Spark DataSource 源码解析
SparkSession.read()

创建DataFrameReader对象,进行数据读取任务。
DataFrameReader
format

schema

option
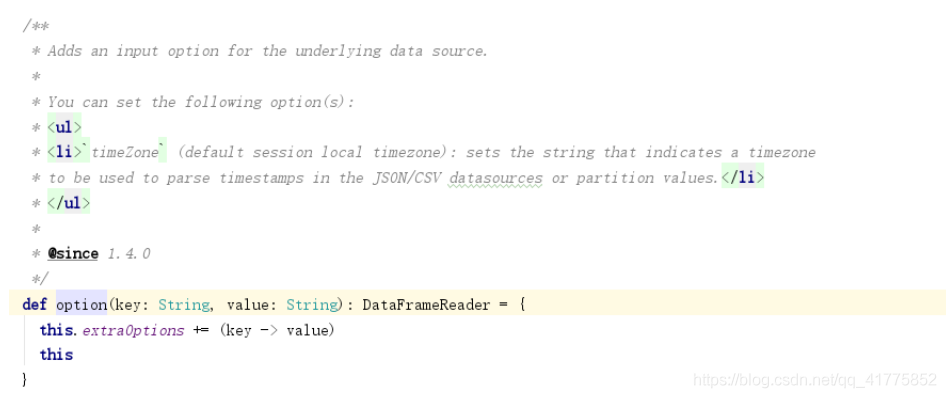
json、csv、text…

通过format函数设置格式,并调用load函数加载数据。
load
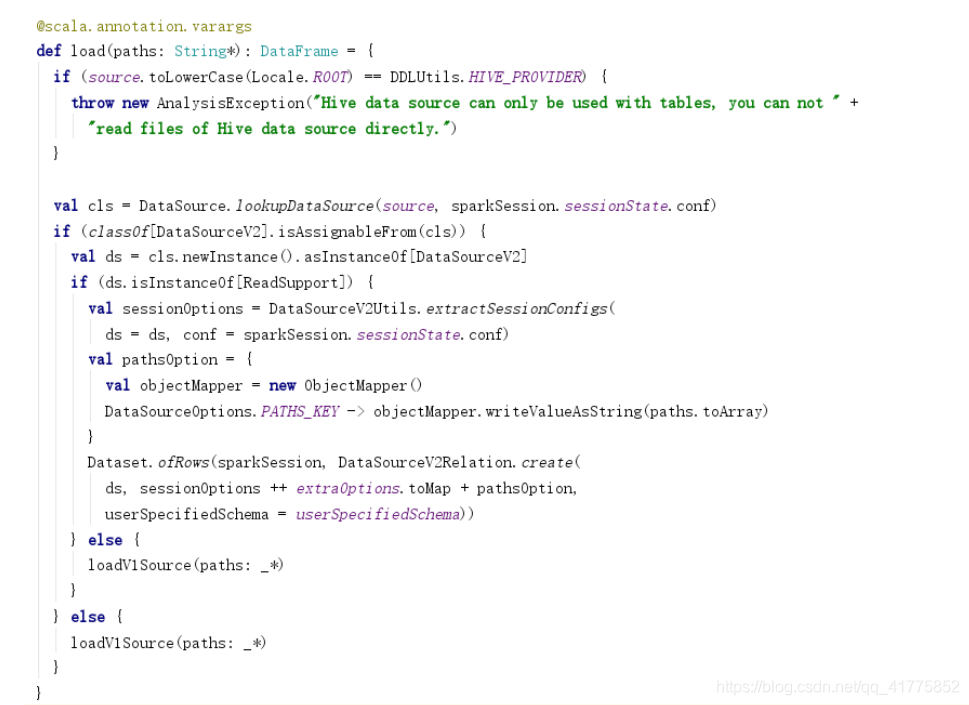
调用DataSource.lookupDataSource方法获取source(参数为format传入的字符串)对应的Class对象。
如果该Class对象继承自DataSourceV2,且实现了ReadSupport接口,则调用DataSourceV2Relation.create方法创建DataSourceV2Relation逻辑计划,传入Dataset.ofRows方法,生成DataSet<Row>返回。
否则,调用loadV1Source方法,返回DataSet<Row>。
DataSource.lookupDataSource
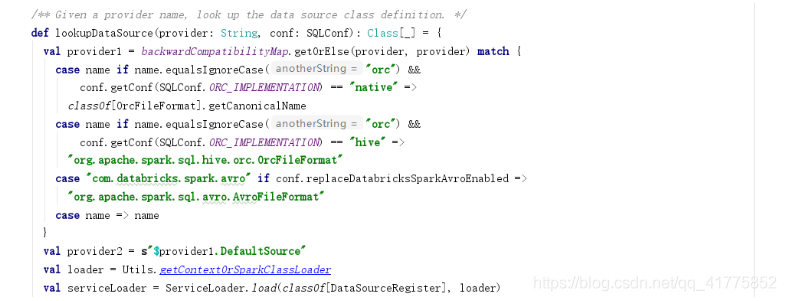

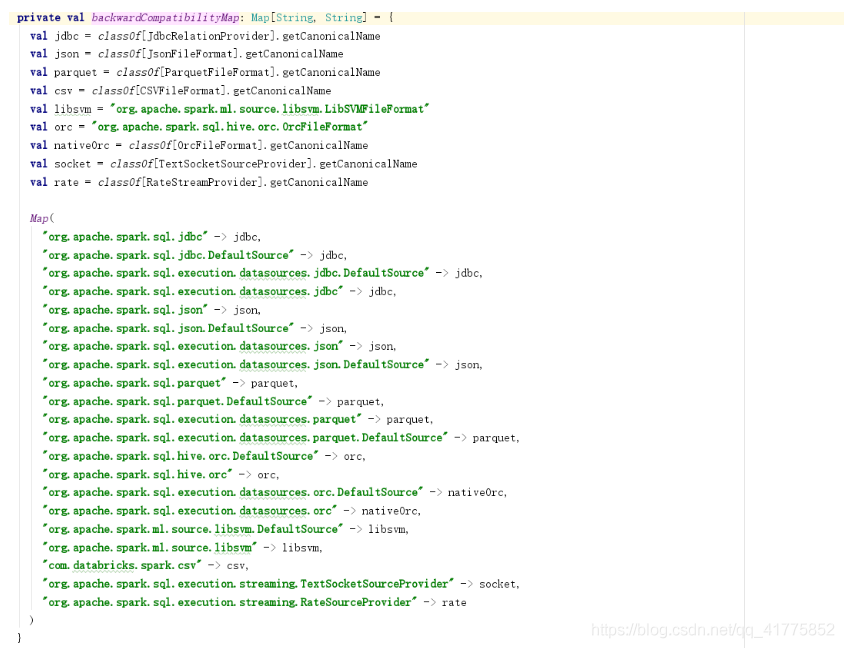
创建provider1 : 从backwardCompatibilityMap获取provider(DataframeRead的source字符串)所对应的默认的DataSourceProvider的全类名。如果provider为jdbc、json、parquet、orc等相关的全类名,则可直接返回对应的DataSourceProvider的全类名,否则返回provider本身。
举例:
(1)provider = “json” => provider1 = “json”,因为 backwardCompatibilityMap没有key为"json";
(2)provider = “org.apache.spark.sql.json” => provoider1 = “org.apache.spark.sql.execution.datasources.json.JsonFileFormat”
创建provider2 = s"$provider1.DefaultSource"
举例:
(1)provider1 = “json” => provider2 = “json.DefaultSource”;
(2) provoider1 = “org.apache.spark.sql.execution.datasources.json.JsonFileFormat” => provider2 = “org.apache.spark.sql.execution.datasources.json.JsonFileFormat.DefaultSource”)
使用ServiceLoader加载所有继承DataSourceRegister的类,得到serviceLoader
serviceLoader.asScala.filter(_.shortName().equalsIgnoreCase(provider1)).toList判断provider1是否为shortName(继承DataSourceRegister可以为DataSource注册shortName)。
provider1不是shortName,则使用SparkClassLoader加载provider1,失败则加载provider2
举例:
provider1 = org.apache.spark.sql.execution.datasources.json.JsonFileFormat,加载成功
provider1是shortName,则直接返回其对应的DataSource Class。
举例:provider1 = json,
从以上步骤我们可以看出自定义DataSource的方法,则有以下两种方式:
用provider1正确加载DataSourceProvider类。provider(即传入format方法中的字符串)= shortName,但是DataSourceProvider必须继承DataSourceRegister接口。或者provider = 自定义DataSourceProvider的全类名。
用provider2正确加载DataSourceProvider类。provider = 自定义DataSourceProvider类的包名,DataSourceProvider类名为DefaultSource。
DataSourceProvider一般分为两类:继承FileFormat或RelationProvider接口.
DataSource API扩展借鉴:
https://github.com/apache/hbase-connectors/tree/master/spark
https://github.com/IGNF/spark-iqmulus
DataFrameReader.loadV1Source

创建DataSource对象,并调用resolveRelation方法返回BaseRelation对象,传入sparkSession.baseRelationToDataFrame方法,返回RDD<Row>
DataSource.resolveRelation
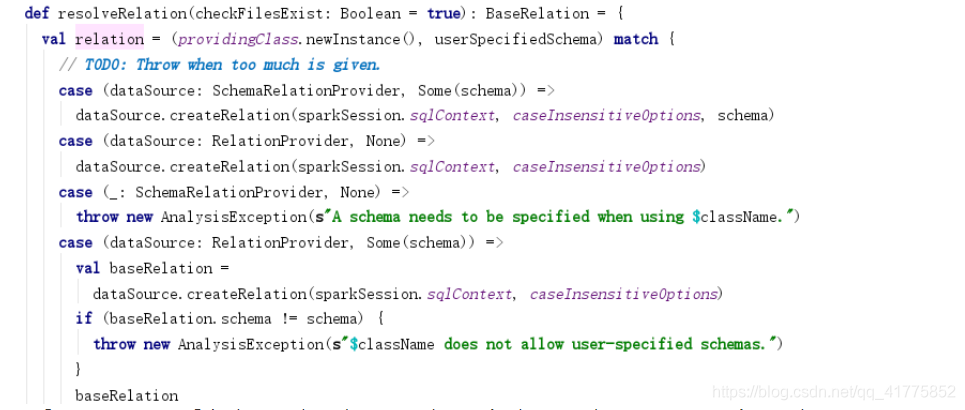

providingClass即是调用DataSource.lookupDataSource返回的DataSource Class。

- 如果DataSource是SchemaRelationProvider类型,且userSpecifiedSchema不为null,则调用dataSource.createRelation(传入schema)创建BaseRelation。
- 如果DataSource是RelationProvider类型,且userSpecifiedSchema为null,则调用dataSource.createRelation(不传入schema)创建BaseRelation。
- 如果DataSource是RelationProvider类型,且userSpecifiedSchema不为null,则调用dataSource.createRelation(不传入schema)创建BaseRelation,如果baseRelation.schema != userSpecifiedSchema则报出异常,否则返回
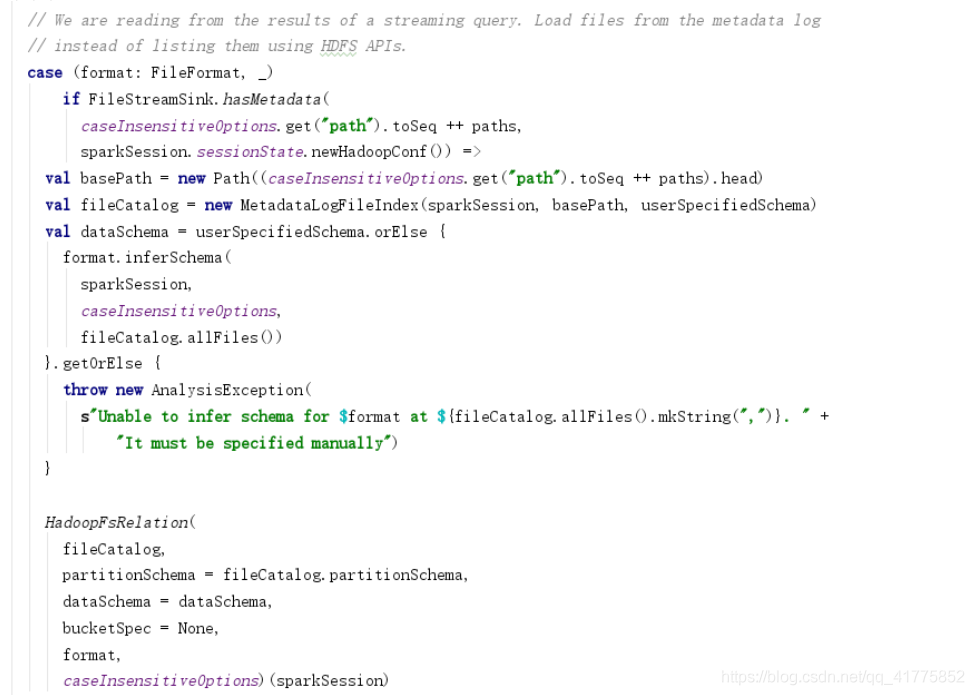
- 如果DataSource是FileFormat,则创建HadoopFsRelation对象。
对于创建的BaseRelation对象进行checkColumnNameDuplication,然后返回。
SparkSession.baseRelationToDataFrame

利用BaseRelation创建LogicalRelation逻辑计划。
数据源有关的Strategy
FileSourceStrategy
SparkSQL执行过程中利用Strategy会将逻辑计算转换为物理计划。

FileSourceStrategy会传入HadoopFsRelation创建FileSourceScanExec物理计划。
FileSourceScanExec
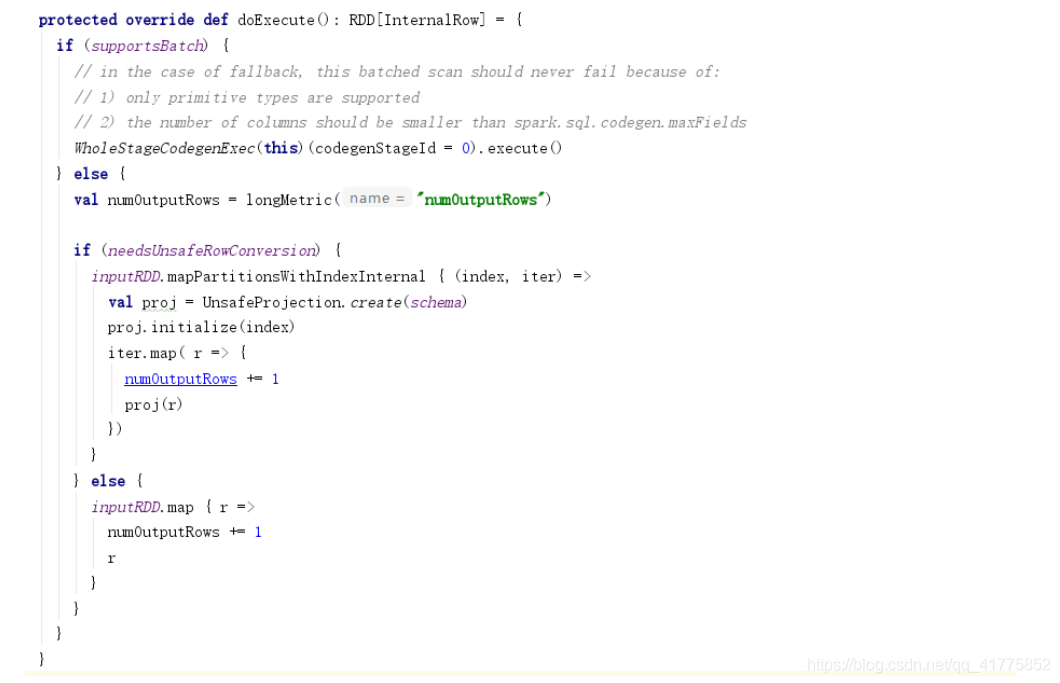
doExecute()判断inputRDD<InternalRow>是否需要进行unsafeRow的转换。
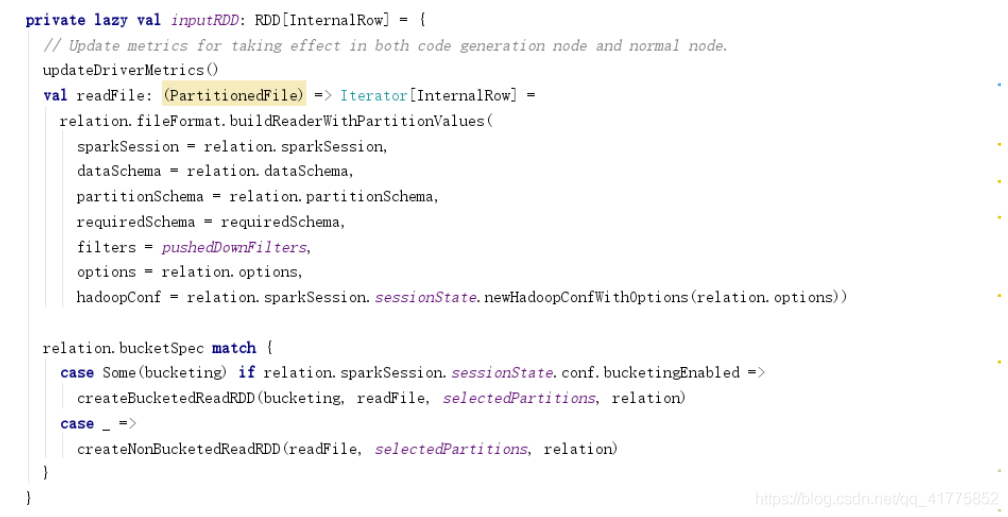
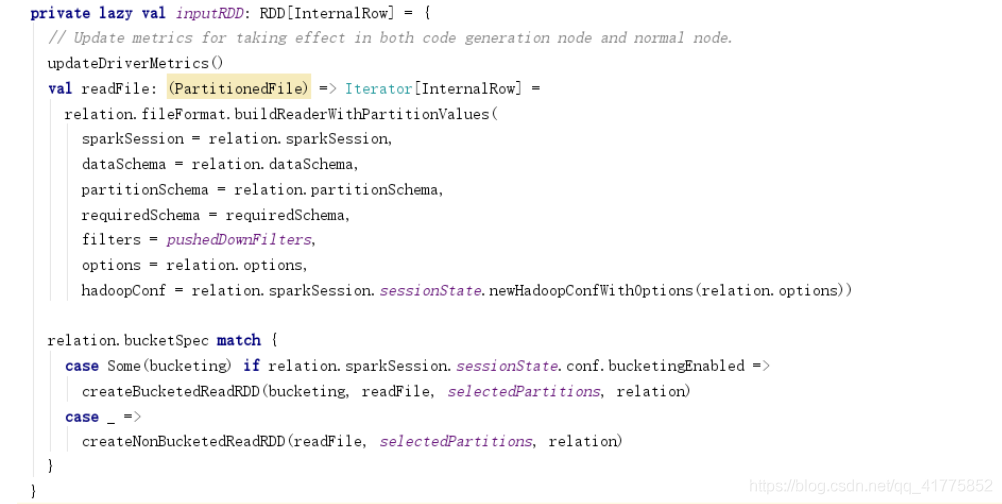
inputRDD中利用relation.fileFormat.buildReaderWithPartitionValues作为readFile的方法,创建BucketedReadRDD或者NonBucketedReadRDD。

buildReader方法实现在FileFormat子类当中,比如TextFileFormat:


TextFileFormat使用HadoopFileLinesReader或者HadoopFileWholeTextReader读取PartitionedFile文件中的数据,返回Iterator[UnsafeRow] 。
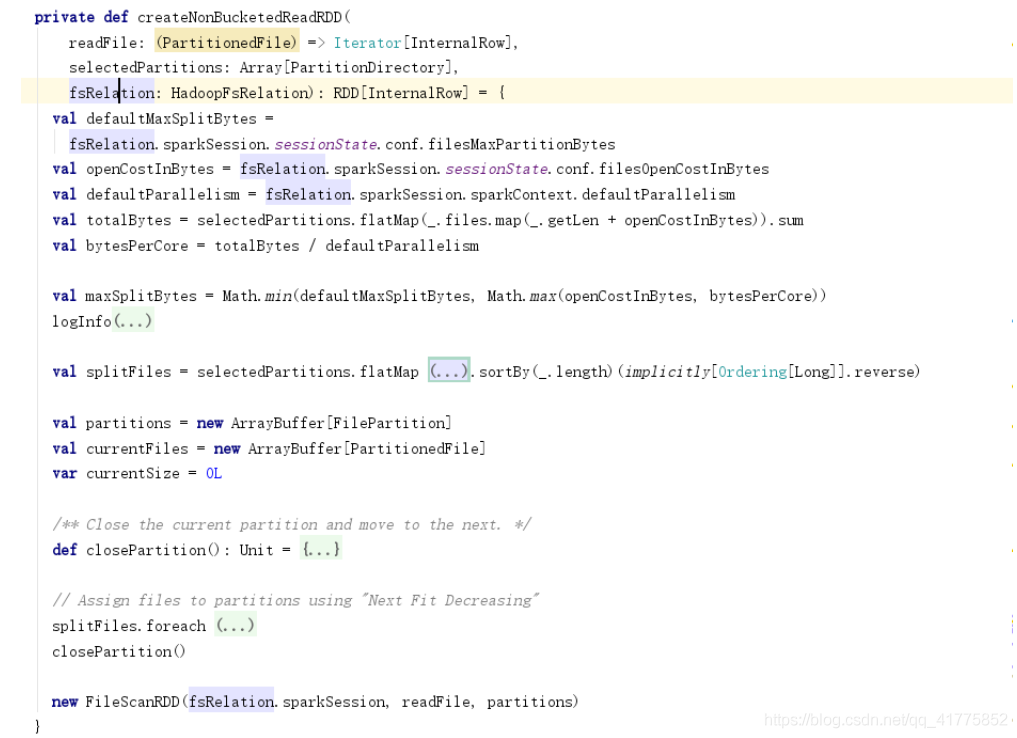
createNonBucketedReadRDD和createBucketedReadRDD会创建FileScanRDD。FileScanRDD的compute方法会利用readFile方法读取文件数据。
DataSourceStrategy
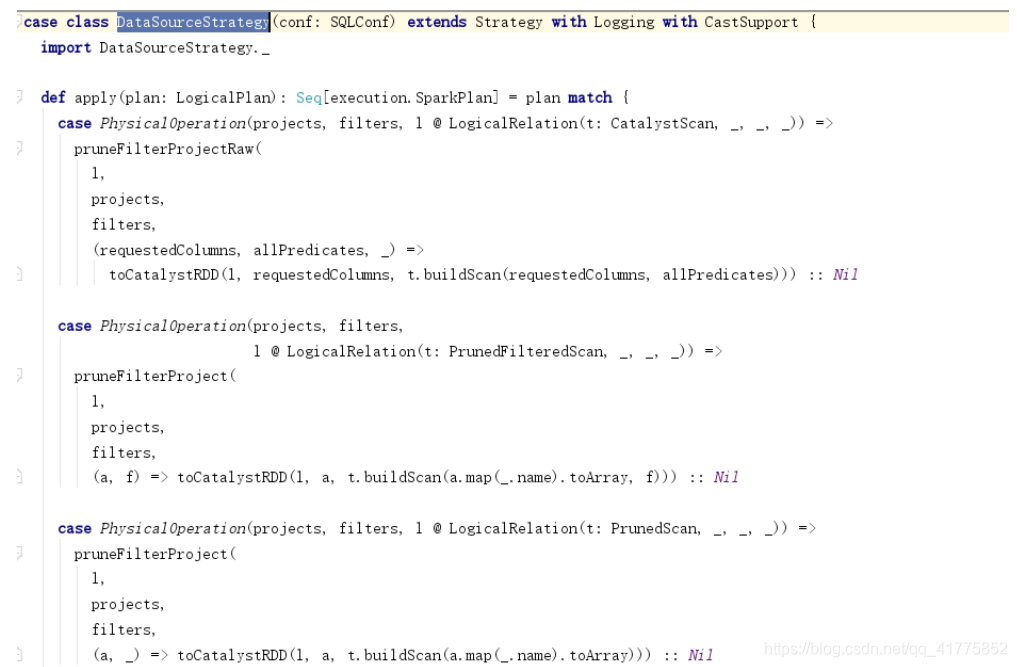

InMemoryScans

DataSourceStrategy和InMemoryScans策略最后都会生成RowDataSourceScanExec,最终会调用CatalystScan\PrunedScan\TableScan的buildScan方法生成RDD[Row],再调用toCatalystRDD将RDD[Row]转换为RDD[InternalRow]。

总结
format方法传入source字符串
DataSource.lookupDataSource会找到source对应的DataSource类(一般包括FileFormat和 RelationProvider两类)
DataSource.resolveRelation会根据DataSource类型创建BaseRelation(一般包括HadoopFsRelation和继承BaseRelation且实现以下接口的类:TableScan、PrunedScan、PrunedFilteredScan、InsertableRelation、CatalystScan )。
SparkSession.baseRelationToDataFrame将BaseRelation传入创建LogicalRelation逻辑计划,并利用LogicalRelation创建DataSet。
FileSourceScanExec\DataSourceStrategy\InMemoryScans将LogicalRelation逻辑计划转换为物理计划,生成具体的DataSourceRDD,compute函数实现真正的读取逻辑。
————————————————
原文链接:https://blog.csdn.net/qq_41775852/article/details/112359682

 浙公网安备 33010602011771号
浙公网安备 33010602011771号