作业5
一. 单选题(共8题,16分)
1. (单选题, 2分)下列传统并行计算框架,说法错误的是哪一项?
- A.
刀片服务器、高速网、SAN,价格贵,扩展性差上
- B.
共享式(共享内存/共享存储),容错性好
- C.
编程难度高
- D.
实时、细粒度计算、计算密集型
2. (单选题, 2分)下列关于MapReduce模型的描述,错误的是哪一项?
- A. MapReduce采用“ 分而治之”策略
- B. MapReduce设计的一个理念就是“ 计算向数据靠拢”
- C.
MapReduce框架采用了Master/Slave架构
- D.
MapReduce应用程序只能用Java来写
3. (单选题, 2分)MapReduce1.0的体系结构中,JobTracker是主要任务是什么?
- A.
负责资源监控和作业调度,监控所有TaskTracker与Job的健康状况
- B.
使用“slot”等量划分本节点上的资源量(CPU、内存等)
- C.
会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给TaskTracker
- D.
会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务(Task)
4. (单选题, 2分)下列关于MapReduce工作流程,哪个描述是正确的?
- A.
所有的数据交换都是通过MapReduce框架自身去实现的
- B.
不同的Map任务之间会进行通信
- C.
不同的Reduce任务之间可以发生信息交换
- D.
用户可以显式地从一台机器向另一台机器发送消息
5. (单选题, 2分)下列关于MapReduce的说法,哪个描述是错误的?
- A.
MapReduce具有广泛的应用,比如关系代数运算、分组与聚合运算等
- B.
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数
- C.
编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算
- D.
不同的Map任务之间可以进行通信
6. (单选题, 2分)下列关于Map和Reduce函数的描述,哪个是错误的?
- A.
Map将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理
- B.
Map每一个输入的<k 1 ,v 1 >会输出一批<k 2 ,v 2 >。<k 2 ,v 2 >是计算的中间结果
- C.
Reduce输入的中间结果<k 2 ,List(v 2 )>中的List(v 2 )表示是一批属于不同k 2 的value
- D.
Reduce输入的中间结果<k 2 ,List(v 2 )>中的List(v 2 )表示是一批属于同一个k 2 的value
7. (单选题, 2分)关于MapReduce1.0的体系结构的描述,下列说法错误的是?
- A.
Task 分为Map Task 和Reduce Task 两种,分别由JobTracker 和TaskTracker 启动
- B.
slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
- C.
TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)
- D.
TaskTracker 会周期性接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
8. (单选题, 2分)下列说法错误的是?
- A.
Hadoop MapReduce是MapReduce的开源实现,后者比前者使用门槛低很多
- B.
MapReduce采用非共享式架构,容错性好
- C.
MapReduce主要用于批处理、实时、计算密集型应用
- D.
MapReduce采用“ 分而治之”策略
二. 多选题(共6题,16分)
9. (多选题, 2.6分)MapReduce相较于传统的并行计算框架有什么优势?
- A.
非共享式,容错性好
- B. 普通PC机,便宜,扩展性好
- C.
编程简单,只要告诉MapReduce做什么即可
- D.
批处理、非实时、数据密集型
10. (多选题, 2.6分)MapReduce体系结构主要由以下哪几个部分构成?
- A.
Client
- B.
JobTracker
- C.
TaskTracker
- D.
Task
11. (多选题, 2.7分)下列关于MapReduce的体系结构的描述,说法正确的有?
- A. 用户编写的MapReduce程序通过Client提交到JobTracker端
- B.
JobTracker负责资源监控和作业调度
- C.
TaskTracker监控所有TaskTracker与Job的健康状况
- D.
TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)
12. (多选题, 2.7分)下列关于Map 端的Shuffle的描述,哪些是正确的?
- A.
当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
- B.
MapReduce默认为每个Map任务分配1000MB缓存
- C. 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- D. 每个Map任务分配多个缓存,使得任务运行更有效率
13. (多选题, 2.7分)MapReduce执行的全过程包括以下哪几个主要阶段?
- A.
从分布式文件系统读入数据
- B.
执行Map任务输出中间结果
- C. 通过 Shuffle阶段把中间结果分区排序整理后发送给Reduce任务
- D.
执行Reduce任务得到最终结果并写入分布式文件系统
14. (多选题, 2.7分)下列说法正确的是?
- A.
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
- B.
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
- C.
在MapReduce工作流程中,所有的数据交换都是通过MapReduce框架自身去实现的
- D. 在MapReduce工作流程中,用户不能显式地从一台机器向另一台机器发送消息
三. 简答题(共1题,20分)
15. (简答题, 20分)
请在以下两题中任选一题作答:
(1)通过查阅资料,写出一个或多个MapReduce的具体应用,并谈谈自己对MapReduce的认识。(满分10分)
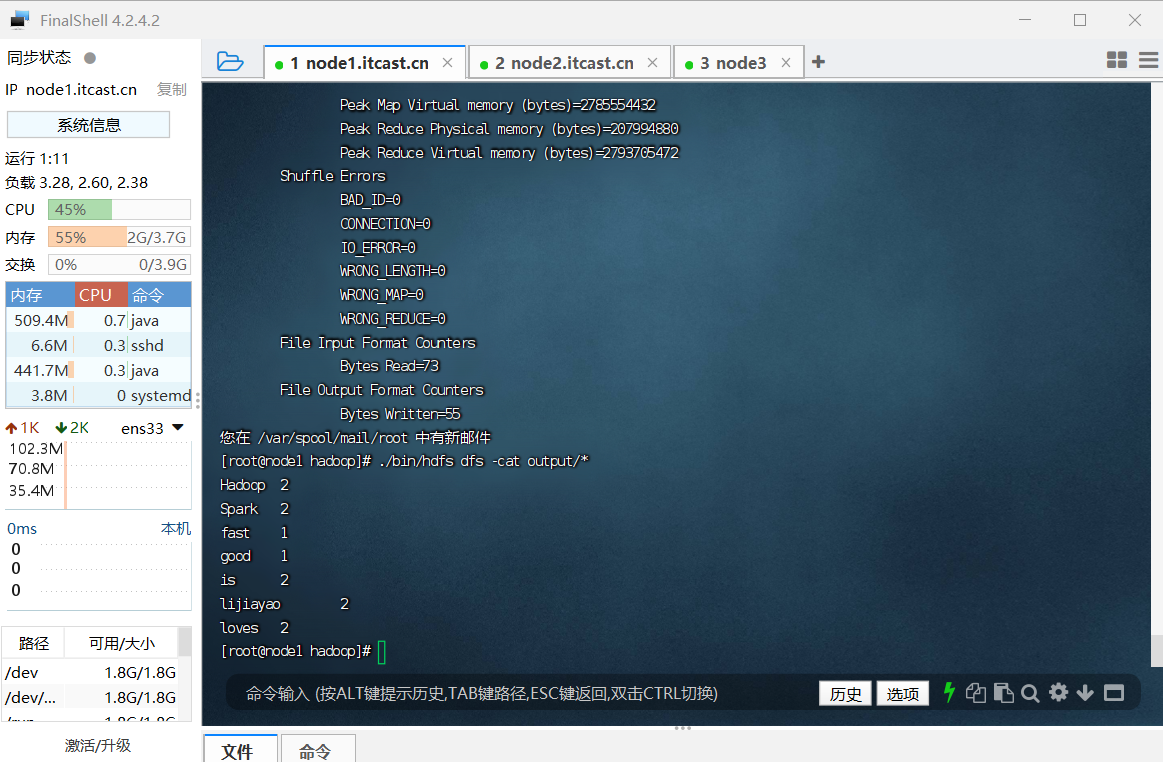
(2)词频统计任务编程实践,任务要求:在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt,文件wordfile1.txt的内容格式如下,需要将zhangsan换成自己名字的英文全拼:
zhangsan loves Spark
zhangsan loves Hadoop
文件wordfile2.txt的内容如下:
Hadoop is good
Spark is fast
请对这两个小数据集样本编写MapReduce词频统计程序,并截图给出统计结果,可参考相关教程https://dblab.xmu.edu.cn/blog/2481/。(满分20分)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号