【转】SparkSQL扩展到自定义数据源之Druid-Spark查询druid
Druid是Apache 下开源的一款存储与计算一体的olap查询引擎,spark则是纯计算引擎。Druid的数据存储在历史节点,通过broker节点查询,整体的查询流程是两阶段的聚合。数据分布在多个历史节点,查询时,第一阶段在各个历史节点并行计算,第二阶段,多个历史节点的数据汇聚到broker节点,做最后的聚合结算。架构上,broker存在单点瓶颈的风险。通常的意义的聚合,例如sum,max,min,count,broker查询性能足够应对。但是,复杂的聚合,例如去重计算:datasketch,hypeunique,bitmap精确去重,分位数计算,broker显得捉襟见肘,特别吃力。
这类计算不是简单的类型的加减乘除(max,min,sum),而是复杂数据容器之间的计算,占用堆内存特别多,CPU消耗也很多。顺便说一句,我们的分析场景,max,min,sum,avg,count 毫无地位,disctinct count才是主角,恰恰去重计算业界根本没有特别好的解决方案。唯一的一个是美图的基于分布式bitmap的去重计算:https://www.infoq.cn/article/UEyPTRJcztM7FQGebtfT
单个broker根本不足以应付。解决思路自然是增加broker节点,增加聚合的并行度。
1.增加druid的broker节点
1)数据分布在60个历史节点上,我们可以引入10个broker节点,每个broker节点负责聚合6个历史节点聚合的中间数据。这样第二阶段有10个broker节点在聚合。最后再引入一个broker,将10个broker的聚合结果最后一次聚合。
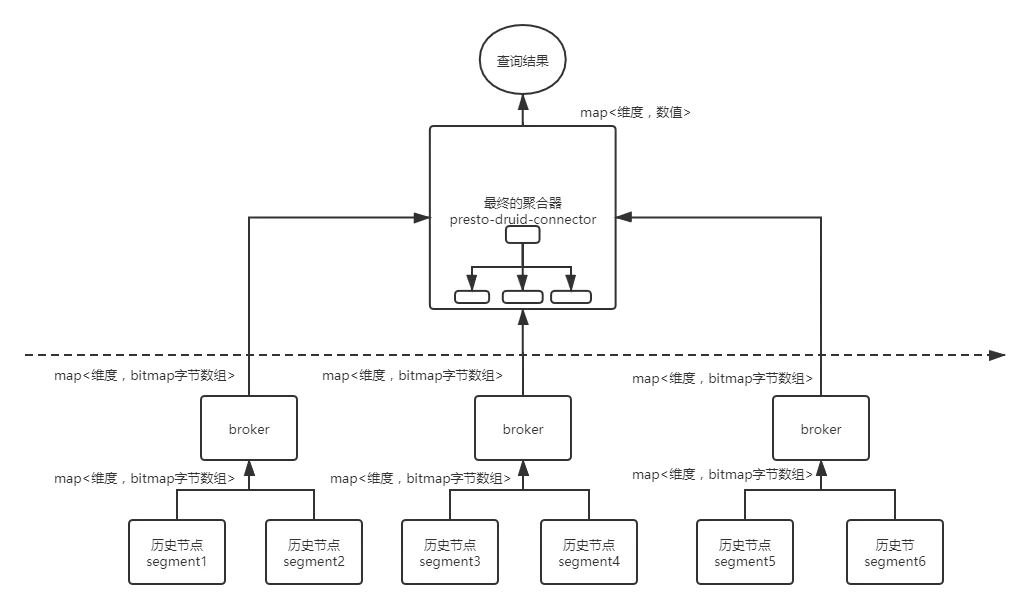
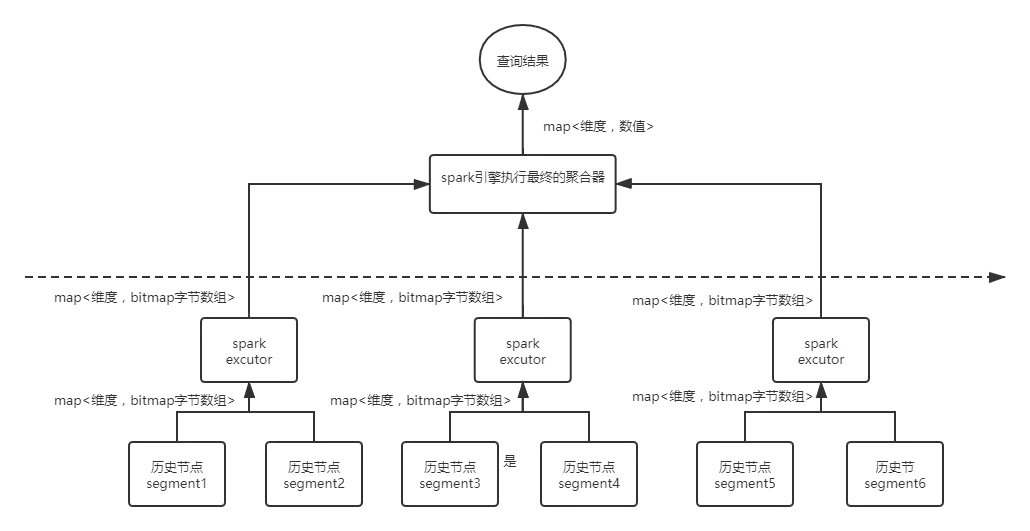
2.引入分布式计算引擎Spark/Presto
针对(1)的不足之处在与,第二阶段的聚合的并发还是不够多。直接一步到位,引入分布式计算引擎:spark或者presto,历史节点的计算的结果在spark中构建临时表,通过全体数据shuffle的方式,进行聚合。这里以spark为例。
假设数据分布在60个历史节点,spark启动60个executor,每个executor分别拉取一个历史节点的数据,这样RDD的分区数量是:60。通过自定义UDAF函数,对数据通过shuffle进行分组聚合。最后的结果拉倒driver。这里的最后结果已经最终的结果,可以直接传输到driver,返回查询结果。
SparkSQL扩展数据源开发步骤
1.自定义RDD。实现compute,getPartition等接口。
这里定义RDD的分区数量与传入的参数历史节点的数量相等。
定义next接口。这里强调下spark和druid是一脉相承。druid中,历史节点返回聚合数据的方式就是通过迭代器的方式流式返回,所以,RDD的next接口中,可以自然使用druid中迭代器接口:JsonParserIterator。直接将DirectDruidClient中JsonParserIterator封装一下,放到RDD的next中,特别合适。复杂聚合类型的数据类型,历史节点中返回是byte[],在spark需要转换为binaryType。
2.自定义数据源。实现relationprovider接口,buildscan等。
3.自定义复杂类型的聚合函数UDAF。
可以参考这个https://www.shangmayuan.com/a/f5496e01261d4b499d9cb938.html
本质上就是将byte[] 反序列为RoaringBitmap类型,进行与或操作,然后序列化,开始下一次聚合。
--------------------------------------------
作者:sydt2011
链接:https://www.jianshu.com/p/a6658291ed4f
来源:简书

