
第一次个人编程作业
编程任务
- 附上github的链接:https://github.com/Lilychannel/soft_homwork
- 计算模块接口的设计与实现过程
- 计算模块接口部分的性能改进
- 计算模块部分单元测试展示
一、计算模块接口的设计与实现过程
首先让我们简单概括一下题目,论文查重——等价于输出两个给定样本之间的重复率。我们马上想到的是就是转化估算不同样本之间的相似性度量(Similarity Measurement),如何表示两个样本的差距,通常我们会采用的方法就是计算样本间的“距离”(Distance)。在计算机中,常见的距离有很多种,一些常见的距离测度有欧氏距离、jaccard距离、余弦距离、编辑距离、海明距离等,再有了这么大概的一个思路后,第一步要做的就是先确定一下整个算法的框架:
可以清楚的大概将这个问题分成三个部分:预处理,转换计算,输出
 列出大概的框架,再逐步去完成每个小功能
列出大概的框架,再逐步去完成每个小功能
一、预处理
预处理的目的是将提供的文本文件转化成我们能够进行计算的形式
在查阅资料后了解,对文档进行预处理,最平常不过的就是对文档进行分词,python中有着强大的“jieba”包,能够完成对一篇文档的分词以及关键词的提取,这里我使用了jieba.cut与jieba.analyse.extract_tags进行结合来对需要测试的文本进行处理,简单介绍一下这两个方法:
word = jieba.cut(str, cut_all=True, HMM=True)
- 第一个参数为需要分词的字符串
- 第二个 cut_all 参数用来控制是否采用全模式
- 第三个 HMM 参数用来控制是否使用 HMM 模型
keywords = jieba.analyse.extract_tags(content, topK=5, withWeight=True, allowPOS=())
- 第一个参数:待提取关键词的文本
- 第二个参数topK:返回关键词的数量,重要性从高到低排序(在此次实验中我取了250,可以根据文本的大小来决定这个数字)
- 第三个参数withWeight:是否同时返回每个关键词的权重
- 第四个allowPOS:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
经过分词后输出两个列表(这里的输出之前还对标点符号做了过滤,具体的将在性能改进提出)

分别得到250个关键词之后,现在就可以转入下一步工作啦!
二、计算距离
前面提到一些常见的距离测度有欧氏距离、jaccard距离、余弦距离、编辑距离、海明距离等,但是这些方法都普遍存在一个弊端,就是无法将其扩展到海量数据,在查找相关资料的时候,突然发现了一个对海量数据查重的方法——最小哈希法(虽然用在这次作业仅对两个文档进行查重,有点大材小用,但是基于本人是大数据的,对海量数据这类名词较敏感,就趁此机会学习一下啦!)
简单的讲解一下我理解的MinHash
1.首先要理解MinHash的前提知道最基础的Jaccard相似性系数,公式如下
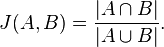
简单来说就是A与B所共有元素的个数/A与B元素之和
2.我们知道两个文档的Jaccard相似度的计算需要用到文档和单词,而MinHash同样也要用到文档和单词,将文档doc1,doc2作为列,单词作为行,这样我们可以获得一张列表,为了方便表达,这张表中用1,2,3,4表达:

如图所示,顺序1234代表单词,如果doc中有该单词就是1,否则为0,MinHash则将原来的“顺序”1234随机变成2314,随之表中0,1的位置也会随之改变,所谓的行号却并没有发生变化,变化的是矩阵的内容。我们再找到排在最前面的1所在的行号来代表这个文档,得到:
doc1=1,doc2=2
那么doc1和doc2的相似度=doc1和doc2相同的代表行号数)/(能够表示doc1和doc2的代表行号的种类)=0/2
这里你可能会有三个疑问:
> 一是仅用一个单词代表一个文档的准确率未免太低了
>二是怎么做到“随机排序”
>三是如果每次都靠变换矩阵的内容,那么在数据量大的情况下效率仍是低下的
MinHash算法主要根据以上三个方面的问题给出了改进方法:
进行多次随机的变换,取出多个单词来进行比较:我们知道(刚刚知道)hash函数能够随机产生行号的顺序,根据定义的hash函数遍历doc矩阵中的值,对值为0的跳过。对1的,计算出hash函数产生的行号,将行号最小的值作为hash函数输出的值,最后根据多个hash函数输出的值,获得hash函数表,例如:
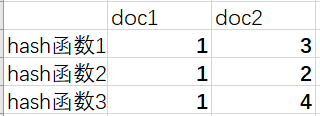
其中行排列的minhash值相等的个数为0,而共有4中代表行号的种类,那么doc1和doc2的相似度=0/4=0
(以上是我自己的理解,如果有偏差的话,求指正!!!)
综上,MinHash的原理就是利用两个集合的随机的一个行排列的minhash值相等的概率和两个集合的Jaccard相似度相等
讲这么多,怎么实现呢? python有相应的模块(很简单嘻嘻)
from datasketch import MinHash
放出实现函数的部分代码:
def main(self):
# MinHash计算
text1, text2 = MinHash(), MinHash()
# 提取关键词
orig_1 = self.extract_keyword(self.orig_1)
text_2 = self.extract_keyword(self.text_2)
for data in orig_1:
text1.update(data.encode('utf8'))#字典s1的键/值对更新到m1里面
for data in text_2:
text2.update(data.encode('utf8'))#字典s2的键/值对更新到m2里面
return text2.jaccard(text1) #返回相似度
三、输入输出以及组装
这个步骤就很简单了吧!!!就是将算出来的文件写入指定的文档中,因为作业要求接受命令行参数,所以引用了sys,不多说,直接见代码:
import sys
orig, com, ans = sys.argv[1:]
orig_text=r''+orig #转义符失效
com_text=r''+com
ans_text=r''+ans
with open(orig_text, 'r',encoding='UTF-8') as x, open(com_text, 'r',encoding='UTF-8') as y:
orig_doc = x.read()
text_doc = y.read()
similarity = MinHashSimilarity(orig_doc, text_doc)
similarity = similarity.main()
f=open(ans_text,"a")
f.write(str(round(similarity,2)))
f.close()
print('相似度: %.2f%%' % (similarity*100))
将三个功能组合起来就是涉及函数的调用啦,原代码在guithub中自取~~
二、计算模块接口部分的性能改进
不知道为啥安装PyCharm一直失败,为了赶上进度,所以我只能先基于自己原先的思路,查找资料先完善一下自己的整个代码的功能块
比如文本中如果仅仅只是用jieba分词,那么查看分词结果的时候,就会发现文本中许多转义符也会被算成一个字符在内,如下

如果选择这样分词,在接下来的运算会浪费较多资源,为了改善这个问题,引入了re正则包和html包,对文档中的转义符进行过滤(这里的过滤就是把转义符的位置换成空格,之后jieba进行切割分词)
实现的代码如下:
def extract_keyword(content): # 提取关键词
# 正则过滤html标签
re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S)
#编译成正则表达式对象
content = re_exp.sub(' ', content)
#使用空格替换所有正则表达式字符串中出现的位置
content = html.unescape(content)
# 切割
words= [i for i in jieba.cut(content, cut_all=True) if i != '']
print(words)
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(words), topK=200, withWeight=False)
return keywords
其实为了更精确,应该去除停用词,以及一些语气词,由于上交的代码不允许打开其他文件就放弃了
做完这些后,我感觉自己已经黔驴技穷了,经过我一番努力,终于PyCharm安装成功,使用自带的“Profile”生成性能分析表(借鉴大佬的办法)

整个文件的运行时间为:
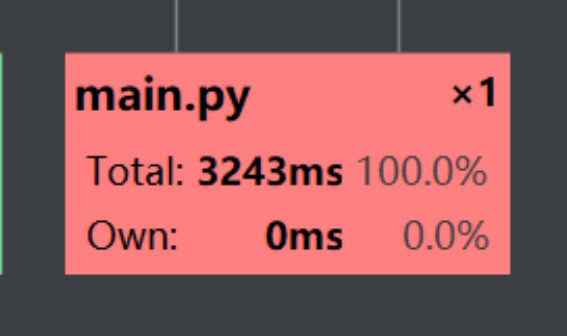
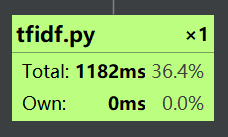
其中占用时间最长的是tfidf模块:
三、计算模块部分单元测试展示
进行到这一步的时候真的一脸懵逼,还好有我漂亮的舍友相助,最后选用了Unittest来进行测试运行,这里使用仅样本所提供的10份文件
部分测试的代码如下:
import unittest
import My_test
from BeautifulReport import BeautifulReport
class make_all_text(unittest.TestCase):
def test_self(self):
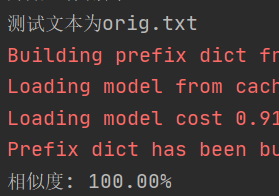
print("测试文本为orig.txt")
My_test.test_work('orig.txt', 'orig.txt', 'ans.txt')
if __name__ == '__main__':
print("开始进行测试……")
suite = unittest.TestSuite()
suite.addTest(make_all_text('test_self'))
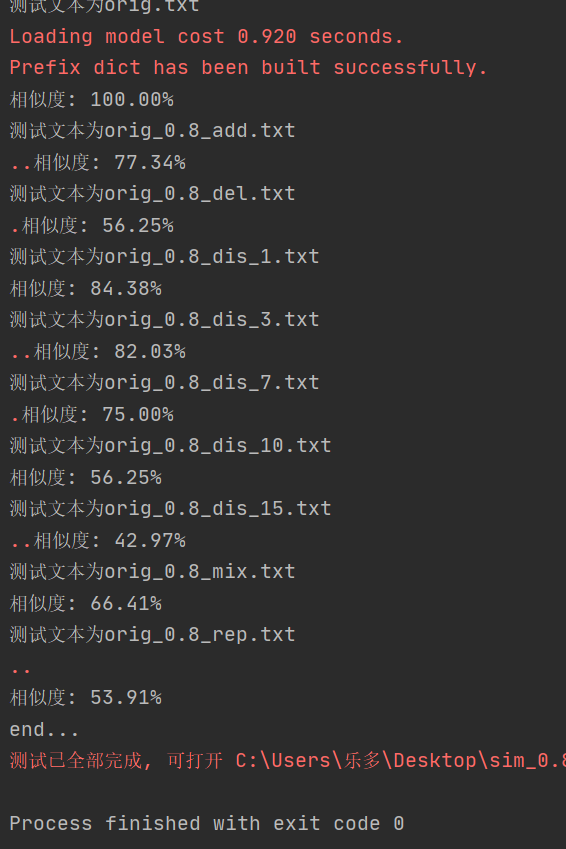
得到输出:
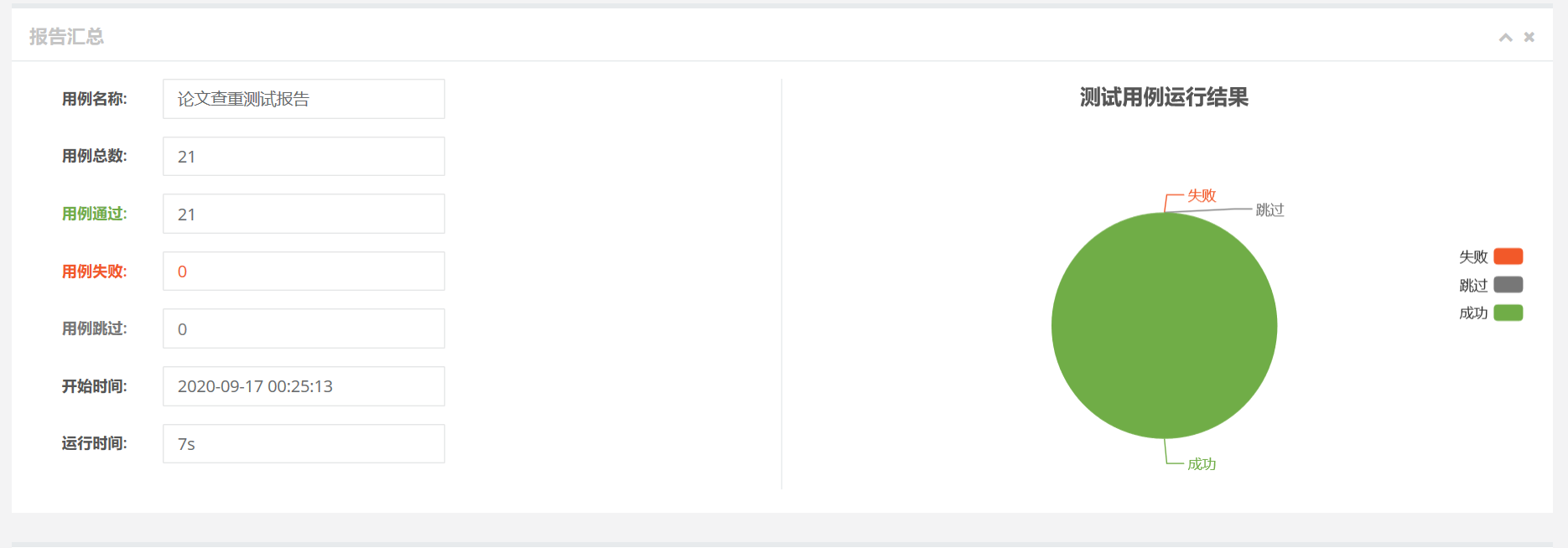
单元测试覆盖率截图如下:
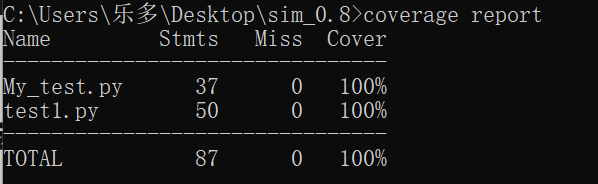
看到结果覆盖率100%,我是震惊的(过于“完美”?),也可能是我的代码数量比较少,所以覆盖率高吧(这个测试的代码还没有异常处理)。。。
补充:
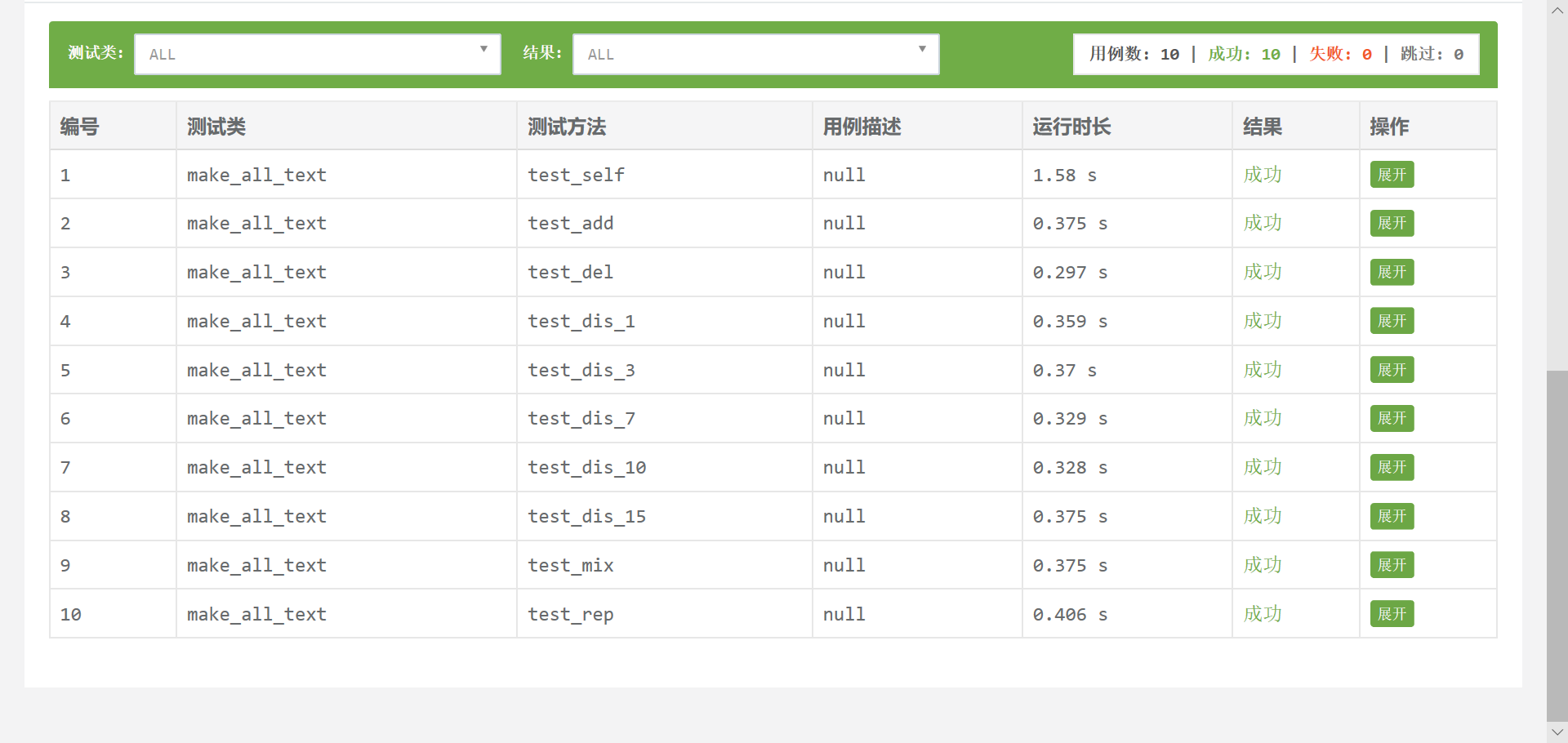
为了整个测试的完整性,我又自己新增设了11个样本,分别是根据原文进行增删改等操作,还放了英文文本,结果如下:
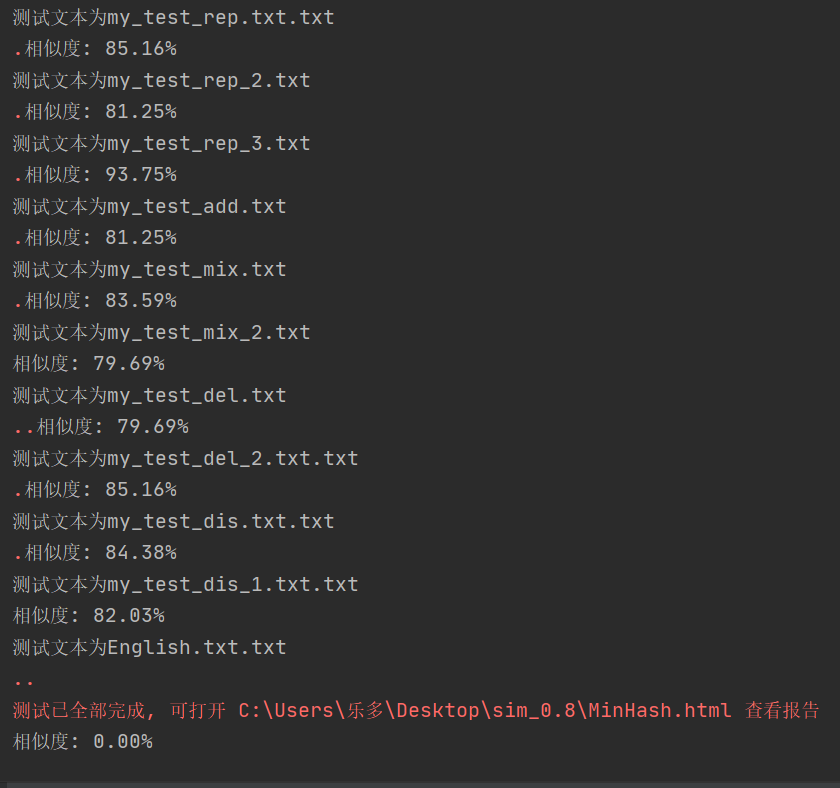
总的测试报告:
四、计算模块部分异常处理说明三、输入输出以及组装
很好,到了这一步我还是一脸懵逼,思想还停留在小学生水平——心里就想着我的编译都没报错还要异常处理?好吧,在参考了其他同学的优秀想法后,知道了要对代码中可能出现的异常情况进行分析,大概有两种种
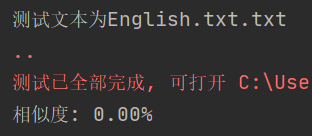
- 测试的文本没有中文,相似率可能不是0
- 测试文本跟原文不同,相似率是100%
针对以上两种情况,我又新增了测试了English文本,以及跟原文本比较,幸好答案都是符合期待的
接下来可能出现的异常就在读取文件跟计算jaccard相似度了,于是我新增了以下的异常处理:
try:
with open(orig_text, 'r', encoding='UTF-8') as x, open(com_text, 'r', encoding='UTF-8') as y:
orig_doc = x.read()
text_doc = y.read()
except Exception as e:
print(e)
try:
f = open(ans_text, "a")
f.write(str(round(similarity, 2)))
f.close()
except Exception as e:
print(e)
try:
return text2.jaccard(text1) # 返回相似度
except Exception as err:
print(err)
return 0.0
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 70 |
| · Estimate | · 估计这个任务需要多少时间 | 1500 | 1600 |
| Development | 开发 | 240 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 300 |
| Design Spec | 生成设计文档 | 120 | 60 |
| Design Review | 设计复审 | 120 | 70 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 45 |
| Design | 具体设计 | 180 | 200 |
| Coding | 具体编码 | 480 | 360 |
| Code Review | 代码复审 | 120 | 100 |
| Test | 测试(自我测试,修改代码,提交代码) | 180 | 360 |
| Reporting | 报告 | 240 | 300 |
| Test Repor | 测试报告 | 450 | 120 |
| Size Measurement | 计算工作量 | 140 | 120 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程的改进计划 | 60 | 45 |
| 合计 | 4130 | 4050 |
六、总结
- 这次的作业,让我深刻的意识到面对同一个作业大佬跟菜鸡的成果差距有多大,也知道了原来写代码之前跟写代码之后还有这么多的任务(爆哭)
- 在写代码编译通过后,并不意味着结束,还要从多个角度去找到可能出现的异常,以及做到在别人给的样例之外,自己编写样例进行测试。
- 写代码很难,写测试更难!
- 一个好的算法背后离不开为它服务的n多个插件
参考资料
1.minHash最小哈希原理
2.https://blog.csdn.net/minzhung/article/details/102993769
3.https://www.sohu.com/a/343710179_120104204

