并发和竞态
(一)基本概念
对并发的管理是操作系统编程领域中的核心问题之一。
设备驱动程序开发者必须在开始设计时就考虑到并发因素,并对内核提供的并发管理机制有深刻的认识。
竞态:竞争状态;
引发竞态的原因是:并发式访问同一共享资源:
①多线程并发访问;
②抢占式并发访问;
③中断程序并发访问;
④SMP(Symmetric Multi-Processing)核间并发访问;
竞态造成的影响:处于竞态中的任务,所获得资源与预期不符,从而产生非预期的结果。
设计驱动程序的规则:
①尽可能避免资源共享,最明显的应用就是避免使用全局变量;
②在单个执行线程之外共享硬件或者软件资源的任何时候,必须显式地管理对该资源的访问,确保一次只有一个执行线程可操作共享资源;
③当内核代码创建了一个可能和内核的其他部分共享的对象时,该对象必须在还有其他组件引用自己时保持存在并正确工作;在对象还不能正确工作时,不能将其对内核可用;
(二)信号量和互斥体
信号量分为:计数型信号量和二值信号量,二值信号量也称作互斥体。
目的:建立临界区,确保在任意时刻,临界区只被一个任务访问。
一个信号量的本质就是一个整数,它和一对函数联合使用,这对函数通常被称为P和V。
Linux内核中几乎所有的信号量均用户互斥。(因此,只要知道,计数型信号量的原理与停车场相似即可。)
如果在拥有一个信号量时发生错误,必须在将错误状态返回给调用者前释放该信号量。
信号的机制会使等待信号量的任务进入休眠,因此:
①信号量适用于占用资源比较久的场合(资源占用时间短,频繁切换任务引起的开销远大于信号量带来的优势);
②信号量不可用于中断(中断不能休眠);
Linux信号量的实现
.\linux-2.6.22.6_vscode\include\asm-avr32\semaphore.h
声明和初始化一个互斥体:
(静态)
1 #define DECLARE_MUTEX(name) __DECLARE_SEMAPHORE_GENERIC(name,1)
2 #define DECLARE_MUTEX_LOCKED(name) __DECLARE_SEMAPHORE_GENERIC(name,0)
(动态)
1 void init_MUTEX (struct semaphore *sem);
2 void init_MUTEX_LOCKED (struct semaphore *sem);
申请信号量:
1 /*
2 * This is ugly, but we want the default case to fall through.
3 * "__down_failed" is a special asm handler that calls the C
4 * routine that actually waits. See arch/i386/kernel/semaphore.c
5 */
6 static inline void down(struct semaphore * sem);
7
8
9 /*
10 * Interruptible try to acquire a semaphore. If we obtained
11 * it, return zero. If we were interrupted, returns -EINTR
12 */
13 static inline int down_interruptible(struct semaphore * sem);
14
15
16 /*
17 * Non-blockingly attempt to down() a semaphore.
18 * Returns zero if we acquired it
19 */
20 static inline int down_trylock(struct semaphore * sem);
释放信号量:
1 /*
2 * Note! This is subtle. We jump to wake people up only if
3 * the semaphore was negative (== somebody was waiting on it).
4 * The default case (no contention) will result in NO
5 * jumps for both down() and up().
6 */
7 static inline void up(struct semaphore * sem);
读取者/写入者信号量
.\linux-2.6.22.6_vscode\include\linux\rwsem.h
使用情景:很少需要写访问,并且写入者只会短期拥有信号量(避免读取者"饿死")。
1 /*
2 * lock for reading
3 */
4 extern void down_read(struct rw_semaphore *sem);
5
6 /*
7 * trylock for reading -- returns 1 if successful, 0 if contention
8 */
9 extern int down_read_trylock(struct rw_semaphore *sem);
10
11 /*
12 * lock for writing
13 */
14 extern void down_write(struct rw_semaphore *sem);
15
16 /*
17 * trylock for writing -- returns 1 if successful, 0 if contention
18 */
19 extern int down_write_trylock(struct rw_semaphore *sem);
20
21 /*
22 * release a read lock
23 */
24 extern void up_read(struct rw_semaphore *sem);
25
26 /*
27 * release a write lock
28 */
29 extern void up_write(struct rw_semaphore *sem);
30
31 /*
32 * downgrade write lock to read lock
33 */
34 extern void downgrade_write(struct rw_semaphore *sem);
(三)Completion
内核编程的一种常见模式是,在当前线程之外初始化某个活动,然后等待该活动的结束。
(轻量级机制,允许一个线程告诉另一个线程某个工作已完成。)
典型应用:模块退出时,内核线程终止。
.\linux-2.6.22.6_vscode\include\linux\completion.h
声明和初始化Completion:
(静态)
1 #define DECLARE_COMPLETION(work) \
2 struct completion work = COMPLETION_INITIALIZER(work)
(动态)
1 static inline void init_completion(struct completion *x);
等待Completion事件:
1 extern void FASTCALL(wait_for_completion(struct completion *));
2 extern int FASTCALL(wait_for_completion_interruptible(struct completion *x));
3 extern unsigned long FASTCALL(wait_for_completion_timeout(struct completion *x,
4 unsigned long timeout));
5 extern unsigned long FASTCALL(wait_for_completion_interruptible_timeout(
6 struct completion *x, unsigned long timeout));
发出Completion事件:
1 extern void FASTCALL(complete(struct completion *));
2 extern void FASTCALL(complete_all(struct completion *));
如果发出的事件是complete_all事件,那么这个complete在被使用后丢弃,如需继续使用,在发出下个事件前,需要重新初始化:
1 #define INIT_COMPLETION(x) ((x).done = 0)
(四)自旋锁
自旋锁可以在不能休眠的进程中使用,比如中断处理例程。
自旋锁是一个互斥设备。
自旋锁最初是为了在多处理器系统上使用而设计的。
"自旋":等待自旋锁的进程进入忙循环并重复检查这个锁,直到该锁可用为止。
必须遵守的规则:
①任何拥有自旋锁的代码都必须是原子的。
②任何拥有自旋锁的代码不能休眠。
③在拥有自旋锁时禁止中断(仅在本地CPU上)。
.\linux-2.6.22.6_vscode\include\linux\spinlock.h
初始化自旋锁:
(静态)
1 /*
2 * SPIN_LOCK_UNLOCKED and RW_LOCK_UNLOCKED defeat lockdep state tracking and
3 * are hence deprecated.
4 * Please use DEFINE_SPINLOCK()/DEFINE_RWLOCK() or
5 * __SPIN_LOCK_UNLOCKED()/__RW_LOCK_UNLOCKED() as appropriate.
6 */
7 #define SPIN_LOCK_UNLOCKED __SPIN_LOCK_UNLOCKED(old_style_spin_init)
8 #define RW_LOCK_UNLOCKED __RW_LOCK_UNLOCKED(old_style_rw_init)
9
10 #define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)
11 #define DEFINE_RWLOCK(x) rwlock_t x = __RW_LOCK_UNLOCKED(x)
(动态)
1 spin_lock_init(spinlock_t *lock);
申请锁资源:
1 spin_lock(spinlock_t *lock);
1 spin_lock_irq(spinlock_t *lock);
2 spin_lock_irqsave(spinlock_t *lock, flags); //flags:irq flag
3 spin_lock_bh(spinlock_t *lock);
非阻塞式申请:
1 spin_trylock(spinlock_t *lock);
2 spin_trylock_bh(spinlock_t *lock);
3 spin_trylock_irq(spinlock_t *lock);
4 spin_trylock_irqsave(spinlock_t *lock, flags);
释放锁资源:
1 spin_unlock(spinlock_t *lock);
2 spin_unlock_irq(spinlock_t *lock);
3 spin_unlock_irqrestore(spinlock_t *lock, flags);
4 spin_unlock_bh(spinlock_t *lock);
读取者/写入者锁
这种锁允许任意数量的读取者同时进入临界区,但是写入者必须互斥访问。
与resem类似,避免读取者"饥饿"。
接口请看:
.\linux-2.6.22.6_vscode\include\linux\spinlock.h
(五)锁陷阱——针对前面的小节
如果某个获得锁的函数要调用其他同样尝试获取这个锁的函数,我们的代码就会死锁。
无论是信号量还是自旋锁,都不允许锁拥有者第二次获得这个锁,如果试图这么做,系统将挂起。
提供给外部调用的函数,必须显式地处理锁定。
在必须获取多个锁时,应该始终以相同的顺序获得;这里的相同顺序是指所有进程获得锁的顺序应该统一;避免死锁。
如果我们必须获得一个局本锁(比如一个设备锁),以及一个属于内核更中心位置的锁,则首先获取自己的局部锁。
最好的办法就是,避免出现需要多个锁的情况。
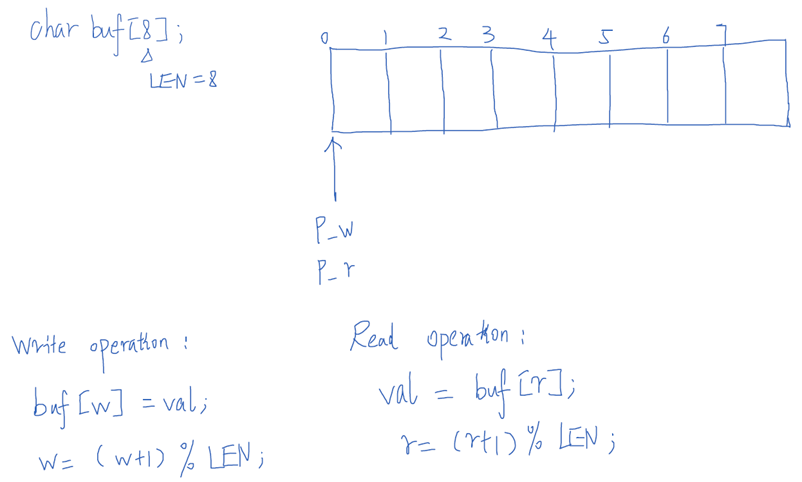
(六)循环缓冲区(circular buffer)
目的:从根本上避免使用锁,避免竞态。
要求:写入者看到的数据结构始终和读取者看到的保持一致。
实现:构造一个环形缓冲区:一个数组、两个指针(一个记录读、一个记录写)。
只要写入者在更新写入索引值之前,将新的值保存到缓冲区,则读取者将始终看到一致的数据结构(注意重叠、超前等问题)。
(七)原子变量
针对共享资源是一个整数的情形,为了节省开销,内核提供了一种原子的整数类型,称为atomic_t。
atomic_t变量中不能记录大于24位的整数。
.\linux-2.6.22.6_vscode\include\asm-arm\atomic.h
(八)位操作
为了实现位操作,内核提供了一组可原子地修改和测试单个位地函数。
不幸的是,这些函数依赖于具体的架构。
使用位操作来管理一个锁变量以控制对某个共享变量的访问,则相对复杂并值得讨论。
.\linux-2.6.22.6_vscode\include\asm-arm\bitops.h
(九)顺序锁—— seqlock
提供对共享资源的快速、免锁访问。
使用场景:受保护的资源——很小、很简单、会频繁的地被使用、写入访问很少发生并且必须快速时,可以使用seqlock。
seqlock会允许读取者对资源的自由访问,到要求读取者检查是否和写入者发生冲突,当这种冲突发生时,就需要重试对资源的访问。
seqlock通常不能用于保护包含有指针的结构数据。
读取访问通过获得一个(无符号的)整数顺序值而进入临界区;在退出时,该顺序值会和当前值比较;如果不相等,则必须重试读取访问。
.\linux-2.6.22.6_vscode\include\linux\seqlock.h
(十)读取-复制-更新(Read-Copy-Updata,RCU)
高级的互斥机制。
很少在驱动程序中使用,但是很知名,因此我们必须有基本的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号