Paper——可容错的虚拟机实践系统设计.18162229
本篇是论文《The Design of a Practical System for Fault-Tolerant Virtual Machines》的学习笔记
论文作者:Daniel J. Scales, Mike Nelson, Ganesh Venkitachalam @ VMWare, Inc
设计目标:通过主备复制手段设计一个可容错的VM,用于用户运行企业级程序。primary日常工作,一旦它宕机,和它保持lock-step的backup会立刻顶上,外界观察不到这些操作,我们制造了只有一台VM永远在正常运行的假象。
要考虑的点:
- 使用什么手段保持primary和backup严格同步
- 在虚拟化单核CPU时和多核CPU时手段有何不同
- 非确定性指令和外部中断如何处理
- primary和backup任意一个宕机之后如何处理,如何恢复到一主一备并保持同步的状态
- 脑裂问题如何处理,如何保证只有一个primary正在与外部交互
- backup作为primary,新选择的backup如何追上此前的全部操作
- backup宕机恢复之后或者脑裂恢复之后,如何追上primary在这段时间的操作
- ...
同步手段概述#
- 状态迁移:将变更后的状态迁移到backup,包括CPU状态(寄存器)、内存、IO设备等
- 复制状态机:将产生变更的操作(operation)发送给backup
试想一个会操作大量内存的操作,如果使用状态迁移则要传输大量的数据,占用带宽并且难以保持同步;而复制状态机只会该操作发送给backup,节省数据传输量。
本篇论文中采用复制状态机的方式。
复制状态机及其限制#
状态机是一个数学模型,它具有状态,外部的输入事件会让状态机的状态发生改变。
若有状态机A和B,它们的初始状态一致,后续状态机B以相同的顺序执行和A一样的输入事件,并且这些输入事件对状态产生的变更都是确定性的,那么B就会和A保持同步。下面两点是复制状态机的关键:
- 主备初始状态一致
- 备份以相同的顺序执行和主一样的输入事件
- 所有操作对状态的变更都是确定性的
可以把计算机看作是一个状态机,其持有的状态就是CPU寄存器、内存、缓存,而输入事件则是CPU执行的指令以及外部中断。
既然选择了复制状态机,就意味着VMWare团队必须处理所有非确定性的外部事件,包括:
- 非确定性指令:随机数、日期时间等
- 外部中断:中断由设备发出,对于计算机的执行来说是异步的,假设中断在A的第110条指令和第111条指令之间发生,那么对于B,若想与A保持同步,必须也在110条和111条之间插入这个中断
- 只支持单核:对于多核CPU的每一个内存读写都是非确定性的操作
一般来说采用复制状态机的容错系统处理非确定性操作的方式是将非确定性操作的结果连同操作一起发送给备份,但是对于多核CPU的内存读写,这相当于将内存操作的全部结果都发送,所以复制状态机的优势已经没了。
VMWare FT貌似后期支持多核CPU的时候采用了状态迁移
利用Hypervisor#
VMWare FT是如何捕获primary的每一个指令执行以及外部输入的呢?
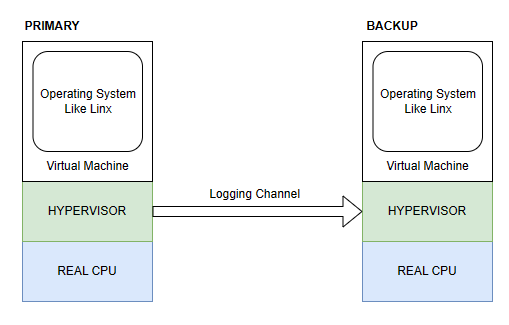
在运行的虚拟机以及实际硬件之间有一个Hypervisor层,它对于一个VM的执行有完全的控制权,包括向VM递送所有的输入。它能够捕获所有primary上的非确定性操作的必要信息,并通过logging channel将这些信息发送给backup以在backup上重放。
举个例子——接收外部事件:
- primary的hypervisor通过外部中断接收到网卡包,它通过logging channel将其发送给backup的logging channel,并向VM层递送该中断
- backup的hypervisor也向它的VM层递送该中断
举个例子——发送外部事件:
- primary执行到了一个发送外部事件的指令,hypervisor识别到它是primary,外部事件将正常发送
- backup也执行到了这个指令,hypervisor识别到它是backup,不发送本次事件。所以不会有两个网卡包被发送到网络中
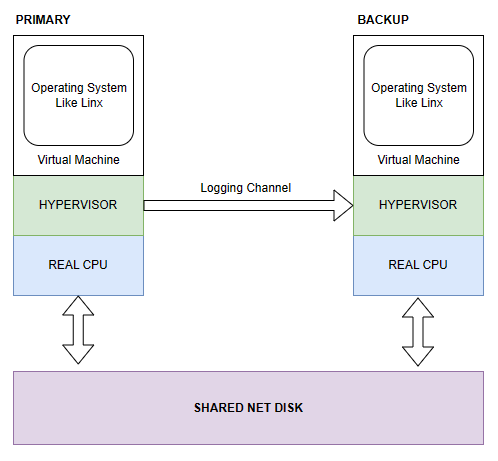
共享磁盘#
上面提到backup会丢弃所有外部事件的发送,那磁盘写入怎么解决?
primary和backup会共享一个底层的网络磁盘,当primary宕机backup顶上后可以看到和primary一样的磁盘。
主备同步实现#
输出需求:如果backup VM在primary宕机后接手,那么backup必须以和所有primary VM已经向外界发送的输出完全一致的方式继续执行。
解决方式是通过延迟输出:在一个外部输出(通常是网络包)在primary上发生时,primary只有在backup VM已经收到全部的,使它能够至少重放执行到此次输出操作的那个位置的信息时,才会将输出递送给外部。也就是说backup VM必须接收到输出操作之前的全部日志条目。
译者:我的理解是,只要满足这输出需求,对于外界来说就看不出primary宕机了。即使有一些非确定输入还没被应用到backup,但是这些非确定输入并未产生任何到外界的输出。这比论文中提到并且未采用的将每一个非确定性事件当作一个epoch的结尾这种更加严格的方式更轻量。
当VM在执行完一次output后宕机了,backup必须要知道它要重放执行到那次output,然后停止重放,作为primary继续执行。所以,primary的每次output是一个关键点,它可以看作primary对外界的一个无法撤销的保证,backup必须能够提供这次保证。至于为什么backup只需要重放到最近一次output,因为在那之后primary没有对外界做任何承诺。
为了实现这一点,在每一次output操作会生成一个特殊的日志发送到backup,并且primary要遵守如下输出规则:
输出规则:primary不向外界发出output,直到backup已经收到并ack了产生此次输出的操作日志项。
论文中提到,即使延迟了输出,primary仍然无需等待输出成功后再继续后面的执行,它可以立即向后执行
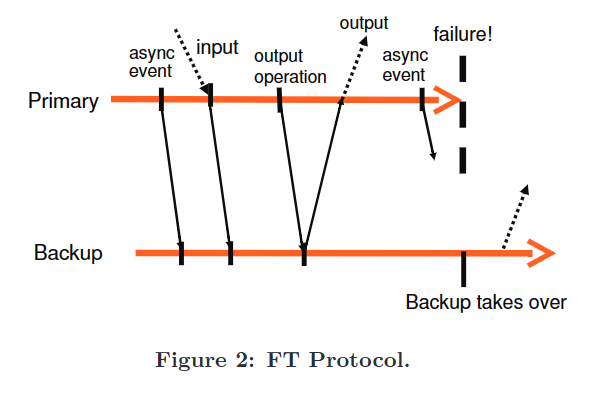
上面是论文中对FT Protocol的一个图示,从primary到backup的箭头代表log条目的传递,从backup到primary的箭头代表backup对日志条目的ack。异步事件、输入以及输出操作的日志必须被发送给backup并且被ack
同时,因为该协议中没有两阶段提交类似的保证,所以是没法保证在故障情况下向外界的输出只发生了精确一次的,因为backup在顶替时无法确定primary是在output之前还是之后crash的。具体的细节取决于VMWareFT的具体实现,若backup重放到输出操作之前然后作为primary,就可能产生重复输出;若是之后,则可能产生丢失输出。VMWareFT认为底层网络的基础设施、操作系统以及应用程序都足以处理丢包和重复包的问题,因为丢包和重复包可能会由于很多除了主备切换的原因导致。
还是没解释的问题:如何精确的在backup上重放某一个interrput的执行位置
错误修复实现#
TL; DR
- backup宕机,primary作为普通VM独自执行
- primary宕机,backup执行完全部ack的日志后,作为普通VM独自执行
- 通过heartbeat和logging channel的网络流量探测对方是否活着
- 通过共享存储的原子test-and-set处理脑裂情况,保证只有一个服务器go live
VMWare FT是一主一备的架构,当主或备任意一个宕机,对方都需要及时发现并修复问题,以保证高可用。
当backup宕机,主节点停止record mode(记录模式),开始作为一个普通VM独自执行。
当primary宕机,backup可能稍微落后,它可能有一堆已经ack的log条目,但由于还没有执行到合适的位置来应用这些log条目,backup继续重放,直到没有log条目,此时它停止replay mode(重放模式),转换成primary,开始作为一个普通的VM独自执行。
backup转移到primary时还需要做一些特定设备的操作以保证正常运行,比如VMWareFT会对外宣称新primary的MAC地址以便网络交换机将流量切入到新primary上。此外,新的primary可能要进行一些磁盘IO。
容错VM之间通过HeartBeat以及logging channel的网络流量来判断错误(对方挂了或者网络挂了),由于时钟中断非常频繁,所以如果logging channel停掉,基本可以断定错误发生。
错误发生后,我们必须要保证primary和backup只有一个作为新的primary运行(论文中称为go live)。VMWare FT通过利用共享存储服务器上提供的原子的test-and-set实现。共享服务器上有一个flag,想要go live的VM对它做一次原子test-and-set,成功的可以go live,失败的应该意识到已经有VM go live了。
考虑共享存储服务的网络分区了,此时可能primary和backup只有一个能连上,那么能连上的那个go live。也可能都连不上,此时二者都暂停执行,因为共享存储也在那个上面,允许它们执行也没用。
实践细节#
启动和重启FT VM#
说是利用VMWare的另一个产品VMotion的已有功能实现的。
管理Logging Channel#
根据论文中的描述,我猜backup VM应该是这样一个状态机,它不停的取log buffer中的日志,每一个日志里应该有它应该在哪个指令处执行(考虑外部中断),然后它执行指令到那个位置,之后再重放刚刚取出的日志,完成后,再取下一条日志,周而复始。
当log buffer空了,它就挂起不执行了,等待log buffer再次有内容。backup不与外界交互,所以它怎样执行都不影响client的体验。
实践中还有可能backup执行太慢了,导致primary无法往已经满的buffer中再次写入,此时primary会停止执行。相当于他们实现了类似TCP的流量控制。
VMWareFT是不允许backup执行过慢于primary的,他们还设计了一些其他机制来检测backup的进度延后,并slow down primary。
FT VM上的操作#
磁盘IO上的实现问题#
网络IO上的实现问题#
其他可能的设计#
- 共享和非共享磁盘
- 在Backup上执行磁盘读
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/18163041
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)