MySQL分享
本次分享主要涉及InnoDB如何在磁盘上保存数据
- InnoDB表空间结构:介绍了InnoDB表文件中的一些组件,比如段、区、页、行记录。除了告诉你怎样存之外,更重要的是希望解释为什么要这样
- 索引页结构:数据以及索引都存在于索引页中,介绍索引页如何组织,当数据删除、更新时会发生啥
- 索引分裂、合并:由此,我们可以引出索引页的合并以及分裂,还有分裂可能造成的性能影响
InnoDB表空间结构
页,以及为什么要有页
当我们思考数据库表的时候,我们认为它们是一系列的行的集合:

但由于信息=位+上下文,它们只是一系列在InnoDB上下文中被解释为行的二进制位,它们实际以字节形式被存储在某种Non-Volatile设备上,比如它们最终是在物理磁盘的文件中。

假设上面就是表数据的最终二进制表示,我们想执行一条SQL来得到表中的部分行,比如提取出六年级的所有学生,怎么做呢?
CPU没有直接在磁盘上进行计算的指令,这些位必须被搬到内存中被InnoDB去解释成行
那么一次搬多少呢?
- 我们不知道每行数据的边界在哪
- 即使每行数据是固定大小的(比如20B),我可以轻易的做出如下操作,我们肯定也希望尽量减少磁盘读取次数,所以一次肯定不能只读一条进内存吧
file = open(tablefile) start = 0 while (true) { student = parse(read(file, start, 20B)) # EOF if (student == null) break if (student.grade == 6) resultset.add(student) start += 20B } - 就算你无所谓性能,一次只读一条,硬件设备给OS的接口就是一次读一个固定大小的页,如果不考虑pagecache,你实际上每次都拿出来了4KB大小的数据,但是你只拿了其中的20字节,其它全扔了,然后下一次你再重复取
基于种种原因,我们肯定需要以固定大小的页来组织这些行,数据库每次以页为单元将数据拉到内存中进行计算。现在,我们有了如下的视图:
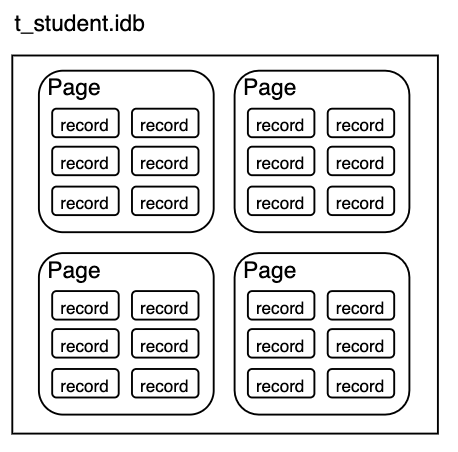
实际上硬件的页、操作系统的页和数据库的页是三个概念,这已经超出了这个分享的范围,忽略。
也许看到这里可以思考下为什么没人在内存里用B+树做搜索,没人在磁盘里用二叉树做搜索。
区,以及为什么要有区
我们经常会建立索引,甚至在InnoDB中,表本身都是个聚簇索引,索引的目的就是要加速查询,所以它本身需要是有序的,比如B+树最后一层是一个有序链表。
维护索引在物理上的有序很难,除非你插入的顺序就是有序的,如下图,此时你要插入10,一切都没什么问题,若你想插入6.5,那恐怕要想维护物理的有序性,后面所有数据都要移动了,别忘了这些页和记录的框框只是我们加上的逻辑视图,它们在文件里就是一堆位,没有什么魔法可以在中间凭空插入一堆其它的数据。
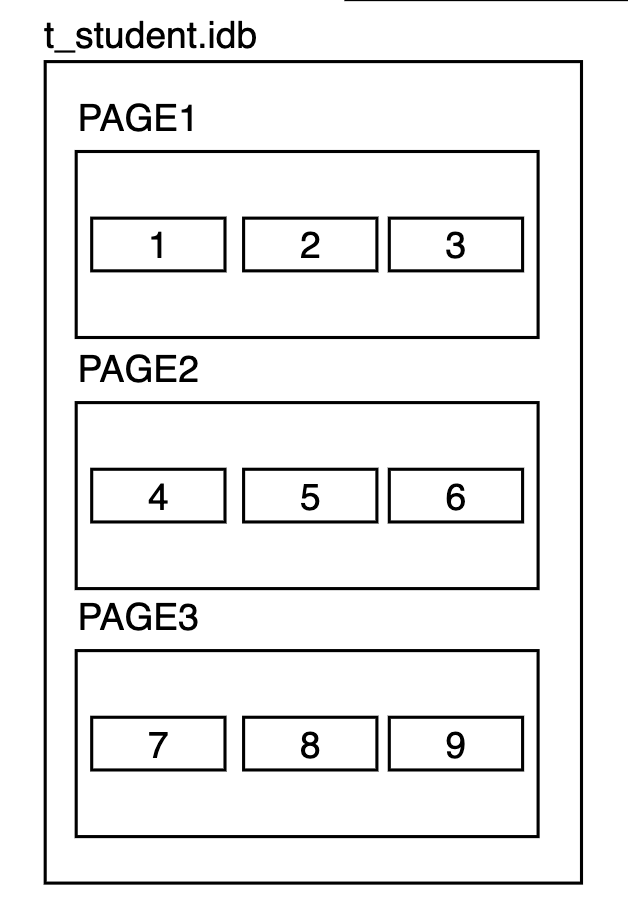
所以我们只能维护逻辑顺序,比如使用链表来维持顺序:
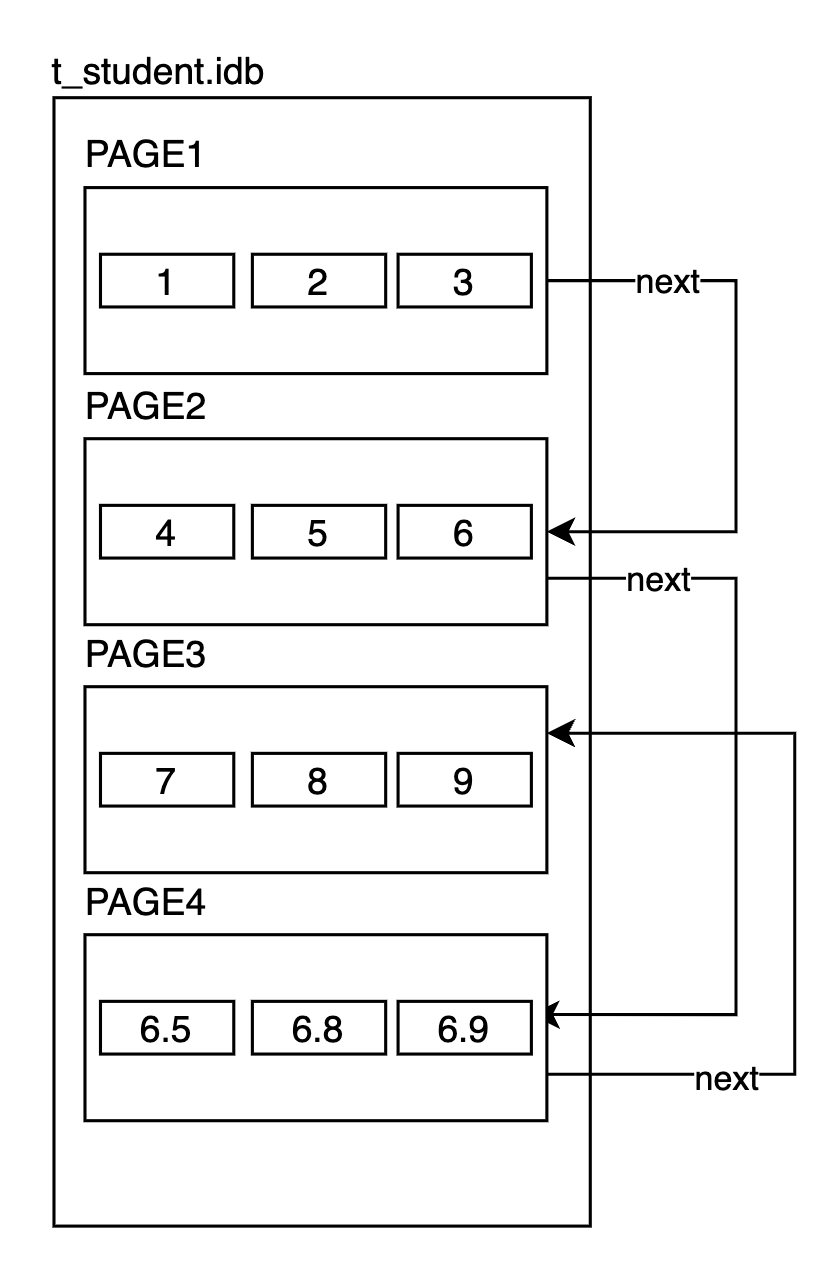
即使通过链表使得页面在逻辑上有序了,但物理上还是随机的磁盘访问,如果你希望尽量让这些逻辑有序的页在物理上也尽量有序的话,唯一的办法就是预先分配连续的一块大空间,未来如果要搞这种中间插入页的情况,我们还有较为靠近的空间可以用。
这个预先分配的空间就称为区。
默认情况下,InnoDB引擎的页大小为16KB,区为1MB,一个区中可以容纳64个页。
在5.7.6支持32K页和64K页时,32K对应的区大小为2MB,64K对应的为4MB
表空间文件和段
在最上层,我们有一个表空间文件,InnoDB目前版本的默认情况下,每个表使用一个独立的表空间文件,也可以在所有表共享表空间文件。
表空间文件中包含多种类型的信息,比如数据信息、索引信息(B+树非叶子节点),回滚信息,这些不同的信息由不同的段管理,段也是个逻辑概念,其中包含多个区
所以最终的InnoDB表空间文件的视图如下:
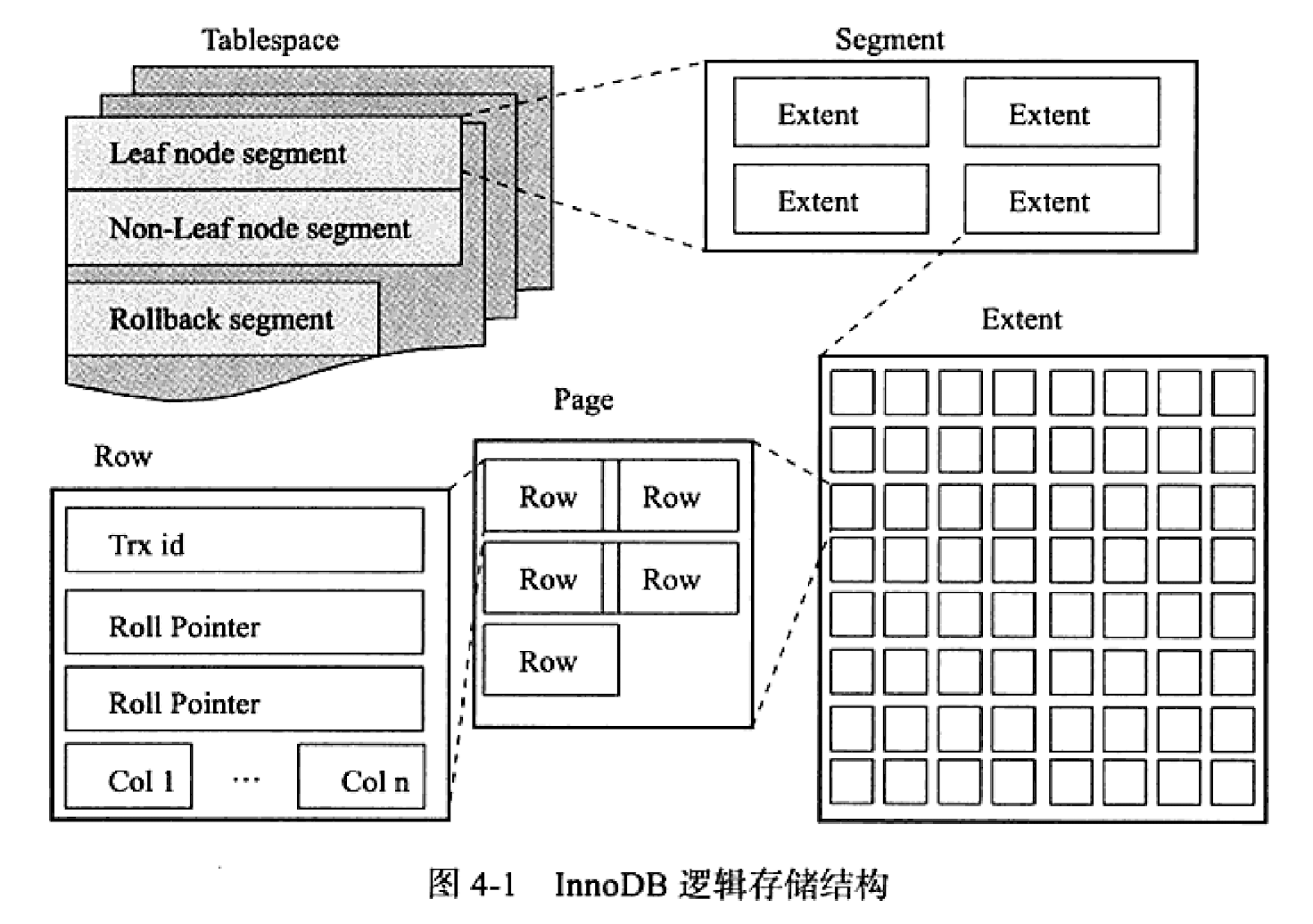
我们比较关心的是保存数据页的Non-Leaf node segment以及保存索引页的Leaf node Segment。
索引如何组织
上面我们提到了数据页、索引页之类的词,但实际上,它们在InnoDB中的页类型是一样的,都是索引页。
InnoDB使用B+树作为索引数据结构,其特性是非叶子节点只用于定位,其索引项中只包含索引key和用于寻址下一个页的页号,而叶子节点只包含数据,其索引项中包含索引key以及携带的数据。叶子节点从左向右读取就是按照索引key排序好的。
对于主键索引(聚簇索引)来说,叶子节点携带的数据就是整个行,而对于辅助索引来说,叶子节点携带的数据就是主键的id。
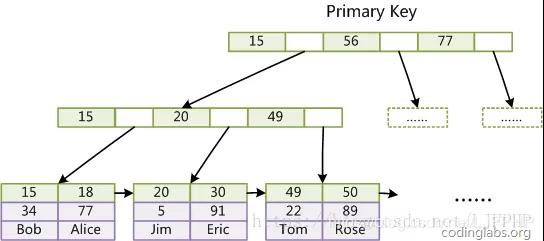
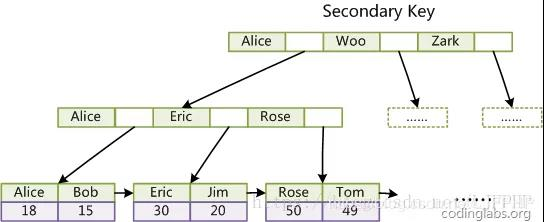
所以,我们说的数据页,本质上是那些B+树的叶子节点页,我们说的索引页,是哪些非叶子节点页,虽然都叫索引页,但对于每一个索引,MySQL使用不同的段来保存这两种页面。
下面,我有一个actor表,它有4列,actor_id是主键,还有一个在lastname上的索引。
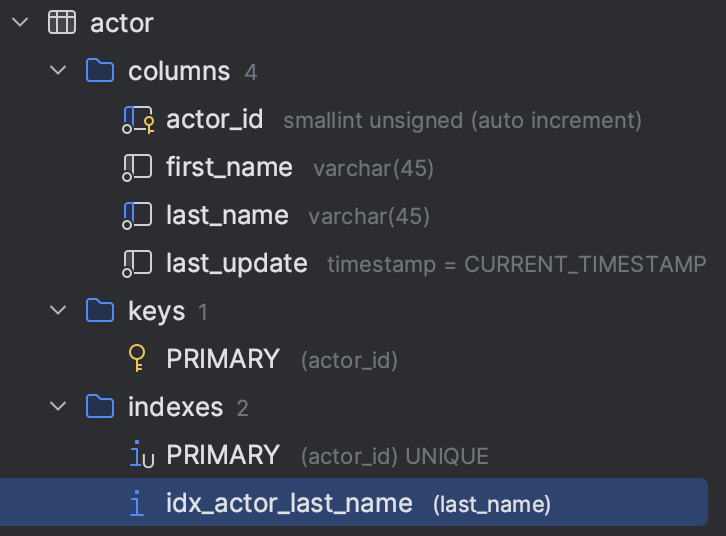
如果我们使用innodb_space工具来查看该表对应的ibd文件,会看到两个索引页:
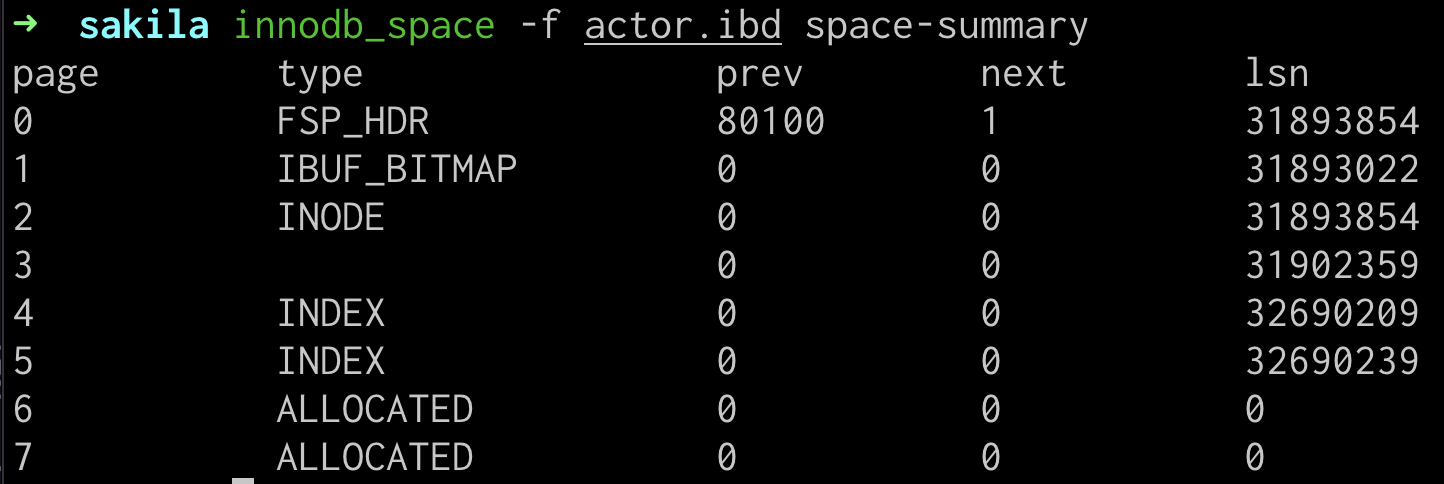
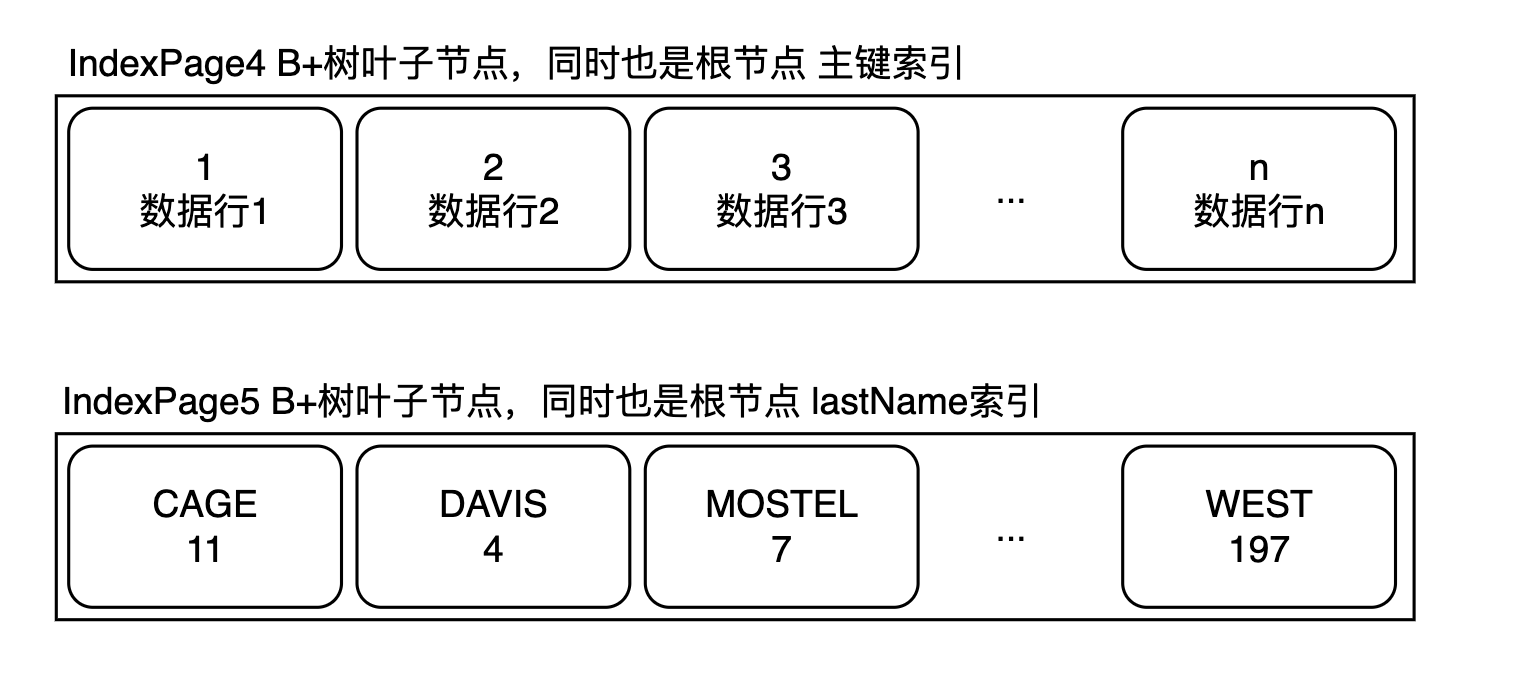
该表的数据量太小了,所以对于每一个索引,只要一个B+树叶子节点就能保存,所以这两个INDEX页分别对应两个索引。大概是这种形态:
film_text表的数据稍多一些,它也是有一个主键索引,加一个在title、description的辅助索引:
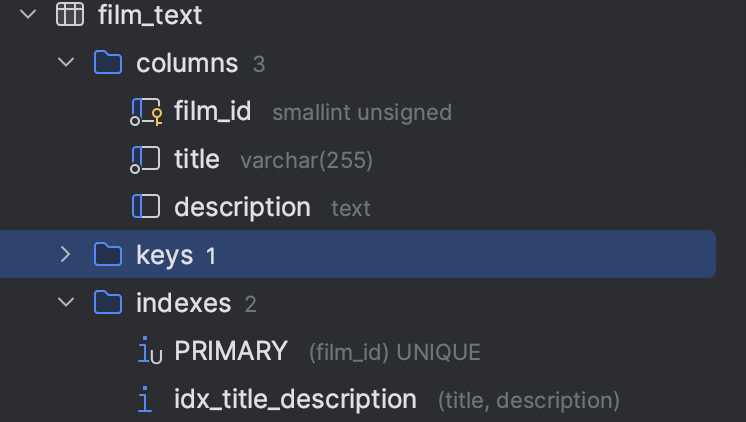
通过innodb_space工具,大概可以看出,4和5同样还是两个索引的根节点(因为它们的prev和next是0),只不过这次,数据量上来了,根节点无法容纳全部数据,B+树就增高了一层
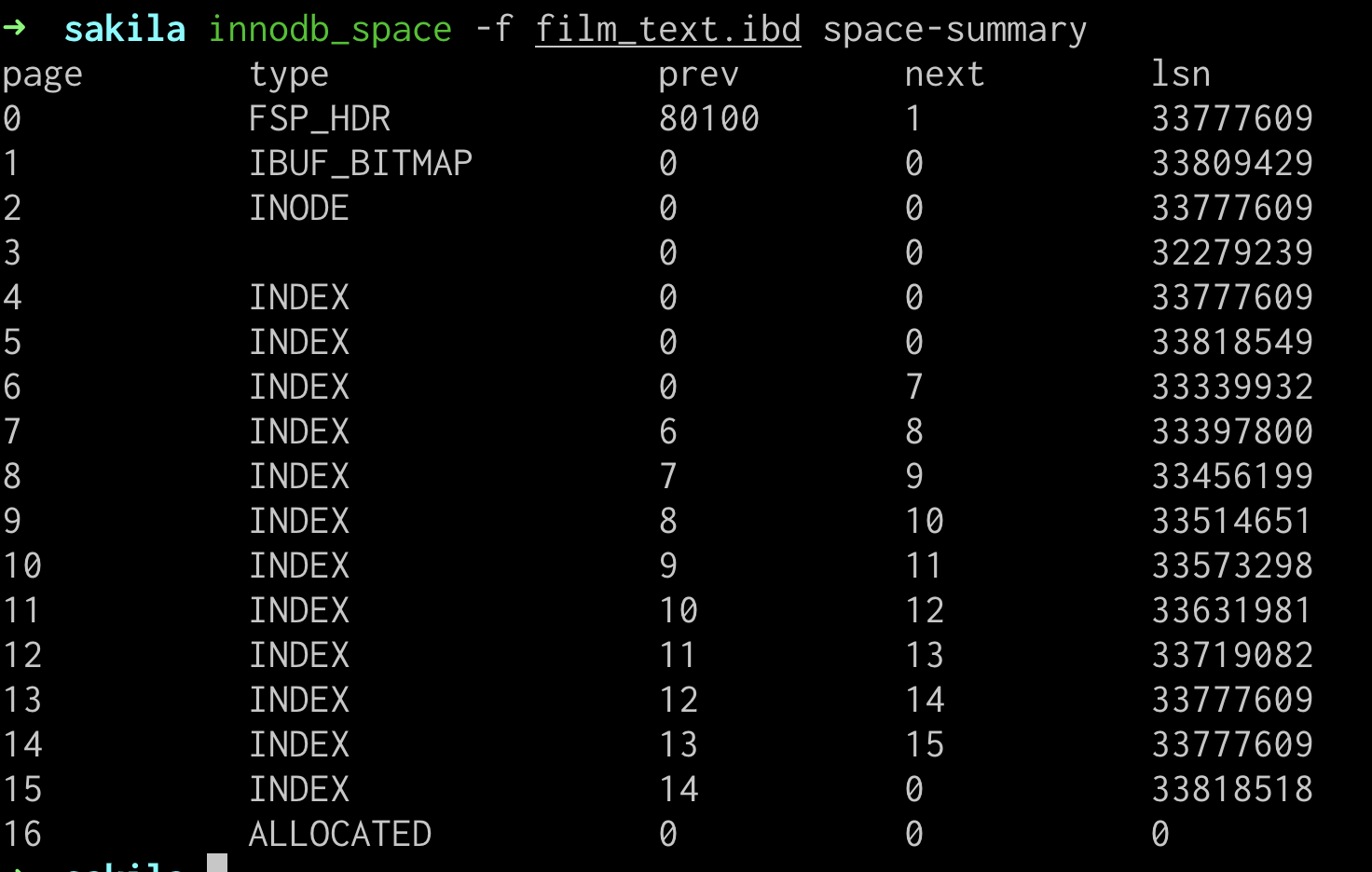
这次看起来大概是这样:
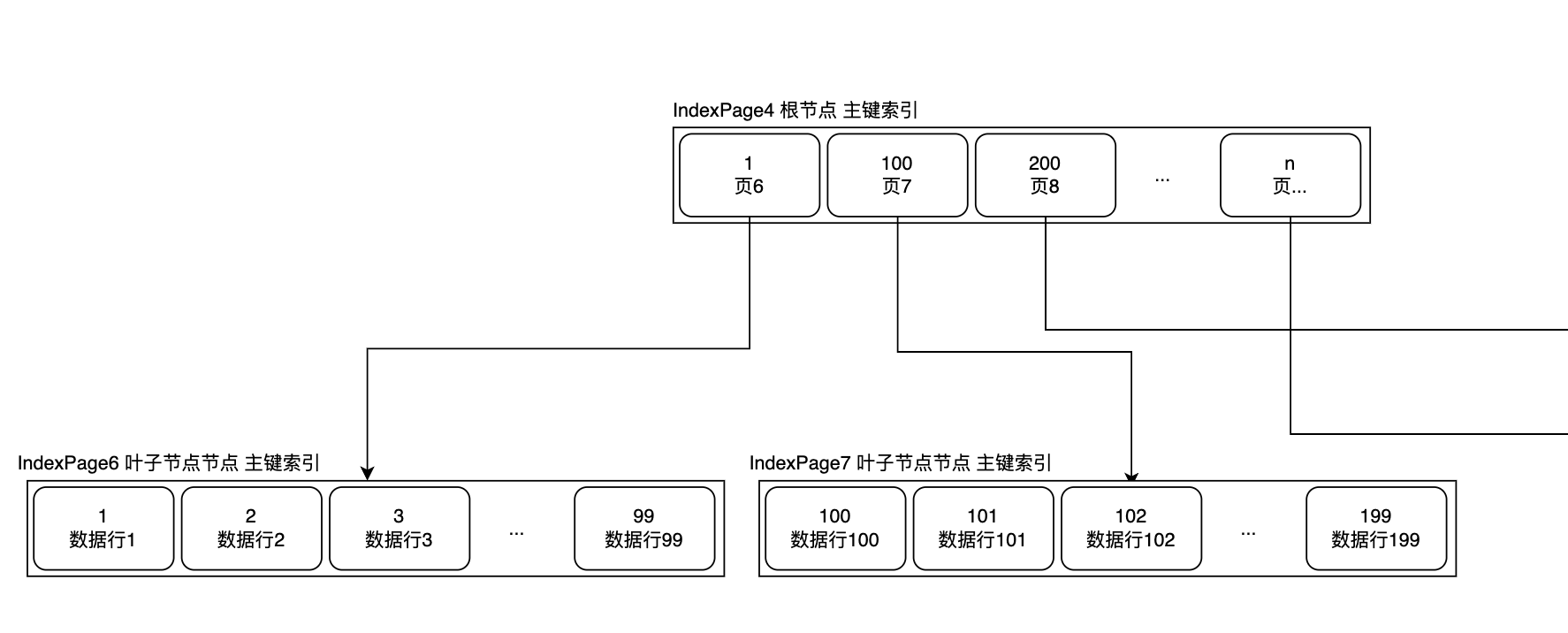
索引页结构
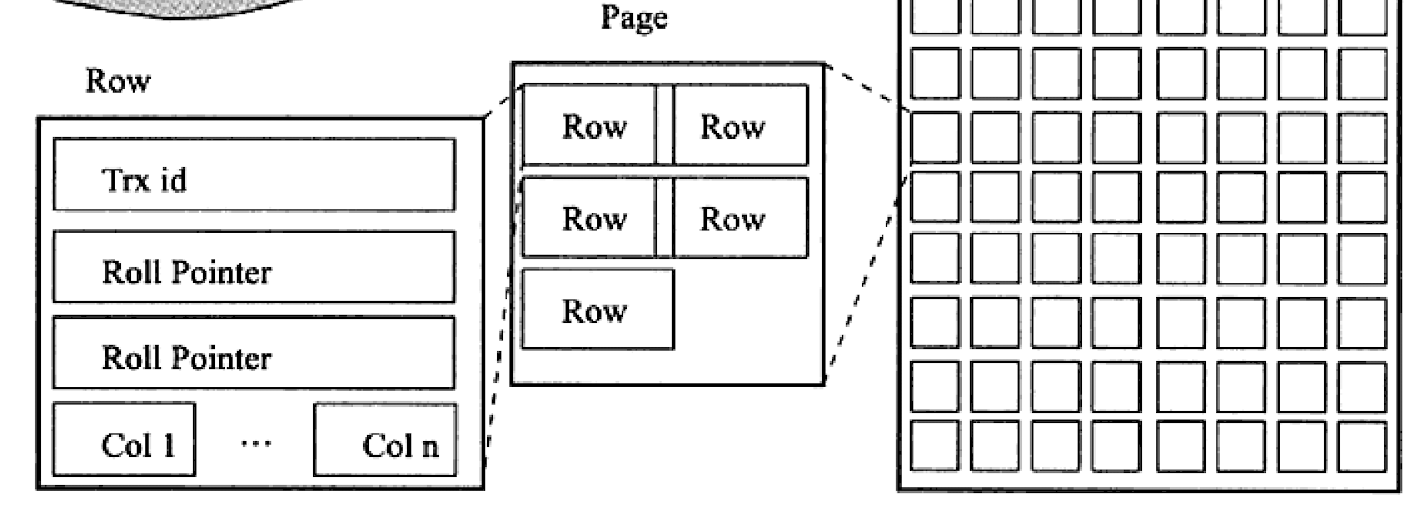
从我们上面画的那些图来看,索引页上就是一个一个的索引项,不管是叶子节点还是非叶子节点。但实际情况没那么简单,索引页中实际上有很多东西:
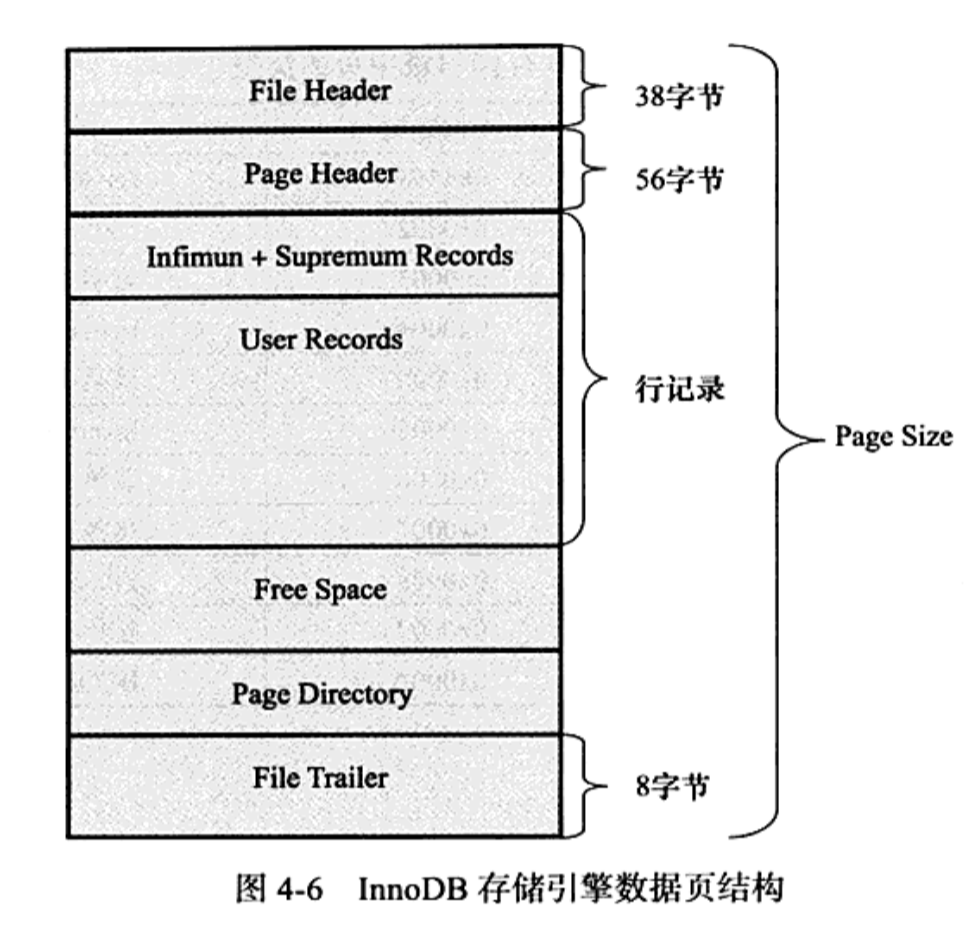
文件头
文件头中有这两个字段:
FIL_PAGE_PREV:当前页的上一个页,它在文件头中的offset为8,占用4字节FIL_PAGE_NEXT:当前页的下一个页,它在文件头中的offset为12,占用4字节
这两个字段就是给B+树的叶子节点连成双向链表的,那些非叶子节点页这两个字段都是0。
我们来看下之前film_text表中的叶子节点的文件头部分,page7是一个叶子节点,16KB * 1024 * 7 = 0x1c000,再加上8字节就是该页的上一个页的页号,下图表明页7的上一个页是6,下一个页是8,和innodb_space工具给出的结果一致

User Records
我们说过,沿着B+树叶子节点一直向下读取,就是对索引的顺序读取。这就意味着User Records中的记录也是有序的,但是维护这种有序性不是没有成本的,一个页面16KB,InnoDB需要某种高效的方式来维护这种有序性。
高效插入和删除
插入和删除时通过移动数据来保持有序几乎是不可取的,InnoDB选择让页中的记录在物理上可以无序,使用链表来维持它们的顺序,记录头中的next_record字段代表了逻辑上的下一条数据的偏移量。
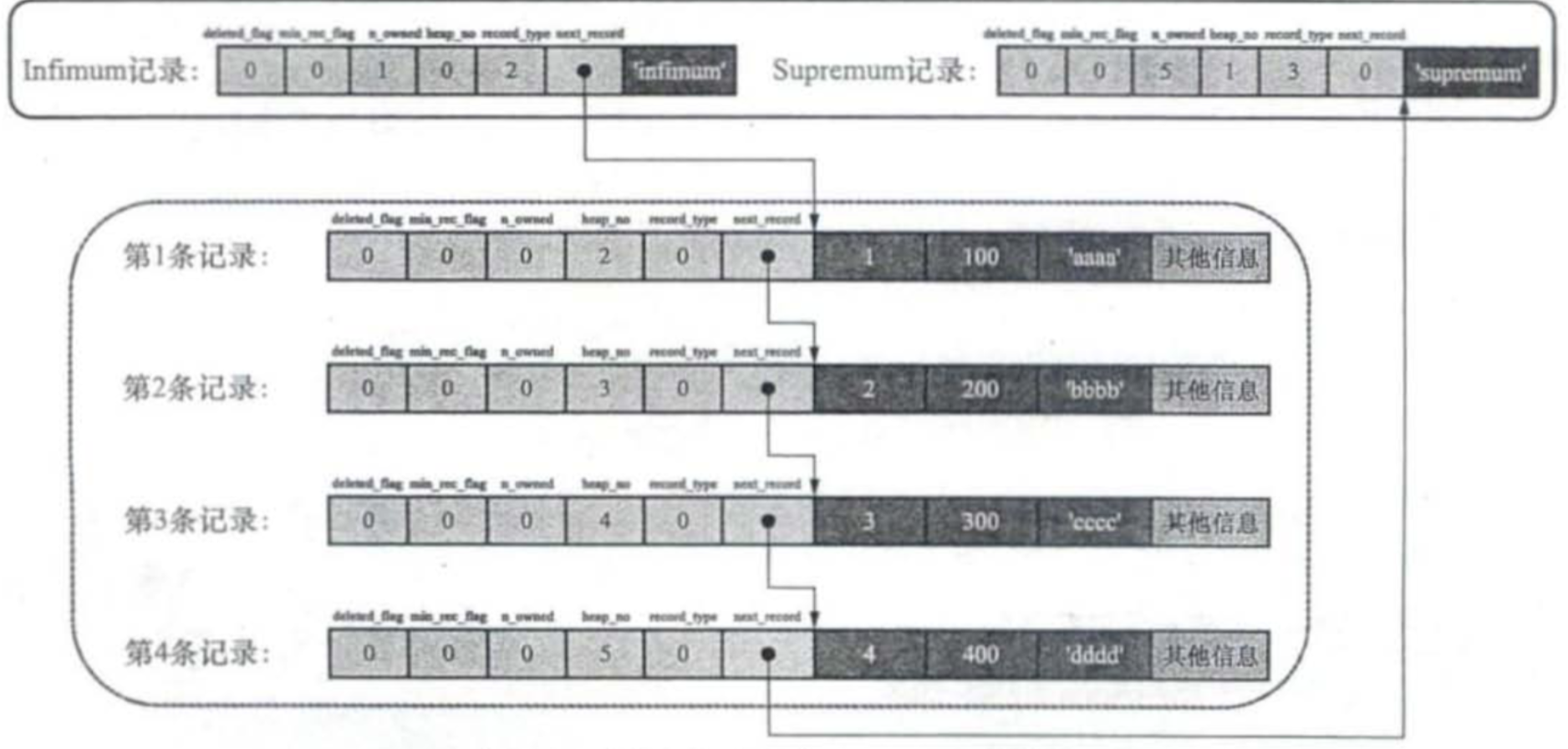
这样,删除和插入数据时实际上只需要操作链表节点即可,不涉及到数据的移动,被删除的数据会放到一个垃圾链表中等待复用。
听起来很像InnoDB在16KB的块上在实现内存分配器。
高效查找数据
对于查找数据,数据页中有一个Page Directory区,InnoDB把User Records中的链表分成若干个组,这样,若某一个页面中保存了ID为1到100的数据,那么就可以建立如下页目录:
key=1 offset=0
key=15 offset=912
key=30 offset=513
key=45 offset=9153
key=60 offset=1457
这样,先对key做二分查找,定位key所在的组,就能找到该组领头的记录的偏移量(offset),然后对整个链表的线性查找就变成了对组内有限数量个成员的线性查找了。
碎片问题
对于索引页内部的空间如何管理的细节,InnoDB的文档上没找到,网上也没找到相关的文章,我们做个实验简单看下。
我们创建一个主键自增的test表,它只有一个字段——fld,fld是变长字符串,这意味着每一条test表的记录的长度不一定是一样的,我们插入两条数据:
CREATE TABLE test (
id int primary key AUTO_INCREMENT,
fld VARCHAR(512) NOT NULL
);
INSERT INTO test (fld) VALUES ('hello, world!');
INSERT INTO test (fld) VALUES ('!dlrow ,olleh');
这两个字符串的十六进制表示如下,稍后我们用十六进制编辑器来观察ibd文件:
hello, world! => 68656c6c6f2c776f726c6421
!dlrow ,olleh => 21646c726f772c6f6c6c6568
现在,我们可以看到在page4左右的位置(0x10000)有着这两行数据。

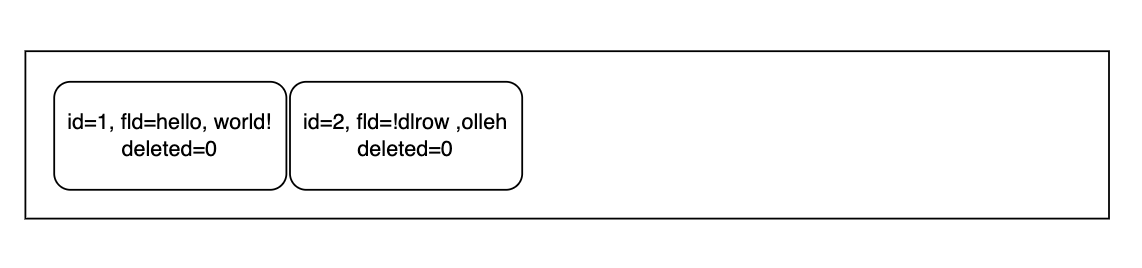
现在,要是我把id为1的fld字段变得更长,InnoDB会怎样处理?
UPDATE test SET fld = 'hello, world! hello, world!' WHERE id = 1;
反正它之前的记录已经容纳不了修改后的它了,要么,InnoDB将页内所有数据后移,给这个id为1的腾地儿,要么想别的办法,并且允许页内存在一定碎片。
我们看到,InnoDB在物理上原来的记录2的后面放了修改后的记录1,而原来的记录1没有动,如果你往前看会看到一些不一样(那个💲字符),估计是原来的记录被打了删除标记。

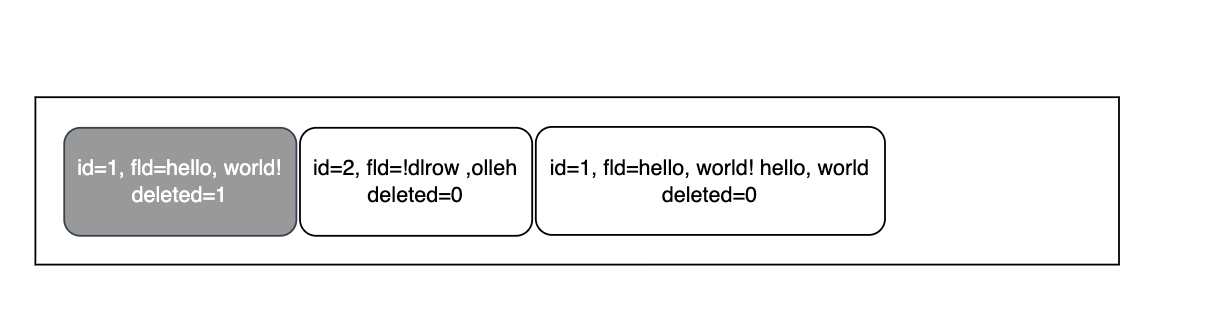
这样页内部就产生了一个碎片,如果接下来我再插入一个正好能复用前面的碎片的行呢?
INSERT INTO test (fld) VALUES ('xxxxx, xxxxx!');
可以看到碎片被复用了。

但碎片能完美复用的情况还是占少数,大多数情况下,要么就是复用了,但是产生了更小的,更加难以复用的碎片,要么就是没法复用,使用新的空间。
总之,删除和更新行长度时都会产生碎片,行变短,产生碎片,行变长,和删除行的效果一致。
页合并
InnoDB提供了MERGE_THRESHOLD属性,代表当页删除和更新长度时,若利用率已经低于这个值,就要尝试和旁边的页做一次合并以减缓碎片带来的影响,相当一次碎片清理。
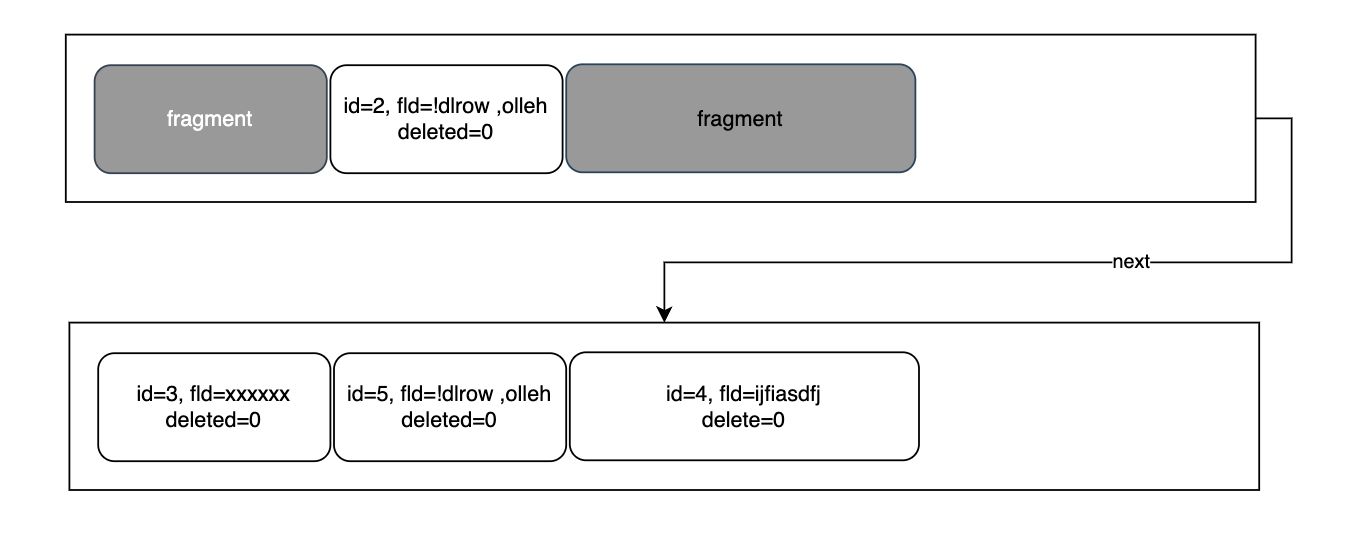
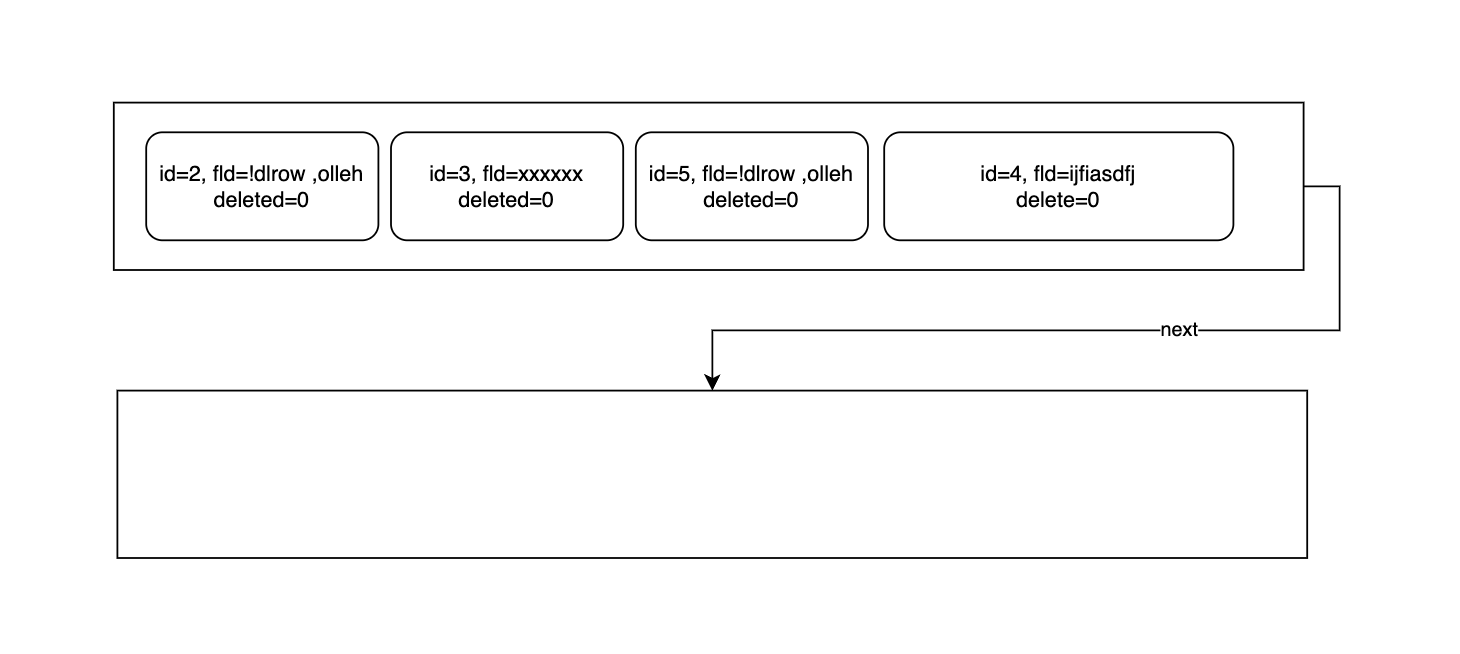
MERGE_THRESHOLD默认是50,但考虑如果两个待合并页的利用率都刚好低于50%一点的话,这两个页合并后很快就会由于空间满了要进行页分裂,如果这种merge-split操作频繁发生,可能会适得其反。所以InnoDB官方页推荐将该值设低一些。
合并操作只在两个页间发生,并且不会多任何页也不会少任何页,也就意味着InnoDB无需重新在各个页间建立指向关系。
页分裂
页分裂是指如下情况,当你想往第一个页插入id为6的数据时,你发现插不进去,它快满了,此时理应往下一个页中塞,然而下一个页也快满了...
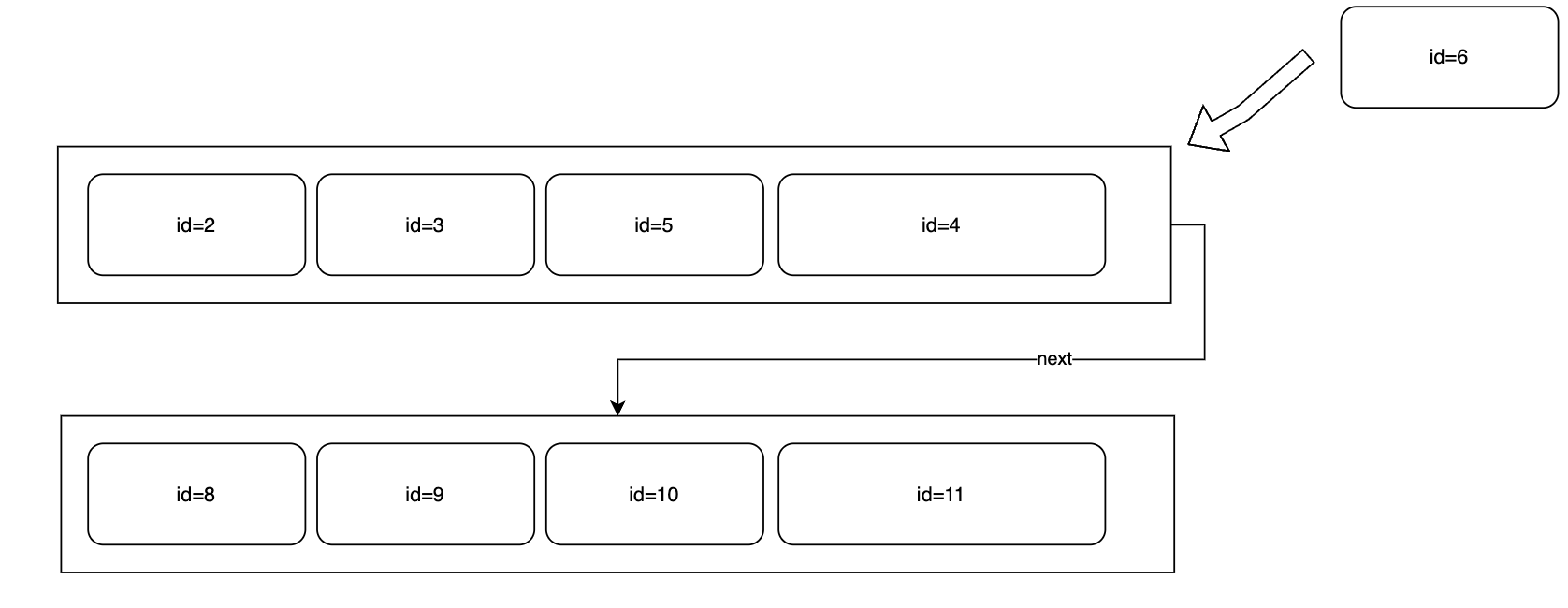
这时必须要出现一个新的页,之前我们说了区的概念,目前这两个页很可能在一个区中,所以它们在物理上大概率差的也不远,但是新创建的页不一定能在这个区里,可能现在的id都排到1000000了,这个区还有空间的希望渺茫,我们只能在别的区创建一个页插入到这两个页中间,那在扫描B+树的叶子节点时,本来磁盘工作的很稳定,一直在一个区的附近扫,突然就要跑很远去另一个区,然后再扫完中间这个页再跑很远回来......
所以为什么主键和索引尽量要有序就已经很清晰了,我承认直到刚才我都没有真正理解为啥,只知道会造成页分裂,但页分裂的后果完全不知道。网上的解释其实大部分都不是关键原因,看着很蒙,感觉他们说的那些根本不是究极原因。

