Raft论文阅读笔记.18171971
本文是对Raft论文阅读后的一些核心内容总结
原论文:In Search of an Understandable Consensus Algorithm
(Extended Version)
Raft概览
Raft论文中用几个表格给出了Raft的细节概览,这里不用仔细阅读,后面学习的时候会慢慢深刻的理解这些内容
server持有的状态

RPC原语


server规则

属性保证
Raft保证一下每一个属性在任何时间都是永真式:
- 选举安全性:在一个term内,只有一个leader被选举出来
- leader只追加:leader永远不会覆盖或删除日志中的条目,它只追加条目
- 日志匹配性:如果两个日志包含一个index相同且term相同的条目,那么在这个index之前的所有日志条目都是相同的
- leader完备性:如果在一个term中,一个日志条目被提交了,那么在任何更高的term中,该日志条目都会在该term的leader的日志中出现
- 状态机安全性:如果server应用了某一个index的日志到它的状态机上,那么任何其他server都不可以在该index上应用不同的日志
Leader选举
本模块描述了Raft如何进行leader选举,并满足了Raft的选举安全性
Raft中的server有三种状态:
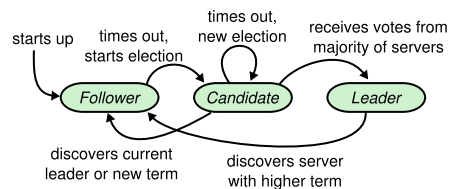
流程概览
- 当server启动时,它默认就是follower。它会监听请求,有来自leader的
AppendEntries RPC,用于复制日志条目和心跳;有来自candidate的RequestVote RPC,用于竞选leader时征求投票 - 当一段时间没有接到来自leader和candidate的请求,它自己便会想要成为leader
- follower会将term + 1,然后将自己的状态变为candidate,先给自己投一票,然后给集群中所有server发送
RequestVote RPC请求投票- 当大多数server投票给它了,它便成为当前term的leader
- 当它接到更高term的
AppendEntries或RequestVote,代表当前leader已经过时,它变回follower - 当它接到相同term的
AppendEntries,代表已经有人赢得选举 - 当它接到更小term的
AppendEntries,代表一个老的leader来了一个请求,可能因为网络分区恢复或者是leader宕机重启,此时拒绝该请求 - 一段时间过去了,没有任何结果。可能由于当前term的candidate太多,导致没有server获得大多数投票。此时它重回follower
- 当candidate成为leader,它将周期性的通过无内容的
AppendEntries RPC来维护自己的地位,其中包含当前term,以避免其它follower开启另一次选举 - 当leader接收到更高term的
AppendEntires RPC时,也许是因为脑裂发生,也许是因为它宕机重启了,而此时已经有新的leader了,它将变回follower
集群中的任何一个follower在给定term只能给一个candidate投票,以先来先服务原则
选举安全性满足
假设一个term内有两个leader被选举出来,假设是A和B,那么必然A和B都获得了大多数的投票,则必然有至少1个follower给A和B都投了票,而这在竞选流程中这是不可能发生的。
边界情况考虑
考虑在竞选过程中发生server宕机会发生什么:
- 假设follower在term 1给A投票后宕机,重启后接到了B的
RequestVote RPC。这要求server必须持久化它在给定term投票给了谁,才不会做出违反规则的操作。在开篇的图片中可以看到是使用votedFor状态来持久化的。 - 假设candidate宕机,不论它是否已经赢得了leader都没什么影响,follower和candidate的超时机制稍后都会推进重新选举
- 假设被选中的leader宕机再重启,有几种情况,一是还没server发现并开始竞选,此时什么都不影响;二是已经开始竞选但还没新的leader产生,此时可能发生一些微妙的问题;三是新的leader已经产生了,此时,旧leader有可能继续接收client的请求,但它通过
AppendEntries RPC向其它server复制时不一定会成功,由于它的term会被认为是过时的。这要求每一个server必须持久化当前term - 尚未解决的问题:考虑leader宕机后,某个candidate的
RequestVote RPC还没有被大多数接到,而此时leader恢复,它的AppendEntries RPC抢先被大多数接到,并且向client承诺commit并应用到状态机中,会发生什么。这就是后面的模块要讨论的了
在同时出现多个candidate时,没人能够赢得大多数的投票,此时可能再重复多少次都是无用功,raft使用随机timeout机制来解决这个问题。
日志复制
本模块描述Raft如何复制日志,并且满足了Raft的日志匹配性
流程概览
- leader接到client的命令,将其作为新的日志条目追加到日志中
- 然后它发送
AppendEntries RPC给所有server来复制该日志条目,除了client的命令外,该请求中还包含什么我们先不讨论 - 当该条目在大多数server上复制成功(包含leader),leader将它应用到自己的状态机上,给客户端返回committed,告诉它已经提交成功
- 若server由于各种原因(网络、运行速度慢、宕机)而无响应,leader将不停重试该请求
这里有一个实现上的难点,在分布式系统中我们无法确定server无响应的原因,当leader重试时
AppendEntries RPC时,没准server已经接到了,只是返回信息丢失了。这意味着实践中AppendEntries RPC的实现必须能够识别这种重复 - leader维护最后一个成功提交的log的index,在稍后的
AppendEntries RPC(正常追加记录以及心跳)中携带,这样所有server都能知道可以将哪些条目应用到自己的状态机。所以follower应用状态机是比leader晚的,这类似两阶段提交。
下图是日志的图例,每一组横向的方块是一个server上的日志,方块即日志条目。每个日志条目包含一个client命令,一个index表示它在所有日志中的下标,一个term表示该日志产生的term(为了便于识别使用不同颜色)。
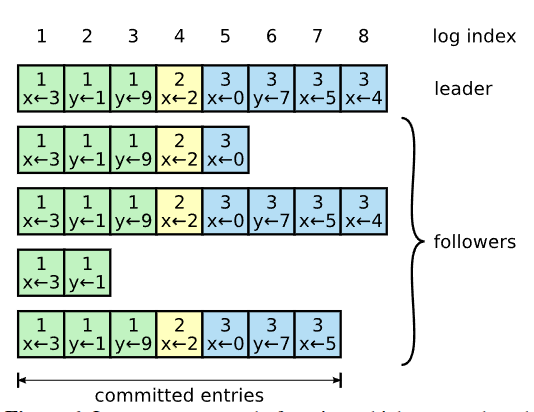
日志匹配性满足
日志匹配性:如果两个日志包含一个index相同且term相同的条目,那么在这个index之前的所有日志条目都是相同的
Raft将日志匹配性拆成两个小条件来分别保证,最后使用数学归纳法,便可以得到整个日志匹配性:
- 如果不同日志中的两个条目具有相同的index和term,那么它们保存着相同的命令
- 如果不同日志中的两个条目具有相同的index和term,那么前面所有的日志条目都是相同的
第一个条件已经在leader选举阶段,由同一个term只会存在一个leader,并且leader只会追加日志条目,不会修改已经写入的条目来保证。
第二个条件通过在AppendEntries RPC中添加字段来解决,leader会在请求中添加前一个日志的index和term。因为我们已经满足了条件1,所以若follower的前一个日志的index和term和请求中的index和term相同,那么两个日志条目必然也相同。只有在这种情况下,follower才会宣告此次追加成功,否则都是失败的追加。
边界情况考虑
考虑如下情况:
- term1,#0是leader,它将新条目复制给#2后便宕机了
- term2,#1变成了leader,它将新条目复制给#4便宕机了
- term3,#0变成leader,此时,它发现有的server上比它多数据,有的server上比它少数据。
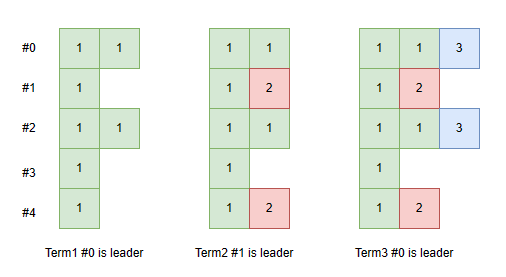
根据目前所知的raft,这个来自term3的新条目没法在其它任何server上复制了,因为没有任何其它server在index 2处有来自term 1的条目。
日志覆盖
Raft通过强制所有follower复制leader的日志来解决这一问题。意思是,像上图中的term 3,新leader #0必须强迫所有server都复制它的日志,也就是说server #1、#5在index2处的日志条目要被替换成leader的,而server #4则会追加一个条目。
leader中会维护每一个server上最后一个复制成功的index——lastIndex,但该值不必持久化,leader可以在重启后将所有server的lastIndex初始化成它log中最后一个条目的index,通过发送AppendEntries RPC,并将参数中的pervLogIndex设成lastIndex,将prevLogTerm设置成lastIndex处日志条目的term,再根据是否能够追加来判断二者的日志在index以及之前是否一致。当发现不一致,lastIndex -= 1。这样,最后所有server的日志就必然跟leader一致。
边界情况2
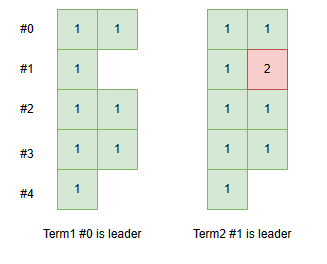
如上图,假设:
- term1,#0是leader,它将新的日志条目复制给了#2,#3,此时该条目已经在大多数server上了,#0将其应用到自己的状态机上,并给外界返回committed
- 在后续的heartbeat中,#2和#3也许也将该条目应用到自己的状态机了
- term2,#1是leader,如果它按照上述的方式不加限制的覆盖,则#0、#2、#3上已经提交的日志将会被修改,这违反了leader完备性和状态机安全性
leader完备性:如果在一个term中,一个日志条目被提交了,那么在任何更高的term中,该日志条目都会在该term的leader的日志中出现
状态机安全性:如果server应用了某一个index的日志到它的状态机上,那么任何其他server都不可以在该index上应用不同的日志
Raft并没有在日志复制模块解决该问题,而是将其放到了下一块,安全性模块中
安全性
本模块通过在“谁能在leader选举中胜出”处添加额外限制,来补齐Raft的其它尚未满足的特性。
选举限制
在日志复制阶段,由于leader启动后会用自己的日志覆盖所有follower的日志,若新leader中不包含全部已提交的日志的话,就会存在像上一个图片中那样,已提交的日志被覆盖,最终导致状态机执行结果不一致的问题。
Raft限制只有包含全部已提交日志条目的server才可以成为leader。
- 一个candidate在选举时,为了赢得选举,它必须得得到大多数的同意
- 一个已经提交的日志,它所在的server必然会和这个大多数有重叠,因为两个大多数必然有重叠
- candidate在选举时将自己最新的日志信息
lastLogIndex以及lastLogTerm包含在RequestVote RPC中 - follower发现自己的
lastLogIndex比它大,或者lastLogTerm比它新,旧拒绝给它投票
在这个规则下,若一个candidate不包含已提交日志,那么它必然无法拿到大多数的投票,也必然无法成为新的leader。
边界情况
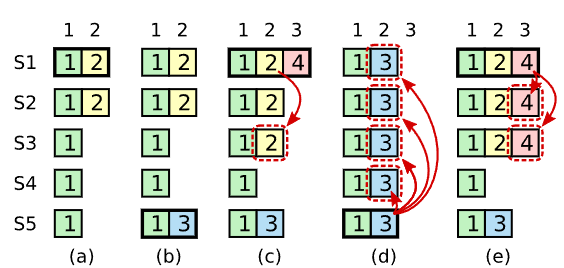
在上图中:
- term2(a),S1是leader,它将新条目复制到了S2上便宕机了
- term3(b),S5是leader,它向自己的日志中追加了一个条目便宕机了
- term4(c),S1是leader,它开始执行日志复制,最终将term2中的条目复制给了大多数,此时该条目有被应用到状态机的风险
- term5(d),S5是leader,因为它在index2上的日志term更大,所以它能够赢得大多数的投票,此时,它开始日志复制,它会将已经提交的条目覆盖掉
产生这种边界条件的原因是,我们不能错误的将来自之前term的日志复制给大多数后就认为它们已经提交了,这种假设只在当前term成立,因为在当前term,其他server上不会有更新term的数据了(如上图中第c组S5上的3)。
Raft解决这一问题的办法是,它永远不会直接通过计算副本数来提交来自之前term的日志,它只通过计算副本数来提交当前term的日志条目,一旦当前term的条目被提交,根据日志匹配性,之前的所有日志都被间接的提交了。(日志覆盖会处理这种情况)
到这里我们可以看出,Raft是一个把简单性放在第一位的算法,这让花一个下午理解一个共识算法成为可能。其实Raft也可以采用更复杂的手段来救援来自老term的日志,包括前面的很多解决办法都可以更复杂更高级,但是Raft都没做。
也许正是因为它的简单,所以官方称它的性能和其他共识算法没太大区别。
Leader完备性满足
leader完备性:如果在一个term中,一个日志条目被提交了,那么在任何更高的term中,该日志条目都会在该term的leader的日志中出现
该反证法来自Paper原文
我们假设Leader完备性不满足,并且term \(T\)的leader——\(leader_T\),在它的term中提交了一个日志条目\(E\),但是\(E\)并未在未来的某一个term的leader中存在。假设term \(U>T\),是最早的一个其leader(\(leader_U\))中不存在条目\(E\)的term。
- 在\(leader_U\)选举时,已提交的条目\(E\)必然不在它的日志中存在,因为leader永远不会删除或覆盖自己的条目
- \(leader_T\)必然将\(E\)成功复制给了集群中的大多数,而\(leader_U\)也必然获得了集群中大多数的投票。因此,至少有一个server(投票者)既接收了\(leader_T\)的条目\(E\),也给\(leader_U\)投票了,这个投票者是反证的关键:如下图:
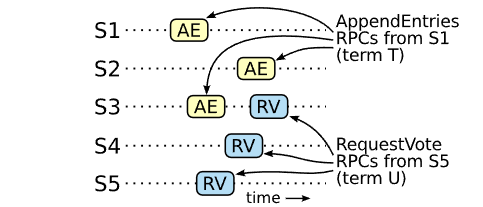
- 投票者必须要在给\(leader_U\)投票之前就接受了来自\(leader_T\)的条目\(E\)。否则,它就会拒绝\(leader_T\)的
AppendEntires RPC,因为投票者当前term将会比\(T\)的大 - 投票者在给\(leader_U\)投票时肯定仍然保存着条目\(E\),因为(直到\(leader_U\))之前的每一个leader都保存着条目\(E\)(这是我们的假设前提),leader永远不会移除条目,并且follower只会在与leader冲突时移除条目
- 投票者给\(leader_U\)投了一票,所以\(leader_U\)的日志必然比投票者更新(up-to-date),这引出了两个矛盾中的其一
- 首先,如果投票者和\(leader_U\)有着一样的
lastLogTerm,那么\(leader_U\)的日志必然至少和投票者一样长,所以它必然包含投票者中的每一个日志,这是一个矛盾,因为投票者包含已提交的条目\(E\)但我们假设\(leader_U\)不包含 - 否则,\(leader_U\)的
lastLogTerm必然比投票者大,更进一步,它肯定大于\(T\),因为投票者的最后一个日志条目至少是\(T\)(其中包含已term\(T\)中的已提交条目\(E\))。创建了\(leader_U\)的最后一个日志条目的更早的那个leader的日志中必然包含已提交日志\(E\)(这也是我们的假设前提),那么,根据日志匹配性,\(leader_U\)的日志中也必然包含已提交条目\(E\) - 我们完成了反证,因此所有比\(T\)大的term的leader都必然包含T中所有已提交的条目
- 日志匹配性同样保证了未来的leader将包含间接提交的所有条目
状态机安全性满足
若Leader完备性满足,我们可以证明状态机安全性。
状态机安全性:如果server应用了某一个index的日志到它的状态机上,那么任何其他server都不可以在该index上应用不同的日志
在server应用日志条目到它的状态机时,这个条目必须已经提交,并且包括它在内,以及之前的所有条目都必须和leader上的一致。
现在考虑任何一个server应用了给定index的日志的更低的term,leader完备性保证在更高的term的leader中,将包含着相同的日志条目,所以后续在该index上应用的term将会应用相同的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号