RF/GBDT/XGBoost/LightGBM简单总结(完结)
这四种都是非常流行的集成学习(Ensemble Learning)方式,在本文简单总结一下它们的原理和使用方法.
Random Forest(随机森林):
- 随机森林属于Bagging,也就是有放回抽样,多数表决或简单平均.Bagging之间的基学习器是并列生成的.RF就是以决策树为基学习器的Bagging,进一步在决策树的训练过程中引入了随机特征选择,这会使单棵树的偏差增加,但总体而言有利于集成.RF的每个基学习器只使用了训练集中约63.2%的样本,剩下的样本可以用作袋外估计.
- 一般使用的是sklearn.ensemble中的RandomForestClassifier和RandomForestRegressor.
- 框架参数(相比GBDT较少,因为基学习器之间没有依赖关系):
- n_estimators=100:最大的基学习器的个数
- oob_score=False:是否采用袋外样本
- bootstrap=True:是否有放回采样
- n_jobs=1:并行job个数
- 决策树参数:
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
- criterion:CART树划分时对特征的评价标准,分类树默认gini,可选entropy,回归树默认mse,可选mae.
GBDT(梯度提升树)
- GBDT属于Boosting.它和Bagging都使用同样类型的分类器,区别是不同分类器通过串行训练获得,通过关注被已有分类器错分的数据来获得新的分类器.Boosting分类器的权重并不相等,每个权重对应分类器在上一轮迭代中的成功度.GBDT的关键是利用损失函数的负梯度方向作为残差的近似值,进而拟合出新的CART回归树.
- 一般使用的是sklearn.ensemble中的GradientBoostingClassifier和GradientBoostingRegressor.
- 框架参数:
- n_estimators=100:最大基学习器个数
- learning_rate=1:每个基学习器的权重缩减系数(步长)
- subsample=1.0:子采样,是不放回抽样,推荐值0.5~0.8
- loss:损失函数,分类模型默认deviance,可选exponential.回归模型默认ls,可选lad,huber和quantile.
- 决策树参数(与RF基本相同):
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
XGBoost
- 相比传统GBDT,XGBoost能自动利用CPU的多线程,支持线性分类器,使用二阶导数进行优化,在代价函数中加入了正则项,可以自动处理缺失值,支持并行(在特征粒度上的).
- 参考XGBoost python API和xgboost调参经验.
- 在训练过程一般用xgboost.train(),参数有:
- params:一个字典,训练参数的列表,形式是 {‘booster’:’gbtree’,’eta’:0.1}
- dtrain:训练数据
- num_boost_round:提升迭代的次数
- evals:用于对训练过程中进行评估列表中的元素
- obj:自定义目的函数
- feval:自定义评估函数
- maxmize:是否对评估函数最大化
- early_stopping_rounds:早停次数
- learning_rates:每一次提升的学习率的列表
- params参数:
- booster=gbtree:使用哪种基学习器,可选gbtree,gblinear或dart
- objective:目标函数,回归一般是reglinear,reg:logistic,count:poisson,分类一般是binary:logistic,rank:pairwise
- eta:更新中减少的步长
- max_depth:最大深度
- subsample:随即采样的比例
- min_child_weight:最小叶子节点样本权重和
- colsample_bytree:随即采样的列数的占比
- gamma:分裂最小loss,只有损失函数下降超过这个值节点才会分裂
- lambda:L2正则化的权重
LightGBM
- LightGBM是基于决策树的分布式梯度提升框架.它与XGBoost的区别是:
- 切分算法,XGBoost使用pre_sorted,LightGBM采用histogram.
- 决策树生长策略:XGBoost使用带深度限制的level-wise,一次分裂同一层的叶子.LightGBM采用leaf-wise,每次从当前所有叶子找到一个分裂增益最大的叶子.
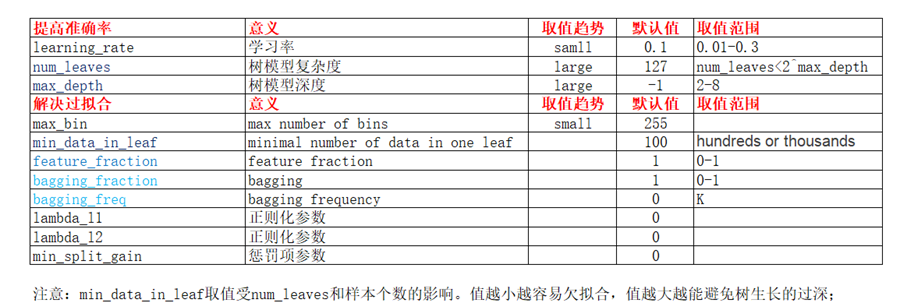
此外还有objective,metric等参数.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号