特征转换之python代码
一、连续型变量
1.1 连续变量无量纲化
(1)无量纲化: 使不同规格尺度的数据转化统一规格尺度(将数据单位统一)
(2)无量纲化方法:标准化, 区间所方法
标准化: 将连续性变量转变为 均值0 标准差1 的变量

代码: #对 Amount字段--均值为0,方差为1标准化
from sklearn import preprocessing
std = preprocessing.StandardScaler() #StandardScaler
Amount = RFM['Amount'].values.reshape(-1,1)
std.fit(Amount)
RFM['Amount_std'] = std.transform(Amount)
RFM.head(5)
区间缩放法:把原始的连续型变量转换为范围在[a,b]或者 [0,1] 之间的变量
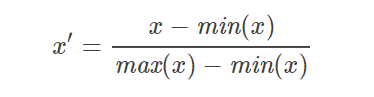
代码: #对 Amount字段--[0,1]区间归一化
from sklearn import preprocessing
MinMaxscaler = preprocessing.MinMaxscaler() #MinMaxscaler
Amount = RFM['Amount'].values.reshape(-1,1)
MinMaxscaler.fit(Amount) #拟合(训练)
RFM['Amount_range'] = MinMaxscaler.transform(Amount)
RFM.head(5)
1.2 连续变量数据变换
数据变换:通过函数变换改变原始数据的分布 目 的: 数据从无关系 -> 有关系 呈偏态分布-->变换后差异拉开 让数据符合模型理论所需要的假设,然后对其分析,例如:变换后数据呈正态分布x′=ln(x)
数据变化方法:logX,Ine等 对数函数变换 <span id="MathJax-Span-97" class="mrow"><span id="MathJax-Span-98" class="msup"><span id="MathJax-Span-99" class="texatom"><span id="MathJax-Span-100" class="mrow"><span id="MathJax-Span-101" class="mi">x<span id="MathJax-Span-102" class="mo">′<span id="MathJax-Span-103" class="mo">=<span id="MathJax-Span-104" class="mi">l<span id="MathJax-Span-105" class="mi">n<span id="MathJax-Span-106" class="mo">(<span id="MathJax-Span-107" class="mi">x<span id="MathJax-Span-108" class="mo">)box-cox变换 :自动寻找最佳正态分布变换函数的方法

代码1: #对 Amount字段--log 变换
import numpy as np
RFM['Amount_log'] = np.log(RFM['Amount'])
RFM,head(5)
代码2: #对 Amount字段--sqrt (平方根) 变换
import numpy as np
RFM['Amount_sqrt'] = np.sqrt(RFM['Amount'])
RFM,head(5)
1.3 连续变量离散化
目的:方便探索数据相关性
减少异常数据对模型的干扰
为模型引入非线性,提升模型预测能力
离散后,可进行特征交叉组合,又M+N 变成 M*N
数据离散化方法:
非监督离散方法:
自定义规则,
等宽方法,
等频/等深方法
非监督离散方法:
#对 Amount字段--自定义区间 离散化
cut_points = [0,200,500,800,1000]
RFM['Amount_bin'] = pd.cut(RFM['Amount'],bin = cut_points)
RFM,head(5)
#对 Amount字段--等宽 离散化
RFM['Amount_width_bin'] = pd.cut(RFM.Amount,20) #分成20等分
RFM,head(5)
grouped = RFM.groupby('Amount_width_bin')
grouped['CardID'].count()
#对 Amount字段--等深 离散化
RFM['Amount_depth_bin'] = pd.qcut(RFM.Amount,5) #分成5人的等分约20%
RFM,head(5)
grouped = RFM.groupby('Amount_depth_bin')
grouped['CardID'].count()
有监督离散方法:决策树 离散化后的目标分类纯度最高(对目标有很好的区分能力) 一种特殊的离散化方法: 二值化: 把连续型变量分割为0/1(是/否) 例如:是否大于18岁(是/否) Rounding(取整): 本质上时一种类似‘等距方法’的离散
二、类别变量编码
类别变量编码:
类别型变量—-编码成—> 数值型变量
目的:
机器学习算法 无法处理类别型变量,必须转换为数值型变量
一定程度起到了扩充特征的作用(构造了新的特征)
one-hot encoding 独热编码
dummy encoding 哑变量编码
label-encoding 标签编码
count-Encoding 频数编码 (可以去量纲化,秩序,归一化)
Target encoding 二分类 用目标变量中的某一类的比例来编码
代码:
import pandas as pd #导入的数据源于 特征构造
trade = pd.read_csv('./data/transaction.txt')
trade['Date'] = pd.to_datetime(trade['Date'])
RFM = trade.groupby('CardID').egg({'Date':'max','CardID':'count','Amount':'sum'})
RFM.head()
--------------Onehot 编码(独热编码)使用pandas------------------
onehot = pd.get_dummies(RFM['CardID']),drop_first = False,prefix = 'Freq'
onehot.head()
from sklearn import preprocessing #使用sklearn 导入OneHotEncoder
onehot = preprocessing.OneHotEncoder() #OneHotEncoder
Freq = RFM['CardID'].values.reshape(-1,1)
onehot.fit(Freq)
Freq_onehot = onehot.transform(Freq).toarray()
Freq_onehot
df = pd.DataFrame(Freq_onehot) #将array 转为pandas 的dataframe
df.head()
三、时间型、日期型变量转换
代码:
import pandas as pd
data = pd.DataFrame({'data_time':pd.date_range('1/1/2017 00:00:00',period = 12,freq = 'H'),'data':pd.date_range('2017-1-1',period = 12,freq = 'M')
})
■ data:提取日期型和时间型的特征变量
data['year']= data['data_time'].dt.year
data['month'] = data['data_time'].dt.month
data['day'] = data['data_time'].dt.day
data['hour'] = data['data_time'].dt.hour
data['minute'] = data['data_time'].dt.minute
data['second'] = data['data_time'].dt.second
data['quarter'] = data['data_time'].dt.quarter
data['week'] = data['data_time'].dt.week
data['yearmonth'] = data['data_time'].dt.strftime('%Y-%m')
data['halfyear'] = data['data_time'].mapa(lambda d:'H' if d.month <= 6 else 'H2')
■ data:转换为相对时间特征
import datetime
data['deltaDayToToday'] = (datetime.date.today()-data['date'].dt.date).dt.days #距离今天的间隔(天数)
data['deltaMonthToToday'] = datetime.date.today().month - data['date'].dt.month #距离今天的间隔(月数)
data['daysOfyear'] = data['date'].map(lambda d:366 if d.is_leap_year els 365) #一年过去的进度
data['rateOfyear'] = data['date'].dt.dayofyear/data['daysOfyear']
data.head()
四、 缺失值处理
删除缺失值记录
缺失值替换:
用0替换
平均数替换
众数替换
预测模型替换
构造NaN encoding编码 :
构造一个新的字段来标识是否有缺失(1/0) 任何时候都可使用
import pandas as pd
titanic = pd.read_csv('./data/titanic.csv')
titanic.info()
age_mean = round(titanic['Age'].mean()) #对缺失值进行填充
titanic['Age'].fillna(age_mean,inplace = True) #填充平均年龄
titanic.info()
titanic = pd.read_csv('./data/titanic.csv') #构造缺失值的标志变量(0/1)
titanic.info()
titanic['Age_ismissing'] = 0
titanic.loc[titanic['Age'].isnull(),'Age_ismissing'] = 1
titanic['Age_ismissing'].value_counts()
五、 特征组合
目的:
构造更多更好的特征,提升模型精度(例如:地球仪的经纬密度)
方法:
多个连续变量: 加减乘除运算
多个类别型变量: 所有值交叉组合
import pandas as pd
titanic = pd.read_csv('./data/titanic.csv')
titanic.head()
# 组合特征
titanic['Sex_pclass_combo'] = titanic['Sex']+'_pclass_'+titanic['Pclass'].astype(str)
titanic.Sex_pclass_combo.value_counts()
# onehot编码
Sex_pclass_combo = pd.get_dummies['Sex_pclass_combo'],drop_first = False,prefix = 'onehot'
Sex_pclass_combo.head()

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/12529949.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号