

SQL基础
SQL基础
LIKE操作符进行通配搜索
通配符(wildcard):用来匹配值的一部分的特殊字符
搜索模式(search pattern):由字面值、通配符或两者组合构成的搜索条件
用途:例如搜索产品名包含bean bag的所有产品
为了在搜索子句中使用通配符,必须使用LIKE操作符。LIKE指示DBMS后跟的搜索模式利用通配符匹配而不是简单的相等匹配进行比较。
谓词(predicate):从技术上来说LIKE其实是谓词而不是操作符。
几种通配符:
| 通配符 | 作用 |
|---|---|
% |
表示任何字符出现任意次数(包括0次) |
_ |
表示匹配单个字符 |
[] |
指定一个字符集,必须匹配通配符所在位置的一个字符 |
WHERE prod_name LIKE 'Fish%'; --找出所有以Fish起头的产品
WHERE prod_name LIKE '%bean bag%'; --找出所有包含bean bag的产品名
WHERE prod_name LIKE '__ inch teddy bear'; --匹配两位字符(因为有2个下划线)
WHERE cust_contact LIKE '[JM]%'; --找出所有名字以J或M起头的联系人
WHERE cust_contact LIKE '[^JM]%'; --找出所有名字不是J和M起头的联系人(^表示否定该集合)
注意后面所跟的空格
许多DBMS都用空格来填补字段的内容。比如某列设置为50个字符,而存储的文本只有17个,那就会在这个文本后面多添加33个空格。这样做的话如果我们想匹配以f开头y结尾的文本就会有影响,因为此时最末尾的是空格而不是y。所以不能写成'f%y',而只能写成'f%y%'来匹配后面的空格。或者最好的方法就是利用函数去掉最后的空格。
也要注意
%不能匹配NULL。
只有Microsoft Access和SQL Server支持集合
[]。
使用通配符的技巧
通配符的代价是搜索时间比其它搜索长。所以:
- 不要过度使用通配符。如果其它操作符能达到目的,应该使用其他操作符。
- 在确实需要使用通配符的时候,尽量不要把它们用在搜索模式的开始处。把通配符放在最开始的地方,搜索起来是最慢的。
创建计算字段(Calculated fields)
存储在数据库表中的数据一般不是我们需要的格式,因此我们在SELECT的过程中可以直接检索出转换、计算或者格式化过的数据,而不是检索出数据,然后再在客户端的应用程序中重新格式化。
计算字段不实际存在于数据库表中,而是运行时在SELECT语句内创建的。
在SQL语句中可以完成的许多转换和格式化工作其实都可以直接在客户端应用程序内完成,但是一般来说在数据库服务器上完成这些操作比在客户端中更快。
几种典型的计算字段
拼接字段(concatenate)
把两个列拼接起来。在SQL中的SELECT语句中可使用一个特殊的操作符来拼接两个列。Access和SQL Server是+,DB2、Oracle、PostgreSQL、SQLite等使用||。在MySQL和MariaDB中必须使用特殊的函数。
SELECT vend_name + '(' + vend_country + ')' AS vend_title FROM ...
SELECT vend_name || '(' || vend_country || ')' AS vend_title FROM ...
SELECT Concat(vend_name, '(', vend_country, ')') AS vend_title FROM ... -- MySQL或MariaDB
有时
vend_name或vend_country可能会在字符串最后有多余的空格来填充到该field设置的长度。我们不需要这些空格,所以可以用RTRIM()函数来把右边的空格去掉:RTRIM(vend_name)。除了RTRIM()外,还有LTRIM()和TRIM()
计算字段没有名字,它只是一个值。如果只是我们自己在使用SQL的时候查结果比较无所谓,但是如果要在客户端中应用的话没有名字就是个问题。因此需要用
AS关键字给该字段赋予别名(alias)。
执行算数计算
SELECT quantity*item_price AS expanded_price FROM ...
使用函数处理数据
SQL函数在不同的DBMS中有可能不一样。事实上只有少数几个函数被所有主要的DBMS等同地支持。如:
| 函数 | 语法 |
|---|---|
| 提取字符串的组成部分 | Access使用MID()Oracle、PostgreSQL和SQLite使用 SUBSTR();MySQL和SQL Server使用 SUBSTRING() |
| 数据类型转换 | Access、Oracle每种类型的转换有一个函数; DB2和PostgreSQL使用 CAST()MariaDB和SQL Server使用 CONVERT() |
| 取当前日期 | Access使用NOW();DB2和PostgreSQL使用 CURRENT_DATE;MariaDB和MySQL使用 CURDATE();Oracle使用 SYSDATESQL Server使用 GETDATE()SQLite使用 DATE() |
上表说明,SQL函数有不可移植性。
一些函数的示例:
-
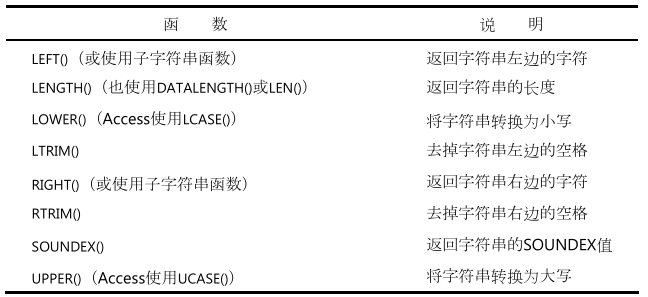
常用的文本处理函数:
![image]()
-
常用的日期和时间处理函数
每个DBMS都不一样。
-
数值处理函数:
主要的DBMS中都比较统一——
函数 说明 ABS() 返回绝对值 COS() 返回一个角度的余弦 EXP() 返回一个数的指数值 PI() 返回圆周率 SIN() 返回一个角度的正弦 SQRT() 返回一个数的平方根 TAN() 返回一个角度的正切
聚集函数与数据的汇总
聚集函数(aggregate function):对某些行运行的函数,计算并返回一个值。
使用聚集函数的目的:我们不需要实际检索出数据,而是对这些数据进行一个汇总,比如说计数、求和、找最大最小平均值等。
SQL给出了5个聚集函数——AVG(), COUNT(), MAX(), MIN(), SUM()
基本使用
SELECT SUM(item_price*quantity) AS total_price
FROM ...
输出:
total_price
----------
1648.0000
其他使用方法(使用聚集参数)
-
对所有行执行计算——指定
ALL参数或不指定参数(ALL是默认行为) -
只包含不同的值——指定
DISTINCT参数(Access不支持)SELECT AVG(DISTINCT prod_price) AS avg_price FROM ...DISTINCT不能用于COUNT(*),只能使用COUNT()。DISTINCT用于MIN()和MAX()没有意义,因为一组数据不管有没有distinct,它的最大和最小值都是一样的。 -
除了
ALL和DISTINCT两个参数外,DBMS还支持其它参数,如支持对查询结果的子集进行计算的TOP和TOPPERCENT。具体参阅相关文档。
分组数据——GROUP BY和HAVING子句
GROUP BY
- GROUP BY子句可以包含任意数目的列,因此可以对分组进行嵌套,更细致地进行数据分组。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后指定的分组上进行汇总。
- GROUP BY子句中列出的每一个列都必须是检索列或有效的表达式。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前
HAVING —— 过滤分组
SQL允许过滤分组,规定包含哪些分组,排除哪些分组。例如,我们可能只想列出至少有2个订单的所有顾客。为此,必须基于完整的分组而不是个别的行进行过滤。
WHERE在GROUP BY之前,过滤的是行而不是分组。因此WHERE不能够完成任务。
过滤分组举例:
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
输出:
cust_id orders
---------- -----------
1000000001 2
可以看到,在这里HAVING过滤是基于分组之后计算出的聚集值,而不是特定行的值。
HAVING和WHERE的差别的另一种理解:
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。因此WHERE排除的行不包括在分组中。
同时使用WHERE和HAVING的例子:返回过去12个月内具有2个以上顾客的订单。
- 先用WHERE语句过滤出过去12个月内下过的订单,然后再增加HAVING子句过滤出具有两个以上订单的分组。
SELECT子句顺序
SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY
子查询
WHERE中的子查询
在SELECT语句中,子查询总是从内向外处理。包含子查询的SELECT语句难以阅读和调试,所以把子查询分解为多行并进行适当的缩进,能极大简化子查询的使用。
SQL语句对于能嵌套的子查询的数目没有限制。不过在实际使用中由于性能的限制,不能嵌套太多的子查询。
作为计算字段使用子查询
【例】Orders表中有订单与相应的顾客ID,求:显示Customer表中每个顾客的订单总数。
【解】步骤如下:
- 从Customer表中检索顾客列表
- 对于检索出的每个顾客,统计其在Orders表中的订单数目。
我们最终结果的其中一列是“订单数目”,而这个数目是每个顾客在Orders表中的订单数目。对于单个顾客,我们可以通过下面的代码获得其订单数目:
SELECT COUNT(*) AS orders
FROM Orders
WHERE cust_id='100000001';
而对每个顾客,我们可以从Customers表中获得cust_id,从而满足要求:
SELECT cust_name, cust_state,
(SELECT COUNT(*) FROM Orders WHERE Orders.cust_id=Customers.cust_id) AS orders
FROM Customers
ORDER BY cust_name;
这条SELECT语句对Customers表中的每个顾客返回3列:cust_name, cust_state和orders。orders是一个计算字段,是由圆括号中的子查询建立的。该子查询对检索出的每个顾客执行一次。
在这里使用了完全限定列名,即
Orders.cust_id=Customers.cust_id,如果不用完全限定列名,仅仅采用cust_id=cust_id会让DBMS对Orders表中的cust_id自身进行比较,这会总是返回Orders表中订单的总数。
联结表
基础联结
-
最简单的联结(内联结inner join、等值联结equijoin):
SELECT vend_name, prod_name, prod_price FROM Vendors, Products WHERE Vendors.vend_id=Products.vend_id;WHERE子句在此声明的是两个表联结的条件。如果没有WHERE这个条件的限定,则第一个表中的每一行将与第二个表中的每一行进行配对,而不管它们逻辑上是否能配在一起。由没有联结条件的表关系返回的结果为笛卡尔积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
如果采用内联结的另外一种语法
INNER JOIN,则如下:SELECT vend_name, prod_name, prod_price FROM Vendors INNER JOIN Products ON Vendors.vend_id=Products.vend_id; -
内联结多个表
SELECT prod_name, vend_name, prod_price, quantity FROM OrderItems, Products, Vendors WHERE Products.vend_id = Vendors.vend_id AND OrderItems.prod_id = Products.prod_id AND order_num = 20007;
创建高级联结
使用表别名
使用表别名的理由:
- 缩短SQL语句
- 允许在一条SELECT语句中多次使用相同的表
SELECT cust_name, cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
使用不同类型的联结
自联结
【例】给与Jim Jones同一公司的所有顾客发送一份邮件。这个查询要求首先找出Jim Jones工作的公司,然后找出在该公司下工作的顾客。下面是通过自联结解决的代码:
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';
自然联结
无论何时对表进行联结,两个表(或多个表)中应该会有至少一列重复的列(或者更多)用来联结。标准的联结(前面介绍的内联结)返回所有数据,相同的列甚至出现多次。自然联结排除多次出现,使每一列只返回一次。一般的做法是:对一个表使用通配符(SELECT*),而对其他的表的列使用明确的子集来完成。下面举一个例子:
SELECT C.*, O.order_num, O.order_date,
OI.prod_id, OI.quantity, OI.item_price
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
外联结
外联结包括没有关联行的行,也就是说如果有没匹配到条件的行,外联结允许返回Null。外联结的语法为OUTER JOIN,在实际使用的时候一般会加上LEFT或RIGHT来指定是哪个表的列应该包含所有的行(就是说这个表的这一列要全部出现,另一张表如果没匹配到就Null)。还有一种全外联结(full outer join),但很多DBMS都不支持。
使用带聚集函数的联结
【例】检索所有顾客及每个顾客所下的订单数
SELECT Customers.cust_id,
COUNT(Orders.order_num) AS num_ord
FROM Customers INNER JOIN Orders
ON Customers.cust_id = Orders.cust_id
GROUP BY Customers.cust_id;
GROUP BY子句按顾客分组数据,因此函数调用COUNT(Orders.order_num)对每个顾客的订单计数,将它作为num_ord返回。
组合查询
多数SQL查询只包含从一个或多个表中返回数据的单条SELECT语句。但是SQL允许执行多条SQL语句,并将结果作为一个查询结果返回。这些组合查询通常称为并(union)或复合查询(compound query)。
主要有2种情况需要使用组合查询:
- 在一个查询中从不同的表返回结构数据
- 对一个表执行多个查询,按一个查询返回数据
组合查询和多个
WHERE条件多数情况下,组合相同的表的两个查询所完成的工作=含多个
WHERE子句条件的一个查询完成的工作。i.e.任何具有多个WHERE子句的SELECT语句都可以作为一个组合查询。
创建组合查询
使用UNION关键字
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';
第一条
SELECT把三个州的缩写传入IN子句,检索出这些州的所有行。第二条SELECT把顾客名为Fun4All的所有行找出来。
上面的语句的效果如果用WHERE子句多个条件的方式来实现就是:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
OR cust_name = 'Fun4All';
一般如果是简单的问题,直接使用多个WHERE条件来限制就好了。但是如果复杂情况下使用UNION可能会更简单。
使用UNION的注意事项:
UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过不需要用相同顺序列出)- 列数据必须兼容:类型不必完全相同,但是必须是DBMS可以隐含转换的类型(例如不同的数值类型或不同的日期类型)
UNION默认取消重复的行。如果我们想允许返回的结果含有重复的行,可以使用UNION ALL- 为
UNION查询进行排序时,要在最后一条SELECT语句之后使用ORDER BY子句。不允许使用多条ORDER BY子句。
使用视图
基本概念
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
为什么要使用视图?有以下一些原因:
- 重用SQL语句
- 简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节。
- 使用表的一部分而不是整个表。
- 保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
如:现在有以下SELECT查询语句:
SELECT cust_name, cust_contact
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num
AND prod_id = 'RGAN01';
上面的SELECT查询语句用来检索订购了RGAN01产品的顾客。如果我们想检索其他产品或多个产品的话,就需要了解Customers表、Orders表等底层表格的结构,并修改WHERE子句中的内容。现在,假如可以把整个查询包装成一个名为ProductCustomers的虚拟表,则我们可以轻松地检索出相同的数据:
SELECT cust_name, cust_contact
FROM ProductCustomers
WHERE prod_id = 'RGAN01';
其中ProductCustomers是一个视图。作为视图,它不包含任何列或数据,包含的是一个查询(与上面用以正确联结表的相同查询)。
因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时需要的所有检索。如果你用多个联结和过滤创建了复杂的视图或者嵌套了视图,性能可能会下降得很厉害。因此,在部署使用了大量视图的应用前,应该进行测试。
创建视图
视图用CREATE VIEW语句来创建。CREATE VIEW只能用来创建不存在的视图。
视图简化SQL语句
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num;
这条语句创建一个名为ProductCustomers的视图,它联结三个表,返回已订购了任意产品的所有顾客的列表。有了这个视图后,我们如果想查询订购了产品RGAN01的顾客,只需要:
SELECT cust_name, cust_contact
FROM ProductCustomers
WHERE prod_id='RGAN01';
可以看出,视图极大地简化了复杂SQL语句的使用。利用视图可以一次性地编写基础的SQL,然后根据需要多次使用。在创建视图的时候,最好是创建不绑定特定数据的视图,比如说上面创建的视图返回的是订购所有产品的顾客,而不是只仅仅返回订购了RGAN01的顾客,这样一来就使得我们创建的这个视图可以被重用,而且可能更有用。
视图重新格式化检索出的数据
CREATE VIEW VendorLocations AS
SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')'
AS vend_title
FROM Vendors;
如果我们需要一直用到vend_name (vend_country)这种输出格式的话,干脆直接用上面的语句创建视图,就可以一直重用了。
视图过滤不想要的数据
CREATE VIEW CustomerEMailList AS
SELECT cust_id, cust_name, cust_email
FROM Customers
WHERE cust_email IS NOT NULL;
使用存储过程
基本概念
存储过程(Procedure)是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程中可以包含逻辑控制语句和数据操纵语句,可以接受参数、输出参数、返回单个或多个结果集以及返回值。
使用存储过程的理由:
-
由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的 SQL 语句块要快。
-
在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担。
-
不要求反复建立一系列处理步骤,因而保证了数据的一致性。如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的。
-
……
存储过程的一些缺陷:
- 不可移植性:不同DBMS的存储过程语法有所不同。
- 难度大:一般来说,编写存储过程比编写基本 SQL语句复杂,需要更高的技能,更丰富的经验。
执行存储过程
执行别人写好的存储过程是最常见的。SQL语句为EXECUTE。
EXECUTE AddNewProduct('JTS01', 'Stuffed Eiffel Tower', 6.49, 'Plush stuffed toy with the text La Tour Eiffel in red white and blue');
创建存储过程
不同DBMS创建存储过程的语法有所不同。下面的代码位SQL Server的版本。
【例1】
CREATE PROCEDURE MailingListCount
AS
DECLARE @cnt INTEGER
SELECT @cnt = COUNT(*)
FROM Customers
WHERE NOT cust_mail IS NULL
RETURN @cnt;
该存储过程没有参数。用
DECLARE语句声明了一个名为@cnt的局部变量(SQL Server中所有局部变量名都以@开头);然后在SELECT语句中使用这个变量,让它包含COUNT()函数返回的值;最后,用RETURN @cnt语句将计数值返回给调用程序。
调用SQL Server例子:
DECLARE @ReturnValue INT
EXECUTE @ReturnValue=MailingListCount;
SELECT @ReturnValue
这段代码声明了一个变量来保存存储过程返回的任何值,然后执行存储过程,再使用
SELECT语句显示返回的值。
【例2】在Orders表中插入一个新订单。
CREATE PROCEDURE NewOrder @cust_id CHAR(10)
AS
-- Declare variable for order number
DECLARE @order_num INTERER
-- Get current highest order number
SELECT @order_num=MAX(order_num)
FROM Orders
-- Determine next order number
SELECT @order_num=@order_num+1
-- Insert new order
INSERT INTO Orders(order_num, order_date, cust_id)
VALUES(@order_num, GETDATE(), @cust_id)
-- Return order number
RETURN @order_num;
这个存储过程输入一个参数,即下订单顾客的ID,这里的局部变量命名为@cust_id。订单号和订单日期这两列在存储过程中自动生成。代码首先声明一个局部变量来存储订单号。接着,检索当前最大订单号(使用MAX()函数)并增加 1(使用SELECT语句)。然后用INSERT语句插入由新生成的订单号、当前系统日期(用GETDATE()函数检索)和传递的顾客 ID组成的订单。最后,用RETURN @order_num返回订单号(处理订单物品需要它)。
另一个实现方法:
CREATE PROCEDURE NewOrder @cust_id CHAR(10)
AS
-- Insert new order
INSERT INTO Orders(cust_id)
VALUES(@cust_id)
-- Return order number
SELECT order_num = @@IDENTITY;
注意:这边的订单号是由DBMS自动生成的。大多数DBMS都支持自增,SQL Server中称这些自动增量的列为标识字段(identity field),而其他DBMS称之为自动编号(auto number)或序列(sequence)。SQL Server中获得自动生成的这个ID的方法是利用全局变量@@IDENTITY。
管理事务处理
基本概念
事务处理(transaction processing),通过确保成批的SQL操作要么完全执行,要么完全不执行,来维护数据库的完整性。
Example
给系统添加订单的过程如下:
- 检查数据库中是否存在相应的顾客,若不存在则添加;
- 检查顾客ID;
- 在Orders表添加一行,与顾客ID相关联;
- 检索Orders表中赋予的新订单ID;
- 为订购的每个物品在OrderItems表中添加一行,通过检索出来的ID把它与Orders表关联(并且通过产品ID与Products表关联)
若现在由于某些数据库故障,这个过程无法完成,则有可能产生问题。这个时候就需要用到事务处理了。利用事务处理,可以保证一组操作不会中途停止,要么完全执行,要么完全不执行。如果没有错误发生,整组语句提交给(写到)数据库表;若发生错误,则进行rollback(回退),将数据库恢复到某个已知的安全状态。
- 事务(transaction):指一组SQL语句;
- 回退(rollback):指撤销指定SQL语句的过程;
- 提交(commit):将没储存的SQL语句结果写入数据库表;
- 保留点(savepoint):指事务处理中设置的临时占位符(placeholder),可以对它发布回退(与回退整个事务处理不同)
事务处理可以用来管理
INSERT、UPDATE和DELETE语句,不能回退SELECT语句(也没有必要)。也不能回退CREATE或DROP操作。事务处理中可以使用这些语句,但是回退时这些操作也不撤销。
控制事务处理
不同DBMS实现事务处理的语法有所不同。
管理事务的关键在于将SQL语句组分解成逻辑块,并明确规定数据何时应该回退,何时不应该回退。
有些DBMS要求明确表示事务处理块的开始和结束。如在SQL Server中,标识如下:
BEGIN TRANSACTION
...
COMMIT TRANSACTION
其他DBMS的语法:
-- PostgreSQL
BEGIN
...
-- Oracle
SET TRANSACTION
...
-- MariaDB & MySQL
START TRANSACTION
...
多数DBMS没有明确标识事务处理在何时结束。事务一直存在,直到被中断。通常COMMIT用于保存更改,ROLLBACK用于撤销。
使用ROLLBACK
DELETE FROM Orders;
ROLLBACK;
在上例中执行DELETE操作,然后用ROLLBACK语句撤销。
使用COMMIT
一般的SQL语句都是针对数据库表直接执行和编写的。这就是所谓的隐式提交(implicit commit),即提交(写或保存)操作都是自动进行的。但是,在事务处理块中,提交不会隐式进行。(不过有的DBMS也会按隐式提交处理事务端)。进行明确的提交,使用COMMIT语句。
BEGIN TRANSACTION
DELETE OrderItems WHERE order_num = 12345
DELETE Orders WHERE order_num = 12345
COMMIT TRANSACTION
在这个 SQL Server例子中,从系统中完全删除订单12345。因为涉及更
新两个数据库表Orders和OrderItems,所以使用事务处理块来保证订
单不被部分删除。最后的 COMMIT语句仅在不出错时写出更改。如果第
一条DELETE起作用,但第二条失败,则DELETE不会提交。
使用保留点
针对复杂的事务可能会需要部分提交或回退。
要支持回退部分事务,需在事务处理块的合适位置放置placeholder。
-- SQL Server
SAVE TRANSACTION delete1;
...
ROLLBACK TRANSACTION delete1;
-- MariaDB & MySQL & Oracle
SAVEPOINT delete1;
...
ROLLBACK TO delete1;
保留点越多越好。因为保留点越多,就能够越灵活地进行回退。
使用游标
有时需要在SELECT出来的行中前进或后退一行或多行,这就是游标的用途所在。
游标(cursor)是一个存储在DBMS服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序就可以根据需要滚动或浏览其中的数据。
游标对基于 Web的应用(如 ASP、ASP.NET、ColdFusion、PHP、Python、Ruby、JSP等)用处不大。虽然游标在客户端应用和服务器会话期间存在,但这种客户/服务器模式不适合 Web应用,因为应用服务器是数据库客户端而不是最终用户。所以,大多数 Web应用开发人员不使用游标,他们根据自己的需要重新开发相应的功能。
不同的DBMS支持不同的游标选项和属性。常见的一些选项和特性如下:
- 能够标记游标为只读,使数据能读取,但不能更新或删除;
- 能控制可以执行的定向操作(向前、向后、第一、最后、绝对位置、相对位置等)
- 能标记某些列为可编辑的,某些列为不可编辑的;
- 规定范围,使游标对创建它的特定请求(如存储过程)或对所有请求可访问;
- 指示DBMS对检索出的数据(而不是指出表中活动数据)进行复制,是数据在游标打开和访问期间不断变化。
使用游标涉及几个明确的步骤:
- 使用前需声明(定义)游标。
- 一旦声明,就必须打开游标以供使用。
- 对于填有数据的游标,根据需要取出(检索)各行。
- 在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具体的DBMS)
声明游标后,可根据需要频繁地打开和关闭游标。在游标打开时,可根据需要频繁地执行取操作。
创建游标
使用DECLARE语句创建游标。不同DBMS有所不同。
-- DB2、MariaDB、MySQL和 SQL Server版本
DECLARE CustCursor CURSOR
FOR
SELECT * FROM Customers
WHERE cust_email IS NULL
-- Oracle & PostgreSQL
DECLARE CURSOR CustCursor
IS
SELECT * FROM Customers
WHERE cust_email IS NULL
使用游标
使用前需要用OPEN CURSOR语句打开游标。
OPEN CURSOR CustCursor
大部分DBMS中的语法相同。
打开游标后,可以用FETCH语句访问cursor数据了。FETCH指出要检索哪些行,从何处检索他们以及将它们放于何处(如变量名)。
-- 使用Oracle语法从游标中检索一行(第一行)
DECLARE TYPE CustCursor IS REF CURSOR
RETURN Customers%ROWTYPE;
DECLARE CustRecord Customers%ROWTYPE
BEGIN
OPEN CustCursor;
FETCH CustCursor INTO CustRecord; -- 检索当前行(自动从第一行开始),放到声明的变量CustRecord中。对于检索出来的数据不做任何处理。
CLOSE CustCursor;
END;
-- 使用Oracle语法从第一行到最后一行对检索出的数据进行循环
DECLARE TYPE CustCursor IS REF CURSOR
RETURN Customers%ROWTYPE;
DECLARE CustRecord Customers%ROWTYPE
BEGIN
OPEN CustCursor;
LOOP
FETCH CustCursor INTO CustRecord;
EXIT WHEN CustCursor%NOTFOUND;
...
END LOOP;
CLOSE CustCursor;
END;
-- SQL Server语法
-- 为每个检索出来的列声明一个变量
DECLARE @cust_id CHAR(10),
@cust_name CHAR(50),
@cust_address CHAR(50),
@cust_city CHAR(50),
@cust_state CHAR(5),
@cust_zip CHAR(10),
@cust_country CHAR(50),
@cust_contact CHAR(50),
@cust_email CHAR(255)
OPEN CustCursor
-- FETCH语句检索一行并保存值到这些变量中
FETCH NEXT FROM CustCursor
INTO @cust_id, @cust_name, @cust_address,
@cust_city, @cust_state, @cust_zip,
@cust_country, @cust_contact, @cust_email
-- 使用 WHILE 循环处理每一行
WHILE @@FETCH_STATUS = 0 -- 条件:在取不出更多的行时终止处理(退出循环)
BEGIN
FETCH NEXT FROM CustCursor
INTO @cust_id, @cust_name, @cust_address,
@cust_city, @cust_state, @cust_zip,
@cust_country, @cust_contact, @cust_email
END
CLOSE CustCursor
关闭游标
-- DB2, Oracle, PostgreSQL
CLOSE CustCursor
-- SQL Server
CLOSE CustCursor
DEALLOCATE CURSOR CustCursor
高级SQL特性
约束
关系数据库存储分解为多个表的数据,每个表存储相应的数据。利用键来建立从一个表到另一个表的引用。 --> 术语引用完整性(referential integrity)
正确地进行关系数据库设计,需要一种方法保证只在表中插入合法数据。例如,如果 Orders表存储订单信息,OrderItems表存储订单详细内容,应该保证 OrderItems中引用的任何订单 ID都存在于 Orders中。类似地,在 Orders表中引用的任意顾客必须存在于 Customers表中。
所以我们需要一种约束(Constraint)来管理如何插入或处理数据库数据的规则。
DBMS通过在数据库表上施加约束来实施引用完整性。大多数约束是在表定义中定义的。
主键
主键是一种特殊的约束,用来保证一列(或一组列)中的值是唯一的,而且永不改动。换句话说,表中的一列(或多个列)的值唯一标识表中的每一行。
可以作为主键的列需要满足以下条件:
- 任意两行的主键值都不相同;
- 每行都具有一个主键值(列中不允许出现NULL);
- 包含主键值的列从不修改或更新;
- 主键值不能重用。如果从表中删除某一行,其主键值不分配给新行。
定义主键的方法:
-
在创建表的时候指定之:
CREATE TABLE Vendors ( vend_id CHAR(10) NOT NULL PRIMARY KEY, ... ); -
在修改表的时候指定:(SQLite不允许)
ALTER TABLE Vendors ADD CONSTRAINT PRIMARY KEY (vend_id);
外键
外键是表中的一列,其值必须在另一表的主键中。外键是保证引用完整性的极其重要的部分。
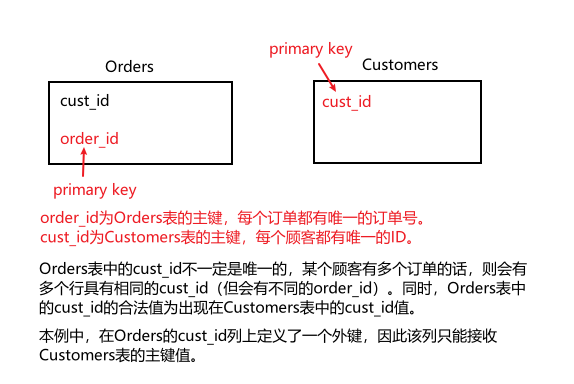
定义外键的方法:
-- 在创建表时定义
CREATE TABLE Orders
(
order_id INTEGER NOT NULL PRIMARY KEY,
order_date DATETIME NOT NULL,
cust_id CHAR(10) NOT NULL REFERENCES Customers(cust_id)
)
-- 在ALTER TABLE中用CONSTRAINT定义
ALTER TABLE Orders
ADD CONSTRAINT
FOREIGN KEY (cust_id) REFERENCES Customers (cust_id)
外键有助于防止意外删除
在定义外键后,DBMS不允许删除在另一个表中具有关联行的行。例如,不能删除关联订单的顾客。删除该顾客的唯一方法是首先删除相关的订单(这表示还要删除相关的订单项)。由于需要一系列的删除,因而利用外键可以防止意外删除数据。
有的 DBMS支持称为级联删除(cascading delete)的特性。如果启用,该特性在从一个表中删除行时删除所有相关的数据。例如,如果启用级联删除并且从Customers表中删除某个顾客,则任何关联的订单行也会被自动删除。
唯一约束
唯一约束用来保证一列(或一组列)中的数据是唯一的。它们类似于主键,但是区别很大:
- 表可以包含多个唯一约束,但只能有一个主键。
- 唯一约束可以包含NULL值。
- 唯一约束可修改或更新。
- 唯一约束列的值可以重复使用。
- 唯一约束不能用来定义外键。
唯一约束可以用UNIQUE关键字在表定义中定义,也可以用单独的CONSTRAINT定义。
检查约束
检查约束用来保证一列(或一组列)的数据满足一组指定的条件。如:
- 检查最小或最大值。例如,防止0个物品的订单。
- 指定范围。例如,保证发货日期大于等于今天的日期,但不超过今天起一年后的日期。
- 只允许特定的值。例如,在性别字段中只允许M或F。
CREATE TABLE OrderItems
(
...
quantity INTEGER NOT NULL CHECK (quantity > 0),
...
)
ADD CONSTRAINT CHECK (gender LIKE '[MF]')
索引
索引用来排序数据以加快搜索和排序操作的速度。假如我们有一本书,现在我们想在这本书中找到所有的“数据类型”这个词。简单的办法就是从第一页开始一页一页地找,但是这样效率很低。如果这本书提供一个“索引”,我们通过查找索引知道了“数据类型”这个词出现在这本书的第几页,然后直接翻到这些记录好的页码中就可以找到“数据类型”这个词。
数据库索引的作用也一样。主键数据总是排序的(DBMS makes it)。因此,按主键检索特定的行总是一个快速有效的方法。但是我们搜索其它的列,效率可能就不高了。比如我们想搜索住在某个州的客户,怎么办?表的数据没有按州排列,我们就得读出表中所有的行,看是不是匹配。如果我们使用索引,可以在一个或多个列上定义索引,使DBMS保存其内容的一个排序过的列表。定义索引后,DBMS搜索排序过的索引,找出匹配位置,然后检索这些行。
索引的注意事项:
- 索引改善了检索操作的性能,但降低了数据增删改的性能。在执行这些操作时,DBMS必须动态地更新索引。
- 索引数据可能要占用大量的存储空间。
- 并非所有的数据都适合做索引。取值不多的数据(如州)不如具有更多可能值的数据(如姓或名),能够通过索引得到那么多好处。
- 索引用于数据过滤和数据排序。
CREATE INDEX prod_name_ind
ON Products (prod_name);
触发器
触发器是特殊的存储过程,在特定的数据库活动发生时自动执行。触发器可以和特定表上的INSERT、UPDATE和DELETE操作(或组合)相关联。
触发器与单个的表相关联。与Orders表上的INSERT操作相关联的触发器只在Orders表插入行的时候执行。
触发器的常见用途:
- 保证数据一致。例如在
INSERT或UPDATE操作中将所有的州名转换为大写。 - 基于某个表的变动在其他表上执行活动。例如,每当更新或删除一行时将审计跟踪记录写入某个日志表。
- 进行额外的验证并根据需要回退数据。例如,保证某个顾客的可用资金不超限定,如果已经超出,则阻塞插入。
- 计算计算列的值或更新时间戳。
创建触发器:
-- SQL Server
CREATE TRIGGER customer_state
ON Customers
FOR INSERT, UPDATE
AS
UPDATE Customers
SET cust_state = Upper(cust_state)
WHERE Customers.cust_id = inserted.cust_id;
-- Oracle, PostgreSQL
CREATE TRIGGER customer_state
AFTER INSERT OR UPDATE
FOR EACH ROW
BEGIN
UPDATE Customers
SET cust_state = Upper(cust_state)
WHERE Customers.cust_id = :OLD.cust_id
END;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号