Notes 20180311 : String第三讲_深入了解String
很多前辈我可能对于我的这节文章很困惑,觉得String这个东西还有什么需要特别了解的吗?其实不然,String是一个使用十分频繁的工具类,不可避免地我们也会遇到一些陷阱,深入了解String对于我们避免陷阱,甚至优化操作是很有必要的。本节我们主要讲解"码点与代码单元"、“不可变的String”、“无意识的递归”、“重载+”。
1.码点与代码单元
Java字符串是由字符序列组成的。而前面我们介绍char数据类型的时候也讲到过,char数据类型是一个采用UTF-16编码表示Unicode码点的代码单元。大多数的常用Unicode字符使用一个代码单元就可以表示,而辅助字符需要一对代码单元表示。更多Unicode的内容可以参见Knowledge Point 20180305 Java程序员详述编码Unicode
1.1 字符串“长度”
String中提供了一个方法length(),该方法将返回采用UTF-16编码表示的给定字符串所需要的代码单元数量。注意是代码单元数量,而不是字符串的长度(我们通常所理解的字符串长度是字符串中字符个数,这里得到的并不是这种结果);除了length()外,String还提供了另一个关于长度的方法codePointCount(int beginIndex, int endIndex),该方法返回此 String指定文本范围内的Unicode代码点数。在这里我们要搞清楚代码单元和代码点数的区别,代码点:是指一个编码表中的某个字符对应的代码值,也就是Unicode编码表中每个字符对应的数值。代码单元是指表示一个代码点所需的最小单位,在Java中使用的是char数据类型,一个char表示一个代码单元,这也就是为什么下面的代码会编译报错,𝕆是一个辅助字符,需要用两个代码单元表示,所以这里不能使用char类型来表示。
// char ch = '𝕆';会提示无效的字符,因为char只能表示基本的
看下面的例子:
String greeting = "Hello"; System.out.println("字符串greeting的代码单元长度:" + greeting.length());//字符串greeting的代码单元长度:5 System.out.println("字符串greeting的码点数量:" + greeting.codePointCount(0, greeting.length()));//字符串greeting的码点数量:5
上面的代码并没有什么晦涩难懂的地方,我们使用的都是常用的Unicode字符,它们使用一个代码单元(2个字节)就可以表示,所以字符的码点数量和代码单元的数量是一致的,但是我们不要忘了Unicode中是存在辅助字符的,辅助字符是一个字符占用两个代码单元,下面我们来看另一个例子:
String str = "𝕆 is the set of octonions"; System.out.println("字符串str的代码单元长度"+ str.length());//字符串str的代码单元长度26 System.out.println("字符串str的码点数量:" + str.codePointCount(0, str.length()));//字符串str的码点数量:25 System.out.println("str获取指定代码单元的码点:" + str.codePointAt(1));//56646
通过这段代码,我们很容易就看出了两个方法的区别了,length()返回String中的代码单元,底层是通过字符数组的长度来获取。而codePointCount()返回了代码点数量,底层是Character的一个方法。由于使用了一个辅助字符,所以明显的代码单元是比代码点数量多1的。在最后一句我们获取索引1处的码点,得到的也并非是“空格”,空格的Unicode是32,所以这里返回的并不是一个空格,而是辅助字符的第二个代码单元。
1.2 String中对于码点的操作方法
String中给我们提供了很多用于操作码点的方法,我们在上一节中已经认识了,这节我们详细罗列一下:
- int
codePointAt(int index)返回指定索引处的字符(Unicode代码点)。IndexOutOfBoundsException - int
codePointBefore(int index)返回指定索引之前的字符(Unicode代码点)。IndexOutOfBoundsException - int
codePointCount(int beginIndex, int endIndex)返回此String指定文本范围内的Unicode代码点数。IndexOutOfBoundsException - int
offsetByCodePoints(int index, int codePointOffset)返回此String内的指数,与indexcodePointOffset代码点。IndexOutOfBoundsException
上面几个方法都存在索引越界的异常【底层是数组,所以存在这种隐患,在操作时应该注意参数越界的情况】,这里所有的参数是代码单元。前面三个方法我们已经认识过,这里就只讲解一下第四个方法:“这个函数的第二个参数是以第一个参数为标准后移的代码单元(注意是代码单元,不是代码点)的数量。返回该代码点在字符串中的代码单元索引。”
String str2 = "𝕆is the set 𝕆is the set of octonions of octonions"; System.out.println(str2.offsetByCodePoints(7, 7));//15 以第7个代码点为标准后移7个代码点后是i,在字符串中的代码单元位置为15
System.out.println(str2.codePointAt(15));//105
String str3 = "i";
System.out.println(str3.codePointAt(0));//10
看完上面的,我们再来看一下另外两个方法:
System.out.println(str2.codePointAt(0));//120134 System.out.println(str2.codePointAt(1));//56646 System.out.println(str2.codePointBefore(2));//120134 System.out.println(str2.codePointBefore(1));//55349
codePointAt(int index)该方法会返回该代码单元的码点数,但是该方法会向后寻找,但是不能向前寻找,所以在操作辅助字符的时候,我们发现如果查询的是辅助字符的第一个代码单元,那么返回的是该辅助字符的码点数,这是因为该方法向后寻找和第二个代码单元合并成了一个完整的辅助字符。但如果查看的辅助字符的第二个代码单元,那么就只能返回第二个代码单元的码点数了。String应对该方法,也提供了一个向前查询的方法codePointBefore,该方法会查询给定代码单元前的码点数,但是如果给定代码单元是普通字符,那么不管该代码单元前面是普通字符还是辅助字符,都可以完整显示该码点数。如果给定代码单元是辅助字符且是辅助字符的第二个代码单元,那么就只会返回该辅助字符的第一个代码单元了。
1.3 String关于码点的练习操作
1.3.1 获取码点数组和代码单元数组
给定一个字符串,将该字符串返回一个由码点数构成的int数组和代码单元构成的int数组:
@Test public void test1(){ String str1 = "𝕆is the set 𝕆is"; System.out.println(Arrays.toString(codePoint(str1))); }
/** * 码点数组 * @param str */ public int[] codePoint(String str){ int[] arr = new int[str.codePointCount(0, str.length())]; int cp = 0; int j = 0; for (int i = 0; i < str.length();) { cp = str.codePointAt(i); if(Character.isSupplementaryCodePoint(cp)){ arr[j] = cp; i += 2; }else{ arr[j] = cp;
i++; } j++; } return arr; }
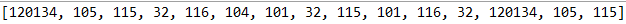
上面我们看到使用到了Character的一个静态方法isSupplementaryCodePoint(int index),该方法的作用“确定指定字符(Unicode代码点)是否在 supplementary character范围内,即检查该码点是否是辅助字符的码点”,
代码分析:
我们首先要创建一个数组来存放字符串中的码点,这个数组的长度和字符串的码点数量一致;定义两个变量作为码点数和数组角标,遍历字符串,判断每个代码单元是否是辅助字符,如果是辅助字符,那么就要往前进两位,否则往前进一位;同时将该码点存入数组中,数组角标进1.
上面我们使用的前进的方法来操作的,自然也是可以后退查询的,下面我们改写上面的代码:
/** * 码点数组 * @param str */ public int[] codePoint(String str){ int[] arr = new int[str.codePointCount(0, str.length())]; int cp = 0; int j = arr.length-1; for (int i = str.length(); i > 0; ) { i--; if(Character.isSurrogate(str.charAt(i))) i--; cp = str.codePointAt(i); arr[j] = cp; j--; } return arr; }
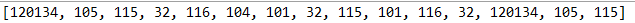
这里很容易就看出来这是通过后退来操作的(--),在这个操作中又使用了Character的一个静态方法isSurrogate(char ch),该方法用来判断码点是否属于辅助字符,从最后一个代码单元开始循环,我们知道代码单元是从0开始的,所以在开始判断前应该是长度先-1,否则会出现越界异常,判断该码点是否属于辅助字符,如果属于,那么向后退1,获取该辅助字符的码点,将其放入数组,同时数组索引减1,因为我是让数组索引和字符串中相应字符对应对弈从后开始填充数组。如果不是辅助字符,那么此时获取该代码单元,而不用再向前退1.
上面是获取码点的数组,下面看一下获取代码单元的数组,这比起上面就简单了很多:
/** * 代码单元数组 */ public int[] codeUnit(String str){ int[] arr = new int[str.length()]; int cp = 0; int j = 0; for (int i = 0; i < arr.length; i++) { arr[j] = str.codePointAt(i); j++; } return arr; }
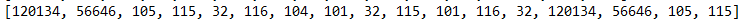
1.3.2 码点和字符串的转换
如果给出一个字符串,你怎么将字符串中的某个码点转换为Unicode中的对应数呢?给定一个码点数,怎么转换为字符串呢?
/** * 码点-->码点数 */ @Test public void numCode(){ String str1 = "𝕆is the set 𝕆is"; System.out.println("\\U+" + Integer.toHexString(str1.codePointAt(0))); } /** * 根据给定Unicode-->String */ @Test public void numString(){ String str1 = "\\U+1d546\\U+1d546"; String[] arr = str1.split("\\\\U\\+"); System.out.println(Arrays.toString(arr)); StringBuilder sb = new StringBuilder(); for (int i = 0; i < arr.length; i++) { if(!arr[i] .equals("")){ int code = Integer.parseInt(arr[i], 16); // sb.append((char)code); 强转会造成辅助字符的丢失 char[] ch = Character.toChars(code); sb.append(ch); } } System.out.println(sb.toString()); }
1.4 总结
String是一种基本的引用数据类型,也是我们使用很频繁的一种引用数据。底层是通过字符数组来实现的,String的长度取决于字符数组的长度,而字符数组的长度在于代码单元的数量,代码单元和码点是截然不同的概念。我们在操作String的时候,通过索引查找到的其实就是相应的代码单元,并不是我们认为的"字符",所以要注意,一旦String中含有辅助字符的时候,我们要切切小心.。
2.不可变的String
本文转载https://www.zhihu.com/question/31345592 @胖胖
不可变的String,初听之下好像是说字符串不可以改变,实际上这种说法,并没错,不过这里我想说的是为什么String要不可变,String是怎么实现不可变的,什么是不可变,下面我们一一探讨一下:
观察String的源代码,我们发现,String是一个被final修饰的类,如下:
public final class String
private final char value[];
。。。。。。。。。。 public native String intern(); }
那么这是什么意思呢?String为什么要用final修饰呢?目的何在呢?下面我们来了解一下:
我们知道final修饰的类不能被继承,而没有子类的类,自然不存在重写方法的风险。JDK中有一些类在设计之处,Java程序员为了保护类不被破坏,就将其修饰为final,拒绝因为继承而造成的恶意对类的方法造成的破坏。这是对String不可变最基础的解释了。
2.1 什么是不可变
String不可变很简单,如下图,给一个已有字符串“abcd”第二次赋值为"abcdel",不是在原内存地址上修改数据,而是重新指向一个新地址,新对象。这是String不可变最直观的的一种理解和解释了,我们通过一段代码就可以看出来:
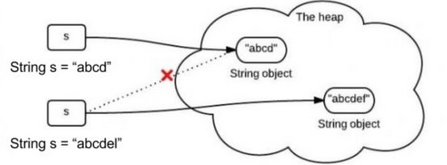
/** * 字符串是不可变的 */ @Test public void fun1(){ String str1 = "abcd"; String str2 = str1; System.out.println(str1 == str2);//true str1 = "abcdel"; System.out.println(str1 == str2);//false }
我们发现,当str1改变后,str2并没有随着改变,这是因为什么呢?通过一幅图来看一下:
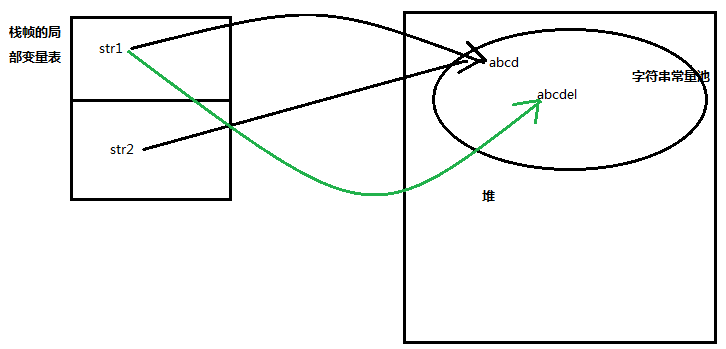
通过这种直接赋值字符串内容生成的字符串对象,会首先去字符串常量池中寻找是否有这个字符串,如果有那么直接返回该字符串地址,如果没有,那么先在字符串常量池中创建该字符串,然后返回该字符串地址;上面在创建str1时就是后一种情况,而在将str1赋值给str2时,是将该字符串常量池中的地址返回给str2的,当str1改变时,由于String是不可变的,所以是重新创建了一个字符串“abcdel”,并将该字符串地址返回给str1,所以此时str1指向了abcdel,但是原有字符串上面还有指针指向它,就是str2,所以也不会被垃圾回收,我们在进行地址判断时,也出现了false的情况。但是如果我们通过另一种方式来创建字符串会是什么情况呢?
/** * 字符串不可变 */ @Test public void fun2(){ String str1 = new String("abcd"); String str2 = str1; System.out.println(str1 == str2);//true str1 = "abcdel"; System.out.println(str1 == str2);//false }
此时这种情况出现的结果和上面是相同的,那么内存中的结构也相同吗?不是的,这种情况虽然结果和上面相同,但是内存结构却差别很大,下面再画副图看一下:
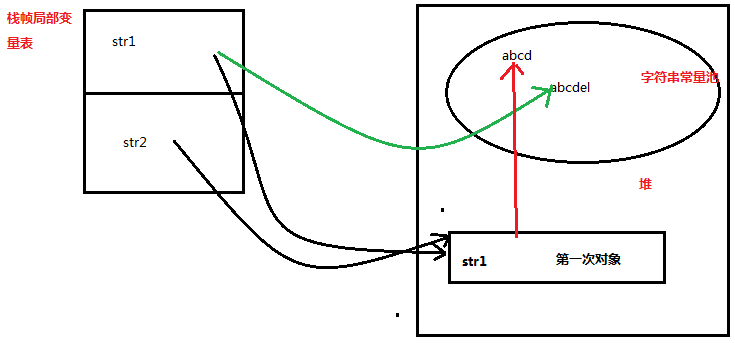
这幅图看起来和上面的很相似,唯一不同的在于我们创建String使用了new,因此而带来的变化是在堆中创建了一个str1对象,str1和str2都指向这个对象,我们更改str1后,str1指向了字符串常量池中的“abcdel”,而str2的指向内有改变,所以我们看到的结果就如同上面所示了。通过两幅图我们知道了String改变时是不会在原有内容上改变的,而是从新创建了一个字符串对象,那么这种不可变是怎么实现的呢?
2.2 String为什么不可变
在前面我们贴出过String的一些源码,我们放到这里再看一下:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { private final char value[];//String本质是一个char数组,而且是通过final修饰的. private int hash; public String() { this.value = "".value; } public String(String original) { this.value = original.value; this.hash = original.hash; } public String(char value[]) { this.value = Arrays.copyOf(value, value.length); } }
首先String类是用final关键字修饰,这说明String不可继承。继续查看发现,String类的核心字段value是个char[],而且是用final修饰的。final修饰的字段创建后就不可改变。可能认为我们讲到这里就完了,其实不然。虽然value是不可变的,但也仅限于这个引用地址不会再发生变化。这并不能否定Array数组是可变的事实。Array的数据结构看下图:
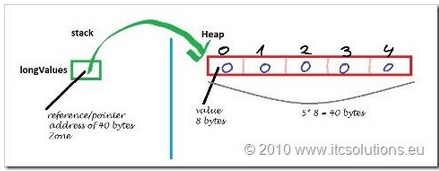
也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。String类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面的示例:
@org.junit.Test public void fun1(){ final int[] value = {1,2,3}; int[] another = {4,5,6}; // value = another;这里会提示final不可改变 }
value用final修饰,编译器不允许我们将value指向堆中另一个地址。但如果我直接对数组元素进行动手,那么情况就又不同了;
@org.junit.Test public void fun1(){ final int[] value = {1,2,3}; System.out.println(Arrays.toString(value));//[1, 2, 3] value[2] = 100; System.out.println(Arrays.toString(value));//[1, 2, 100] }
或者我们使用更粗暴的反射修改也是可以的:
@org.junit.Test public void fun1(){ final int[] value = {1,2,3}; System.out.println(Arrays.toString(value));//[1, 2, 3]// value[2] = 100; Array.set(value, 2, 101); System.out.println(Arrays.toString(value));//[1, 2, 101] }
所以说String是不可变的,关键是因为SUN的工程师在设计该基本工具类时,在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段(value是private的)。private final char value[]这一句中,真正构成不可变的除了final外,还有更重要的一点就是private,private的私有访问权限的作用比final还要重要。而且设计师还很小心地把整个String设计成final禁止继承,避免被其他人继承后破坏。所以String不可变的关键在于底层的实现,而并非单单是一个final。考研的是工程师构造数据类型,封装数据的能力。
2.3 不可变有什么用
上面我们了解了什么是不可变,也了解了不可变是如何实现的,那么不可变在开发中有什么作用呢?也就是优势何在呢?最简单的优点就是为了安全,看下面这个场景:
package cn.charsequence.string.can_not_change; import java.lang.reflect.Array; import java.util.Arrays; public class Test { //不可变的String public static String appendStr(String s){ s += "bbb"; return s; } //可变的StringBuilder public static StringBuilder appendSb(StringBuilder sb){ return sb.append("bbb"); } public static void main(String[] args) { String s = new String("aaa"); String ns = Test.appendStr(s); System.out.println("String aaa >>> " + s.toString());//String aaa >>> aaa StringBuilder sb = new StringBuilder("aaa"); StringBuilder nsb = Test.appendSb(sb); System.out.println("StringBuiler >>> " + sb.toString());//StringBuiler >>> aaabbb } }
如果开发中不小心像上面的例子里,直接在传进来的参数上加“bbb”,因为Java对象参数传的是引用,所以可变的StringBuiler参数就被改变了。可以看到变量sb在Test.appendSb(sb)操作之后,就变成了"aaabbb"。有的时候这可能不是我们的本意。所以String不可变的安全性就体现出来了。再看下面这个HashSet用StringBuilder做元素的场景,问题就更严重了,而且更隐蔽。
public static void main(String[] args) { HashSet<StringBuilder> hs = new HashSet<>(); StringBuilder sb1 = new StringBuilder("aaa"); StringBuilder sb2 = new StringBuilder("aaabbb"); hs.add(sb1); hs.add(sb2); StringBuilder sb3 = sb1; sb3.append("bbb"); System.out.println(hs);//[aaabbb, aaabbb] }
StringBuilder型变量sb1和sb2分别指向了堆内的字面量“aaa”和"aaabbb"。把他们都插入一个HashSet。到这一步没问题。但如果后面我把变量sb3也指向sb1的地址,再改变sb3的值,因为StringBuilder没有不可变性的保护,sb3直接在原先“aaa”的地址上改。导致sb1的值也变了。这时候,HashSet上就出现了两个相等的键值“aaabbb”。破坏了HashSet键值的唯一性。所以千万不要用可变类型做HashMap和HashSet键值。
上面我们说了String不可变的安全性,当有多个引用指向同一个内存地址时,不可变保证了安全性。除了安全性外,String的不可变也体现在了高性能上面。我们知道Java内存结构模型中提供了字符串常量池,我们通过直接赋值的方式创建字符串对象时,会先去字符串常量池中查找该字符串是否存在,如果存在直接返回该字符串地址,如果不存在则先创建后返回地址,如下面:
String one = "someString";
String two = "someString";
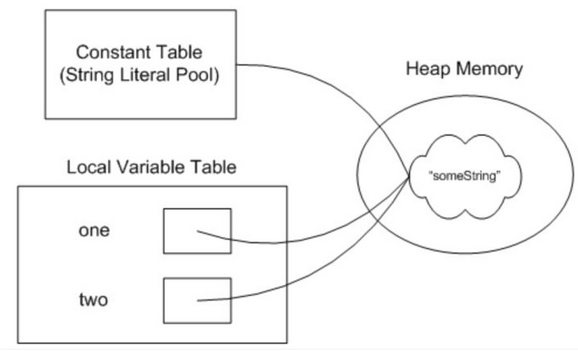
上面one和two指向同一个字符串对象,这样可以在大量使用字符串的情况下,可以节省内存空间,提高效率。但之所以能实现这个特性,String的不可变性是最基本的一个必要条件。要是内存中字符串内容能够改来改去,这么做就完全没有意义了。
总结:String的不可变性提高了复用性,节省空间,保证了开发安全,提高了程序效率。
2.4 不可变提高效率的补充解读
乍一看可能会觉得小编我是不是脑子进水了,怎么上边刚验证了String的不可变安全、高效,在这里又疑惑是否提高效率。其实我在这里想要说的是“有些时候看起来好像修改一个代码单元要比创建一个新字符串更加简洁。答案是也对,也不对。的确,通过拼接“Hel”和“p!”来创建一个新字符串的效率确实不高。但是,不可变字符串却有一个优点:使字符串共享。”
设计之初,Java的设计者认为共享带来的高效率远远胜过于提取、拼接字符串所带来的低效率。查看程序发现:很少需要修改字符串,而是往往需要对字符串进行比较(当然,也有例外情况,将来自文件或键盘的单个字符或较短的字符串汇集成字符串。为此Java提供了缓冲字符串用来操作)。所以应该站在不一样的角度来看不可变的高效率,在合适的地方,采用合适的操作。
3.无意识的递归
无意识的递归是在读《Java编程思想》时遇到的一个知识点,觉得是有必要了解的,下面我们来认识一下:
Java中的每个类从根本上都是继承自Object,标准容器类自然也不例外.因此容器类都有toString()方法,并且覆写了该方法,使得它生成的String结果能够表达容器自身,以及容器所包含的对象.例如ArrayList.toString(),它会遍历ArrayList中包含的所有对象,调用每个元素上的toString()方法.但如果你希望toString()打印出对象的内存地址,也许你会考虑使用this关键字:
package cn.charsequence.string.can_not_change; import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class InfiniteRecursion { /** * 重写toString方法 */ @Override public String toString() { // TODO Auto-generated method stub return " InfiniteRecursion address: " + this + "\n"; } public static void main(String[] args) { List<InfiniteRecursion> list = new ArrayList<InfiniteRecursion>(); for (int i = 0; i < 10; i++) { list.add(new InfiniteRecursion()); } System.out.println(list); } }
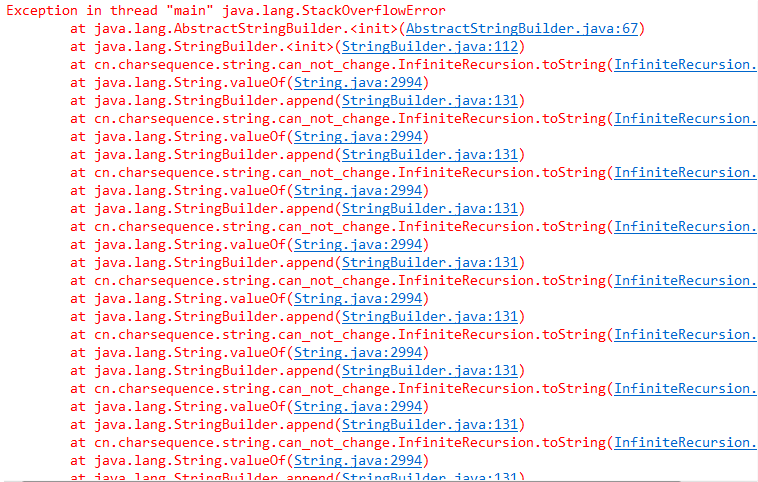
当你创建了InfiniteRecursion对象,并将其打印出来的时候,你会得到一串非常长的异常.如果你将该InfiniteRecursion对象存入一个ArrayList中,然后打印该ArrayList,你也会得到同样的异常.其实,当如下代码运行时:
return " InfiniteRecursion address: " + this + "\n";
这里发生了自动类型转换.由InfiniteRecursion类型转换成String类型.因为编译器看到一个String对象后面跟着一个”+”,而再后面的对象不是String,于是编译器试着将this转换成一个String.它怎么转换呢,正是通过this上的toString()方法,于是就发生了递归调用.
如果你真的想要打印出对象的内存地址,应该调用Object.toString()方法,这才是负责此任务的方法,所以你不该使用this,而是应该调用super.toString()方法.改变上面toString方法代码:
/** * 重写toString方法 */ @Override public String toString() { // TODO Auto-generated method stub // return " InfiniteRecursion address: " + this + "\n"; return " InfiniteRecursion address: " + super.toString() + "\n"; }

4. 重载“+”与StringBuilder
String对象是不可变的,你可以给一个String对象加任意多的别名.改变String时会创建一个新的String,原String并不会发生变化,所以指向它的任何引用都不可能改变原有的值,因此,也就不会对其他的引用有什么影响(例如两个别名指向同一个引用,一个别名有了改变这个引用的操作,那么不可变性就保证了另一个别名引用的安全).
不可变性会带来一定的效率问题.为String对象重载的”+”操作符就是一个例子.重载的意思是,一个操作符在应用于特定的类时,被赋予了特殊的意义(用于String的”+”与”+=”是Java中仅有的两个重载过的操作符,而Java并不允许程序员重载任何操作符).+在数学中用来两个数的相加,在字符串中用来连接String:
package cn.string.two; public class Concatenation { public static void main(String[] args) { String mango = "mango"; String s = "abc" + mango + "def" + 47; System.out.println(s); } }
可以想象一下,这段代码可能是这样工作的:String可能有一个append()方法,它会生成一个新的String对象,以包含”abc”与mango连接后的字符串.然后,该对象再与”def”相连,生成另一个新的String对象,依次类推.这种工作方式当然也行得通,但是为了生成最终的String,此方式会产生一大堆需要垃圾回收的中间对象.我猜想,Java设计师一开始就是这么做的(这也是软件设计中的一个教训:除非你用代码将系统实现,并让它动起来,否则你无法真正了解它会有什么问题),然后他们发现其性能相当糟糕.想看看以上代码到底是如何工作的吗,可以用JDK自带的工具javap来反编译以上代码.命令如下:

这里的-c标志表示将生成JVM字节码.我剔除掉了不感兴趣的部分,然后作了一点点修改,于是有了以下的字节码:
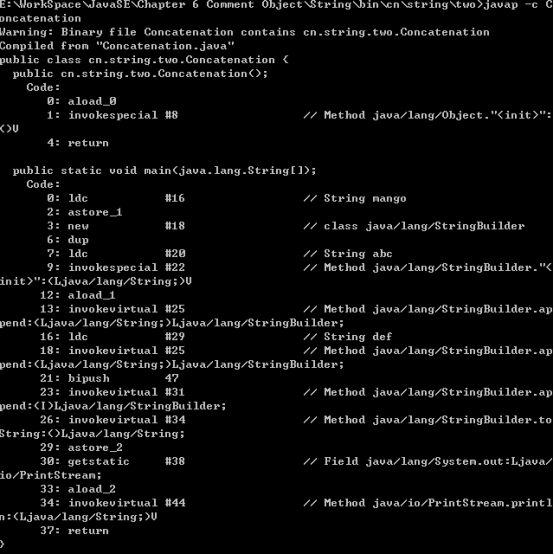
如果有汇编语言的经验,以上代码一定看着眼熟,其中的dup与invokevirtural语句相当于Java虚拟机上的汇编语句.即使你完全不了解汇编语言也无需担心,需要注意的重点是:编译器自动引入了java.lang.StringBuilder类.虽然我们在源代码中并没有使用StringBuilder类,但是编译器却自作主张地使用了它,因为它更高效.
在这个例子中,编译器创建了一个StringBuilder对象,用以构造最终的String,并为每个字符串调用一次StringBuilder的append()方法,总计四次.最后调用toString()生成结果,并存在s(使用的命令为astore_2)
现在,也许你会觉得可以随意使用String对象,反正编译器会为你自动地优化性能.可是在这之前,让我们更深入地看看编译器能为我们优化到什么程度.下面的程序采用两种方式生成一个String:方法一使用了多个String对象,方法二在代码中使用了StringBuilder.
package cn.stringPractise.Commonoperation; public class WhitherStringBuilder { public static void main(String[] args) { String[] str = {"长安古道马迟迟","高柳乱蝉嘶","夕阳岛外","秋风原上","目断四天垂", "归云一去无踪迹","何处是前期","狎兴生疏","酒徒萧索","不似去年时。"}; System.out.println(implicit(str)); System.out.println(explicit(str)); } public static String implicit(String[] fields){ String result = ""; for (int i = 0; i < fields.length; i++) { result += fields[i]; } return result; } public static String explicit(String[] fields){ StringBuilder sb = new StringBuilder(); for (int i = 0; i < fields.length; i++) { sb.append(fields[i]); } return sb.toString(); } }
public static void main(String[] args) { String[] str = {"长安古道马迟迟","高柳乱蝉嘶","夕阳岛外","秋风原上","目断四天垂", "归云一去无踪迹","何处是前期","狎兴生疏","酒徒萧索","不似去年时。"}; String[] str1 = new String[20000]; for (int i = 0; i < 20000; i++) { str1[i] = Integer.toString(i); } long start = System.currentTimeMillis(); // System.out.println(implicit(str1)); implicit(str1); long end = System.currentTimeMillis(); System.out.println(end-start); start = System.currentTimeMillis(); explicit(str1); // System.out.println(explicit(str1)); end = System.currentTimeMillis(); System.out.println(end-start); }


现在运行javap -c WitherStringBuilder,可以看到两个方法对应的(简化过的)字节码.首先是implicit()方法:
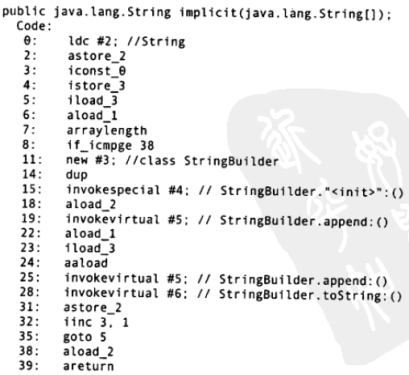
注意从第8行到第35行构成了一个循环体.第8行:对堆栈中的操作数进行”大于或等于的整数比较运算”,循环结束时跳到第38行.第35行:返回循环体的起始点(第5行).要注意的重点是:StringBuilder是在循环体内构成的,这意味着每经过一次循环,就会创建一个新的StringBuilder对象.
下面是explicit()方法对应的字节码:
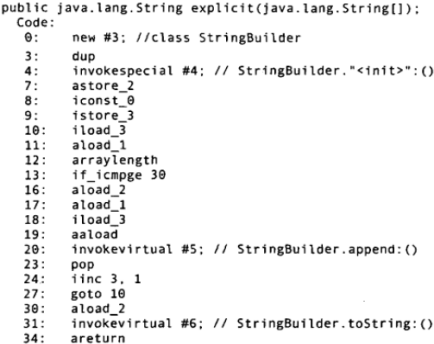
可以看到,不仅循环部分的代码更简短、更简单,而且它只生成了一个StringBuilder对象。显式的创建StringBuilder还允许你预先为其指定大小.如果你已经知道最终的字符串大概有多长,那预先指定StringBuilder的大小可以避免多长重新分配缓冲.
因此,当你为一个类编写toString()方法时,如果字符串操作比较简单,那就可以信赖编译器,它会为你合理地构造最终的字符串结果.但是,如果你要在toString()方法中使用循环,那么最好自己创建一个StringBuilder对象,用它来构造最终的结果.参考一下示例:
package cn.stringPractise.Commonoperation; import java.util.Random; public class UsingStringBuilder { public static Random rand = new Random(47); @Override public String toString() { StringBuilder builder = new StringBuilder("["); for (int i = 0; i < 25; i++) { builder.append(rand.nextInt(100)); builder.append(","); } builder.delete(builder.length()/2, builder.length()); builder.append("]"); return builder.toString(); } public static void main(String[] args) { UsingStringBuilder usingStringBuilder = new UsingStringBuilder(); System.out.println(usingStringBuilder); } }
public void println(Object x) { String s = String.valueOf(x); synchronized (this) { print(s); newLine(); } }
public static String valueOf(Object obj) { return (obj == null) ? "null" : obj.toString(); }
最终的结果是用append()语句一点点拼接起来的.如果你想走捷径,例如append(a+”:”+c),那编译器就会掉入陷阱,从而为你另外创建一个StringBuilder对象处理括号内的字符串操作.如果拿不准该用哪种方式,随时可以用javap来分析你的程序.
StringBuilder提供了丰富而全面的方法,包括insert()、repleace()、substring()甚至reverse(),但是最常用的还是append()和toString().还有delete()方法,上面的例子中我们用它删除最后一个逗号与空格,以便添加右括号.
StringBuilder是Java SE5引入的,在这之前Java用的是StringBuffer.后者是线程安全的,因此开销也会大些,所以在Java SE5/6中,字符串操作应该还会更快一点.关于缓冲字符串我们在介绍完String后会统一再详细介绍。
4.1 重载“+”流程简略
两个字段在进行“+”操作时,那么究竟是怎么操作呢?我们自己书写一段代码,debug可以看到,在操作时会首先调用String,valueOf()方法,如果该字段是null,那么返回null,否则调用toString方法,将其转变为String,进行StringBuilder。append()操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号