
python用xpath方法爬取伯乐在线
1.xpath的用法


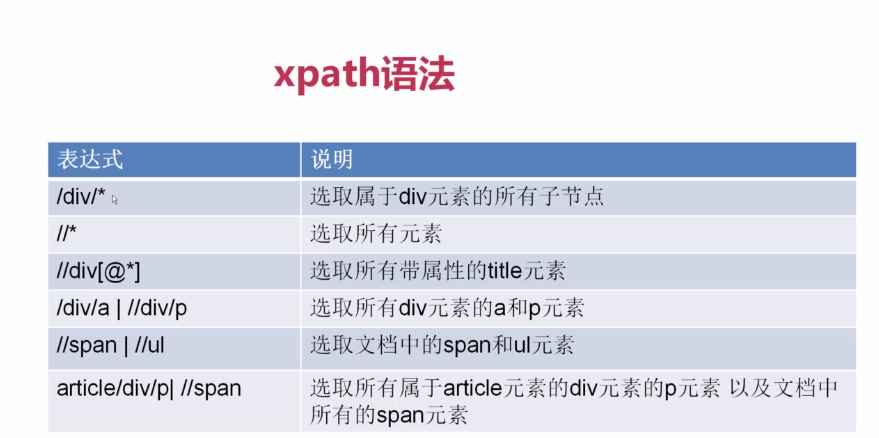
2.提取信息
(1)在命令行中可以测试

response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","")
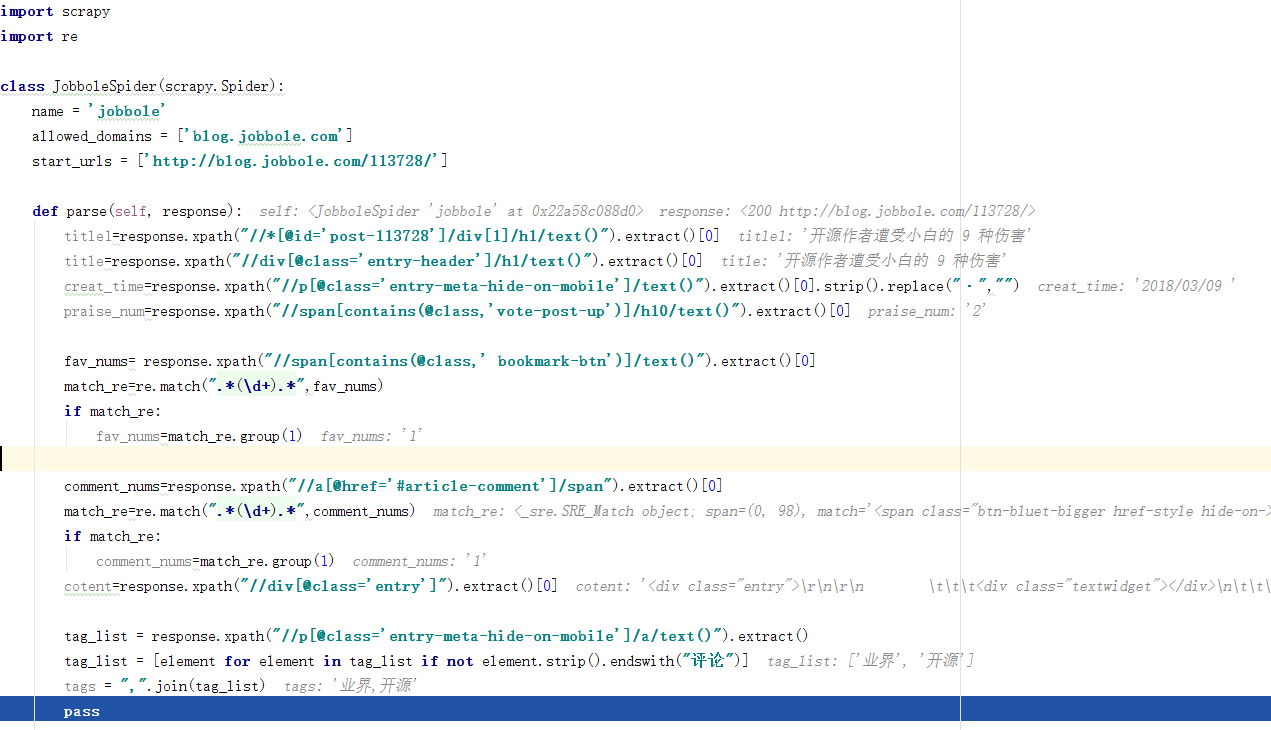
(2)在pycharm中运行
import scrapy import re class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/113728/'] def parse(self, response): title1=response.xpath("//*[@id='post-113728']/div[1]/h1/text()").extract()[0] title=response.xpath("//div[@class='entry-header']/h1/text()").extract()[0] creat_time=response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","") praise_num=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0] fav_nums= response.xpath("//span[contains(@class,' bookmark-btn')]/text()").extract()[0] match_re=re.match(".*(\d+).*",fav_nums) if match_re: fav_nums=match_re.group(1) comment_nums=response.xpath("//a[@href='#article-comment']/span").extract()[0] match_re=re.match(".*(\d+).*",comment_nums) if match_re: comment_nums=match_re.group(1) cotent=response.xpath("//div[@class='entry']").extract()[0] tag_list = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list) pass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号