线程
前言: 进程,线程傻傻分不清
========= 储备知识 ======== 细说背景:CPU+RAM+各种资源(比如显卡,光驱,键盘,GPS, 等等外设)构成我们的电脑,但是电脑的运行,实际就是CPU和相关寄存器以及RAM之间的事情。 一个最最基础的事实:CPU太快,太快,太快了,寄存器仅仅能够追的上他的脚步,RAM和别的挂在各总线上的设备完全是望其项背。那当多个任务要执行的时候怎么办呢?轮流着来?或者谁优先级高谁来?不管怎么样的策略,一句话就是在CPU看来就是轮流着来。 一个必须知道的事实:执行一段程序代码,实现一个功能的过程介绍 ,当得到CPU的时候,相关的资源必须也已经就位,就是显卡啊,GPS啊什么的必须就位,然后CPU开始执行。这里除了CPU以外所有的就构成了这个程序的执行环境,也就是我们所定义的程序上下文。 当这个程序执行完了,或者分配给他的CPU执行时间用完了,那它就要被切换出去,等待下一次CPU的临幸。在被切换出去的最后一步工作就是保存程序上下文,因为这个是下次他被CPU临幸的运行环境,必须保存。 串联起来的事实:前面讲过在CPU看来所有的任务都是一个一个的轮流执行的,具体的轮流方法就是:先加载程序A的上下文,然后开始执行A,保存程序A的上下文,调入下一个要执行的程序B的程序上下文,然后开始执行B,保存程序B的上下文。。。。 ========= 结论 ======== 进程和线程就是这样的背景出来的,两个名词不过是对应的CPU时间段的描述,名词就是这样的功能。 进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文 线程是什么呢?进程的颗粒度太大,每次都要有上下的调入,保存,调出。 如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序A,实际分成 a,b,c等多个块组合而成。 那么这里具体的执行就可能变成:程序A得到CPU =》CPU加载上下文,开始执行程序A的a小段,然后执行A的b小段,然后再执行A的c小段,最后CPU保存A的上下文。 这里a,b,c的执行是共享了A的上下文,CPU在执行的时候没有进行上下文切换的。 这里的a,b,c就是线程,也就是说线程是共享了进程的上下文环境,的更为细小的CPU时间段。 总结:进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同。
开启线程
两种方式


1 # 方式一: 2 # def task(name): 3 # print('%s is running' % name) 4 # time.sleep(3) 5 # 6 # if __name__ == '__main__': 7 # t = Thread(target=task,args=('lmj',)) 8 # 9 # # t = Process(target=task,args=('lmj',)) 10 # 11 # t.start() 12 # print('主线程') # 主线程代码运行完,等待其他子线程 13 #
1 # # 方式二: 2 # class Mytask(Thread): 3 # 4 # def run(self): 5 # print('%s is running' % self.name) 6 # time.sleep(3) 7 # 8 # if __name__ == '__main__': 9 # t = Mytask() 10 # 11 # # t = Process(target=task,args=('lmj',)) 12 # 13 # t.start() 14 # print('主线程') # 主线程代码运行完,等待其他子线程
查看主线程,“子线程”的pid
1 # # 查看pid: 2 # import os 3 # class Mytask(Thread): 4 # 5 # def run(self): 6 # print('%s is running' % os.getpid()) 7 # time.sleep(3) 8 # 9 # if __name__ == '__main__': 10 # t = Mytask() 11 # 12 # # t = Process(target=task,args=('lmj',)) 13 # 14 # t.start() 15 # print('主线程',os.getpid()) # 主线程代码运行完,等待其他子线程
线程的方法
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁 需要强调的是:运行完毕并非终止运行 #1.对主进程来说,运行完毕指的是主进程代码运行完毕 #2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕 详细解释: #1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
1 from threading import Thread 2 import time 3 def foo(): 4 print(123) 5 time.sleep(1) 6 print("end123") 7 8 def bar(): 9 print(456) 10 time.sleep(3) 11 print("end456") 12 13 if __name__ == '__main__': 14 15 t1=Thread(target=foo) 16 t2=Thread(target=bar) 17 18 t1.daemon=True 19 t1.start() 20 t2.start() 21 print("main---") 22 23 """ 24 123 25 456 26 main--- 27 end123 28 end456 29 """
1 from threading import Thread 2 import time 3 def foo(): 4 print(123) 5 time.sleep(5) 6 print("end123") 7 8 def bar(): 9 print(456) 10 time.sleep(3) 11 print("end456") 12 13 if __name__ == '__main__': 14 15 t1=Thread(target=foo) 16 t2=Thread(target=bar) 17 18 t1.daemon=True 19 t1.start() 20 t2.start() 21 print("main---") 22 23 """ 24 123 25 456 26 main--- 27 end456 28 """
线程互斥锁
牺牲效率,保证数据安全性
1 import time 2 from threading import Thread,Lock 3 4 mutex = Lock() 5 6 x = 10 7 def task(): 8 global x 9 mutex.acquire() 10 temp = x 11 time.sleep(0.1) 12 x = temp - 1 13 mutex.release() 14 15 if __name__ == '__main__': 16 start_time = time.time() 17 t_l = [] 18 for i in range(10): 19 t = Thread(target=task) 20 t_l.append(t) 21 t.start() 22 23 for t in t_l: 24 t.join() 25 26 print('主',x) 27 print('运行时长',time.time()-start_time) 28 29 """ 30 主 0 31 运行时长 1.0055220127105713 32 """
死锁现象与递归锁RLock()
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2018/04/26 11:53 4 # @Author : MJay_Lee 5 # @File : 死锁现象与递归锁.py 6 # @Contact : limengjiejj@hotmail.com 7 8 import time 9 from threading import Thread,RLock 10 11 mutexA = mutexB = RLock() 12 13 14 class MyThread(Thread): 15 def run(self): 16 self.f1() 17 self.f2() 18 19 def f1(self): 20 mutexA.acquire() 21 print('%s 拿到了A锁 ' % self.name) 22 23 mutexB.acquire() 24 print('%s 拿到了B锁 ' % self.name) 25 26 mutexB.release() 27 mutexA.release() 28 29 def f2(self): 30 mutexB.acquire() 31 print('%s 拿到了B锁 ' % self.name) 32 time.sleep(0.1) 33 34 mutexA.acquire() 35 print('%s 拿到了A锁 ' % self.name) 36 mutexA.release() 37 mutexB.release() 38 39 if __name__ == '__main__': 40 for i in range(10): 41 p = MyThread() 42 p.start() 43 44 print('主')
信号量Semaphore
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2018/04/26 12:20 4 # @Author : MJay_Lee 5 # @File : 信号量.py 6 # @Contact : limengjiejj@hotmail.com 7 8 import threading 9 import time 10 from threading import Thread,Semaphore 11 12 13 def task(): 14 sm.acquire() 15 time.sleep(2) 16 print('%s is running' % threading.current_thread().name) 17 sm.release() 18 19 if __name__ == '__main__': 20 sm = Semaphore(5) 21 for i in range(20): 22 t = Thread(target=task) 23 t.start() 24 25 """ 26 效果是5个打印结果一起出现屏幕上 27 Thread-1 is running 28 Thread-3 is running 29 Thread-2 is running 30 Thread-5 is running 31 Thread-4 is running 32 Thread-8 is running 33 Thread-6 is running 34 Thread-7 is running 35 Thread-9 is running 36 Thread-10 is running 37 Thread-11 is running 38 Thread-12 is running 39 Thread-13 is running 40 Thread-15 is running 41 Thread-14 is running 42 Thread-16 is running 43 Thread-17 is running 44 Thread-18 is running 45 Thread-19 is running 46 Thread-20 is running 47 48 """
线程queue
1 # queue队列 :使用import queue,用法与进程Queue一样 2 # 3 # queue is especially useful in threaded programming when information must be exchanged safely between multiple threads. 4 # 5 # class queue.Queue(maxsize=0) #先进先出 6 7 import queue 8 9 q=queue.Queue() 10 q.put('first') 11 q.put('second') 12 q.put('third') 13 14 print(q.get()) 15 print(q.get()) 16 print(q.get()) 17 ''' 18 结果(先进先出): 19 first 20 second 21 third 22 ''' 23 24 class queue.LifoQueue(maxsize=0) #last in fisrt out 25 import queue 26 27 q=queue.LifoQueue() 28 q.put('first') 29 q.put('second') 30 q.put('third') 31 32 print(q.get()) 33 print(q.get()) 34 print(q.get()) 35 ''' 36 结果(后进先出): 37 third 38 second 39 first 40 ''' 41 42 class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列 43 import queue 44 45 q=queue.PriorityQueue() 46 #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 47 q.put((20,'a')) 48 q.put((10,'b')) 49 q.put((30,'c')) 50 51 print(q.get()) 52 print(q.get()) 53 print(q.get()) 54 ''' 55 结果(数字越小优先级越高,优先级高的优先出队): 56 (10, 'b') 57 (20, 'a') 58 (30, 'c') 59 '''
线程Event
import time from threading import Event,current_thread,Thread # success = False event = Event() def check(): print('%s 正在检测服务是否正常' % current_thread().name) time.sleep(5) # global success # success = True event.set() def connect(): count = 1 while not event.is_set(): if count == 4: print('尝试次数过多,请检查网络再重试!') return print('%s 尝试第 %s 次链接。。。' % (current_thread().name,count)) # while True: # if not success: # time.sleep(2) # event.wait(1) count += 1 print('%s 开始链接。。。' % current_thread().name) if __name__ == '__main__': t1 = Thread(target=connect) t2 = Thread(target=connect) t3 = Thread(target=connect) c1 = Thread(target=check) c1.start() t1.start() t2.start() t3.start() """ 结果: Thread-4 正在检测服务是否正常 Thread-1 尝试第 1 次链接。。。 Thread-2 尝试第 1 次链接。。。 Thread-3 尝试第 1 次链接。。。 Thread-1 尝试第 2 次链接。。。 Thread-2 尝试第 2 次链接。。。 Thread-3 尝试第 2 次链接。。。 Thread-2 尝试第 3 次链接。。。 Thread-1 尝试第 3 次链接。。。 Thread-3 尝试第 3 次链接。。。 尝试次数过多,请检查网络再重试! 尝试次数过多,请检查网络再重试! 尝试次数过多,请检查网络再重试! """
协程
1、单线程下实现并发
并发指的是,多个任务看起来是同时运行
并发实现的本质:切换 + 保存状态
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它 ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将下图理解为线程的三种状态
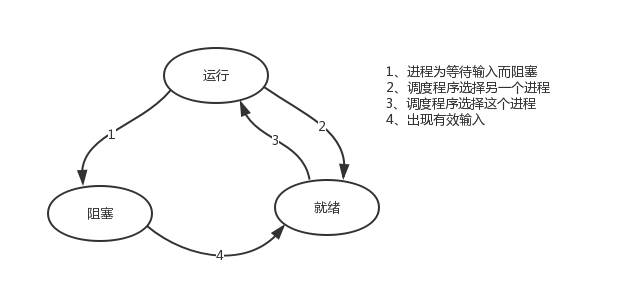
关键理论:
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
故此,协程只有在遇到I/O情况才能提升效率,而不是说协程一定能提升效率。
优点:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
一个示例:
1 import time 2 def consumer(): 3 '''任务1:接收数据,处理数据''' 4 while True: 5 x=yield 6 7 def producer(): 8 '''任务2:生产数据''' 9 g=consumer() 10 next(g) 11 for i in range(10000000): 12 g.send(i) 13 time.sleep(2) 14 15 start=time.time() 16 producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行 17 18 stop=time.time() 19 print(stop-start)
那么,遇到I/O情况,如何实现:(Greenlet)
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
from greenlet import greenlet def eat(name): print('%s eat 1' %name) g2.switch('cly') print('%s eat 2' %name) g2.switch() def play(name): print('%s play 1' %name) g1.switch() print('%s play 2' %name) g1=greenlet(eat) g2=greenlet(play) g1.switch('lmj')#可以在第一次switch时传入参数,以后都不需要
此处会有问题,当在eat方法中有遇到I/O,并不会切换,那么如何实现:gevent
from gevent import monkey;monkey.patch_all() # 此步就是给程序中所有I/O打上标记,让gevent能识别 import gevent import time def eat(name): print('%s eat 1' % name) # gevent.sleep(5) time.sleep(5) print('%s eat 2' % name) def play(name): print('%s play 1' % name) # gevent.sleep(3) time.sleep(3) print('%s play 2' % name) g1 = gevent.spawn(eat,'lmj') g2 = gevent.spawn(play,'cly') # gevent.sleep(6) gevent.joinall([g1,g2]) """ lmj eat 1 cly play 1 cly play 2 lmj eat 2 """
