防盗链——爬取梨视频
这个爬虫做了很久 有几个问题
1.防盗链的问题:如下图所示Referer 这个就是回溯上一个网页 如果上一个网页不是Referer就会报错
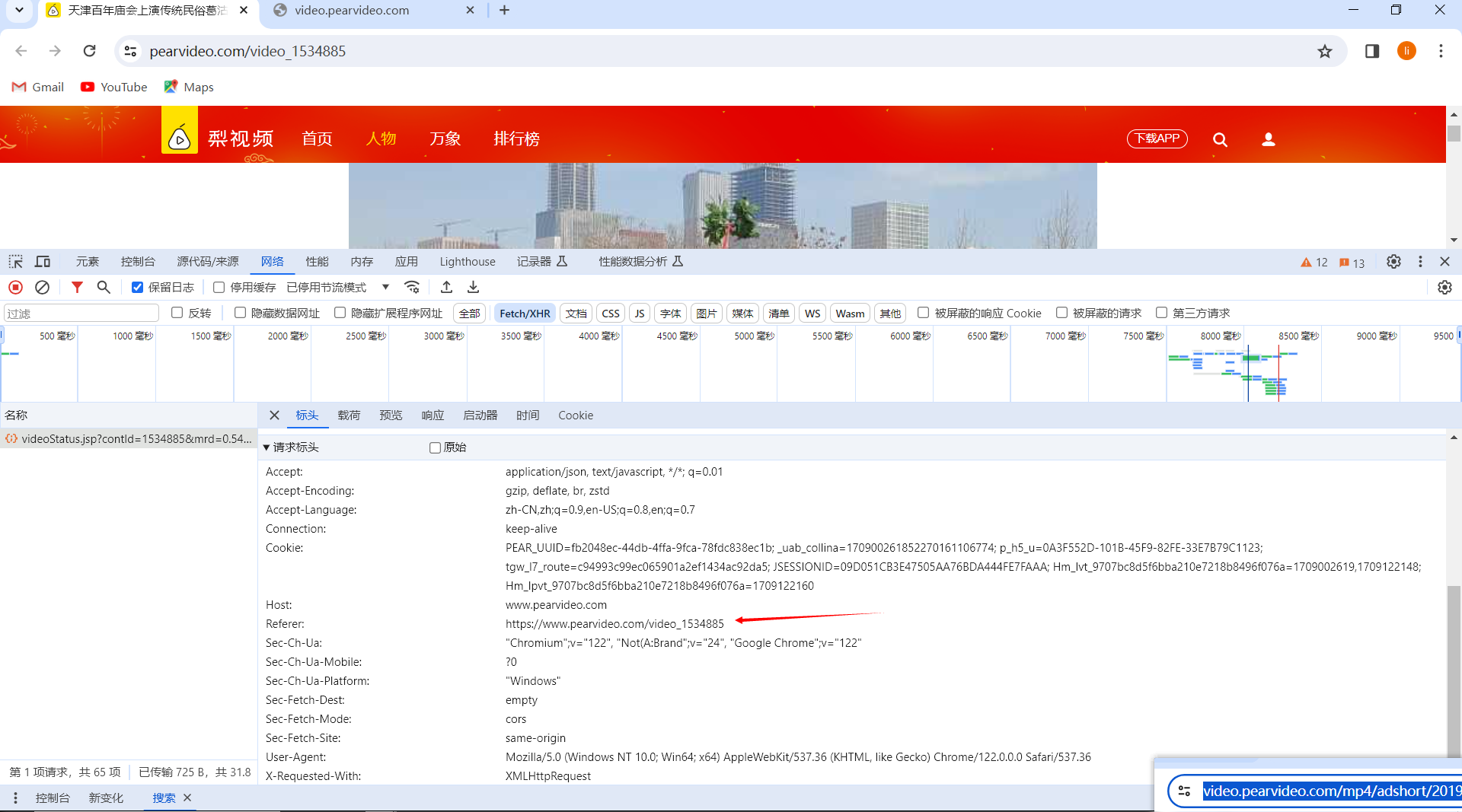

这个就是我没有从那个网页访问的结果
2.在我自己爬取的时候不知道mrd是什么东西 以为跟countId一样是一个标识的东西 结果这只是一个随机的数
代码
# 防盗链:请求网址的上一级 只能从一个网址访问到另一个网址的时候 才可以生效 不然的话就会报错
import requests
from lxml import etree
from multiprocessing.dummy import Pool
#需求:爬取梨视频的视频数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 对下面的url发起请求 解析数据
url = 'https://www.pearvideo.com/category_1'
page_text = requests.get(url=url, headers=headers).text
tree= etree.HTML(page_text)
li_list= tree.xpath('//ul[@class="listvideo-list clearfix"]/li')
urls = []
for li in li_list:
video_url= 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
countId = li.xpath('./div/a/@href')[0].split('_')[1]
# print(countId)
# print(li.xpath('./div/a/@href')[0])
video_name = li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
# print(video_url)
#对详情页中的视频发起请求
video_page = requests.get(url=video_url, headers=headers).text
# print(video_page)
# 从详情页中解析出视频的地址
# content = requests.get(url=video__url, headers=headers).content
headers2 = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
"Referer":f"https://www.pearvideo.com/{video_url}"
}
video__url = f'https://www.pearvideo.com/videoStatus.jsp?contId={countId}&mrd=0.5464291896872164'
response = requests.get(url=video__url, headers=headers2).json()
# print(response)
srcUrl = response['videoInfo']['videos']['srcUrl']
systemTime = response['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{countId}")
# print(url_)
dic={
'name':video_name,
'url':srcUrl
}
# print(dic)
urls.append(dic)
# print(urls)
def get_video_data(dic):
url = dic['url']
print(dic['name'],'正在下载.....')
data = requests.get(url=url, headers=headers).content
with open (dic['name'],'wb')as fp:
fp.write(data)
print(dic['name'],'下载成功')
# 实例化线程池
pool =Pool(4)
pool.map(get_video_data,urls)
pool.close()
pool.join()利用线程池进行爬取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号