RDBMS Optimizer概览.18653036
SQL的出现让我们得以用一种高级的声明式接口来与数据库交互,但在这之下,数据库的优化器做了大量的复杂工作来让SQL的执行尽量地快。
优化器处理什么问题
对于用户的一条SQL:
- 有大量等价的逻辑查询树
- 对于逻辑查询树上的每一个节点(或者说操作符),底层执行引擎可能有多种物理实现方式。如对于join,可能有嵌套循环、排序归并、hashjoin等算法
- 考虑各种逻辑和物理情况后,给出优化器认为最优的一种
所以一言蔽之,优化器本质是一个针对指定SQL,在与其等价的一批物理和逻辑实现方案不同的执行计划搜索空间上的一个搜索算法。
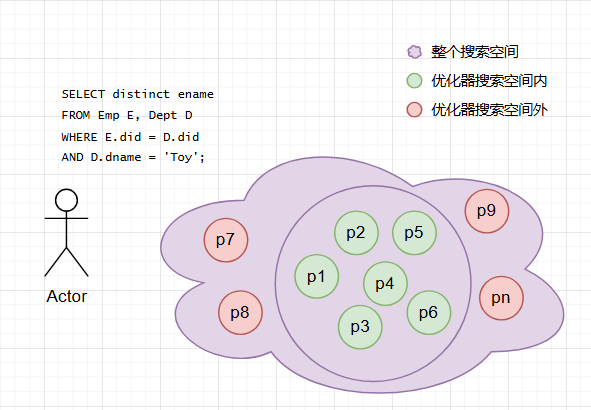
其难点在于:
- 优化器的目标是快和准,即给它的时间是很少的,但对它精确性的要求是极高的
- 优化器的搜索空间特别大,尤其是对于join,会使搜索空间指数级增长到几乎不可能完成,所以各家优化器都会舍弃搜索空间中的很多方案,将搜索空间缩小在一个小的优质范围中
考虑
N个join的查询,可选的连接方式有N!个 - 在未执行具体计划前就知道计划的成本是一个NP Hard问题,所以只能找近似解
- 如何面对大量的逻辑计划和逻辑计划中不同的物理计划?
- 简单方式:先确定一个最优逻辑计划,再找到该逻辑计划下全部物理计划中最优的那个(两个局部最优不一定全局最优)
- 逻辑计划物理计划一同考虑
SPJ的概念:SPJ即由选择、投影、Join组成的查询,是优化器领域主要研究的对象。SPJ由k个Join子句组成,当k=1时,SPJ就是一个简单的单表查询。
优化器常用的两种手段
本小节不会介绍优化器的实现细节,比如,如何遍历搜索空间?我们该如何挑选要进行搜索的子空间?本节只是介绍优化器实现的两种通用技术。
关系代数的等价变换
关系型数据库是基于关系-元组的,在其之上发展出了一套关系代数理论。
与数学上的代数是一样的,关系代数也有各种交换律、结合律等,举个简单的例子,A join B join C和A join (C join B)、B join A join C最终的结果是一样的,但其执行效率可能大相径庭。
上面的例子中我没有使用关系代数的符号,优化器可以应用几百种规律对查询进行随意的等价变换。下面是部分关系代数中的等价变换公式:

- 选择交换律:关系代数中的选择(σ)与SQL中的WHERE等价,对关系\(R\)应用选择谓词\(P1\)和\(P2\),其顺序可以交换。这允许我们在优化时执行谓词下推。
- 连接交换律/结合律:如第4和第5条公式,本质上System-R优化器就大大利用了这一点进行优化
- ...
成本分析
光使用关系代数变换是无法精确优化的,比如我们知道可以将谓词下推,或者可以将连接顺序交换,但是交换后是更好了还是更差了,我们不知道。
所以关系代数变换往往是跟着成本分析一起进行的,成本分析基于数据库的统计数据计算出查询计划树中每一个节点的成本以及总成本,在多个物理查询计划的成本间进行比较,从而得到最优的。
成本分析需要:
- 支撑成本分析的统计信息,比如表、索引数据量,索引选择性
- 计算每种操作符IO和CPU成本的公式
- 计算逻辑树上每个节点输入输出数据的量的公式
优化器实现
System-R优化器
System-R是IBM构建的一个关系型数据库,我们探讨其中的优化器
回顾一下刚刚说的构建优化器所面临的一些挑战:
- 搜索空间巨大,如何限制搜索空间
- 在不执行具体计划的情况下无法知道哪个更优
对于第一个问题,System-R使用的自底向上动态规划搜索算法,天然的将搜索空间限定在一个只有左深树的子空间上,并且不考虑使用笛卡尔积;对于第二个问题,System-R采用基于成本的分析方式来近似得到哪个计划更优。
动态规划思想
System-R优化器是一种动态规划算法,其核心思路为:对于一个具有\(k\)个join的SPJ查询\(Q\),可以看作是用\(k-1\)个join的\(Q\)的子查询的最佳计划再加上一个额外的join组合而成。
进一步说,当你在计算\(k\)个join的SPJ的最优解时,\(k-1\)个join的子查询的最优解你是不用考虑的。下面用一个实例来演示。
现在我们有一个A join B join C的目标:
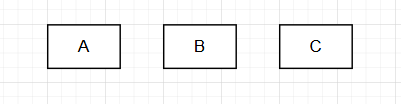
第一步,我们来在\(k=1\)的情况下来看,此时你只需要选出每个单表的物理执行计划:

上图中,A表选择了在c1列上的索引,B表选择了在c2列上的索引,C表选择了全表扫描,而不选择那些分支,我们会进行一波剪枝,因为没必要保留它们。
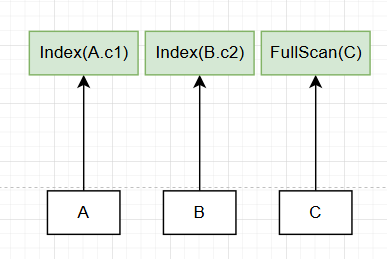
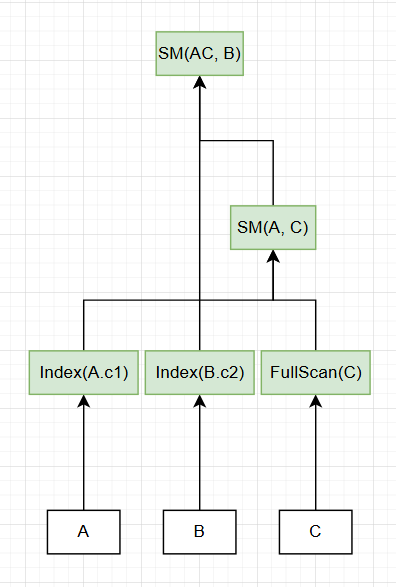
我们把这些提供给上层\(k=2\),在这一层,我们需要进行两两join,并选择对应的join算法

两两join一共有三种情况(C32),AB、AC和BC,在AB的连接中,HashJoin算法胜出,在AC和BC的连接中,排序归并Join胜出。
继续,处理\(k=3\)的情况,只需要在\(k=2\)的所有局部最优输出上追加一个额外的join,并计算出各种可选的物理join算法的成本,最后,我们就能确定唯一一个(在System-R搜索空间范围内)成本最低的路径。为了清晰,这里偷了个小懒,假设每个join可用的算法都只有排序归并:

最终,SM(SM(A, C), B)这一路径胜出
左深树和浓密树
假设现在有具有四个关系的SPJ查询Q,如下是两可能的逻辑树:
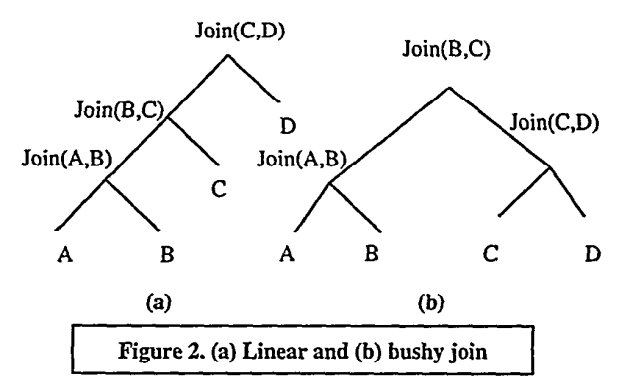
左深树,即上图(a)种所有连接操作符在左侧构成一条线的逻辑查询树,它的特点是没有中间结果之间的join。而图(b)则是浓密树,它先执行(A join B)和(C join D),再将这两个产生的中间结果再join。
虽然已经证明很多时候浓密树是更好的,但是System-R不会考虑这种情况,System-R优化器的搜索空间限定在左深树上,且不会考虑笛卡尔积。
Top-Down优化器
没看懂我靠...
其它优化
查询扁平化
相关嵌套查询 / 非相关嵌套查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号