计算机网络-7-4鉴别
鉴别
鉴别(authentication)是要验证通信的对方确认是自己所要进行通信的对象,而不是其他的冒充者,并且所传送的报文是完整的,没有被他人篡改过。
鉴别与授权是不同的,授权涉及的问题是:所进行的过程是否被允许(例如是否对某一个文件能够进行读或者写)。
鉴别可以分为
- 报文鉴别:鉴别所收到的报文的确是报文的发送者发送的,而不是其他人伪造篡改的。这里包含端点鉴别和保温完整性鉴别。
- 实体鉴别:仅仅鉴别发送报文的实体,实体可以是一个人,也可以是一个进程。这就是端点鉴别。
报文鉴别
密码散列函数
理论上来讲,使用数字签名签名就可以实现对报文的鉴别,然而这种方法有一个很大的缺点,就是对较长的报文进行数字签名会使计算机增加非常大的CPU时间。因此我们需要使用一种相对简单的方法对报文进行鉴别。这种方法就是使用密码散列函数(cryptographic hash function)。
散列函数具有如下两个特点:
- 散列函数的输入长度可以很长,但其输出长度则是固定的,并且较短。散列函数的输出叫做散列值,或更简单些,称为散列。
- 不同的散列值肯定对应于不同的输入,但不同的输入却可能得出相同的散列值。这就是说,散列函数的输入和输出并非一一对应的,而是多对一的。
散列函数又称之为密码散列函数,其最重要的特点是:要找到两个不同的报文,它们具有同样的密码散列函数输出,在计算上是不可行的。也就是说,密码散列函数实际上是一种单项函数(one way function)。如下图7.6
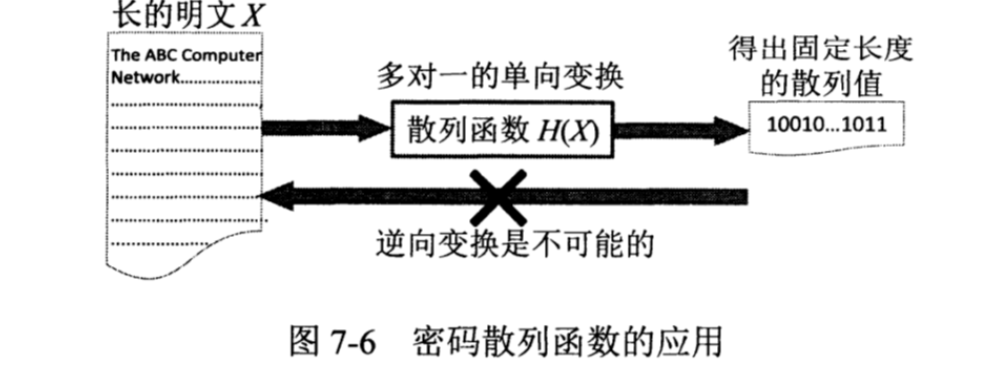
也就是说,如果我们固定长度的散列\(H(X)\)被网络拦截了,那么截获者也无法伪造出另一个明文Y,使得\(H(Y)=H(X)\),散列\(H(X)\)可以保证明文X的完整性。
实用的密码散列函数MD5和SHA-1
通过许多学者的不断努力,已经设计出一些实用的密码散列函数(或称为散列算法),其中最出名的就是 MD5 和 SHA-1。MD 就是 Message Digest 的缩写,意思是报文摘要。MD5 是报文摘要的第5个版本。
MD5算法实现大致如下:
- 先把任意长的报文按模\(2^64\)计算其余数(64位),追加在报文后面。
- 在报文和余数之间填充1-512位,使得填充后的总长度是512的整数倍。填充的首位是1,后面是0。
- 把追加和填充后的报文分割为512位的数据块,每个512位的数据块再分成4个128位的数据库再依次送到不同的散列函数进行4轮运算,每一轮又按32位但是小数据块进行复杂运算。一直到最后计算出MD5报文摘要代码。
这样得出的 MD5 报文摘要代码中的每一位都与原来报文中的每一位有关。由此可见,像MD5这样的密码散列函数实际上已是个相当复杂的算法,而不是简单的函数了。
SHA-1算法实现如下:
SHA是由美国标准与技术协会NIST提出的一个散列算法系列。SHA和MD5相似,但码长为160位(比MD5 的 128 位多了 25%)。SHA 也是用 512 位长的数据块经过复杂运算得出的。SHA比MD5更安全,但计算起来却比MD5要慢些。1995年发布的新版本SHA-1[RFC 3174]在安全性方面有了很大的改进,但后来 SHA-1 也被证明其实际安全性并未达到设计要求,并且也曾被王小云教授的研究团队攻破。虽然现在 SHA-1 仍在使用,但很快就会被另外的两个版本SHA-2和SHA-3[W-SHA3]所替代。例如,微软选择弃用SHA-1的计
报文鉴别码
下面进一步讨论在报文鉴别中怎么使用散列函数
- 用户A首先根据自己的明文X计算出散列\(H(X)\)(例如,使用MD5)。为方便起见,我们把得出的散列H(X)记为H。
- 用户A把散列H拼接在明文X后面,生成了扩展的报文(X,H),然后发送给B。
- 用户B收到了这个扩展的报文(X, H)。因为散列的长度H是早已知道的固定值,因此可以把收到的散列H和明文X分离开。B通过散列函数的运算,计算出收到的明文X的散列H(X)。若H(X)=H,则B似乎可以相信所收到的明文是A发送过来的。
像上面的做法,实际上是不可行的。设想某个入侵者创建了一个伪造的报文M,然后也同样地计算出其散列 H(M),并且冒充A把拼接有散列的扩展报文发送给B。B收到扩展的报文(M, H(M))后,按照上面步骤(3)的方法进行验证,发现一切都是正常的,就会误
认为所收到的伪造报文就是A发送的。
因此,必须设法对上述的攻击进行防范。解决的办法并不复杂,就是对散列进行一次加密。图7-7给出了这种办法的示意图。
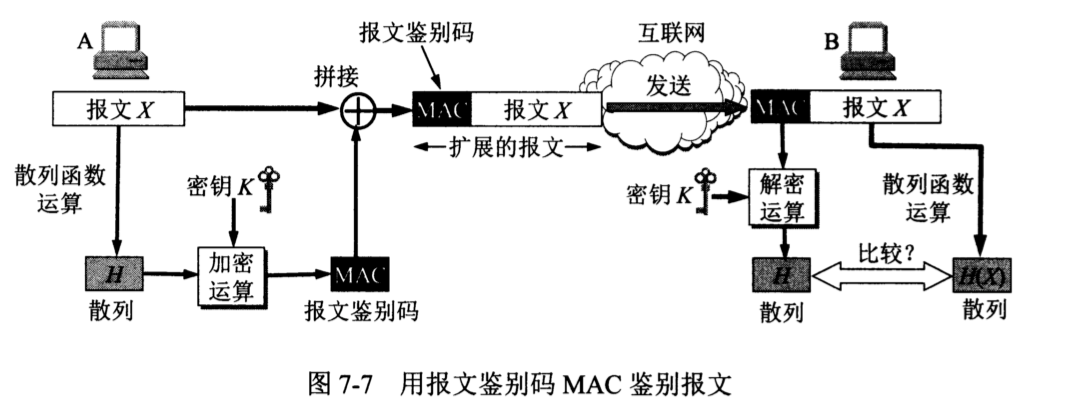
从图 7-7可以看出,在 A 从报文 X导出散列 H 后,就对散列 H 用密钥 K加密。这样得出的结果叫做报文鉴别码 MAC (Message Authentication Code)。请注意:局域网中使用的媒体接入控制 MAC 也是使用这三个字母,因此在看到MAC 时应注意上下文。
A 把已加密的报文鉴别码 MAC 拼接在报文 X的后面,得到扩展的报文,发送给 B。
B 收到扩展的报文后,先把报文鉴别码 MAC 与报文 X分离出来。然后用同样的密钥 K对收到的报文鉴别码 MAC 进行解密运算,得出加密前的散列H。再把报文 X进行散列函数运算,得出散列H(X)。最后,把计算出的散列H(X)与H进行比较。如一致,就可以相信所收到的报文 X 的确是 A 发送的。由于入侵者不掌握密钥 K,所以入侵者无法伪造 A 的报文鉴别码 MAC,因而无法伪造A发送的报文。这样就完成了对报文的鉴别。
我们可以注意到,现在整个的报文是不需要加密的。虽然从散列 H 导出报文鉴别码MAC 需要加密算法,但由于散列H的长度通常都远远小于报文X的长度,因此这种加密不会消耗很多的计算资源。这样,使用鉴别码 MAC 就能够很方便地保护报文的完整性。
现在已经有好几个不同的MAC标准,而使用最广泛的是HMAC,它和MD5、SHA-1一起使用。
实体鉴别
实体鉴别与报文鉴别不同,报文鉴别是对每一个收到的报文都要鉴别报文的发送者,而实体鉴别是在系统接入的持续时间内对和自己通信的对方实体只需验证一次。
最简单的实体鉴别过程如图 7-8 所示。A 向远端的 B 发送带有自己身份 A(例如,A 的姓名)和口令的报文,并且使用双方约定好的共享对称密钥 KAB进行加密。B 收到此报文后,用共享对称密钥 KAB进行解密,从而鉴别了实体A的身份。
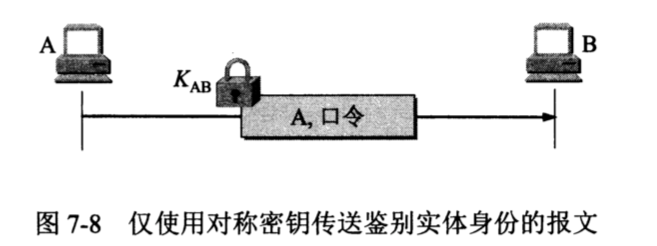
然而这种简单的鉴别方法具有明显的漏洞。例如,入侵者C可以从网络上截获A发给B的报文,C并不需要破译这个报文(因为这可能得花很长时间),而是直接把这个由 A 加密的报文发送给B,使B误认为C就是A;然后B就向伪装成A的C发送许多本来应当发给A的报文。这就叫做重放攻击(replay attack)。C甚至还可以截获A的IP地址,然后把A的IP地址冒充为自己的IP地址(这叫做 IP 欺骗),使B更加容易受骗。
为了对付重放攻击,可以使用不重数(nonce)。不重数就是一个不重复使用的大随机数,即“一次一数”。在鉴别过程中不重数可以使 B 能够把重复的鉴别请求和新的鉴别请求区分开。图7-9给出了这个过程。
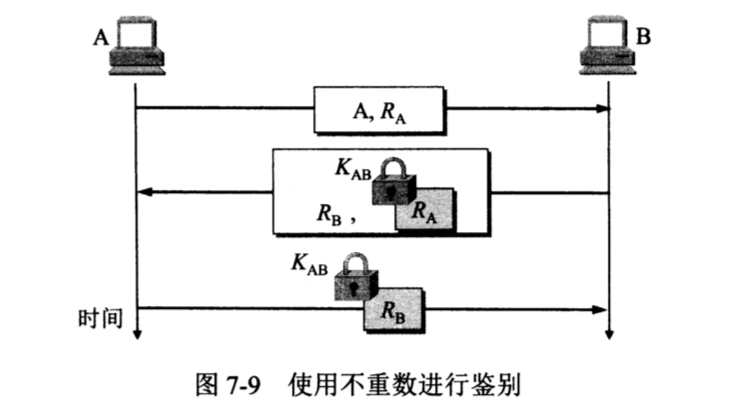
在图 7-9 中,A首先用明文发送其身份A和一个不重数R给B。接着,B响应A的查问,用共享的密钥\(K){AB}\)对\(R_A\)加密后发回给A,同时也给出了自己的不重数\(R_B\)。最后,A再响应B的查问,用共享的密钥\(K_{AB}\)对\(R_B\)加密后发回给B。这里很重要的一点是A和B对不同的会话必须使用不同的不重数集。由于不重数不能重复使用,所以C在进行重放攻击时无法重复使用所截获的不重数。
在使用公钥密码体制时,可以对不重数进行签名鉴别。例如在图7-9中,B用其私钥对不重数\(R_A\)进行签名后发回给A。A用B的公钥核实签名,如能得出自己原来发送的不重数\(R_A\),就核实了和自己通信的对方的确是B。同样,A也用自己的私钥对不重数 \(R_B\)进行签名后发送给B。B用A的公钥核实签名,鉴别了A的身份。
中间人攻击:
如图7-10
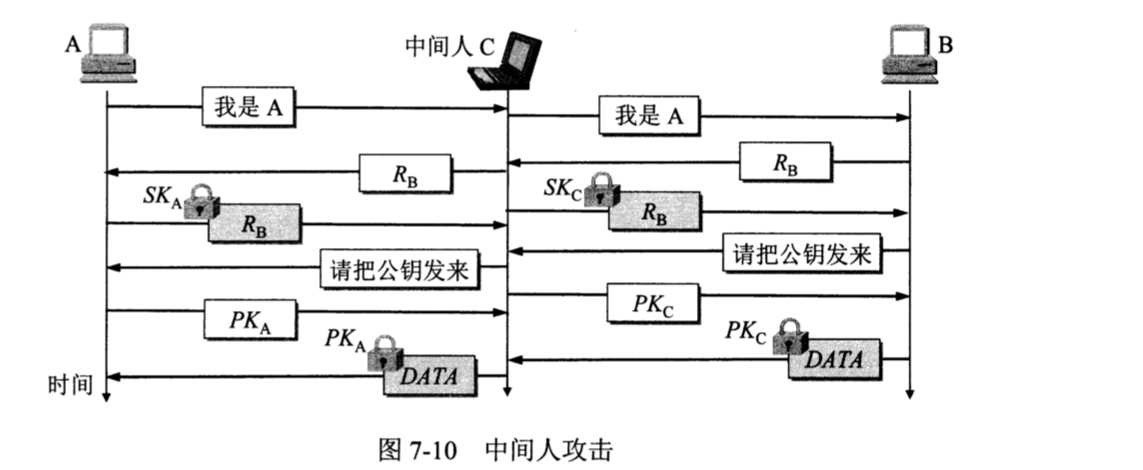
从图7-10可看出,A想和B通信,向B发送“我是A”的报文,并给出了自己的身份。这个报文被“中间人”C截获,C把这个报文原封不动地转发给B。B选择一个不重数\(R_B\)发送给A,但同样被C截获后也照样转发给A。
中间人C用自己的私钥\(SK_C\)对\(R_B\)加密后发回给B,使B误以为是A发来的。A收到RB后也用自己的私钥\(SK_A\)对 RB加密后发回给B,但中途被C截获并丢弃。B向A索取其公钥,这个报文被C截获后转发给A。
C把自己的公钥\(PK_C\)冒充是A的公钥发送给B,而C也截获到A发送给B的公钥\(PK_A\)。
B用收到的公钥\(PK_C\)(以为是A的)对数据DATA加密,并发送给A。C截获后用自己的私钥\(SK_C\)解密,复制一份留下,然后再用A的公钥\(PK_A\)对数据DATA加密后发送给A。A收到数据后,用自己的私钥\(SK\)解密,以为和B进行了保密通信。其实,B发送给A的加密数据已被中间人C截获并解密了一份,但A和B都不知道。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号