hadoop/apps/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 2 10
#注意如果是配置比较低(1G内存,8G硬盘)设置太大,内存不足,容易报错,
(5)配置JobHistory
mapred-site.xml
<configuration> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> </property> </configuration>
# 启动 jobhistory
mr-jobhistory-daemon.sh start historyserver
# JVM 进程
jps
# 1995 NodeManager
# 1781 DataNode
# 4917 Jps
# 1717 NameNode
# 1935 ResourceManager
# 4862 JobHistoryServer
浏览器访问 CentOS 的 IP 地址加端口号 (默认19888) 即可看到 web 端

(6)配置日志聚集
yarn-site.xml
<configuration> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志保留时间(7天) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
# 需要重启一遍服务
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
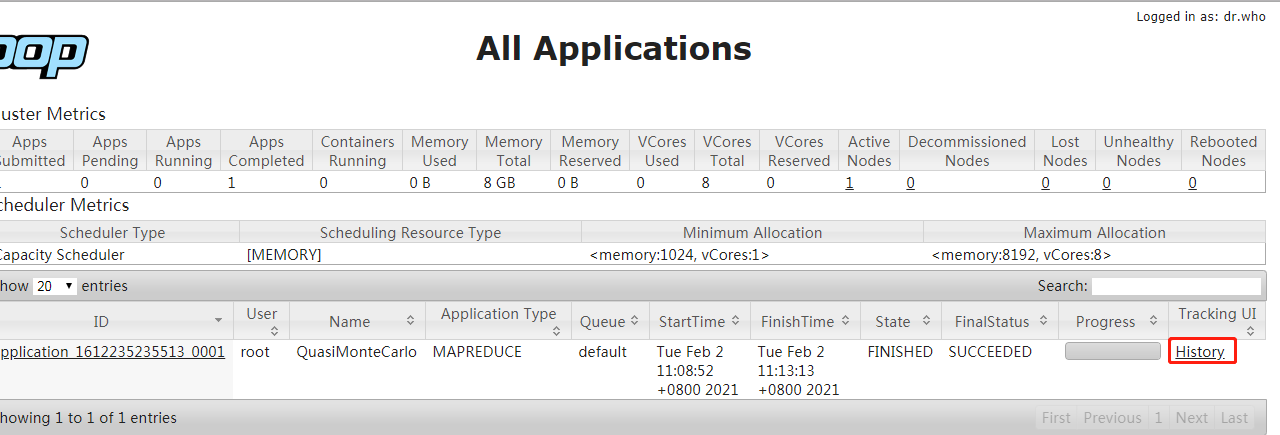
# 再运行一个任务,就可以看到详情
hadoop jar /opt/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar pi 10 100
查看刚刚运行的任务详情,未开启日志聚集之前运行的任务无法查看详情
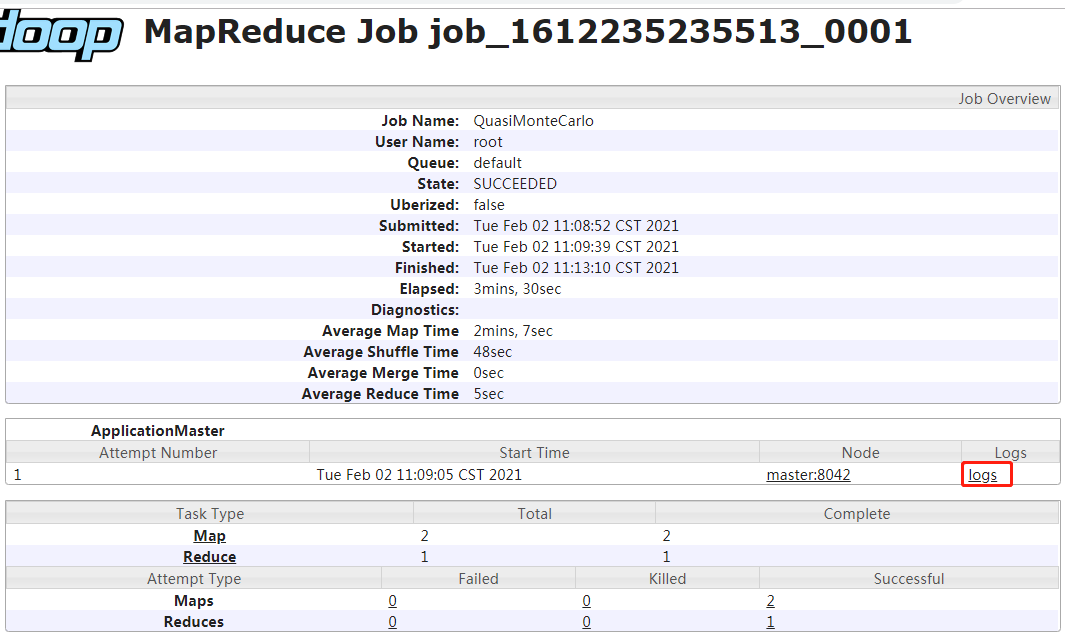
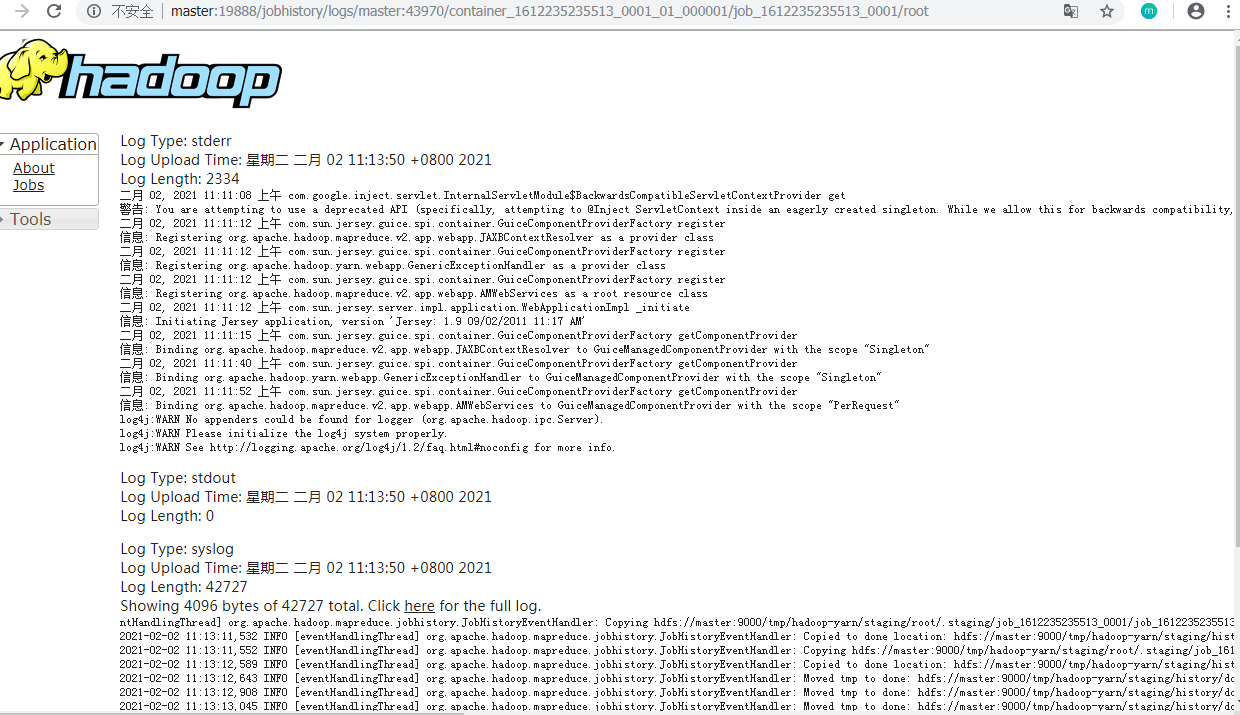
日志聚集功能的应用场景:将日志保存到hdfs,为了防止程序运行完成后,不能查看日志,方便对运行中出现的错误,进行追踪和调试。
参考网址:https://blog.csdn.net/qq_31923871/article/details/107022797?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-11&spm=1001.2101.3001.4242

