[转]Spark自定义HBase数据源
转发原文:Spark自定义HBase数据源
Spark内置很多数据源,却没有HBase的数据源,需要调用rdd的api,如果能有下面这种方式就非常完美了:
frame.write.format("hbase")
.mode(SaveMode.Append)
.option(ZK_HOST_HBASE, "bigdata.cn")
.option(ZK_PORT_HBASE, 2181)
.option(HBASE_TABLE, "tbl_users_2")
.option(HBASE_FAMILY, "detail")
.option(HBASE_ROW_KEY, "id")
.option(HBASE_SELECT_WHERE_CONDITIONS,"id[ge]50")
.save()
参考spark sql内置的数据源和第三方提供的数据源(如Kudu、Elaticsearch),自定义HBase数据源。
一,思路
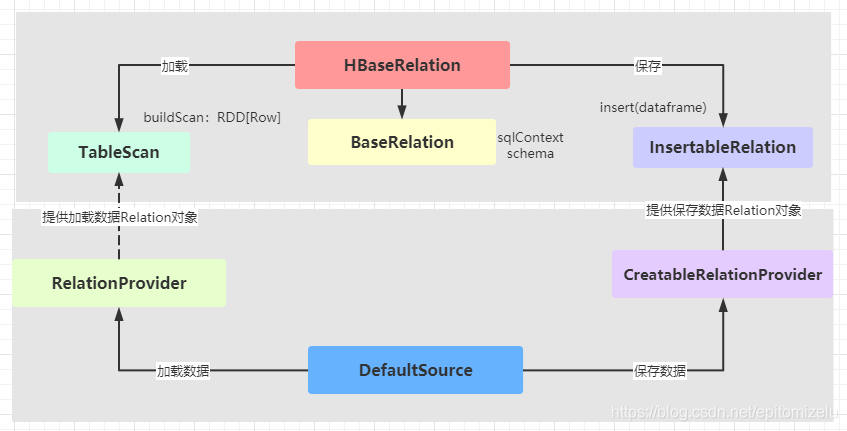
1,编写两个类HBaseRelation和DefaultSource。
HBaseRelation(数据源):负责实现读写HBase的逻辑,继承两个接口,TableScan(读),InsertableRelation(写)
DefaultSource: 工厂类,创建HBaseRelation提供给框架调用,实现两个接口,RelationProvider(创建TableScan对象),CreatableRelationProvider(创建InsertableRelation对象)。如果要用简称format("hbase"),还需要实现DataSourceRegister
这两个类的继承体系如下,上面代码中的format("hbase")指的是DefaultSource,通过DefaultSource创建HBaseRelation对象,再通过HBaseRelation对象读写HBase。
2,注册
format("hbase")中的hbase是DefaultSource的代称,要让系统知道这种关联关系,需要做两件事。
一是DefaultSource继承DataSourceRegister,指定简称。
override def shortName(): String = "hbase"
二是通过resources目录下的配置文件注册,特别注意目录是resources下的META-INF下的services目录。

二,代码
Condition条件类
该类解析过滤条件,.option(HBASE_SELECT_WHERE_CONDITIONS,"id[ge]50"),意思是查询id大于等于50的数据
package com.lcy.models.datasource import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp import scala.util.matching.Regex case class Condition(field:String,op:CompareOp,value:String) object Condition{ val reg = "(.*)\\[(.*)\\](.*)".r def parse(condition:String) = { val matches: Iterator[Regex.Match] = reg.findAllMatchIn(condition) val matchR: Regex.Match = matches.toList(0) val field = matchR.group(1) val op = matchR.group(2) val value = matchR.group(3) val compareOp: CompareOp = op match { case "ge" => CompareOp.GREATER_OR_EQUAL case "gt" => CompareOp.GREATER case "eq" => CompareOp.EQUAL case "le" => CompareOp.LESS_OR_EQUAL case "lt" => CompareOp.LESS case "neq" => CompareOp.NOT_EQUAL case _ => throw new RuntimeException("not supported operator") } Condition(field,compareOp,value) } }
DefaultSource:
package com.lcy.models.datasource import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode} import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, DataSourceRegister, RelationProvider} import org.apache.spark.sql.types.{StringType, StructField, StructType} class DefaultSource extends RelationProvider with CreatableRelationProvider with DataSourceRegister { override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String], data: DataFrame): BaseRelation = { println("xxxxx") val relation = new HBaseRelation(sqlContext, data.schema, parameters) // todo,需要主动调用insert方法,和保存不一样,保存是自动调buildScan方法 relation.insert(data,true) relation } override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = { val fields = parameters.getOrElse("fields.selecting","").split(","); val schema = new StructType( fields.map(field => { StructField(field, StringType, false) }) ) // todo,schema不能传空,哪怕后面不使用 new HBaseRelation(sqlContext,schema,parameters) } override def shortName(): String = "hbase" }
HBaseRelation:
package com.lcy.models.datasource import org.apache.hadoop.conf.Configuration import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Put, Result, Scan} import org.apache.hadoop.hbase.filter.{FilterList, SingleColumnValueFilter} import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat} import org.apache.hadoop.hbase.protobuf.ProtobufUtil import org.apache.hadoop.hbase.util.{Base64, Bytes} import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Row, SQLContext} import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan} import org.apache.spark.sql.types.StructType import scala.util.matching.Regex class HBaseRelation(sqlCxt: SQLContext, structType: StructType, parameters: Map[String, String]) extends BaseRelation with TableScan with InsertableRelation with Serializable{ val ZK_HOST_HBASE = "hbase.zookeeper.quorum" val ZK_PORT_HBASE = "hbase.zookeeper.property.clientPort" val HBASE_FAMILY ="family.name" val HBASE_ROW_KEY ="row.key.name" val HBASE_SELECT_FIELDS ="fields.selecting" val HBASE_SELECT_WHERE_CONDITIONS ="where.conditions" val HBASE_TABLE ="hbase.table" override def sqlContext: SQLContext = sqlCxt override def schema: StructType = structType implicit def toBytes(str:String) = { Bytes.toBytes(str) } override def buildScan(): RDD[Row] = { // * 创建HBaseConf对象 val conf: Configuration = HBaseConfiguration.create() conf.set(ZK_HOST_HBASE, fromParameters(ZK_HOST_HBASE)) conf.set(ZK_PORT_HBASE, fromParameters(ZK_PORT_HBASE)) conf.set(TableInputFormat.INPUT_TABLE, fromParameters(HBASE_TABLE)) // * 根据连接属性创建Scan对象 val scan = new Scan() val familyName: String = fromParameters(HBASE_FAMILY) scan.addFamily(familyName) val fieldsSelecting: String = fromParameters(HBASE_SELECT_FIELDS) val fields: Array[String] = fieldsSelecting.split(",") fields.foreach(field=>{ scan.addColumn(familyName,field) }) // * 解析where条件 val whereConditions: String = fromParameters(HBASE_SELECT_WHERE_CONDITIONS) if (whereConditions != "") { val filterList: FilterList = new FilterList val conditions: Array[String] = whereConditions.split(",") conditions.foreach(condition=>{ val conditionObj: Condition = Condition.parse(condition) filterList.addFilter(new SingleColumnValueFilter(familyName,conditionObj.field,conditionObj.op,conditionObj.value)) // todo 这里非常重要,容易忘记,filter是对查出来的结果集进行过滤,所以过滤的列必须包含在结果集中 scan.addColumn(familyName,conditionObj.field) }) scan.setFilter(filterList) } conf.set( TableInputFormat.SCAN, Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray) ) // * 调用newHadoopApi读取数据 sqlContext .sparkContext .newAPIHadoopRDD(conf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result]) // * 将读取的数据转化为RDD[Row] .mapPartitions( it=>{ it.map(res=> { Row.fromSeq( fields.map(field=>{ // todo 这里要注意,不转成字符串,会在shou时报错 Bytes.toString(res._2.getValue(familyName, field)) }) ) }) } ) } override def insert(data: DataFrame, overwrite: Boolean): Unit = { // 创建Conf对象 val conf: Configuration = HBaseConfiguration.create() conf.set(ZK_HOST_HBASE, fromParameters(ZK_HOST_HBASE)) conf.set(ZK_PORT_HBASE, fromParameters(ZK_PORT_HBASE)) conf.set(TableOutputFormat.OUTPUT_TABLE,fromParameters(HBASE_TABLE)) // 将DataFrame转换为创建RDD[(ImmutableBytesWritable, Put)],封装数据 val family: String = fromParameters(HBASE_FAMILY) val rowKey = fromParameters(HBASE_ROW_KEY) val columns: Array[String] = data.columns val putRDD: RDD[(ImmutableBytesWritable, Put)] = data.rdd.mapPartitions( it => { it.map(row => { val rowKeyValue = row.getAs[String](rowKey) val put = new Put(rowKeyValue) put.addColumn(family, rowKey, rowKeyValue) columns.map(field => { put.addColumn(family, field, row.getAs[String](field)) }) (new ImmutableBytesWritable(rowKeyValue), put) }) } ) // 使用rdd的HadoopApi写入数据 putRDD.saveAsNewAPIHadoopFile( s"datas/hbase/output-${System.nanoTime()}", // classOf[ImmutableBytesWritable], // classOf[Put], // classOf[TableOutputFormat[ImmutableBytesWritable]], // conf) } def fromParameters(key:String) = { parameters.getOrElse(key,"") } }
测试代码:
import com.lcy.models.Constants import com.lcy.models.datasource.HBaseRelation import com.lcy.models.utils.SparkUtils import org.apache.hadoop.hbase.mapred.TableInputFormat import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession} import org.junit.Test object SparkTest { val ZK_HOST_HBASE = "hbase.zookeeper.quorum" val ZK_PORT_HBASE = "hbase.zookeeper.property.clientPort" val HBASE_FAMILY ="family.name" val HBASE_ROW_KEY ="row.key.name" val HBASE_SELECT_FIELDS ="fields.selecting" val HBASE_TABLE ="hbase.table" /** * inType=hbase zkHosts=bigdata-cdh01.itcast.cn zkPort=2181 hbaseTable=tbl_users family=detail selectFieldNames=id,gender * @param args */ def main(args: Array[String]): Unit = { // 1,创建sparkSession val spark: SparkSession = SparkUtils.sparkSession(SparkUtils.sparkConf(this.getClass.getCanonicalName)) val frame: DataFrame = spark.read .format("com.lcy.models.datasource") .option(ZK_HOST_HBASE, "bigdata-cdh01.itcast.cn") .option(ZK_PORT_HBASE, 2181) .option(HBASE_TABLE, "tbl_users") .option(HBASE_FAMILY, "detail") .option(HBASE_SELECT_FIELDS, "id,gender") .option(HBASE_SELECT_WHERE_CONDITIONS,"id[ge]50") .load() frame.show() frame.write.format("hbase") .mode(SaveMode.Append) .option(ZK_HOST_HBASE, "bigdata-cdh01.itcast.cn") .option(ZK_PORT_HBASE, 2181) .option(HBASE_TABLE, "tbl_users_2") .option(HBASE_FAMILY, "detail") .option(HBASE_ROW_KEY, "id") .save() spark.stop() } }
