VQA视觉问答基础知识
本文记录简单了解VQA的过程,目的是以此学习图像和文本的特征预处理、嵌入以及如何设计分类loss等等.
参考资料:
https://zhuanlan.zhihu.com/p/40704719
https://www.youtube.com/watch?v=ElZADFTer4I
https://www.youtube.com/watch?v=cgOmpgcELPQ https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/
https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/
VQA定义:
给定一张图像和一个相关文字问题,从若干候选文字回答中选出正确答案.
常用策略是CNN提取图像特征,RNN提取文本特征,将图像特征和文本特征进行融合,然后通过全连接层进行分类.关键在于如何融合这两个模态.
Visual Question Answering (VQA) by Devi Parikh
Why Words and Pictures?
-
Applications.应用场景很广.
-
Measuring and demonstrating AI capabilities.通过对image和language的理解,衡量并展现AI的能力.
-
Beyond “bucket” recognition.跳出通常的对于AI任务的分类.
Image captions即为图片加上文字描述,可能存在的问题是,文字描述太过通用,无法详细地描绘出图像中的细节.
构建VQA:
-
创建数据集,包括coco数据集中的254721张图片、50000张卡通,从Amazon Mechanical Turk为每张图片收集3个问题,每个问题收集10个回答.
-
38%的问题是binary yes/no, 99%的问题有着<=3个单词的答案.这使得评估变得可行.
-
Input: image和question Output: answer.
-
Image用CNN, Question用RNN和LSTM, 输出是1 of K个最可能的答案.
What such a model can‘t do?
-
例如“pizza box中剩下了几片菜叶子“的问题.因为该模型不具有计数的功能,
Introduction to Visual Question Answering: Datasets, Approaches and Evaluation
A multi-discipline problem:
-
VQA是跨学科的,至少需要NLP、CV、Knowledge Representation & Resoning等知识.
Available datasets:
-
好的datasets结合恰当的评估方法是解决许多问题的关键.
-
VQA非常复杂,因此一个好的dataset要足够大,能包含尽可能多种类的图片和问题.许多datasets从COCO(Microsoft Common Objects in Context)数据集中获取图片.
-
COCO数据集大大简化和加速了VQA dataset的构建过程,但仍存在问题.例如收集广泛的、恰当的、没有歧义的probelm,以及可能被利用的biases.
-
The DAQUAR dataset是第一个重要的VQA dataset.全称是DAtaset for QUestion Answering on Real-world images.它的图片基于NYU-Depth V2 Dataset, 包含6974个training问答和5674个testing问答.它的缺点是只包含了室内图像,并且光照条件使得很难回答问题.
-
The COCO-QA dataset包含123287张图片, 78736个training问答和38948testing问答.值得注意的是它的所有答案都是一个单词.缺点是由于问题是由nlp生成的,因此存在一些奇怪的内容,并且只包含目标、颜色、计数和定位的问题.
-
The VQA dataset包含204721张COCO中的图片和50000张卡通图片.每个图片对应3个问题,每个问题对应10个答案.
Current Approaches:
-
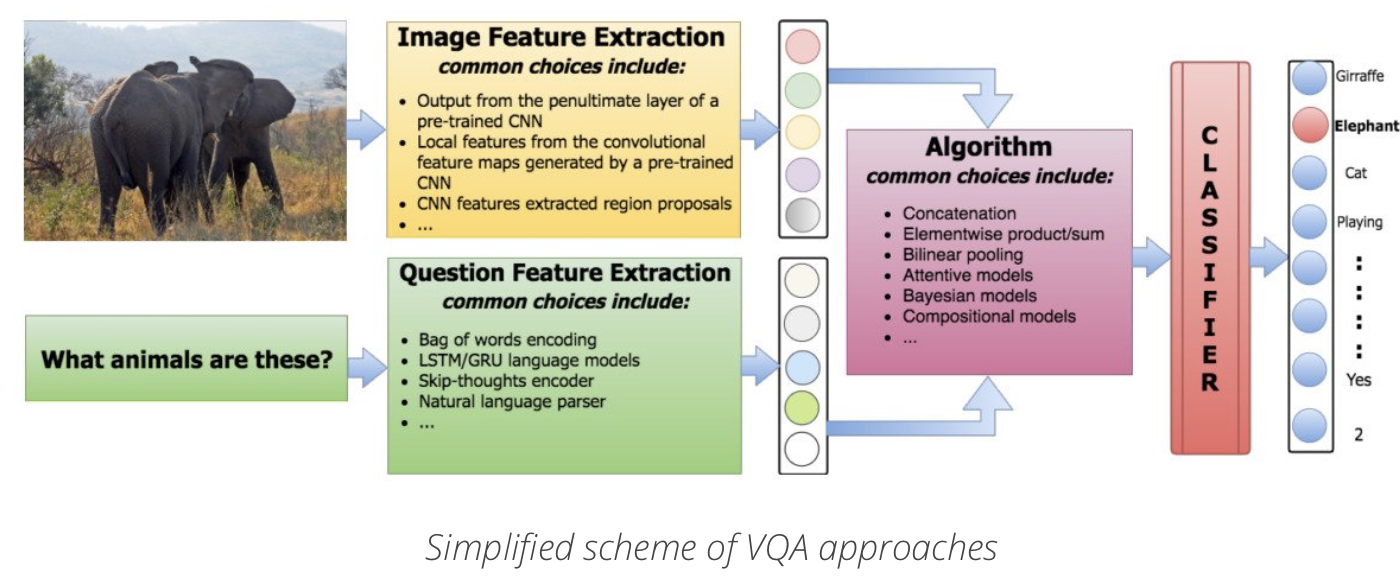
VQA所需要的方法大致是:从问题中抽取特征、从图片中抽取特征、将两种特征结合来生成答案.
-
对于text features,有BoW, LSTM encoders等方法.
-
对于image features, 有pre-trained CNNs on ImageNet是最常用的.对于Answer, 模型一般会将问题视作一个分类任务.
-
不同方法的主要区别就是如何结合textual and image features.
-
一个不好的baseline很可能会给出最频繁出现的答案,或者是随机挑选答案.因此baseline的设计很关键.比较常用的方法是训练一个线性分类器或是网络,将features作为input.
-
Attention-based approaches是让算法专注于最相关的部分.例如“What color is the ball”的关键词就是“color”和“ball”,图像也会认为ball是最重要的一块区域.应用在VQA中,一般会使用spatial attention来生成区域特定特征,用于训练CNN.
-
Bayesian approaches的思想是对于问题和图像特征中同时出现的数据进行建模,作为一种推理关系的方式.
Evaluation metrics:
-
传统的classic accuracy对于有选项的回答系统不错,但是对于开放式回答系统起不到作用.
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号