python-字符串
资料:https://www.cnblogs.com/pythonstudy/p/6105915.html
用引号括起的都是字符串,其中的引号可以是单引号,也可以是双引号
也可以三引号,此时输出格式完全相同
三引号
print(""" 我 是 李 明 """)

print(''' 我 是 李 明 ''')

重复字符串
print("李明"*3)

str.title() 将字符串中每个单词的首字母变成大写
str1=str.capitalize() 首字母大写
name.upper() 将字符串所有字母都变成大写
name.lower() 将字符串所有字母都变成小写
str1=str.swapcase() 大小写反转
full_name = first_name + " " + last_name 合并字符串
first_name和last_name 是字符串变量
\t 表示制表符
print("\tPython")
\n 换行符
print("Languages:\nPython\nC\nJavaScript")
str1=str.rstrip() 删除字符串尾部的空白
不改变str的值
Str1=str.lstrip() 删除字符串开头的空白
不改变str的值
Str1=str.strip() 删除字符串两端的空白
不改变str的值
参数 删除字符串两端指定的字符
bl=str.strip('%*') 删除两端的%和* %*顺序无所谓
strip()的参数为空,那么会默认删除字符串头和尾的空白字符(包括\n,\r,\t这些)
str1=str*5 连续str 5次,赋给str1
切片

str1="lm是中国人,我爱我的祖国" str2=str1[3:6:1] """ 参数1:开始索引,默认为0 参数2:结束索引,不包括结束索引字符【顾头不顾尾】,默认为最后索引号 参数3:步长,默认为1 """ print(str2)

顺序倒置
str1="lm是中国人,我爱我的祖国" str2=str1[::-1] print(str2)

in 是否包含
print("中国"in"我是中国人")
not in 是否不包含
r或R 原始字符串 print(r'\n')
倒着取
str='gexsghjmbv'
str1=str[5:1:-1]
print(str1)
返回值是hgsx
x=str.find(str1) 在字符串str中寻找str1字符串,如果存在返回起始索引值,如果不存在返回-1
x=str.find(str1,3,8) 在字符串str中寻找str1字符串,如果存在返回起始索引值,如果不存在返回-1
参数2 是寻找的起始位置
参数3 是寻找的末位置【注意 顾头不顾尾】
x=str.index(str1,3,8) 与fing类似 只是找不到抛出异常
str1=str.center(10) 总长度10个字符 str字符串居中
参数1 总长度
参数2 填充的字符 默认空格
如果str本身超过10个 就返回str
str1=str.expandtabs() 制表符\t前面不足8位时补全到8位,超过8位补全到16位。。。
str='lml\tmm'
str1=str.expandtabs()
print(str)
print(str1)
显示
lml mm
lml mm
参数 补全到n位 默认8位[用空格补]
x=len(str) 返回字符串的字符数
str1="lm是中国人" i=len(str1) print(i)

bl=str.startswith('bd') 判断字符串是否以bd为开头 是 返回true
bl=str.startswith('lm',2,4) 在指定范围内判断字符串是否以lm为开头 是 返回true
参数2 参数3 指定范围 顾头不顾尾
bl=s.endswith('chr') 判断字符串是否以chr为结尾 是 返回true
bl=s.endswith('chr',2,7) 在指定范围内判断字符串是否以chr为结尾 是 返回true
bl=str.count('lm') 返回字符串中lm的次数
bl=str.count('lm',1,7) 在指定范围内返回字符串中lm的次数 顾头不顾尾
split把字符串变成列表
s=" 我是中国人 我爱我的祖国 李佩霞 " lb=s.split() #以空格为分隔符 返回被分割后的列表 #空格分隔符时,他把连续的空格看成一个,头尾自动不算;其它分隔符不行 print(lb)

s="我是中国人,我爱我的祖国,李佩霞" lb=s.split(",") #指定分隔符 print(lb)

x='我';print(x.isalnum()) 判断是否是由阿拉伯数字或字母组成,不能包含符号、空格
x='我';print(x.isalpha()) 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
print('a'.islower()) 判断是否小写 是返回true
print('a'.isupper()) 判断是否大写 是返回true
s1=s.isalnum() 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
s1=s.isdigit() 字符串只包含数字则返回 True 否则返回 False
c=a.isspace() 是否只由空格组成
c=a.isidentifier() 字符串是否是字母开头
c=a.isprintable() 判断字符串中所有字符是否都是可见字符
c=li.partition(name) 根据指定的分隔符将字符串进行分割
包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
例子
name = 'swht'
li = 'hhsslswhtolljm'
c=li.partition(name)
print(c)
结果 ('hhssl', 'swht', 'olljm')
例子
name = 'swhtaa'
li = 'hhsslswhtolljm'
c=li.partition(name)
print(c)
结果 ('hhsslswhtolljm', '', '')
s1=s.replace('lm','LM') 把字符串中所有lm用LM来替换
s1=s.replace('lm','LM',1) 指定替换次数
join把序列变成字符串
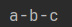
list01=["a","b","c"] result="-".join(list01) """ 参数:序列 - 是分隔符,可以是单个字符,也可以是字符串 """ print(result)
s1=ord('a') 返回对应的 ASCII 数值或者 Unicode 数值
n=ord("a") #返回对应的ASCII数值或者Unicode数值 print(n) #97 n=ord("李") print(n) #26446
s1=chr(s1) 把ASCII数值或者Unicode数值转换成字符
n=chr(97) #返回对应的ASCII数值或者Unicode数值 print(n) #a n=chr(26446) print(n) #李
ascii只要是ascii码中的内容,就打印出来,不是就转换成\u
n=ascii(97) #只要是ascii码中的内容,就打印出来,不是就转换成\u print(n) #97 n=ascii("李") print(n) #'\u674e'
repr返回数据的原来格式--包括格式符号
str()和repr()区别:
函数str( )将其转化成为适于人阅读的前端样式文本
函数repr(object)将对象转化为供解释器读取的形式。返回一个对象的 string 格式
name="liming" print("你好%r"%name) #%r就是repr函数 print(repr("1")) #repr返回数据的原来格式--包括格式符号 print(repr(1))

新版格式输出
r 表示后面没有转义字符
#print("C:\Users\Administrator\Desktop\24教材") #这是错误的,\被认为是转义字符 print("C:\\Users\\Administrator\\Desktop\\24教材") #正确 print(r"C:\Users\Administrator\Desktop\24教材") #正确 #r 表示后面没有转义字符
f-string格式化
f-string 是一种用于格式化字符串的语法,它在 Python 3.6 版本中引入。f-string 可以将变量的值插入到字符串中,并允许指定变量的格式。在 f-string 中,可以在字符串前加上 f 或 F 标记,然后使用花括号 {} 将变量或表达式括起来,以将其插入到字符串中。在花括号内,可以使用冒号 : 来指定格式化选项
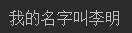
str1="李明" str2=f"我的名字叫{str1}" #使用变量 print(str2)
str2=f"我的年龄是{50+7}岁" #使用表达式 print(str2)

:.保留n位小数
i=12.54678 str2=f"我买了{i:.2f}斤白菜" #2表示保留2位小数 print(str2)

至少n位整数位
str2=f"现在是{2:2d}月" #至少n位整数位 print(str2)

说明:格式化:后面的内容看:https://www.cnblogs.com/liming19680104/p/10291463.html








【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)