作业6
1. (单选题, 3分)下面关于Hive的描述错误的是:
- A. Hive是一个构建在Hadoop之上的数据仓库工具
- B. Hive是由Facebook公司开发的
- C. Hive在某种程度上可以看作是用户编程接口,其本身并不存储和处理数据
- D. Hive定义了简单的类似SQL的查询语言——HiveQL,它与大部分SQL语法无法兼容
我的答案: D:Hive定义了简单的类似SQL的查询语言——HiveQL,它与大部分SQL语法无法兼容;正确答案: D:Hive定义了简单的类似SQL的查询语言——HiveQL,它与大部分SQL语法无法兼容;
3分
2. (单选题, 3分)关于Hive和传统关系数据库的对比分析,下面描述错误的是:
- A. Hive一般依赖于分布式文件系统HDFS,而传统数据库则依赖于本地文件系统
- B. 传统的关系数据库可以针对多个列构建复杂的索引,Hive不支持索引
- C. Hive和传统关系数据库都支持分区
- D. 传统关系数据库很难实现横向扩展,Hive具有很好的水平扩展性
我的答案: B:传统的关系数据库可以针对多个列构建复杂的索引,Hive不支持索引;正确答案: B:传统的关系数据库可以针对多个列构建复杂的索引,Hive不支持索引;
3分
3. (单选题, 3分)以下哪个不是Hive的用户接口模块:
- A. PMI
- B. HWI(Hive Web Interface)
- C. JDBC/ODBC
- D. Thrift Server
我的答案: A:PMI;正确答案: A:PMI;
3分
二. 多选题(共5题,15分)
4. (多选题, 3分)下列说法正确的是:
- A. 数据仓库Hive不需要借助于HDFS就可以完成数据的存储
- B. Impala和Hive、HDFS、HBase等工具可以统一部署在一个Hadoop平台上
- C. Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据
- D. HiveQL语法与传统的SQL语法很相似
我的答案: BCD:Impala和Hive、HDFS、HBase等工具可以统一部署在一个Hadoop平台上; Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据; HiveQL语法与传统的SQL语法很相似;正确答案: BCD:Impala和Hive、HDFS、HBase等工具可以统一部署在一个Hadoop平台上; Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据; HiveQL语法与传统的SQL语法很相似;
3分
5. (多选题, 3分)以下哪些是数据仓库的特性:
- A. 面向主题的(Subject Oriented)
- B. 集成的(Integrated)
- C. 相对稳定的(Non-Volatile)
- D. 反映历史变化
我的答案: ABCD:面向主题的(Subject Oriented); 集成的(Integrated); 相对稳定的(Non-Volatile); 反映历史变化;正确答案: ABCD:面向主题的(Subject Oriented); 集成的(Integrated); 相对稳定的(Non-Volatile); 反映历史变化;
3分
6. (多选题, 3分)Hadoop生态系统中Hive与其他部分的关系的描述正确的是:
- A. HDFS作为高可靠的底层存储,用来存储Hive的海量数据
- B. MapReduce对这些海量数据进行批处理,实现Hive的高性能计算
- C. 当采用MapRedue作为Hive的执行引擎时,用HiveQL语句编写的处理逻辑,最终都要转化为MapReduce任务来运行
- D. HBase与Hive的功能是互补的,它实现了Hive不能提供的功能
我的答案: ABCD:HDFS作为高可靠的底层存储,用来存储Hive的海量数据; MapReduce对这些海量数据进行批处理,实现Hive的高性能计算; 当采用MapRedue作为Hive的执行引擎时,用HiveQL语句编写的处理逻辑,最终都要转化为MapReduce任务来运行; HBase与Hive的功能是互补的,它实现了Hive不能提供的功能;正确答案: ABCD:HDFS作为高可靠的底层存储,用来存储Hive的海量数据; MapReduce对这些海量数据进行批处理,实现Hive的高性能计算; 当采用MapRedue作为Hive的执行引擎时,用HiveQL语句编写的处理逻辑,最终都要转化为MapReduce任务来运行; HBase与Hive的功能是互补的,它实现了Hive不能提供的功能;
3分
7. (多选题, 3分)Hive主要由哪三个模块组成:
- A. 用户接口模块
- B. 用户查询模块
- C. 驱动模块
- D. 元数据存储模块
我的答案: ACD:用户接口模块; 驱动模块; 元数据存储模块;正确答案: ABD:用户接口模块; 用户查询模块; 元数据存储模块;
0分
8. (多选题, 3分)当采用MapReduce作为Hive的执行引擎时,下面描述正确的是:
- A. 当用户向Hive输入一段命令或查询(即HiveQL语句)时,Hive需要与Hadoop交互工作来完成该操作
- B. 命令或查询首先进入到驱动模块,由驱动模块中的编译器进行解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行
- C. 执行器通常的任务是启动一个或多个MapReduce任务,有时也不需要启动MapReduce任务
- D. 执行器通常的任务一定会包含Map和Reduce操作
我的答案: ABC:当用户向Hive输入一段命令或查询(即HiveQL语句)时,Hive需要与Hadoop交互工作来完成该操作; 命令或查询首先进入到驱动模块,由驱动模块中的编译器进行解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行; 执行器通常的任务是启动一个或多个MapReduce任务,有时也不需要启动MapReduce任务;正确答案: ABC:当用户向Hive输入一段命令或查询(即HiveQL语句)时,Hive需要与Hadoop交互工作来完成该操作; 命令或查询首先进入到驱动模块,由驱动模块中的编译器进行解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行; 执行器通常的任务是启动一个或多个MapReduce任务,有时也不需要启动MapReduce任务;
3分
三. 简答题(共1题,30分)
9. (简答题, 30分)
请在以下两题中任选一题作答,其中第一题编程实践满分30,第二题应用调查满分20
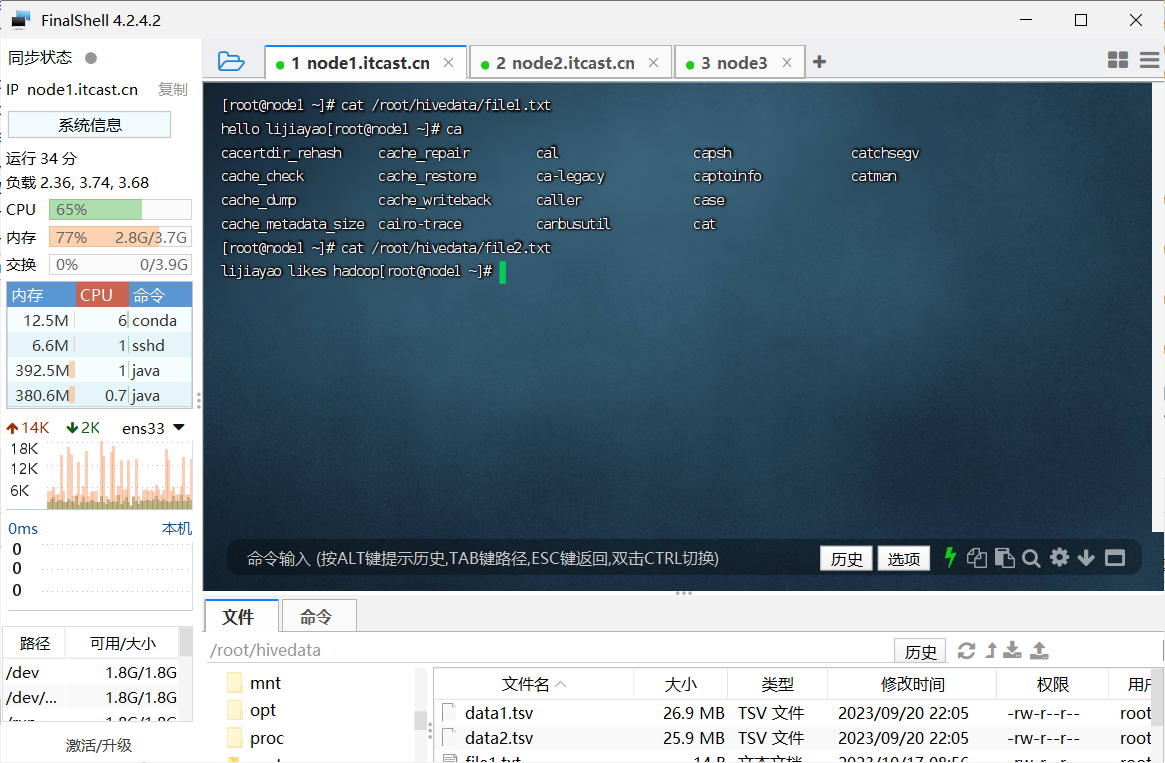
(1)编程实践:参考教程https://dblab.xmu.edu.cn/blog/4309/,编写HiveQL语句实现WordCount算法,在input文件夹中创建两个测试文件file1.txt和file2.txt,然后将教程中的
cd /usr/local/hadoop/input
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt
修改为:
cd /usr/local/hadoop/input
echo "hello zhangsan" > file1.txt
echo "zhangsan likes hadoop" > file2.txt
其中zhangsan替换为自己名字全拼,并将运行过程截图提交。
(2)Hive应用调查,通过查阅资料,整理出关于Hive的应用场景或实际应用案例,字数不少于800字。
利用了hive的可视化工具datagrip 在虚拟机中创建文件file1.txt和file2.txt 利用sql语句导入数据仓库hive,用sql做数据分析
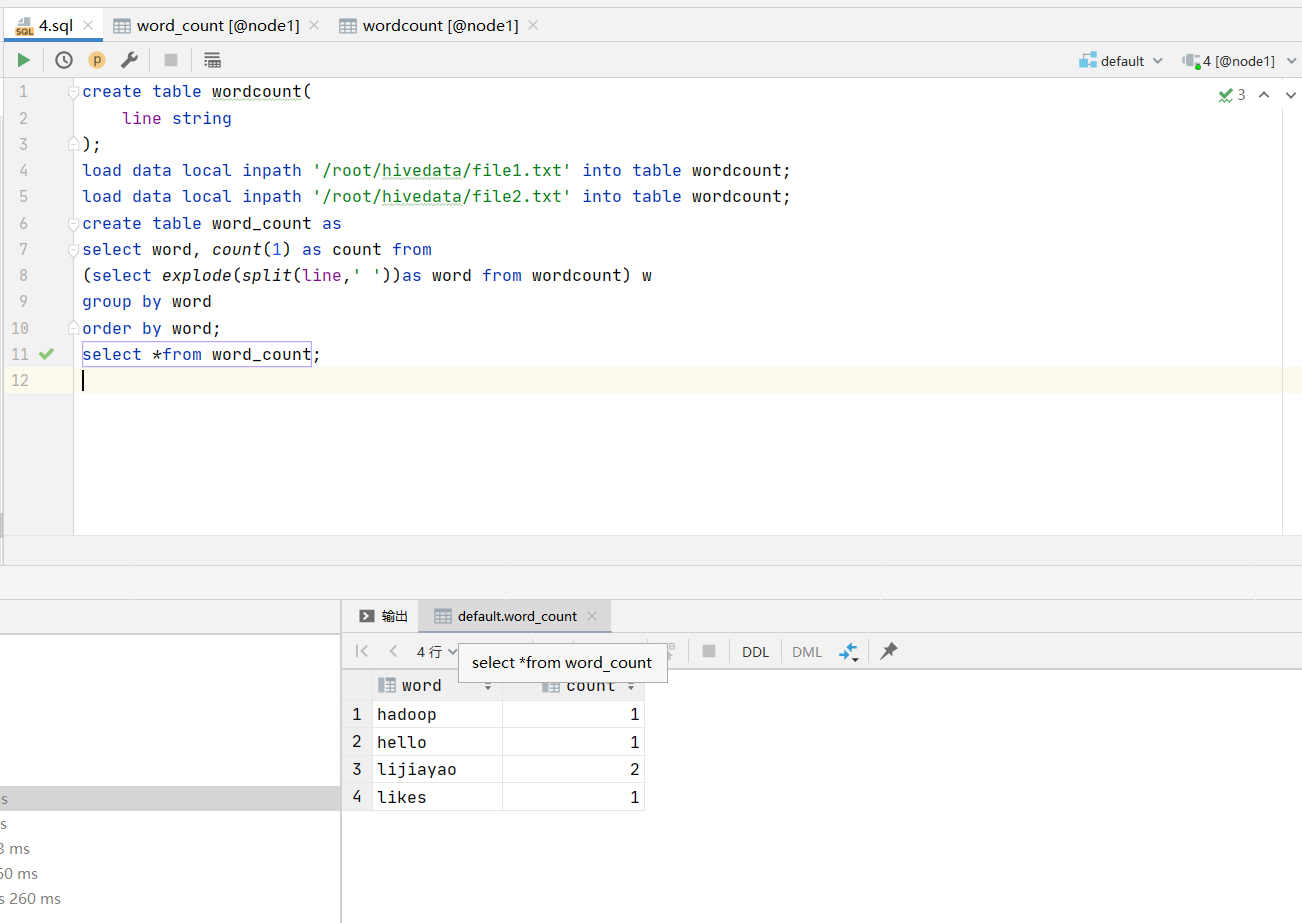
数据文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号