MIT6824 MapReduce总结
MapReduce是一个分布式大任务计算框架,旨在可以方便Google内部的将大型任务拆分到集群环境下,以得到并行化的处理速度。
在分布式情况下,多台机器协作完成一个大型任务需要考虑很多问题:
- 整个分布式系统中都有哪些角色?可以预见的就是肯定有任务的拆分者负责拆分调度任务,有任务的实际执行者
- 如何拆分任务?如何给用户暴露简单的接口,屏蔽任何分布式系统中可能出现的复杂问题
- 每一个角色需要持有什么状态,状态之间是否需要同步,以保证分布式计算的正常进行(理想情况下希望持有的状态是最少的,并且不需要任何同步,这样问题会更少)
- 如何给worker传递任务,以最小化网络带宽的消耗
- 如何保证只要有一个worker存在,整个计算就能make progress
- worker fail如何探测,如何处理?重新调度任务会不会对整个计算产生副作用
- 常见分布式问题的处理,如脑裂、fail等等等等
本篇文章作为《MIT6.824 2021 分布式系统》的学习以及Lab总结,会一一回答上面的问题。
学习MapReduce的论文不重要,看这篇文章也不重要,重要的是去刷Lab,Lab能让你面临MapReduce设计者面临的同样的问题,此时你就是决策者,这才是理解MapReduce设计思路的最佳方式。
[Lab Page] | [MapReduce论文] | [课程视频]
角色划分
先贴上MapReduce论文中的执行概览图:
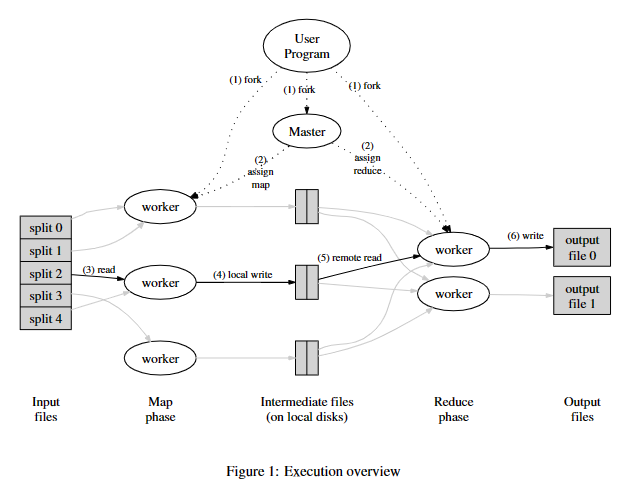
很自然地,我们可以想到分布式计算这个场景中可能有的角色:
- 任务拆分者:将整个大任务拆分成小块
- 调度者:将任务调度给分布式集群中的主机的
- 执行者:实际执行任务的主机
MapReduce的任务拆分由用户程序完成,当MapReduce操作启动,首先就会将任务分割成\(M\)片。
随后,用户程序会在分布式集群中启动多个worker,有一个特殊的worker会作为调度者(后文称coordinator,论文中称master),其它的则负责实际执行任务(后文称worker)。
MapReduce框架中,有单个的
coordinator和多个的worker两种角色。worker fail被框架考虑并处理,coordinator由于只有单点,认为是可靠的,没有做HA处理。
任务抽象
这里需要考虑的是,用户有一个大型计算任务,你的框架需要将这个任务拆分成一堆可以并行执行的小任务。
- 你应该向用户暴露什么样的接口,用户应该负责什么,框架应该负责什么?(隐藏分布式计算中各种复杂问题)
- 你暴露的接口直接影响用户的思考方式,是否足够简单、自然
- 你暴露的接口是否fit大部分的任务,换句话说是不是大部分现实任务都能用你暴露的接口描述
MapReduce框架将分布式计算任务拆分为两个阶段,Map阶段和Reduce阶段。
因为在分布式计算场景中,每一个机器计算一小部分内容,它计算出来的东西是一个局部解,全部的计算需要最终被汇总成全局解,所以Map阶段就是得到\(M\)(Map任务数量)个局部解,Reduce阶段就是汇总\(M\)个局部解得到全局解的。
这是否意味着Reduce阶段无法并行了?不是。MapReduce仍然允许你有\(R\)个并行执行的Reduce任务,每一个计算一部分的全局解。
考虑WordCount任务(计算每一个单词在文本中出现的数量),Map任务将输入文件分割成\(M\)个块,计算每一块的局部解,然后多个Reduce可以汇总全部局部解,最终分别计算开头是A~C、D~G等的全局解。这就意味着在Map和Reduce中间,必须有什么东西将多个局部解得到的结果排序汇总。
在Map阶段就分组输出局部解
MapReduce框架中,具有多少个Reduce任务是用户的输入——\(R\)。
还是考虑WordCount任务,我们可以在Map时就把每一个局部解分割成\(R\)个组,比如\(hash(word) \% R\)。这个分组函数也由用户指定,称为Partition Function。
这样,Reduce任务就可以根据自己是第几个任务去计算自己那一部分的全局解了。
实际的Map-Reduce
MapReduce框架中实际的
Map和Reduce函数和我所讲的有些区别,本文不会陷入细节之中,只是考虑为什么这样做,原汁原味的请去看原Paper。
函数式编程的优势
Map和Reduce来自函数式编程的两个原语。
一个最重要的特点是,函数式编程的函数的值取决于输入的值,不依赖外部状态。即\(Map(X)=Map(Y)\)当\(X=Y\),论文原文里将其称为确定性函数(deterministic function)。
这让MapReduce框架可以很轻易地处理worker fail,后面我们会提到。
Worker崩溃恢复
当worker崩溃,coordinator必须要将任务重新分配给其它worker,但这次崩溃也许只是因为某些其它原因导致的假象(比如脑裂),这就意味着某些任务可能会被执行多次。
- 对于map任务的中间结果,coordinator可以只记录第一个上报的worker的结果,只要有一个worker上报,就可以认为该map任务结束了。
- coordinator可以使用心跳机制来判断worker的活性,或者使用任务完成的超时机制,第一种可以较早的发现worker fail
- 对于reduce任务,它输出的是最终的目标文件,reduce的计算可以在某一个临时文件中,最后利用底层文件系统的原子重命名机制保证只有一个worker实际完成的reduce任务
- 由于map是确定性函数,所以重新映射map任务到其它机器上运行也不会对最终结果产生影响。MapReduce不限制map必须是确定性的,若不是,你得到的就是一个非确定的输出而已
- coordinator会将map的中间结果告诉reduce任务,reduce会对中间结果进行排序分组。有一种可能,即上报结果的map在这段时间里fail,此时该map任务还需重新调度(若map的中间结果也在GFS上便可以不用考虑这种问题,这种情况类似于本节课的lab中的情况)
- 取决于不同的实现,比如coordinator在整个流程中对所有worker持续性的heartbeat,这种情况下coordinator能及时的检测出某一个已经上报map任务结果的worker fail了,此时重新调度它
组件持有的状态
组件持有的状态取决于指定问题的实现方式,在MapReduce框架中,可选的方式很多。
coordinator可以主动RPC调度worker,好处是它的控制权比较多,知道的东西也比较多;坏处就是它要管理的状态比较多。
- 需要知道worker的列表,并且根据worker的状态维护更新该列表
- 需要维护哪些任务在哪些worker上
- 需要维护map任务的中间结果位置
另一种方式是只让worker单向调用coordinator,这种情况下,coordinator需要维护一个未执行任务列表,活跃的worker不断请求一个任务,coordinator给它分配。每当发现worker fail,便将对应的任务放回未执行任务列表等待重新调度。在实验中我就是用的这种方式。
- 这种方式的缺点是coordinator不好控制将任务分配给哪个worker
如果想实现backup task,即避免慢worker拖慢整体速度,可能还需要某种定时器,并且记录哪些任务已经被分配出去了,如果超过多长时间没有结果,重新调度它。
总结
MapReduce处理分布式问题很粗暴,利用了任务重新执行也没问题这一特性,所以coordinator和worker都可以只保存很少的状态和交互,在我的实验实现里,coordinator甚至不知道有哪些worker。
同时它依赖了底层的分布式存储GFS,这让上层应用可以无状态,依赖底层存储保证一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号