

今天跟大家分享的是强化学习在阿里的技术演进与业务创新的知识,下拉文末获取网盘链接
第一章 基于强化学习的实时搜索排序策略调控
1.1 背景

1.2 问题建模

1.2.1 强化学习简介

1.2.2 状态定义
1.2.3 奖赏函数设定
1.3 算法设计

1.3.1 策略函数
1.3.2 策略梯度
1.3.3 值函数的学习
1.4 奖赏塑形

1.5 实验效果

1.6 DDPG 与梯度融合
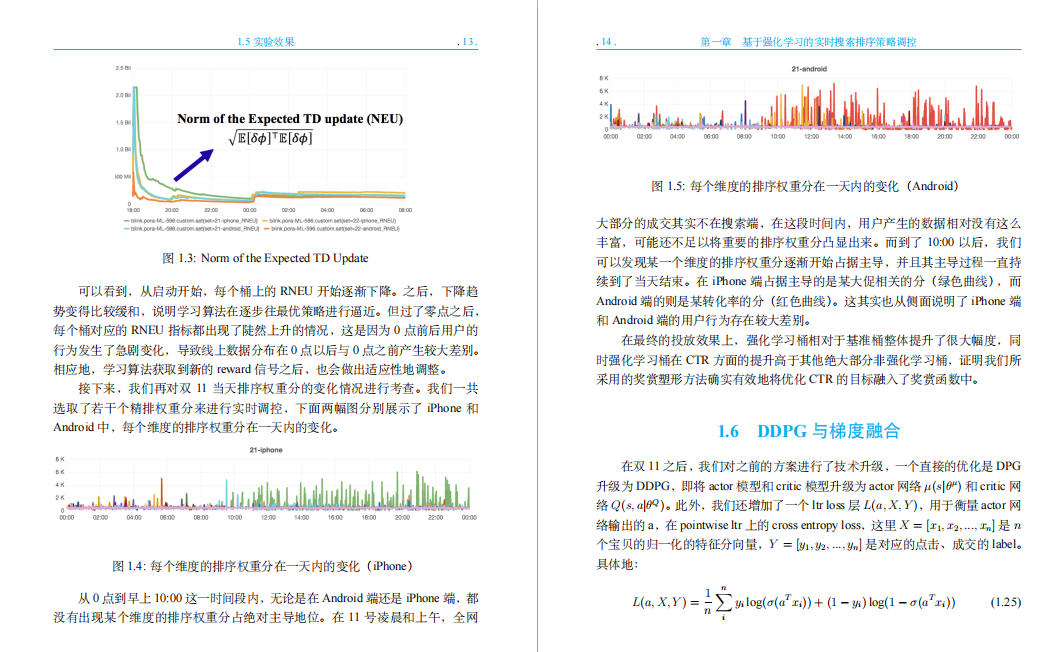
1.7 总结与展望
第二章 延迟奖赏在搜索排序场景中的作用分析
2.1 背景

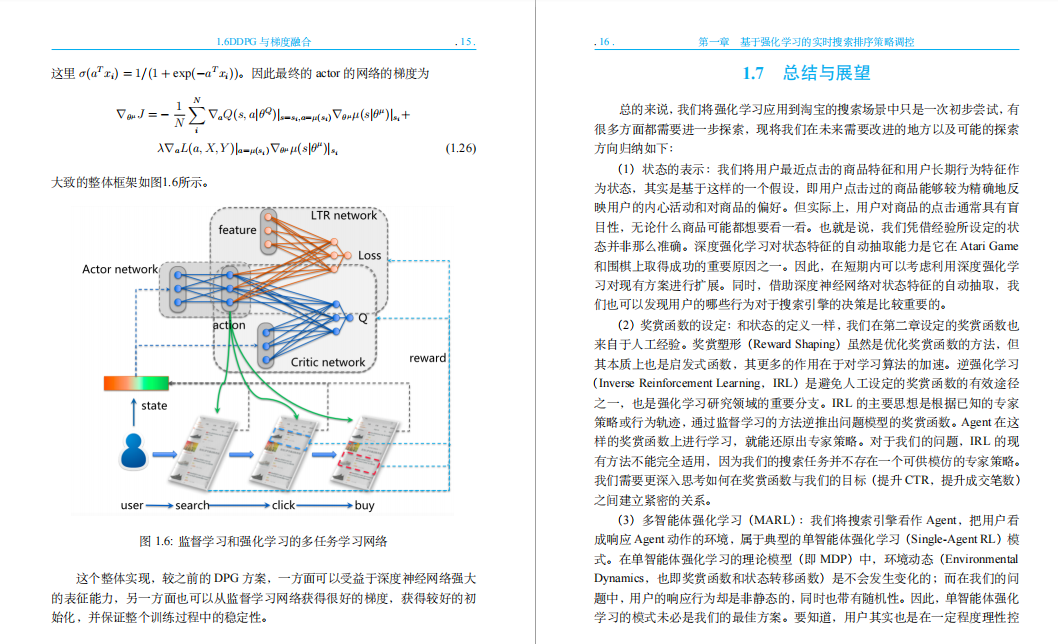
2.2 搜索排序问题回顾
2.3 数据统计分析

2.4 搜索排序问题形式化

2.5 理论分析

2.5.1 马尔可夫性质
2.5.2 折扣率
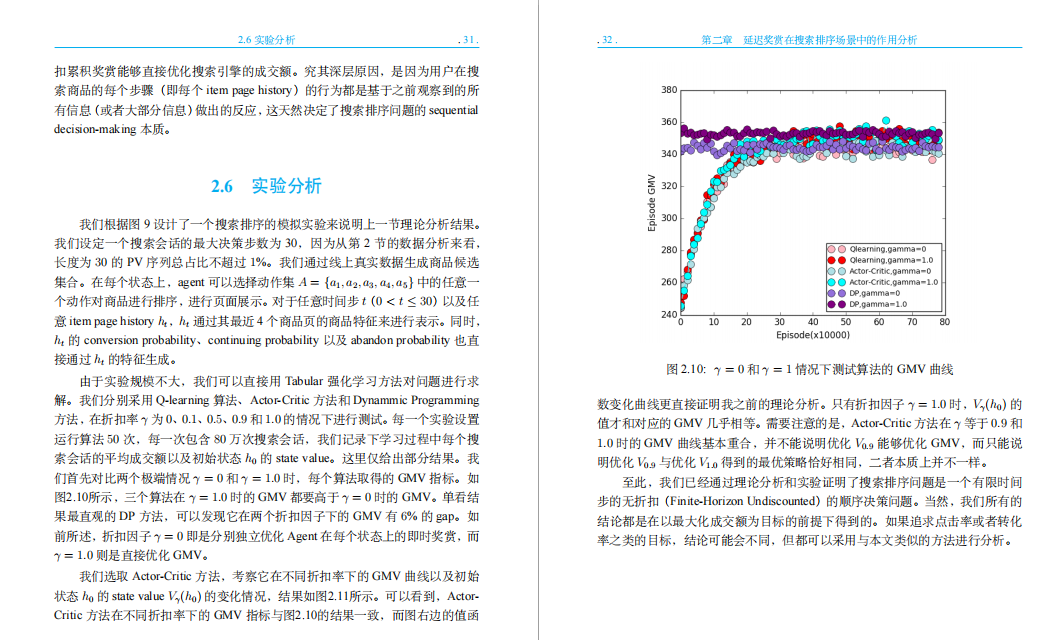
2.6 实验分析
第三章 基于多智能体强化学习的多场景联合优化
3.1 背景

3.2 问题建模

3.2.1 相关背景简介
3.2.2 建模⽅法
3.3 应⽤
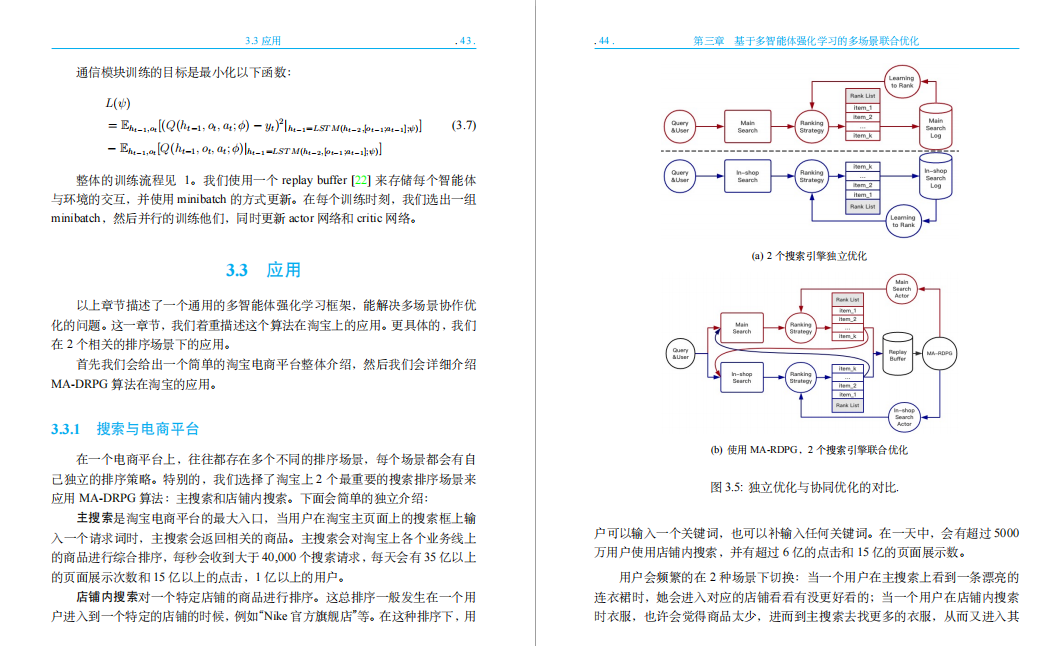
3.3.1 搜索与电商平台
3.3.2 多排序场景协同优化
3.4 实验

3.4.1 实验设置
3.4.2 对⽐基准
3.4.3 实验结果
3.4.4 在线⽰例
3.5 总结与展望

第四章 强化学习在淘宝锦囊推荐系统中的应用
4.1 背景

4.1.1 淘宝锦囊
4.1.2 锦囊的类型调控
4.1.3 ⼯作摘要
4.2 系统框架及问题建模
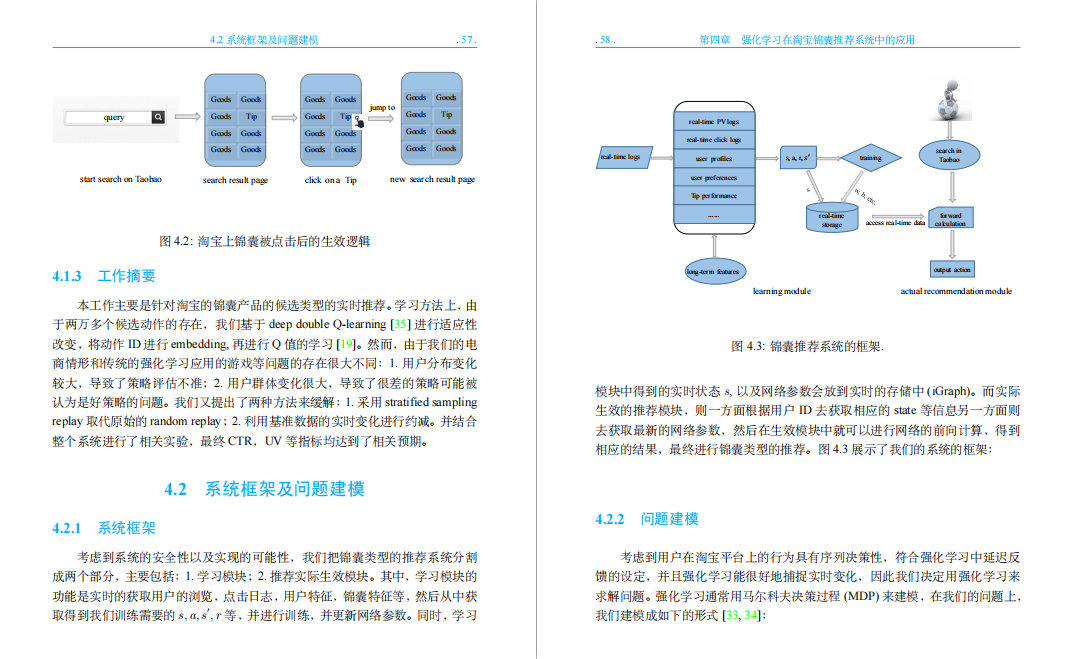
4.2.1 系统框架
4.2.2 问题建模
4.3 算法及模型设计

4.3.1 主体框架
4.3.2 分层采样池
4.3.3 基准约减
4.3.4 算法流程
4.4 实验与总结

由于文档过大,只给大家展示了一部分
点击链接获取完整文档
链接:https://pan.baidu.com/s/15Xl80bxXK2rkDD3_N20Efg
提取码:z3yc

