
用paython爬取知乎,伯乐在线,拉勾网完整版
在main.py
from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) # execute(["scrapy", "crawl", "jobbole"]) # execute(["scrapy", "crawl", "zhihu"]) execute(["scrapy", "crawl", "lagou"])
在items中
import scrapy
import datetime
import re
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from ArticleSpider.settings import SQL_DATETIME_FORMAT, SQL_DATE_FORMAT
from ArticleSpider.utils.common import extract_num
from w3lib.html import remove_tags
class ArticlespiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
def date_convert(value):
try:
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date
def get_nums(value):
match_re = re.match(".*?(\d+).*", value)
if match_re:
nums = int(match_re.group(1))
else:
nums = 0
return nums
def remove_comment_tags(value):
#去掉tag中提取的评论
if "评论" in value:
return ""
else:
return value
def return_value(value):
return value
def exclude_none(value):
if value:
return value
else:
value = "无"
return value
# class JobBoleArticleItem(scrapy.Item):
# title = scrapy.Field()
# create_date = scrapy.Field()
# url = scrapy.Field()
# url_object_id = scrapy.Field()
# front_image_url = scrapy.Field()
# front_image_path = scrapy.Field()
# praise_nums = scrapy.Field()
# comment_nums = scrapy.Field()
# fav_nums = scrapy.Field()
# content = scrapy.Field()
# tags = scrapy.Field()
class ArticleItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field(
input_processor=MapCompose(date_convert),
)
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field(
output_processor=MapCompose(return_value)
)
front_image_path = scrapy.Field()
praise_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
comment_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
fav_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
#因为tag本身是list,所以要重写
tags = scrapy.Field(
input_processor=MapCompose(remove_comment_tags),
output_processor=Join(",")
)
content = scrapy.Field()
# def get_insert_sql(self):
# insert_sql = """
# insert into jobbole_article(title, url, create_date, fav_nums)
# VALUES (%s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(fav_nums)
# """
# params = (self["title"], self["url"], self["create_date"], self["fav_nums"])
#
# return insert_sql, params
class ZhihuQuestionItem(scrapy.Item):
#知乎的问题 item
zhihu_id = scrapy.Field()
topics = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field(
input_processor=MapCompose(exclude_none),
)
answer_num = scrapy.Field()
comments_num = scrapy.Field()
watch_user_num = scrapy.Field()
click_num = scrapy.Field()
crawl_time = scrapy.Field()
def get_insert_sql(self):
#插入知乎question表的sql语句
insert_sql = """
insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num, comments_num,
watch_user_num, click_num, crawl_time
)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE content=VALUES(content), answer_num=VALUES(answer_num), comments_num=VALUES(comments_num),
watch_user_num=VALUES(watch_user_num), click_num=VALUES(click_num)
"""
zhihu_id = self["zhihu_id"][0]
topics = ",".join(self["topics"])
url = self["url"][0]
title = "".join(self["title"])
# content = "".join(self["content"])
# answer_num = extract_num("".join(self["answer_num"]))
# # comments_num = extract_num("".join(self["comments_num"]))
try:
content = "".join(self["content"])
except BaseException:
content = "无"
try:
answer_num = extract_num("".join(self["answer_num"]))
except BaseException:
answer_num = 0
comments_num = extract_num("".join(self["comments_num"]))
if len(self["watch_user_num"]) == 2:
watch_user_num = int(self["watch_user_num"][0])
click_num = int(self["watch_user_num"][1])
else:
watch_user_num = int(self["watch_user_num"][0])
click_num = 0
crawl_time = datetime.datetime.now().strftime(SQL_DATETIME_FORMAT)
params = (zhihu_id, topics, url, title, content, answer_num, comments_num,
watch_user_num, click_num, crawl_time)
return insert_sql, params
class ZhihuAnswerItem(scrapy.Item):
#知乎的问题回答item
zhihu_id = scrapy.Field()
url = scrapy.Field()
question_id = scrapy.Field()
author_id = scrapy.Field()
content = scrapy.Field()
parise_num = scrapy.Field()
comments_num = scrapy.Field()
create_time = scrapy.Field()
update_time = scrapy.Field()
crawl_time = scrapy.Field()
def get_insert_sql(self):
#插入知乎回答表的sql语句
insert_sql = """
insert into zhihu_answer(zhihu_id, url, question_id, author_id, content, parise_num, comments_num,
create_time, update_time, crawl_time
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE content=VALUES(content), comments_num=VALUES(comments_num), parise_num=VALUES(parise_num),
update_time=VALUES(update_time)
"""
create_time = datetime.datetime.fromtimestamp(self["create_time"]).strftime(SQL_DATETIME_FORMAT)
update_time = datetime.datetime.fromtimestamp(self["update_time"]).strftime(SQL_DATETIME_FORMAT)
params = (
self["zhihu_id"], self["url"], self["question_id"],
self["author_id"], self["content"], self["parise_num"],
self["comments_num"], create_time, update_time,
self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
def remove_splash(value):
#去掉工作城市的斜线
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouJobItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class LagouJobItem(scrapy.Item):
#拉勾网职位信息
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor = MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor = MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor = Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_addr, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_addr"], self["company_name"], self["company_url"],
self["job_addr"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
在pipelines.py中
import codecs
import json
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exporters import JsonItemExporter
class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item
class ArticleImagePipeline(ImagesPipeline):
#重写该方法可从result中获取到图片的实际下载地址
def item_completed(self, results, item, info):
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
#**dbparms-->("MySQLdb",host=settings['MYSQL_HOST']
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
# def do_insert(self, cursor, item):
# #执行具体的插入
# #根据不同的item 构建不同的sql语句并插入到mysql中
# insert_sql, params = item.get_insert_sql()
# cursor.execute(insert_sql, params)
def do_insert(self, cursor, item):
#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
class JsonWithEncodingPipeline(object):
# 自定义json文件的导出
def __init__(self):
# 使用codecs打开避免一些编码问题。
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
# 将item转换为dict,然后调用dumps方法生成json对象,false避免中文出错
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
# 当spider关闭的时候: 这是一个spider_closed的信号量。
def spider_closed(self, spider):
self.file.close()
class JsonExporterPipeline(object):
#调用scrapy提供的json export导出json文件
def __init__(self):
self.file = open('articleexport.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
class MysqlPipeline(object):
#采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect('localhost', 'root', '123456', 'article_spider', charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
# def process_item(self, item, spider):
# insert_sql = """
# insert into jobbole_article(title,create_date,url,url_object_id, front_image_url,praise_nums,comment_nums,fav_nums,tags,content)
# VALUES (%s, %s, %s, %s, %s,%s,%s,%s,%s,%s)
# """
# self.cursor.execute(insert_sql, (item["title"],item["create_date"],item["url"],item["url_object_id"],item["front_image_url"],item["praise_nums"],item["comment_nums"],item["fav_nums"],item["tags"],item["content"]))
# self.conn.commit()
在settings中
import os
BOT_NAME = 'ArticleSpider'
SPIDER_MODULES = ['ArticleSpider.spiders']
NEWSPIDER_MODULE = 'ArticleSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ArticleSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'ArticleSpider.middlewares.ArticlespiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'ArticleSpider.middlewares.ArticlespiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
# 'scrapy.pipelines.images.ImagesPipeline': 1,
# 'ArticleSpider.pipelines.ArticleImagePipeline':1,
'ArticleSpider.pipelines.JsonExporterPipeline':2,
# 'ArticleSpider.pipelines.MysqlPipeline': 4,
'ArticleSpider.pipelines.MysqlTwistedPipline': 1,
}
IMAGES_URLS_FIELD = "front_image_url"
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir, 'images')
import sys
BASE_DIR = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR, 'ArticleSpider'))
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36"
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
MYSQL_HOST = "localhost"
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "123456"
SQL_DATETIME_FORMAT = "%Y-%m-%d %H:%M:%S"
SQL_DATE_FORMAT = "%Y-%m-%d"
在jobbole.py中
import scrapy
import re
import datetime
from urllib import parse
from scrapy.http import Request
from ArticleSpider.items import JobBoleArticleItem
from ArticleSpider.utils.common import get_md5
from scrapy.loader import ItemLoader
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts']
def parse(self, response):
"""
1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析
2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse
"""
# 解析列表页中的所有文章url并交给scrapy下载后并进行解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
#获取封面图的url
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
#request下载完成之后,回调parse_detail进行文章详情页的解析
# Request(url=post_url,callback=self.parse_detail)
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail)
#遇到href没有域名的解决方案
#response.url + post_url
# 提取下一页并交给scrapy进行下载
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
# front_image_url = response.meta.get("front_image_url", "") #文章封面图
# title = response.css(".entry-header h1::text").extract_first()
# create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
# praise_nums = response.css(".vote-post-up h10::text").extract()[0]
# fav_nums = response.css(".bookmark-btn::text").extract()[0]
# match_re = re.match(".*?(\d+).*", fav_nums)
# if match_re:
# fav_nums = int(match_re.group(1))
# else:
# fav_nums = 0
#
# comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = int(match_re.group(1))
# else:
# comment_nums = 0
#
# # content = response.css("div.entry::text").extract()
# content = response.css('div.entry').extract_first()
#
# tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract()
# tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
# tags = ",".join(tag_list)
# try:
# create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date()
# except Exception as e:
# create_date = datetime.datetime.now().date()
# article_item = JobBoleArticleItem()
# article_item["title"] = title
# article_item["url"] = response.url
# article_item["create_date"] = create_date
# article_item["front_image_url"] = [front_image_url]
# article_item["praise_nums"] = praise_nums
# article_item["comment_nums"] = comment_nums
# article_item["fav_nums"] = fav_nums
# article_item["tags"] = tags
# article_item["content"] = content
# article_item["url_object_id"] = get_md5(response.url)
front_image_url = response.meta.get("front_image_url", "") # 文章封面图
item_loader = ItemLoader(item=JobBoleArticleItem(), response=response)
item_loader.add_css("title", ".entry-header h1::text")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url", [front_image_url])
item_loader.add_css("praise_nums", ".vote-post-up h10::text")
item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums", ".bookmark-btn::text")
item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text")
item_loader.add_css("content", "div.entry")
#调用这个方法来对规则进行解析生成item对象
article_item = item_loader.load_item()
yield article_item
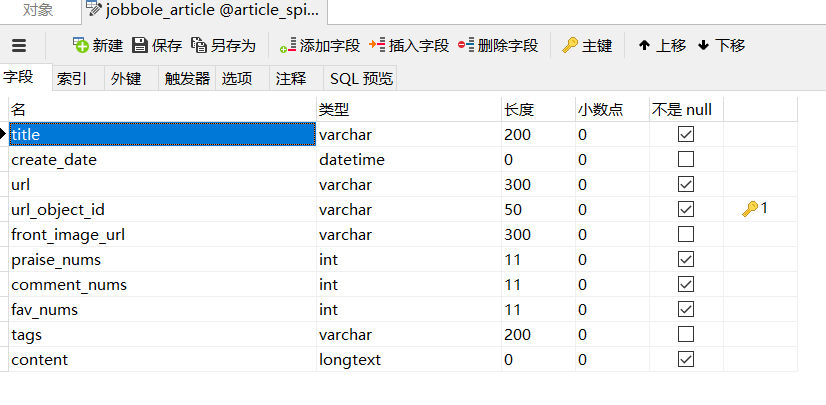
在数据库的设计
在zhihu.py中
import scrapy
import re
from urllib import parse
from selenium import webdriver
from scrapy.http import Request
from scrapy.loader import ItemLoader
import time
import pickle
import datetime
import json
from ArticleSpider.items import ZhihuQuestionItem, ZhihuAnswerItem
try:
import urlparse as parse
except:
from urllib import parse
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/']
#question的第一页answer的请求url
start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccollapsed_counts%2Creviewing_comments_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Crelationship.is_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.is_blocking%2Cis_blocked%2Cis_followed%2Cvoteup_count%2Cmessage_thread_token%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit={1}&offset={2}"
# start_answer_url ="https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=3&offset=3"
# start_answer_url="https://www.zhihu.com/api/v4/questions/22044254/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=3&offset=3"
headers = {
"HOST": "www.zhihu.com",
"Referer": 'https://www.zhihu.com',
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36"
}
custom_settings = {
"COOKIES_ENABLED": True
}
def parse(self, response):
"""
提取出html页面中的所有url 并跟踪这些url进行一步爬取
如果提取的url中格式为 /question/xxx 就下载之后直接进入解析函数
"""
all_urls = response.css("a::attr(href)").extract()
all_urls = [parse.urljoin(response.url, url) for url in all_urls]
#使用lambda函数对于每一个url进行过滤,如果是true放回列表,返回false去除。
all_urls = filter(lambda x:True if x.startswith("https") else False, all_urls)
for url in all_urls:
match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", url)
if match_obj:
# 如果提取到question相关的页面则下载后交由提取函数进行提取
request_url = match_obj.group(1)
yield scrapy.Request(request_url, headers=self.headers, callback=self.parse_question)
else:
# 如果不是question页面则直接进一步跟踪
yield scrapy.Request(url, headers=self.headers, callback=self.parse)
def parse_question(self, response):
#处理question页面, 从页面中提取出具体的question item
# if "QuestionHeader-title" in response.text:
# #处理新版本
# match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url)
# if match_obj:
# question_id = int(match_obj.group(2))
#
# item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
# item_loader.add_css("title", "h1.QuestionHeader-title::text")
# item_loader.add_css("content", ".QuestionHeader-detail span::text")
# item_loader.add_value("url", response.url)
# item_loader.add_value("zhihu_id", question_id)
# item_loader.add_css("answer_num", ".Question-mainColumn a::text")
# item_loader.add_css("comments_num", ".QuestionHeader-Comment span::text")
# item_loader.add_css("watch_user_num", ".QuestionFollowStatus-counts strong::text")
# item_loader.add_css("topics", ".QuestionHeader-topics .Popover div::text")
#
# question_item = item_loader.load_item()
# else:
#处理老版本页面的item提取
match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url)
if match_obj:
question_id = int(match_obj.group(2))
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
# item_loader.add_css("title", ".zh-question-title h2 a::text")
# item_loader.add_xpath("title", "//*[@id='zh-question-title']/h2/a/text()|//*[@id='zh-question-title']/h2/span/text()")
# item_loader.add_css("content", "#zh-question-detail")
# item_loader.add_value("url", response.url)
# item_loader.add_value("zhihu_id", question_id)
# item_loader.add_css("answer_num", "#zh-question-answer-num::text")
# item_loader.add_css("comments_num", "#zh-question-meta-wrap a[name='addcomment']::text")
# # item_loader.add_css("watch_user_num", "#zh-question-side-header-wrap::text")
# item_loader.add_xpath("watch_user_num", "//*[@id='zh-question-side-header-wrap']/text()|//*[@class='zh-question-followers-sidebar']/div/a/strong/text()")
# item_loader.add_css("topics", ".zm-tag-editor-labels a::text")
item_loader.add_css("title", ".QuestionHeader-title::text")
item_loader.add_css("content", ".QuestionHeader-detail span::text")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", ".List-headerText span::text")
item_loader.add_css("comments_num", ".QuestionHeader-Comment span::text")
item_loader.add_css("watch_user_num", ".QuestionFollowStatus-counts strong::text")
item_loader.add_css("topics", ".QuestionHeader-topics .Popover div::text")
question_item = item_loader.load_item()
yield scrapy.Request(self.start_answer_url.format(question_id, 20, 0), headers=self.headers, callback=self.parse_answer)
yield question_item
def parse_answer(self, reponse):
#处理question的answer
ans_json = json.loads(reponse.text)
is_end = ans_json["paging"]["is_end"]
next_url = ans_json["paging"]["next"]
#提取answer的具体字段
for answer in ans_json["data"]:
answer_item = ZhihuAnswerItem()
answer_item["zhihu_id"] = answer["id"]
answer_item["url"] = answer["url"]
answer_item["question_id"] = answer["question"]["id"]
answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None
answer_item["content"] = answer["content"] if "content" in answer else None
answer_item["parise_num"] = answer["voteup_count"]
answer_item["comments_num"] = answer["comment_count"]
answer_item["create_time"] = answer["created_time"]
answer_item["update_time"] = answer["question"]["updated_time"]
answer_item["crawl_time"] = datetime.datetime.now()
yield answer_item
if not is_end:
yield scrapy.Request(next_url, headers=self.headers, callback=self.parse_answer)
def start_requests(self):
browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe")
# browser.get("https://www.zhihu.com/signup?next=%2F")
browser.get("https://www.zhihu.com/signin")
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys("***")#知乎账号
browser.find_element_by_css_selector(".SignFlow-password input").send_keys("***")#知乎密码
print(browser.page_source)
browser.find_element_by_css_selector(".Button.SignFlow-submitButton").click()
time.sleep(10)
Cookies=browser.get_cookies()
# print(Cookies)
cookie_dict={}
for cookie in Cookies:
f=open('C:/Users/Dell/scrapytest/Scripts/ArticleSpider'+cookie['name']+'.zhihu','wb')
pickle.dump(cookie,f)
f.close()
cookie_dict[cookie['name']]=cookie['value']
browser.close()
return[scrapy.Request(url=self.start_urls[0], headers=self.headers,dont_filter=True,cookies=cookie_dict)]
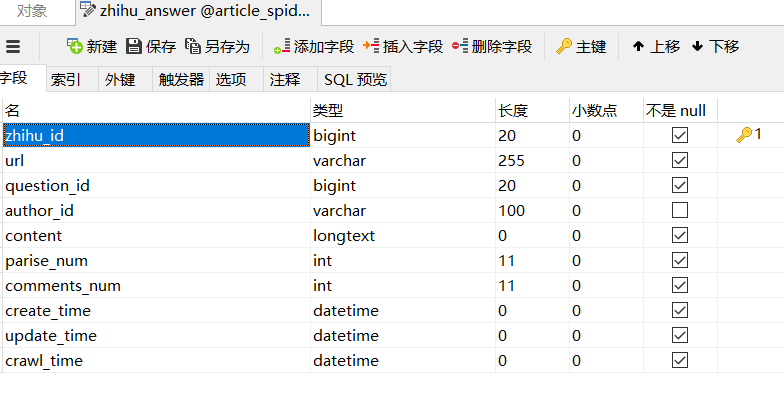
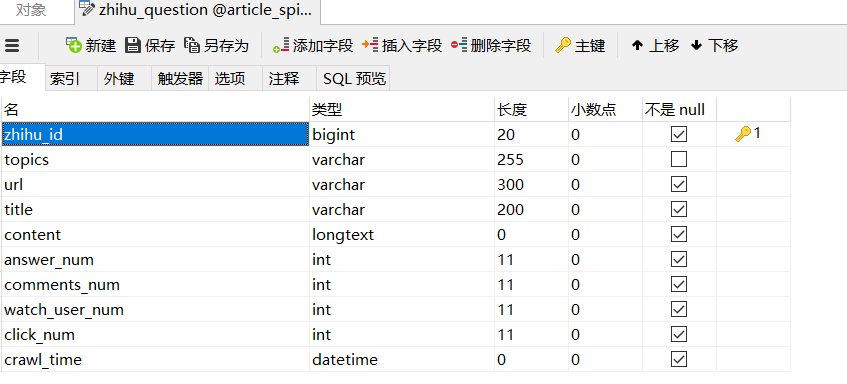
知乎数据库设计
在lagou.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ArticleSpider.utils.common import get_md5
from selenium import webdriver
import time
import pickle
from ArticleSpider.items import LagouJobItemLoader, LagouJobItem
from datetime import datetime
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
# headers = {
# "HOST": "www.lagou.com",
# "Referer": 'https://www.lagou.com',
#
# 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36"
# }
rules = (
Rule(LinkExtractor(allow=r'gongsi/j/\d+.html'), follow=True),
Rule(LinkExtractor(allow=r'zhaopin/.*'), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True),
)
def parse_job(self, response):
#解析拉勾网的职位
item_loader = LagouJobItemLoader(item=LagouJobItem(), response=response)
item_loader.add_css("title", ".job-name::attr(title)")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css("salary", ".job_request .salary::text")
item_loader.add_xpath("job_city", "//*[@class='job_request']/p/span[2]/text()")
item_loader.add_xpath("work_years", "//*[@class='job_request']/p/span[3]/text()")
item_loader.add_xpath("degree_need", "//*[@class='job_request']/p/span[4]/text()")
item_loader.add_xpath("job_type", "//*[@class='job_request']/p/span[5]/text()")
item_loader.add_css("tags", '.position-label li::text')
item_loader.add_css("publish_time", ".publish_time::text")
item_loader.add_css("job_advantage", ".job-advantage p::text")
item_loader.add_css("job_desc", ".job_bt div")
item_loader.add_css("job_addr", ".work_addr")
item_loader.add_css("company_name", "#job_company dt a img::attr(alt)")
item_loader.add_css("company_url", "#job_company dt a::attr(href)")
item_loader.add_value("crawl_time", datetime.now())
job_item = item_loader.load_item()
return job_item
def start_requests(self):
browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe")
browser.get("https://passport.lagou.com/login/login.html?service=https%3a%2f%2fwww.lagou.com%2f")
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[1]/input").send_keys("***")#拉钩账号
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[2]/input").send_keys("****")#拉钩密码
print(browser.page_source)
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[5]").click()
time.sleep(10)
Cookies=browser.get_cookies()
# print(Cookies)
cookie_dict={}
for cookie in Cookies:
f=open('C:/Users/Dell/scrapytest/Scripts/ArticleSpider'+cookie['name']+'.lagou','wb')
pickle.dump(cookie,f)
f.close()
cookie_dict[cookie['name']]=cookie['value']
browser.close()
return[scrapy.Request(url=self.start_urls[0], dont_filter=True,cookies=cookie_dict)]
# return[scrapy.Request(url=self.start_urls[0], headers=self.headers,dont_filter=True,cookies=cookie_dict)]
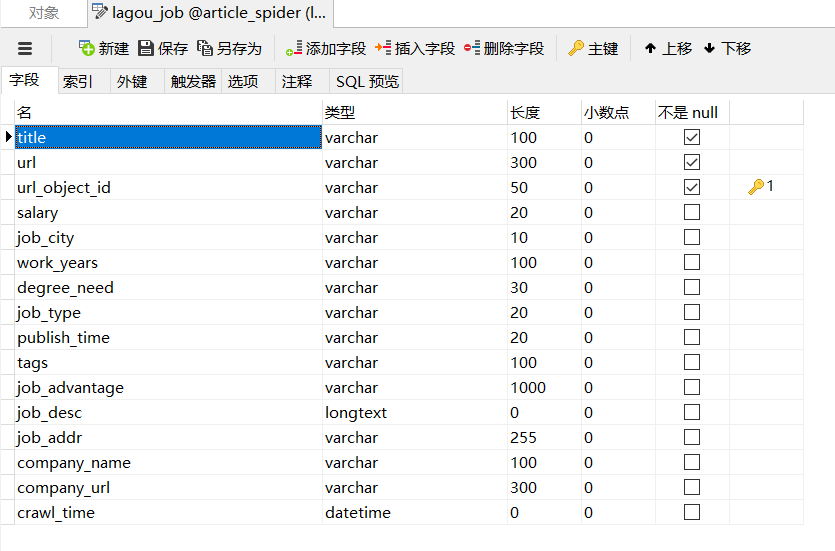
拉钩数据库设计

 浙公网安备 33010602011771号
浙公网安备 33010602011771号