es学习笔记(一)
基本信息
ES中的索引相当于数据库,类型相当于表,文档相当于一条记录。
例子:
建立一个名为example的索引(相当于创建一个数据库,名叫example),然后创建一个名叫people的类型(相当于创建一张名为people的表),类型通过mapping来定义每个字段的的类型

其中keyword类型不会分词,直接根据字符串内容建立反向索引,Test类型在存入es时会先进行分词,然后根据分词结果建立反向索引。(反向索引:根据内容的关键字建立索引)
基本概念:
集群(cluster):一个节点或多个节点的集合,联合起来保存所有的数据(索引以分片为单位分散到多个节点保存)。集群通过名字进行区分。默认名称为elasticsearch
节点(node):节点是一个服务器,是集群的一个部分,存储数据并参与集群的索引与搜索。,也是通过唯一的名字进行区分,默认为随机生成的uuid,通过配置集群的名称加入集群,默认加入elasticSearch集群。
索引(index):很多文档的集合,相当于mysql的数据库。根据名称区分,且名称为小写。
类型(type):可以在一个索引中定义一个或多个类型,相当于mysql的表。
文档(document):被索引的基本单位,相当于数据库的一行。
分片和复制:一个索引存储的数据可能超过单个节点硬盘容量,ES允许把索引数据划分到多个分片上。创建索引是,可以定义想要的分片数量,每个分片具备索引的全部功能,且可存放在集群的任何一个节点。分片目的包括:1.允许水平划分/扩展你的内容。2.允许并行的分发操作到多个节点的分片上,从而提升性能和吞吐量。(分片分发以及各分片上的文档如何被收集到单个搜索请求中的机制由es完全管理,对用户透明)ES允许创建一个或者多个分片的副本,成为复制分片,主要目的是:1.提供了高可用性,防止节点/分片不可用,因此,不要把复制分片和主分片放在同一节点上。2.允许扩大搜索量和吞吐量,不同的搜索请求可以在所有的复制分片中并发执行。
默认情况下,每个索引都会被分配5个主分片和1一个复制分片,这意味着如果你的集群中有两个节点,你的索引将会有5个主分片和5个复制分片,总共有10个分片。在单个索引中你最多可以存储2,147,483,519 (= Integer.MAX_VALUE - 128) 个文档。
默认使用9200端口
基本操作
进入ES的bin目录 cd elasticsearch-5.0.2/bin
运行启动脚本 ./elasticsearch
重载集群或者节点的名称 ./elasticsearch -Ecluster.name=my_cluster_name -Enode.name=my_node_name
查看集群健康状况 curl -XGET ‘localhost:9200/_cat/health?v&pretty' 返回结果中status代表健康状况,可取值为green,yellow,red,green表示一切良好,所有功能正常,yellow表示所有数据可用,但是一些复制分片可能没有正确分发(主分片和复制分片不能再一个节点上),red表示某些数据不能使用。
查询集群的节点情况 curl -XGET 'localhost:9200/_cat/nodes?v&pretty'
列出所有索引 curl -XGET 'localhost:9200/_cat/indices?v&pretty'
创建索引 curl -XPUT ‘localhost:9200/people?pretty&pretty’
将文档索引至类型中 curl -XPUT ‘’localhost:9200/people/person/1?pretty&pretty' -d'{"name": "hshs"}'
查询文档 curl -XGET ‘localhost:9200/people/person/1?pretty&pretty’
删除索引 curl -XDELETE ‘’localhost:9200/people?pretty&pretty
更新文档(删除旧文档然后索引到新文档)curl -XPOST 'localhost:9200/people/person/1/_update?pretty&pretty' -d '{"doc":{"name", "hahhah"}}'
批处理 curl -XPOST 'localhost:9200/people/person/_bulk?pretty&pretty' -d '{ {"update":{}} {"doc":{}} {"delete":{}}}'
以上命令在控制台输入,以下使用elasticsearch-head
查询
1.match_all 匹配所有文档

通过使用_search,post请求,from表示从文档开始下标,默认为0,size总共返回多少个文档,默认为10,sort排序,_source指定返回那些内容,相当于sql指定返回那些字段
2.match基于字段搜索
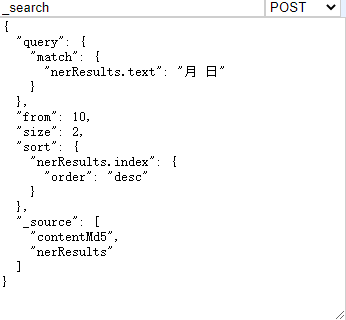
3.match_phrase于match一致,不过是基于词组的,比如match查“月 日”的时候查的是包含月或者日的,而match_phrase查的是包含词组月 日的
4.bool 允许我们将多个match查询合并到一个查询中

must表示两个match查询均为true才返回,即nerResults.text包含月且nerResults.index的值为2,should,相当于或,满足一个即可,must_not,两个均不满足,可组合为复杂查询
5.聚合查询

还可以在里面嵌套

 浙公网安备 33010602011771号
浙公网安备 33010602011771号