
Hadoop/Spark入门学习笔记(完结)
Hadoop基础及演练
---第1章 初识大数据
- 大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术.
---第2章 Hadoop核心HDFS
- Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案,Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算)
- 存储是大数据技术的基础,分布式计算是大数据应用的解决方案
- HDFS基础架构:
- 数据块:是抽象块,一般设置为128MB,备份3个.
- NameNode:主数据块,管理文件系统的命名空间,存放文件元数据,维护文件系统的所有文件和目录,文件与数据块的映射,记录每个文件各个块所在数据节点的信息
- DataNode:从数据块,存储并检索数据块,向NameNode更新所存储块的列表
- HDFS优点:
- 适合大文件存储,并有副本策略
- 可以构建在廉价的机器上,并有一定的容错和恢复机制
- 支持流式数据访问,一次写入,多次读取最高效
- HDFS缺点:
- 不适合大量小文件存储
- 不适合并发写入,不支持文件随机修改
- 不支持随机读等低延时的访问方式
- 数据块的大小多少合适:64MB或128MB,太小会增加硬盘寻道时间,太大会影响MapReduce
- NameNode如果挂了怎么办:设置备用节点,失效后自动激活
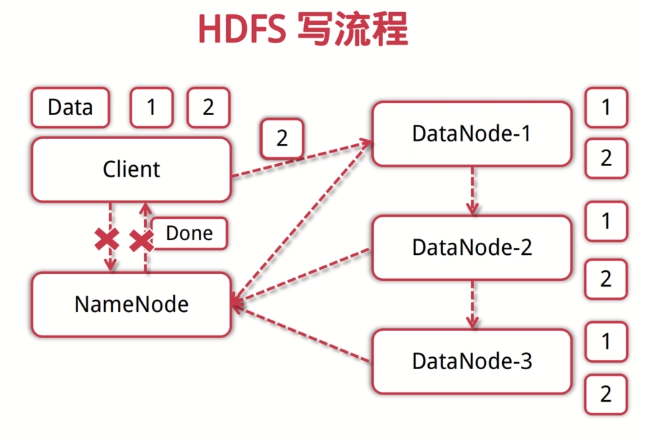
- HDFS写流程:
- 客户端向NameNode发起写数据请求
- 分块写入DataNode节点,DataNode自动完成副本备份
- DataNode向NameNode汇报存储完成,NameNode通知客户端
- HDFS读流程:
- 客户端向NameNode发起读数据请求
- NameNode找出距离最近的DataNode节点信息
- 客户端从DataNode分块下载文件

- 常用HDFS Shell命令:
- 类Linux系统:ls,cat,mkdir,rm,chmod,chown等
- HDFS文件交互:copyFromLocal,copyToLocal,get,put
- 上传文件:hdfs dfs -copyFromLocal 目标文件 目标路径
- 下载文件:hdfs dfs -copyToLocal 源文件 目标文件
- python的hdfs3库可以用python进行文件的写入和读取


from hdfs3 import HDFileSystem test_host = 'localhost' test_port = 9000 def hdfs_exists(hdfs_client): path = '/tmp/test' if hdfs_client.exists(path): hdfs_client.rm(path) hdfs_client.makedirs(path) def hdfs_write_read(hdfs_client): data = b'hello hadoop' * 20 file_a = 'tmp/test/file_a' with hdfs_client.open(file_a, 'wb', replication=1) as f: f.write(data) with hdfs_client.open(file_a, 'rb') as f: out = f.read(len(data)) assert out == data def hdfs_readlines(hdfs_client): file_b = '/tmp/test/file_b' with hdfs_client.open(file_b, 'wb', replication=1) as f: f.write(b'hello\nhadoop') with hdfs_client.open(file_b, 'rb') as f: lines = f.readlines() assert len(lines) == 2 if __name__ == '__main__': #创建客户端 hdfs_client = HDFileSystem(host=test_host, port=test_port) hdfs_exists(hdfs_client) hdfs_write_read(hdfs_client) hdfs_readlines(hdfs_client) hdfs_client.disconnect() print('-' * 20) print('hello hadoop')
---第3章 Hadoop核心MapReduce
- YARN:资源管理器,负责集群资源的管理和调度.
- ResourceManager:分配和调度资源,启动并监控ApplicationMaster,监控NodeManager
- ApplicationMaster:为MR类型的程序申请资源并分配给内部任务,负责数据切分,监控任务的执行及容错
- NodeManager:管理单个节点的资源,处理来自ResourceManager和ApplicationMaster的命令
- MapReduce(MR)是一种编程模型和方法:
- split:输入一个大文件,将其分片
- map:每个分片由单独的机器处理
- reduce:将各个机器计算的结果进行汇总并得到最终结果
import sys def read_input(file): for line in file: yield line.split() def main(): data = read_input(sys.stdin) for words in data: for word in words: print("%s%s%d"%(word, '\t', 1)) if __name__ == '__main__': main()
import sys from operator import itemgetter from itertools import groupby def read_mapper_output(file, separator='\t'): for line in file: yield line.rstrip().split(separator, 1) def main(): data = read_mapper_output(sys.stdin) for current_word, group in groupby(data, itemgetter(0)): total_count = sum(int(count) for current_word, count in group) print("%s%s%d"%(current_word, '\t', total_count)) if __name__ == '__main__': main()
---第4章 Hadoop生态圈介绍
- 如何通过Hadoop存储小文件:可以利用HDFS将小文件合并为大文件,或者利用某种方式对文件进行分组(Hadoop Archives,SequenceFile,HBase)
- 当有节点故障时,集群如何继续提供服务:NameNode会让其他DataNode从现有副本复制这些数据块.如果又恢复正常,则随机选择要删除的副本
- 哪些是影响MapReduce性能的因素:算法,硬件,底层存储系统,输入数据的大小
- HBase是一个分布式数据库.利用HDFS作为文件存储系统,支持MR程序读取数据.可以存储非结构化和半结构化数据.核心概念是RowKey(数据唯一标识,按字典排序),Column Family(列族,多个列的集合,不能超过3个),TimeStamp(时间戳,支持多版本数据同时存在).
- Spark是一个基于内存计算的大数据并行计算框架.是MapReduce的替代方案,兼容HDFS,HIVE等数据源.优势是抽象出分布式内存存储数据结构(弹性分布式数据集RDD),基于事件驱动,通过线程池复用线程提高性能.
Hadoop进阶
---第1章 概述
- 大数据可以用于精准营销,用户画像,商品推荐等功能的实现.
- 一个NameNode对应多个DataNode.所有DataNode定期向NameNode发送心跳,如果NameNode没有收到就认为该DataNode已经挂掉,会将数据发送到其他节点.还有一个Secondary NameNode用于备份NameNode.
- Hadoop2.0移除了JobTracker和TaskTracker,该由Yarn负责集群中所有资源的管理和分配,NodeManager管理单个计算节点.
---第2章 深入探索MapReduce过程
- 以WordCount为例的MapReduce:
- Split:将多个文本分为不同的分片
- Map:以<key,value>形式输入,其中key是行号,value是文本,利用map将其拆分,key为单词,value为1(代表该单词出现一次).
- Shuffle:以map的输出作为输入,将相同的单词归到一起,但不进行次数累加.
- Reduce:以shuffle的输出作为输入,对单词次数进行累加求和,输出key为单词,value为次数.
- 输入文件保存在DataNode的block(数据块)中,每一个文件都会增加分片数量,并映射在NameNode中,而NameNode内存有限,所以HDFS适合存放大文件.
- 节点Map任务的个数可以通过增大mapred.map.tasks来增加,也可以通过增大mapred.min.split.size或合并小文件来减少.
- Combine是指本地优化,在本地先按照key进行一轮排序和合并,在进行网络混洗.在多数情况下Combine的逻辑和Reduce的逻辑是一致的,可以认为Combine是对本地数据的Reduce.
- map先将文件放入内存缓冲区,然后将其中的小文件合并为大文件,进行网络传输.key值相同的文件会进行partition(合并),再进行reduce.
- 一个MapReduce中,以下三者的数量总是相等的:partitioner的数量,redue任务的数量,最终输出文件.
- 在数据量大的情况下,应该将reduce任务数设为较大值.可以通过调节参数mapred.reduce.tasks和job.setNumReduceTasks(int n)方法进行设置
---第3章 Hadoop的分布式缓存
- 在执行MapReduce时,Mapper之间需要共享信息,如果信息量不大,可以将其从HDFS加载到内存中,这就是Hadoop分布式缓存机制(DistributedCache).如果共享数据太大,可以将共享数据分批缓存,重复执行作业.
- MapReduce进行矩阵相乘:
- 将右侧矩阵转置
- 将右矩阵载入分布式缓存
- 将左矩阵的行作为Map输入
- 在Map执行之前将缓存的右矩阵以行为单位放入List
- 在Map计算时从List中取出所有行分别与输入行相乘
---第4章 推荐算法
- 有余弦相似度,切比雪夫距离,欧氏距离,皮尔森系数等描述向量相似程度的度量方法
- 基于物品的推荐算法(ItemCF):
- 用户行为与权重(点击,搜索,收藏,付款)
- 算法思想是给用户推荐那些和他们之前喜欢的物品相似的物品
- 根据用户行为列表计算用户,物品的评分矩阵
- 根据评分矩阵计算物品的相似度矩阵
- 相似度矩阵*评分矩阵=推荐列表
- 在推荐列表中将用户产生过行为的物品置0
- 基于用户的推荐算法(UserCF):
- 根据用户行为列表计算物品,用户的评分矩阵.
- 根据评分矩阵计算用户的相似度矩阵.
- 相似度矩阵*评分矩阵=推荐列表
- 在推荐列表中将用户产生过行为的物品置0
- 基于内容的推荐算法:
- 给用户推荐和他们之前喜欢的物品在内容上相似的其他物品
- 物品特征建模
- 构建Item Profile矩阵(0,1矩阵)
- 构建Item User评分矩阵
- 将两个矩阵相乘得到User Profile矩阵.表示用户对特征的兴趣权重.
- 对Item Profile和User Profile求余弦相似度
- 在推荐列表中将用户产生过行为的物品置0
Spark从零开始
---第1章 Spark介绍
- Spark是一个快速(扩充了流行的MapReduce计算模型,基于内存计算)且通用(容纳了其他分布式系统拥有的功能)的集群计算平台.
- Spark的组件:
- Spark Core:包含Spark的基本功能,比如任务调度,内存管理,容错机制.定义了RDD(弹性分布式数据集),提供了API来创建和操作RDD.
- Spark SQL:处理结构化数据的库.
- Spark Streaming:实时数据流组件.
- Mlib:包含通用机器学习功能的包.
- Graphx:处理图的库,并进行图的并行计算.
- Cluster Managers:集群管理.
- 相比Hadoop,Spark可以用于时效性要求高的场景和机器学习等领域.
---第2章 Spark的下载和安装
- Spark是Scala写的,运行在JVM上.
- Spark的shell能够处理分布在集群上的数据,把数据加载到节点的内存中.分为Python shells和Scala shells.
---第3章 开发第一个Spark程序
- WordCount:
- 创建一个Spark Context
- 加载数据
- 把每一行分割成单词
- 转换成pairs并且计数
- 打包程序-启动集群-提交任务-执行任务
---第4章 RDDs
-
Driver program包含程序main方法,RDDs的定义和操作.它管理很多executors(节点).
-
通过SparkContext访问Spark,它代表和一个集群的连接.在Shell中是自动创建好的.
- RDDs是弹性分布式数据集的简写.它们并行分布在整个集群中.不管整个数据集被切分成几块,都可以用它来访问整个数据集.一个RDD是一个不可改变的分布式集合对象.所有计算都是通过RDDs的创建,转换,操作完成的.一个RDD内部由很多partitions(分片)构成,每个分片包括一部分数据,是Spark并行处理的单元.RDD的创建可以用parelleilzie()或加载外部数据集.
- RDD基本操作:
- Transformations指的是从之前的RDD构建一个新RDD的过程.如map(接收函数,把函数应用到RDD,返回新RDD),filter(接收函数,返回只包含满足filter函数的元素的RDD),flatMap(对每个输入元素,输出多个输出元素).
- RDD支持数学集合计算,如并集,交集.
- Action是在RDD上计算出一个结果,把结果返回给driver program或保存在文件系统.如reduce(接收一个函数,作用在RDD两个类型相同的元素上,返回新元素),collect(遍历整个RDD,返回RDD的内容,注意内容需要单机内存能够容纳下),take(返回RDD的n个元素,返回结果无序),top(返回排序后的topN值),foreach(计算RDD中的每个元素,但不返回到本地).
- Spark维护着RDDs之间的依赖关系和创建关系,叫做血统关系图,可以用于计算RDD的需求和恢复丢失数据.
- 延迟计算:Spark对RDD的计算是在第一次使用action操作的时候.这可以减少数据的传输.
- 使用map()函数可以创建KeyValue对RDDs.KeyValue对RDDs的Transformations操作有reduceByKey(把相同key的结合),groupByKey(把相同的key的values分组),mapValues(对value进行map操作).
- combineByKey是最常用的基于key的聚合函数,接收四个参数.返回类型可以与输入类型不一样.它遍历元素的key,如果是新元素就使用createCombiner函数,如果已存在就使用mergeValue函数.合计每个分片结果的时候使用mergeCombiners函数.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号