【转】PostgreSQL表膨胀的前世今生
当你的数据库快速增长的时候,一定需要注意一件事,那就是“表膨胀”。内置的方法是使用VACUUM或者VACUUMFULL来解决表膨胀问题,但是有一些缺点。
[一、什么是表膨胀]
PostgreSQL使用多版本模型MVCC。实现的方法和Oracle和MySQL不同,当执行update或者是delete的时,Oracle和MySQL会在undo中维护前镜像,用于实现数据库的一致性(C)。例如一个旧事务依赖于已删除的行,此行仍然对其可见,因为它的前镜像依然保存在undo中。而Oracledba经常会遇到ORA-01555错误,这个错误就是事务需要的前镜像已经被覆盖了。
但是这种问题不会在PostgreSQL中出现,因为PostgreSQL是在自己表中维护数据过去的版本和最新的版本。这也就是说在PG的概念中,Undo是存在自己的表里。
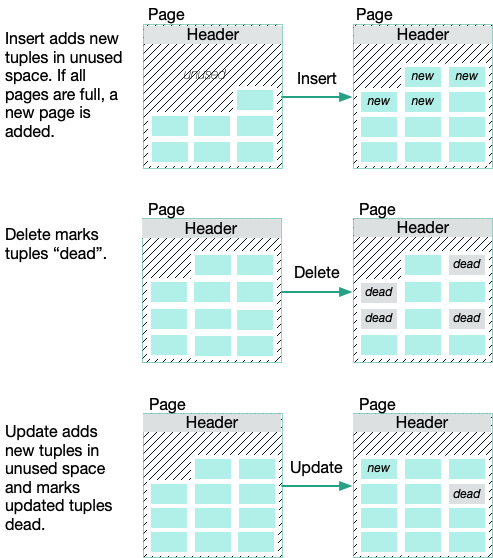
下面我们通过Greenplum的官方文档的图来说明,在PostgreSQL中磁盘存储和内存中最小管理的单位都是Page。而Page中包含Tuple(元组)。元组是一种比较学术的说法,实际上可以理解成是数据库中的行或者记录。当数据库插入一条记录的时候,就会使用page中unused的空间,新增Tuple(元组)。如果Page空间满了,就会使用新的Page。
delete操作,直接就是把元组标记为dead,并不会真正的从物理上删除。Update操作会使用unused的空间创建一个新的元组,然后把旧的数据直接标记为dead。如果这个表上很频繁的做事务,则会出现很多的deadtuple(元组),逐步堆积的deadtuple会将空间耗尽,同时当做全表扫描的时候会产生非常多的额外I/O,对查询速度产生影响。
PostgreSQL具有VACUMM功能,主要有两种方式,一种是VACUMM,另外一种是VACUMMFull。
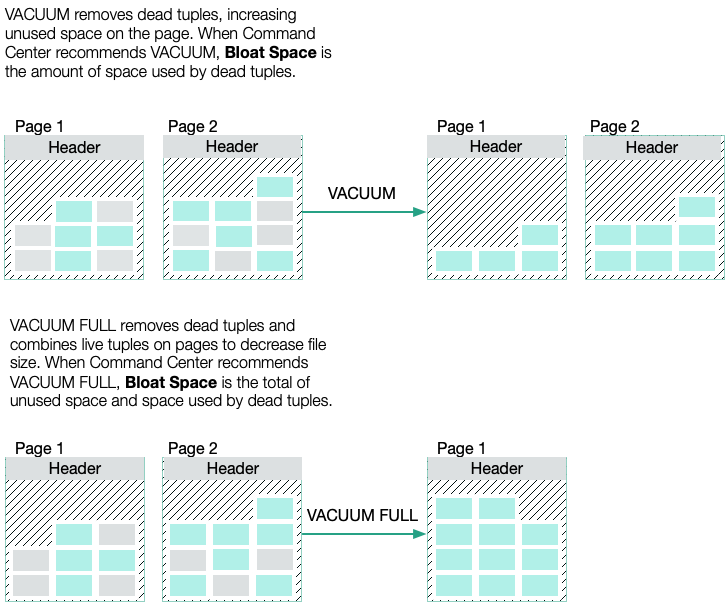
VACUMM命令可以删除deadtuple。如果删除的记录位于表的末端,其所占用的空间将会被物理释放并归还给操作系统。如果不是末端数据,VACUMM会将死元组所占用空间重置为可用状态,那么在今后有新数据插入时,将优先使用该空间,直到所有被重用的空间用完时,再考虑使用新增的磁盘页面。
而VACUMMFULL不论被删除的数据是否处于数据表的末端,这些数据所占用的空间都将被物理的释放并归还于操作系统。之后再有新数据插入时,将分配新的磁盘页面以供使用。同时,VACUMMFULL会上排他锁。当你的表很大的时候,可能会锁上几个小时,任何基于该表的操作都会挂起。
[二、观察表膨胀]
为了进一步观察表膨胀现象,可以安装pageinspect插件。
|
postgres=# create extension pageinspect; CREATE EXTENSION
create table test ( id numeric, name character varying(30) );
postgres=# insert into test select generate_series(1,10),'A'||generate_series(1,10); INSERT 0 10 postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+--------+--------------------------------- 17292510 | 0 | {"\\x0b00800100","\\x074131"} 17292510 | 0 | {"\\x0b00800200","\\x074132"} 17292510 | 0 | {"\\x0b00800300","\\x074133"} 17292510 | 0 | {"\\x0b00800400","\\x074134"} 17292510 | 0 | {"\\x0b00800500","\\x074135"} 17292510 | 0 | {"\\x0b00800600","\\x074136"} 17292510 | 0 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} (10 rows) |
这里我们创建了一个表,并插入了10行数据。这里可以看到t_xmin代表着此行版本插入的事务ID。如果我们做update或者delete,就会产生新的行版本。下面我们来删除5行记录。
|
postgres=# delete from test where id <=5; DELETE 5
postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+----------+--------------------------------- 17292510 | 17292511 | {"\\x0b00800100","\\x074131"} 17292510 | 17292511 | {"\\x0b00800200","\\x074132"} 17292510 | 17292511 | {"\\x0b00800300","\\x074133"} 17292510 | 17292511 | {"\\x0b00800400","\\x074134"} 17292510 | 17292511 | {"\\x0b00800500","\\x074135"} 17292510 | 0 | {"\\x0b00800600","\\x074136"} 17292510 | 0 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} (10 rows) |
这里可以看到,当我们删除5条记录,仍然有10条记录。而被删除的数据可以看到它的t_max事务id已经变成了删除它们的事务id。这些已经删除的记录就类似于Oracle中的undo,仍然保留在同一表中,可以提供给比t_xmax较旧的事务使用。
|
postgres=# update test set name='st' where id=6; UPDATE 1 postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+----------+--------------------------------- 17292510 | 17292511 | {"\\x0b00800100","\\x074131"} 17292510 | 17292511 | {"\\x0b00800200","\\x074132"} 17292510 | 17292511 | {"\\x0b00800300","\\x074133"} 17292510 | 17292511 | {"\\x0b00800400","\\x074134"} 17292510 | 17292511 | {"\\x0b00800500","\\x074135"} 17292510 | 17292517 | {"\\x0b00800600","\\x074136"} 17292510 | 0 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} 17292517 | 0 | {"\\x0b00800600","\\x077374"} |
如果我们做update的话,可以看到t_xmax为0的记录仍然为5条,而多出来一条t_xmax为17292517的记录。就如我们前面理论介绍的一样,update产生了新的元组,而把旧记录做为deadtuple。
接下来我们尝试使用VACUUM来清理。
|
postgres=# vacuum test; VACUUM postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+--------+--------------------------------- | | | | | | | | | | | | 17292510 | 0 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} 17292517 | 0 | {"\\x0b00800600","\\x077374"} (11 rows)
postgres=# update test set name='test' where id=7; UPDATE 1 postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+----------+----------------------------------- 17292571 | 0 | {"\\x0b00800700","\\x0b74657374"} | | | | | | | | | | 17292510 | 17292571 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} 17292517 | 0 | {"\\x0b00800600","\\x077374"} (11 rows)
postgres=# vacuum full test; VACUUM postgres=# SELECT t_xmin, t_xmax, tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); t_xmin | t_xmax | tuple_data_split ----------+----------+----------------------------------- 17292571 | 0 | {"\\x0b00800700","\\x0b74657374"} 17292510 | 17292571 | {"\\x0b00800700","\\x074137"} 17292510 | 0 | {"\\x0b00800800","\\x074138"} 17292510 | 0 | {"\\x0b00800900","\\x074139"} 17292510 | 0 | {"\\x0b00800a00","\\x09413130"} 17292517 | 0 | {"\\x0b00800600","\\x077374"} (6 rows) |
可以看到清理过后仍然有11条记录。如果现在我们再次执行update更新,这个元组是可以在重新用到的。而使用了vacuumfull命令之后,记录才下降到6条。把之前的deadtuple全部都清理了。
[三、表膨胀插件]
前面说到使用vacuum和vacuumfull的功能之后。你会发现两者都有一些缺陷。前者是不能回收空间,也就是会产生类似Oracle中的高水位的概念,而后者是能回收空间,但是会锁表,当表足够大的时候,会锁上数个小时。会导致业务长时间中断。那么有什么锁表时间短而且能回收空间的方法吗?当然,使用pg_repack和pg_squeeze插件就能解决问题。两个插件都能解决这个问题,但是使用哪个更加好呢?
pg_squeeze插件是cybertec公司贡献的,而pg_repack插件是自由软件黑客DanieleVarrazzo所主导的。两者都是C语言编写。

两者之间最大的不同就是pg_repack是通过触发器功能来实现的,在重组的时候,额外使用触发器会有一定的开销,存在一定性能上的影响。而pg_squeeze,它是建立在逻辑复制基础上的。它首先创建一个新的数据文件快照,然后使用内置复制插槽以及逻辑解码从XLOG提取对表更改的记录。然后重新构建表,构建完成之后再锁表,切换FileNode。两者实现方式不同。我个人比较倾向使用pg_squeeze插件。
插件安装较为简单。下载安装包解压,切换到postgres用户,执行make和makeinstall就安装好了。
装完后需要修改数据库参数和重启,并在数据库安装插件。
|
wal_level = logical max_replication_slots = 10 # minimum 1 shared_preload_libraries = 'pg_squeeze'
create extension pg_squeeze; |
接下来创建一个表来测试一下。
|
drop table test; create table test ( id numeric, name character varying(30) );
insert into test select generate_series(1,5000000),'A'||generate_series(1,5000000); postgres=# SELECT pg_size_pretty(pg_relation_size('test')); pg_size_pretty ---------------- 211 MB (1 row) |
当我插入500万记录的时候,表大小是211MB,现在对表做完全更新。
|
postgres=# update test set name='This is a test'; UPDATE 5000000 postgres=# select pg_size_pretty(pg_relation_size('test')); pg_size_pretty ---------------- 460 MB (1 row) |
现在全部更新完成时460MB,直接执行收缩。
|
postgres=# SELECT squeeze.squeeze_table('public', 'test', null, null, null); ERROR: Table "public"."test" has no identity index |
这里报错是表上需要主键才能执行收缩。
|
postgres=# alter table test add primary key(id); ALTER TABLE postgres=# select squeeze.squeeze_table('public', 'test', null, null, null); squeeze_table ---------------
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('test')); pg_size_pretty ---------------- 249 MB (1 row) |
重新创建主键后再次收缩,发现表大小已经从460MB下降到了249MB。回收效果还是很明显。
pg_squeeze插件还有一个比较优秀的功能就是能做成定时任务。首先我们可以把要回收的表插入到squeeze.tables表中,该表最后有一个字段叫schedule,是一种自定义的类型,通过查询squeeze.schedule的定义,可以发现和Linux中的crontab类似。
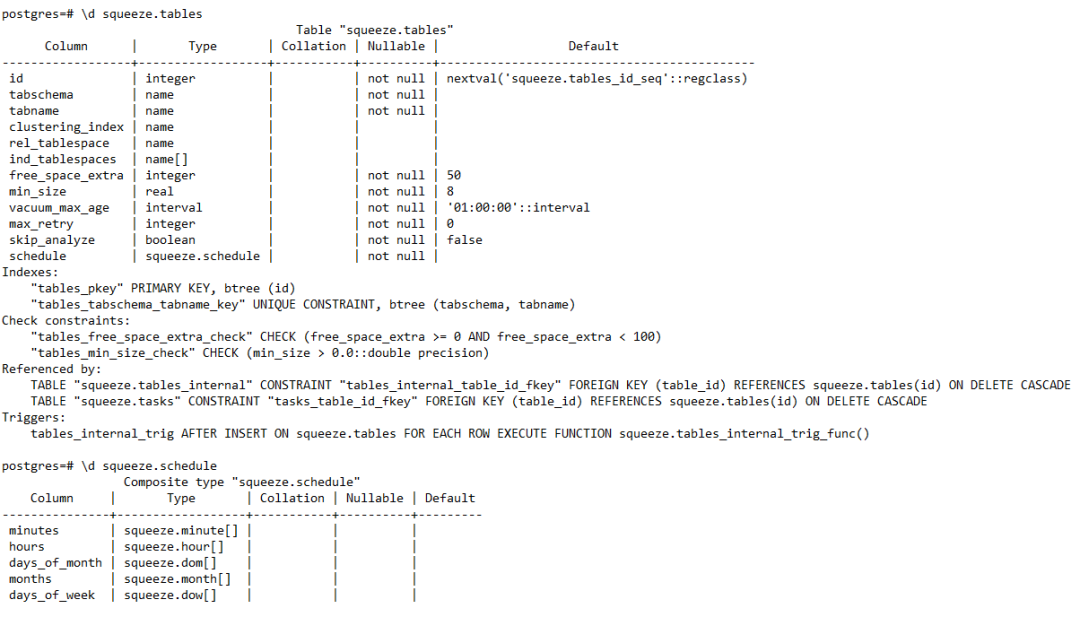

插入记录如上图所示,schedule设置为({5},{1},null,null,{6}),代表在每个周六晚上的1点05分会定时执行。
如果重组表的时候,其他用户删除表、修改表结构、或者始终无法获取短暂的排他锁、空间不足等问题都会造成重组失败。可以通过查看squeeze.errors表来定位错误。

参考文献
PG_SQUEEZE:OPTIMIZING POSTGRESQL STORAGE
https://www.cybertec-postgresql.com/en/pg_squeeze-optimizing-postgresql-storage/
Understandingof Bloat and VACUUM in PostgreSQL
https://www.percona.com/blog/2018/08/06/basic-understanding-bloat-vacuum-postgresql-mvcc/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?