scrapy——分别存储在文本文件和mysql数据库中
笔记
如何将爬取到的数据一份存储到本地一份存储到数据库?
- 创建一个管道类
- 爬虫文件提交到的item指挥给管道文件中的第一个被执行的管道类接收
- process_item方法中的return item表示将item提交给下一个管道类在pipelines类中加入MysqlPiplines类
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class DoubanPipeline:
fp = None
#重写弗雷方法 该方法只在开始爬虫时调用一次
def open_spider(self,spider):
print('开始爬虫!!!')
# 打开文件
self.fp = open('douban.txt','w',encoding='utf-8')
# 专门用来处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
title_ = item['title']
content_ = item['content']
self.fp.write(title_+':'+content_+'\n')
return item
def close_spider(self,spider):
self.fp.close()
class MysqlPipeline:
coon = None
cursor = None
#重写弗雷方法 该方法只在开始爬虫时调用一次
def open_spider(self,spider):
self.coon = pymysql.connect(host='localhost',user='root',password='your_password',db='test',charset='utf8')
# 打开文件
# 专门用来处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
self.cursor = self.coon.cursor()
try:
self.cursor.execute('insert into douban values ("%s","%s")'%(item['title'],item['content']))
self.coon.commit()
except Exception as e:
print(e)
self.coon.rollback()
return item
def close_spider(self,spider):
print('结束爬虫!!!')
self.cursor.close()
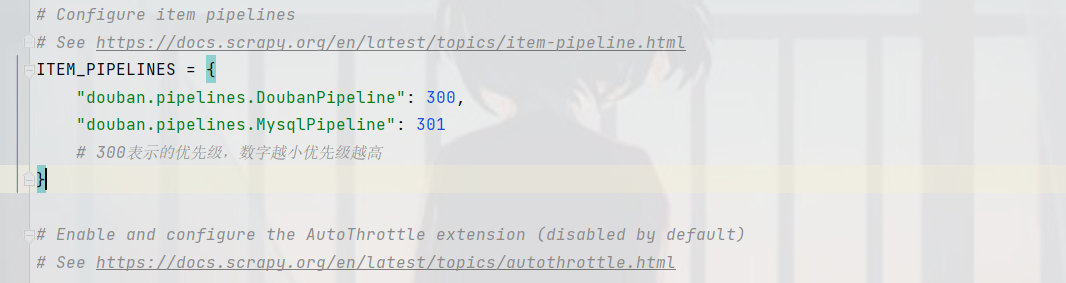
self.coon.close()在settings类中加入MysqlPiplines开启

 浙公网安备 33010602011771号
浙公网安备 33010602011771号