VQA背景概括(简介、方法、数据集)
本文为论文《Visual Question Answering: A Survey of Methods and Datasets》的阅读笔记,论文是17年的,所以暂时不包括近三年的进展,后续学习过程中将逐渐更新。
Abstract
VQA是一项结合了CV和NLP的任务,给定一张图片和一个问题,它的目标是从图片的视觉信息中推理出问题的正确答案。
本文总结了VQA领域的方法、数据集以及评估方式。
Introduction
VQA和其他CV任务的区别是,它回答的问题直到run time才确定,因此它更接近general image understainding。
VQA比image caption更复杂,因为它往往需要图像以外的信息。另外VQA的答案往往更简短,因此也更容易和ground truth比较。
VQA的难点在于图像是高维信息,缺少语法规则和结构,也不能直接使用句法分析、正则表达式等NLP方法。此外,图像捕捉到的信息更接近现实世界,而语言本身就是一种抽象。
Methods
---Joint embedding
joint embedding的目的是在common space中学习到CV和NLP任务的representation。它是大多数VQA 方法的基础。
所使用的image representations一般是在object recognition上预训练的CNN,text representations一般是在large text corpora上预训练word embedding,然后将问题中words的embedding送入到RNN中,用于解决变长序列。
Neural-Image-QA:Question和image features被一起送入encoder LSTM,生成一个固定长度的vector后进入decoder LSTM,每次迭代生成一个word,这个word会被传入到下一个recurrent中直到end symbol出现。
DPPnet:CNN with a dynamic parameter layer,weights由question决定。为了得到adaptive parameter,引入了一个GRUs组成的独立的parameter prediction network,输入question,输出candidate weights。
MCB:Multimodal Compact Bilinear pooling,将image和text features随机投影到高维空间,然后在傅立叶空间进行卷积。
---Attention mechanisms
上述方法大多使用global features来表示visual input,会引入不相关的信息,attention机制使用local features,并允许模型在不同regions给予不同weights。在VQA中即专注于与question相关的regions。
《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》是attention机制在visual tasks中的一个早期应用。
QAM:Question-guided Attention Map,通过卷积核在spatial image feature map中搜索与question语义相关的visual features。卷积核是将question embeddings转换到visual space得到的。
SAN:Stacked Attention Networks
Attention技术提高了所有datasets上的表现,但是在binary questions上没有带来显著提高。一种假设是是非型问题需要更长的推理链,而开放型问题往往只需要关注图片的某一方面。
---Compositional models
这种方法是思路是构建模块化的网络,每个模块对应着某种具体的功能。
NMN:Neural Module Networks,专门为VQA设计,可以利用question的语言结构。NMN会根据不同的question实时地计算出复杂度,然后用textual QA相关的策略,利用语义分析将question转化为逻辑表达式。对question的分析使用的是Standford dependency parser。NMN对于复合结构的问题表现很好,但是在简单问题上表现不佳,它的parsing模块限制了网络结构和纠错的可能。

DMN:Dynamic Memory Networks,主要由4部分组成。Input module将数据转换为vector,称为facts,根据input类型决定具体实现;Question module使用GRU将question转换为vector;Episodic memory module检索出用于回答question的facts;Answer module使用memory的final state来给出答案。
---Knowledge base enhanced approaches
VQA通常需要先验知识,例如“图中有几只哺乳动物“,因此joint embedding存在缺陷:只能获取训练集中已有的知识,不可能覆盖真实世界的所有情况。因此一个解决方案是将推理过程与知识库结合起来。
Ahab:使用最大的结构知识库之一DBpedia,先用CNN提取图片中的信息,然后将它们与DBpedia中类似的概念节点联系起来,并学习从images/questions到知识图中的queries的一个mapping,最终的答案根据query总结得到。
FVQA:改进了Ahab,使用LSTM和data-driven approach学习mapping,并使用两个额外的数据库,ConceptNet和WebChild。
ACK:首先用CNN从image中提取语义属性,然后从DBpedia中检索相关的知识,利用Doc2Vec转换为定长vectors。LSTM会接收这些模型,并interprets with question,最后得到答案。
Datasets and evaluation
VQA的data至少为一个image、question、answer的三元组。
DAQUAR:First VQA dataset designed as benchmark,DAtaset for QUestion Answering on Real-world images。1449 RGBD images,795 training,654 testing。有2种问答pairs,一种是使用8种模板合成的,一种是人工标注的。共有12468个问题,6794 training,5674 testing。

COCO-QA:123287 images,72783 training,38948 testing。每个image有一个问答pair,由COCO dataset中的image descriptions转换而来

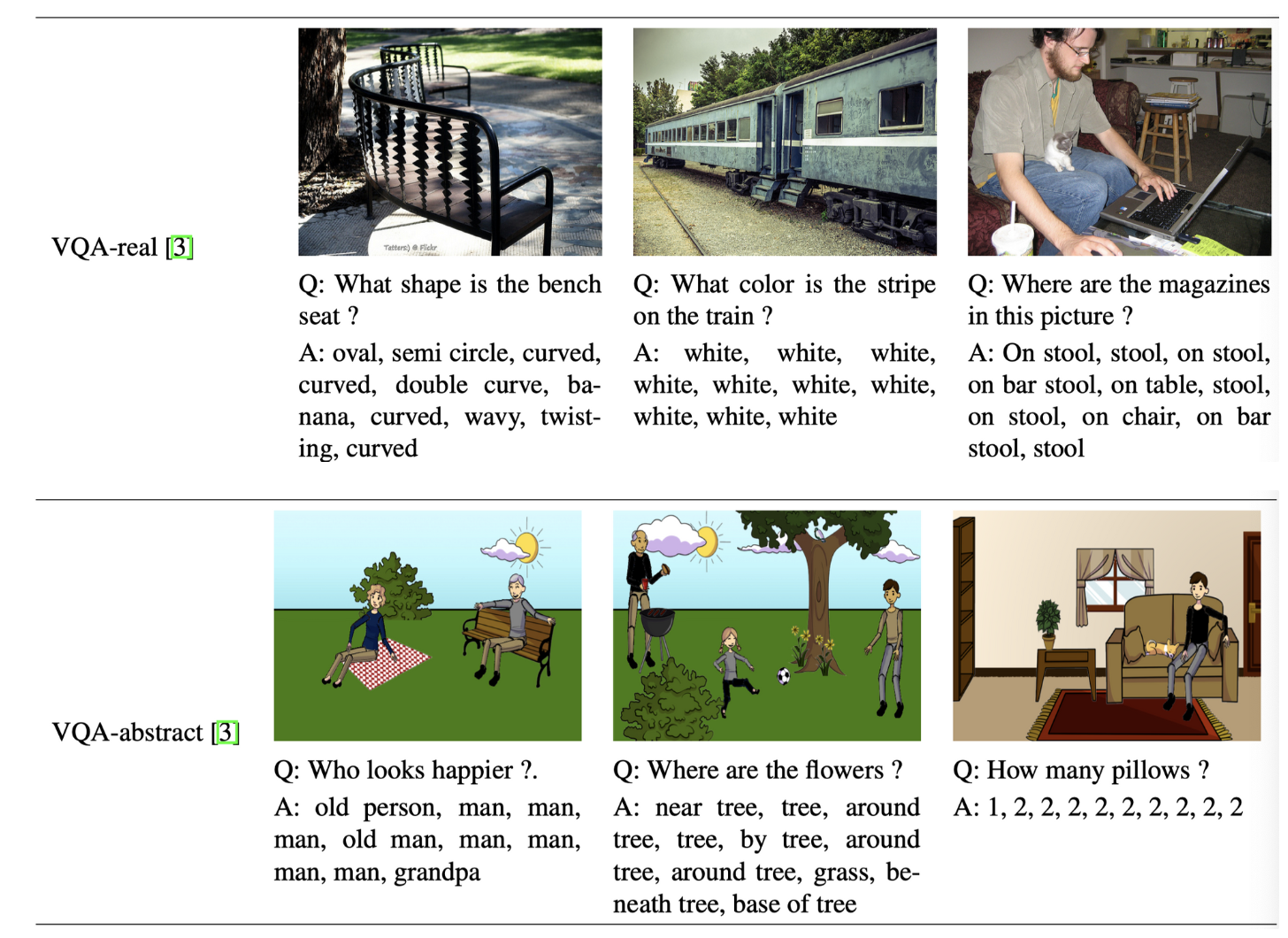
VQA:使用最广泛的数据集之一,2017年更新为VQA v2.0,包含使用真实图片的VQA-real和卡通图片的VQA-abstract。VQA-real包含123287 training和81424 test images from COCO,由真人提供开放型和是非型问题和多种候选答案,共614163个questions。VQA-abstract包括50000scenes,每个scene对应3个questions
Visual Genome:1.7 million questions/answer pairs,问题包括free-form和region-based两种形式,比VQA-real更具多样性。

Visual7W:Visual Genome的一个子集。
Other datasets:使用外部知识库的KB-VQA、FVQA,较简单的Diagrams、Shapes。
Evaluation Measures
为了对answer进行评估,句法和语义的正确性都需要考虑,因此大多数VQA datasets的answer被限制为3个words以下。
WUPS:Wu-Palmer Similarity,在taxonomy tree中比较两者的common subsequence,当similarity超过某一阈值就认为是正确答案,一般使用0.9和0.0两种阈值。
在VQA数据集中,只有当3个以上的人(共10个)提供了该答案,才认为给出的答案是正确的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号