【转】SparkSQL sql解析
原文:
1. 背景
搞了快两年OLAP平台的开发,其中sql的解析优化通过SparkSQL完成,这里简单介绍一下原理
2. Demo
假设你已经搭建了spark,hive环境,我们这边查询下hive表,代码如下:
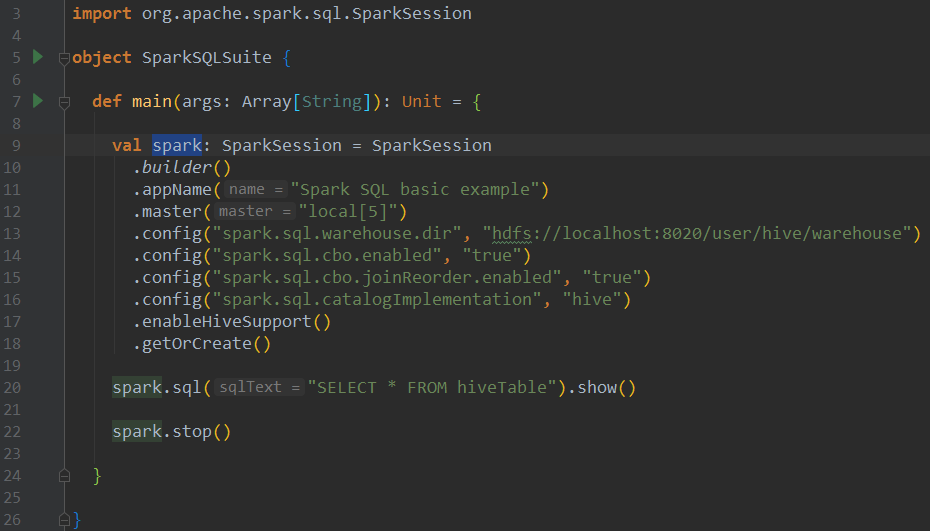
这里主要做了三件事:
1、构建SparkSession
2、执行sql构建DataFrame
3、调用show方法触发action操作,展示结果,调用queryExecution.toString则可以打印各个阶段逻辑计划
3. 流程解析
这里我们主要研究上述Demo步骤2的流程,对SparkSQL有一定了解的同学肯定知道,一条sql进来,要经历五大解析阶段:
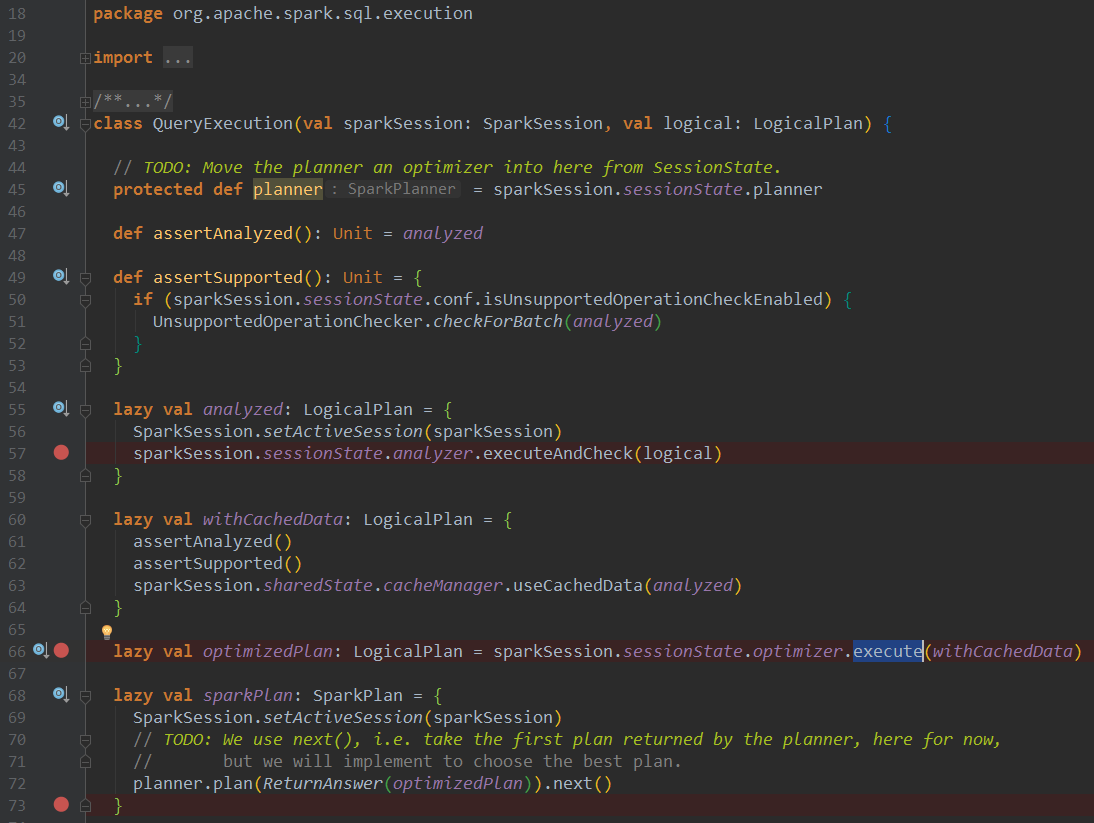
1、初步解析为Unresolved LogicalPlan
2、绑定schema信息解析为Analyzed LogicalPlan,规则见Analyzer类batches
3、结合RBO,CBO规则优化为Optimized LogicalPlan,规则见SparkOptimizer类defaultBatches
4、将Optimized LogicalPlan转化为物理计划Physical Plan,并选择可以执行的(目前选择第一个,未能实现真正意义上的CBO)
5、将可执行的Physical Plan转化为RDD[InternalRow],最终返回QueryExecution对象,并用这玩意结合schema信息构建DataFrame
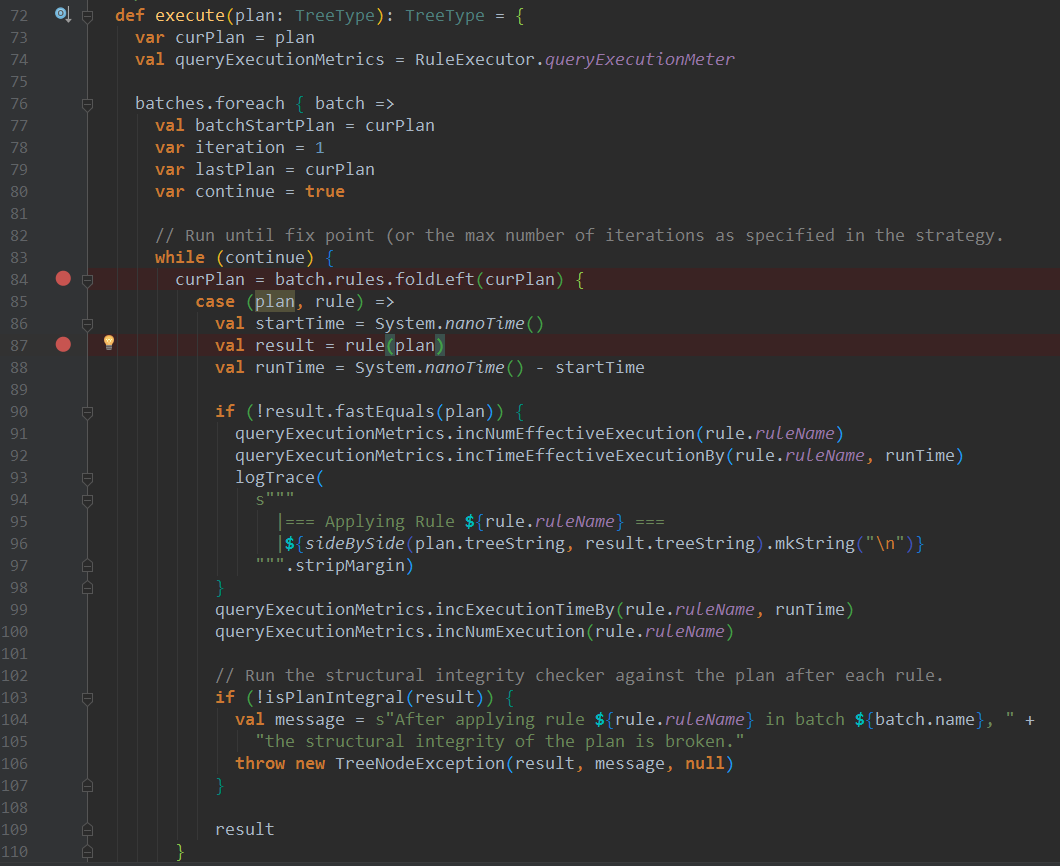
上述各个LogicalPlan的构建的执行方法均在RuleExecutor的execute方法中,对于优化阶段Optimized LogicalPlan的构建,无非是遍历一个个优化规则调用apply方法,将树形结构的LogicalPlan作为参数传入,自底向上或者自顶向下遍历,case匹配进行转换,返回新的LogicalPlan,然后作为参数应用于下一个优化规则
4. 结语
有了上述知识,咱们如果要基于SparkSQL进行OLAP平台开发,继承BaseSessionStateBuilder类, 扩展解析、优化、物理三个部分的规则即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通