【2020/1/18】寒假自学——学习进度报告4
上次是安装完成了,这次就来试试Spark的基本操作。
首先是运行Spark自带的实例SparkPi。
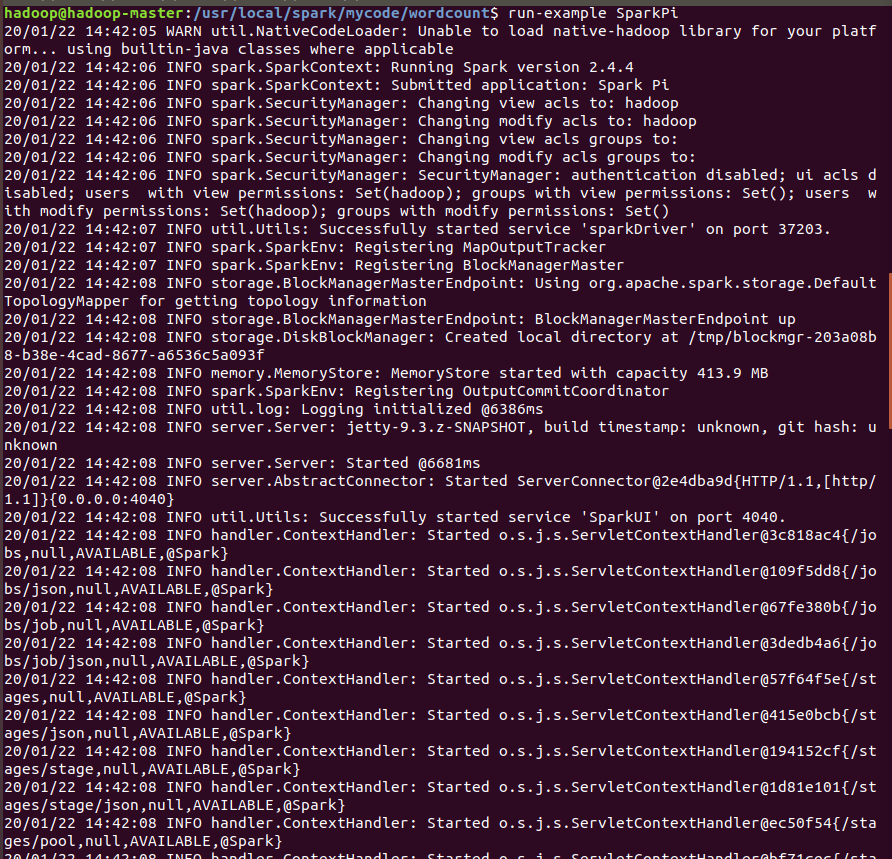
在配置好环境变量的时候可以直接运行,但可以看到虽然运行成功但信息太过复杂,所以检索之后——

虽然计算结果有所偏差,但多少能证明Spark的计算能力可以使用。
第二个运行的就是和计算能力没太大关联的WordCount。

创造好需要的文件(文件内存入了空格隔离的几个单词)。
启动pyspark,其以交互的方式使用Python编写Spark程序。
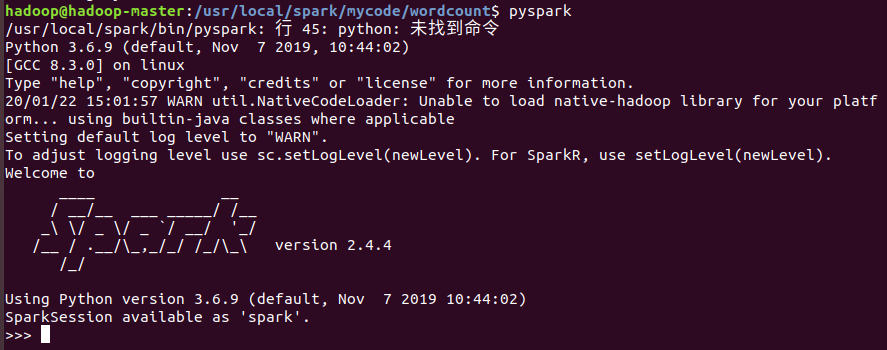
可以看到启动界面如此。
但也有会遇到——

的情况,这就是需要把环境配置到Spark自带的python中。下面记录解决方法——
添加python相关环境变量
文件末尾添加如下语句export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
注意:py4j-0.10.7-src.zip要到$SPARK_HOME/python/lib目录查看是否是这个名称。不同版本的py4j的名称会有差别
$ nano ~/.bashrc
保存后,让环境变量生效
$ source ~/.bashrc————————————————
原文链接:https://blog.csdn.net/qq_42881421/article/details/88069211
如此就可以运行,虽然第一行还是显示python未找到命令。
顺带一提,此时可以在虚拟机和实机里面访问网址ip:4040。
词频统计运行结果——

第三个准备尝试集群化的操作。
首先确认启动集群(但因为没有slave机,所以还是伪集群,但操作无关紧要)。
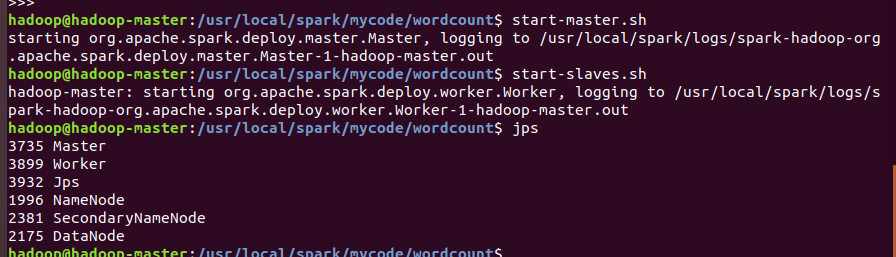
确认Master、Worker的启动。
集群操作一:运行应用程序JAR包
向独立集群管理器提交应用,需要把spark://ip:7077(7077似乎是默认端口)作为主节点参数递给spark-submit。(值得一提的是如果是想向yarn提交应用可以修改参数)
同样很杂,检索后——

可以看到精度还提升不少,可喜可贺。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号