Docker分享
前置知识
本次分享主要介绍容器技术依赖的Namespace,并使用Linux提供的Namespace API制作一个小型的容器。在开始之前,有一些前置知识需要先阐明,也许它们很零碎,但开始之前我还是希望你能够完全理解这些概念。
前置知识这一段除了补短之外,还有一个目的,把一个很多人没解释清楚的问题解释清楚:
什么是容器,和虚拟机有什么区别?
进程树模型:fork和exec
在Linux中,创建进程只能通过fork系统调用(至少很久以前是这样的),它从当前进程拷贝一个分支出来作为子进程,子进程具有和当前进程完全一致的资源视图,比如它们能看到相同的内存,打开的文件描述符。
如果子进程想执行一个新的程序,可以通过exec系列系统调用,它会放弃这些已经拷贝的东西,加载指定的程序并开始执行。
所以,从Linux第一个init进程(pid=1)开始,系统上的所有进程构成一颗进程树:
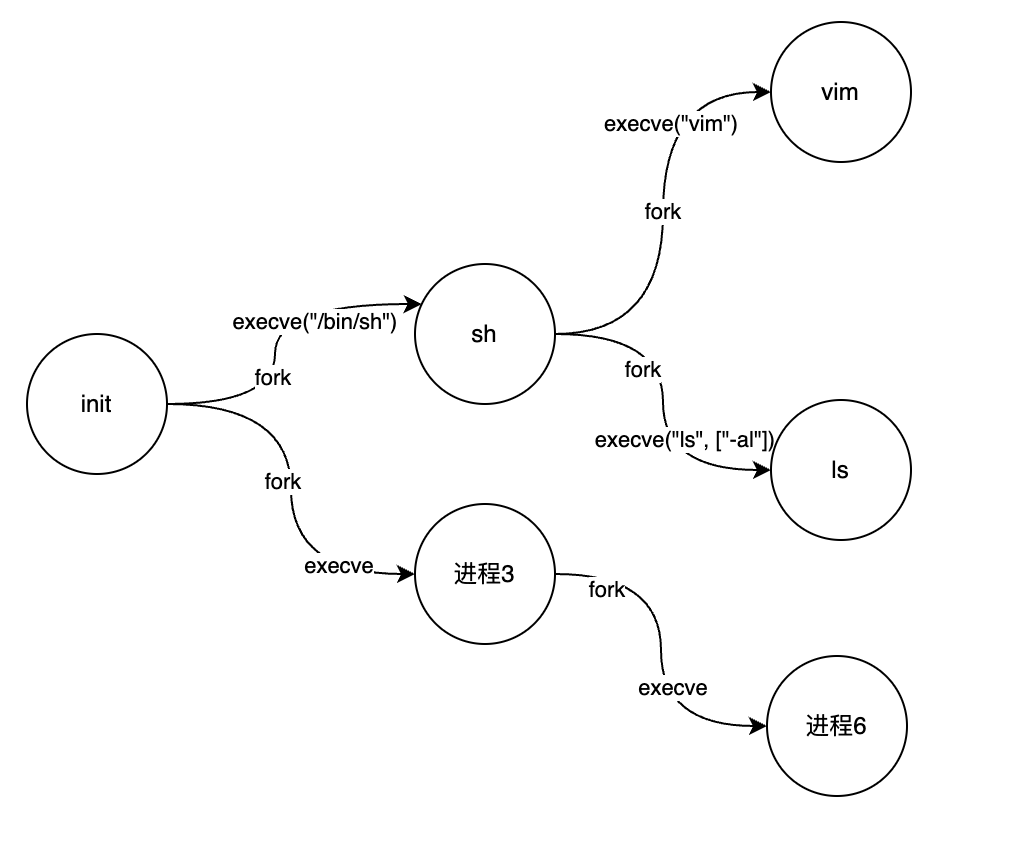
现在linux创建子进程的系统调用可不止一个
fork,比如还有我们后面介绍的clone,但还是遵循这样的树模型。推荐阅读:Namespace in operation, part 2: the namespaces API
演示:strace -f跟踪sh中运行ls的系统调用列表
隔离与共享
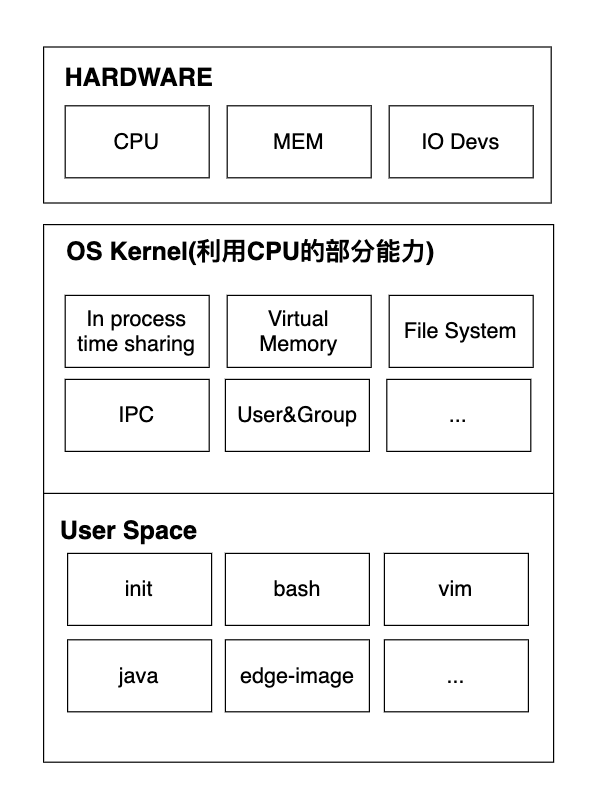
之所以要有进程,是因为操作系统希望你写程序的时候能简单点,你不用考虑你的程序会不会覆盖其它程序的内存,不用考虑如何和其它程序在CPU上分时运行,操作系统会把这些工作全包了,进程之间对于这些硬件资源的访问是隔离的。进程(至少不需要和其它进程通信的进程)几乎可以认为操作系统的硬件资源只有自己在使用。
如果进程之间完全隔离,看不到彼此的存在,那么如何开发
/bin/ps程序?
操作系统提供这些抽象的同时,也引入了一些所有进程共享的资源,比如:
- 文件系统:所有进程看到的文件系统是一致的
- 进程树:所有进程共用一个进程树,并且都拥有一个PID
- 主机名:所有进程看到的主机名都是一致的
- ipc:所有进程共用一套ipc基础组件,比如POSIX消息队列
- 网络接口:所有进程共用相同的网络设备,IP地址
- 用户&组:所有进程都看到相同的用户列表和组列表
上面都不是废话,我们终于可以解释容器是啥了!
理论上来说,如果操作系统可以使用一些魔法,像抽象硬件资源一般抽象这些系统公共资源,让一组进程看到和其它进程隔离的公共资源,那它们就会以为自己是操作系统中唯一的一组进程,但实际上它们只是缸中之脑,它们看到的只是外部的神之手为它们创造的假象。
哦,这就是容器!
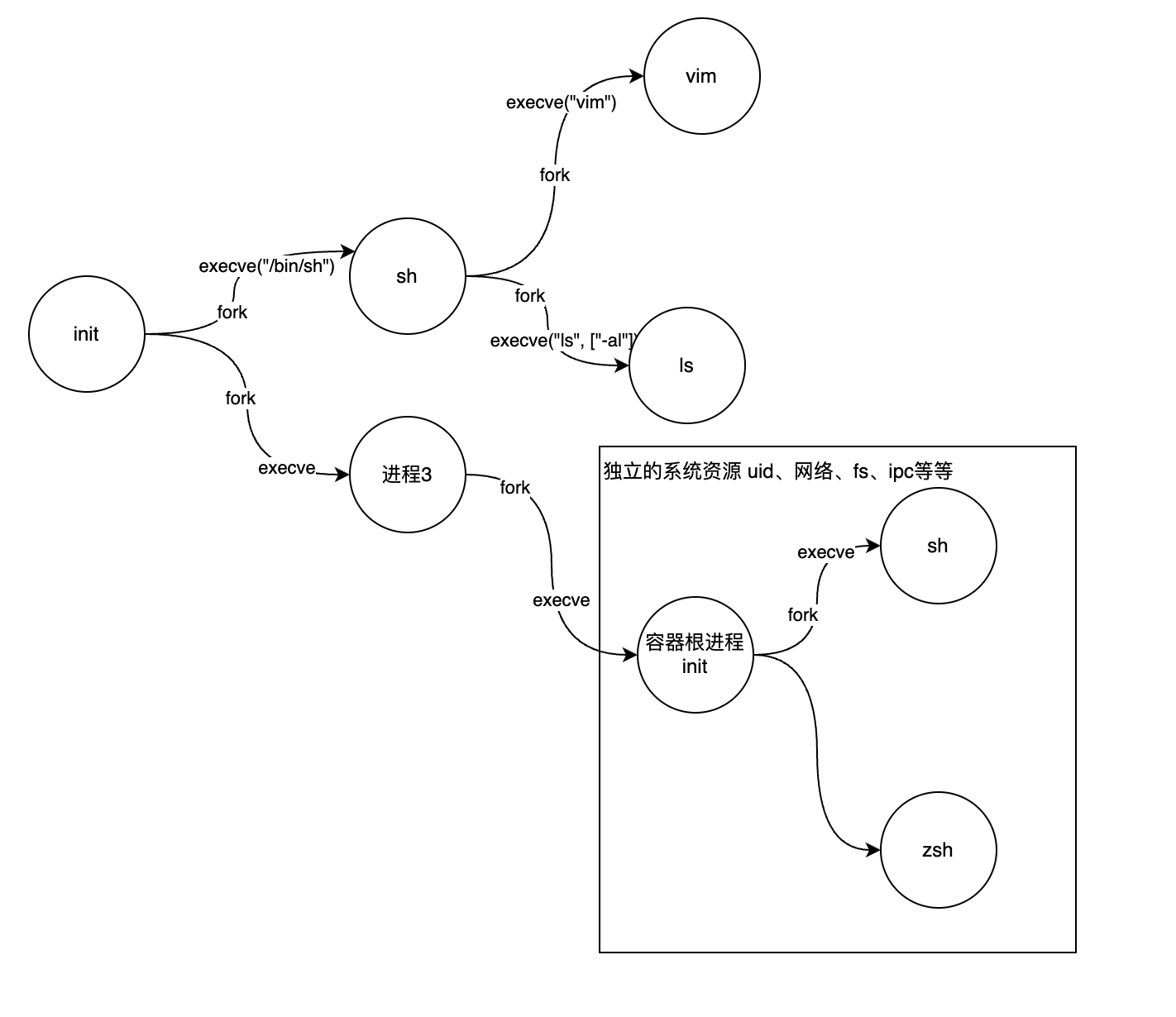
所以,容器和虚拟机有啥区别,自己去想一想吧
下图中,左下角的是虚拟机,可以看到每一个虚拟机在虚拟硬件层上运行着独立的操作系统,而操作系统的资源被隔离给上面的一组进程,就又形成了虚拟机中的容器
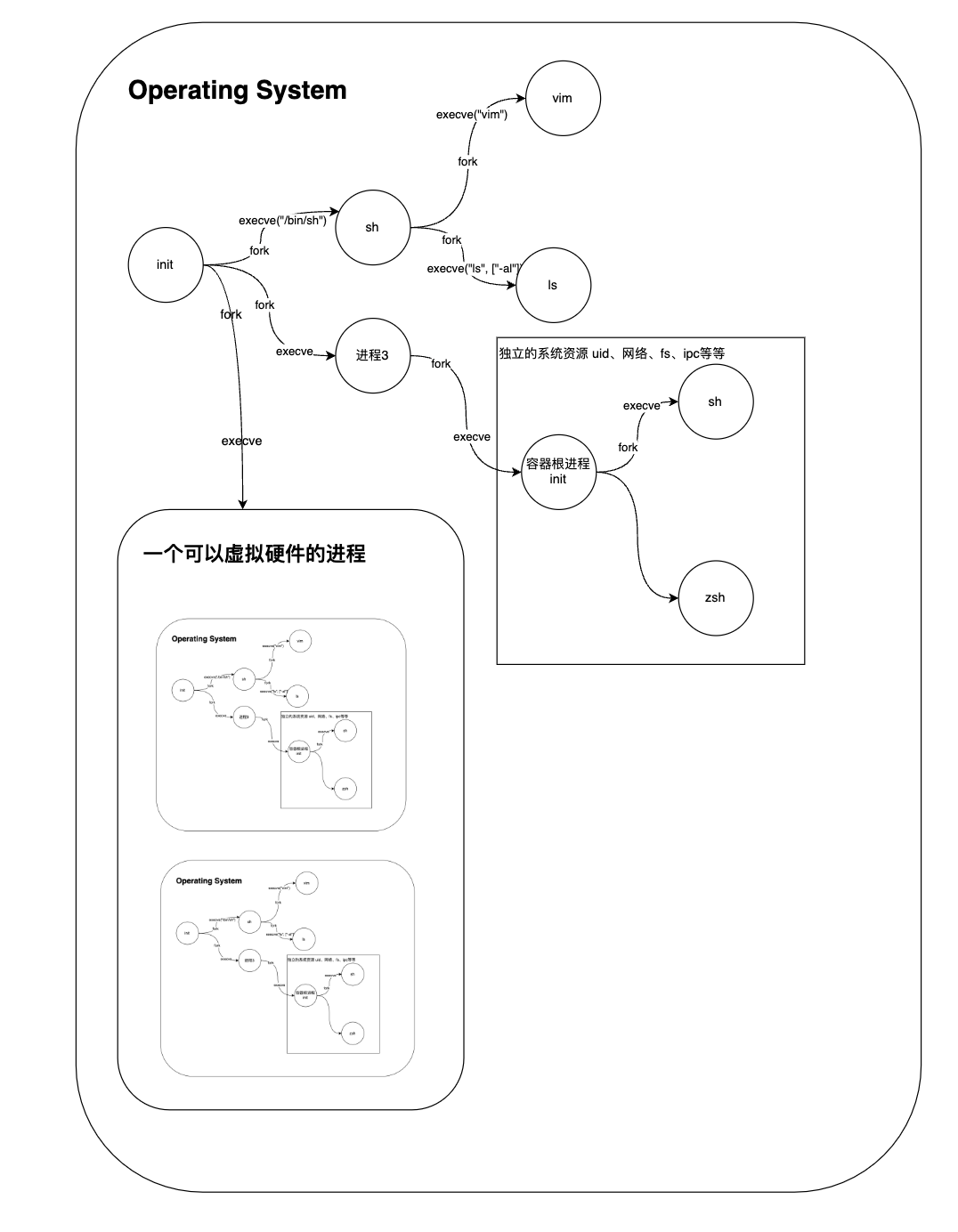
Namespace
Namespace就是限制一组进程与世隔绝,使用自己独立的操作系统资源的魔法,可以理解为是上图中套在一组进程外围的方框。
目前,Linux(针对其提供的全局资源)实现了多种不同类型的namespace,它的目的就是将特定的全局系统资源包装成一个抽象,让在这个namespace中的进程看起来拥有它们自己的全局资源实例,下面是部分关键的:
- Mount: 用于给不同Namespace的进程提供不同的挂载点视图,容器通常将挂载点
/(也就是rootfs)的挂载位置重新挂载成容器提供的rootfs - UTS:不同的Namespace可以有不同的主机名和域名,容器管理程序通常给每一个容器设置自己的主机名和域名
UTS是UNIX Time-sharing System的简写,因为返回主机名和domainname的
uname()系统调用的核心结构体就叫utsname。 - IPC:隔离进程间通信(IPC)资源,即System V IPC对象和POSIX消息队列,每个IPC命名空间有自己的System V IPC标识符和POSIX消息队列文件系统。
- PID:给不同的Namespace提供不同的进程树视图,一个进程只能看到只能看到属于同一个PID Namespace的进程
- Network:隔离和网络相关的系统资源,每一个网络命名空间都有自己的网络设备,IP地址,IP路由表,
/proc/net目录,端口号等。 - User:隔离用户和组ID号空间,允许将一个Namespace中的用户映射到另一个Namespace中的另一个用户,容器经常将非特权用户映射到容器里的root用户
上面对于六种namespace的介绍你可能看的晕乎乎的,很多概念你不理解,没关系,随着文章的推进,我们逐渐都会理解
文件系统、Mount和Umount
我们都知道文件和文件夹是保存在磁盘上的,但磁盘实际上是不知道文件和文件夹的概念的,如果没有操作系统,和它们交流的唯一方式就是通过扇区号来读写512字节的数据......你肯定不想......
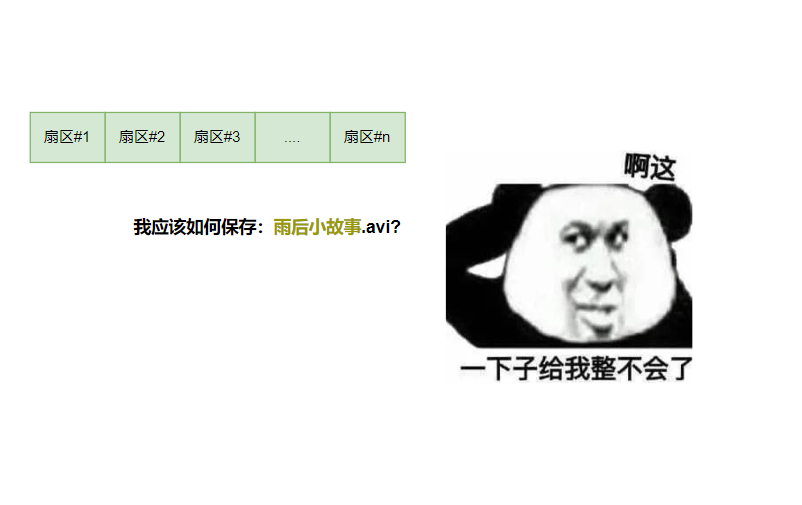
操作系统中的文件系统负责提供文件和文件夹的概念,为了提供这些概念,它们需要在磁盘上建立自己的数据结构。具体使用的数据结构,不同的文件系统可能有不同,这也让它们有各自的性能特性,不过它们都向上提供一致的用户操作接口——文件和文件夹!
mount操作将一个文件系统挂到系统目录树的一个目录下,比如你可能将/dev/sda挂载到/下,这样你就有了操作系统的根目录,被挂载的目录(/)称为挂载点,反之,umount就是卸载这个挂载点。
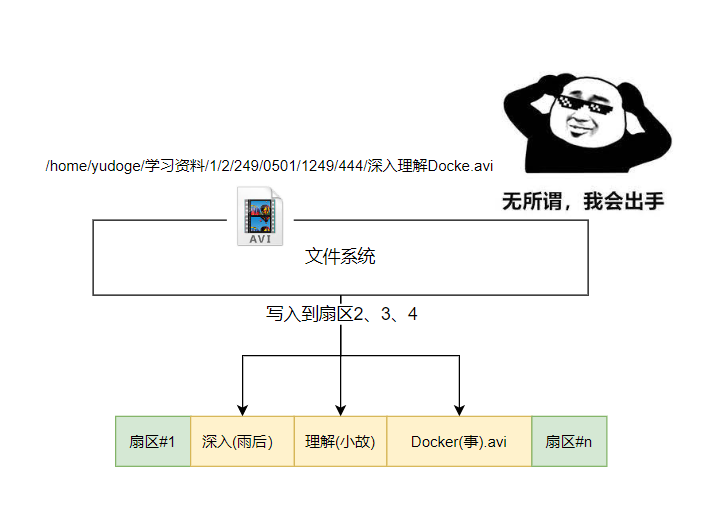
有了/挂载点,我们就可以借用文件系统的接口,在磁盘上创建/home/yudoge/学习资料/1/2/249/050/1249/444/深入理解Docker.avi。
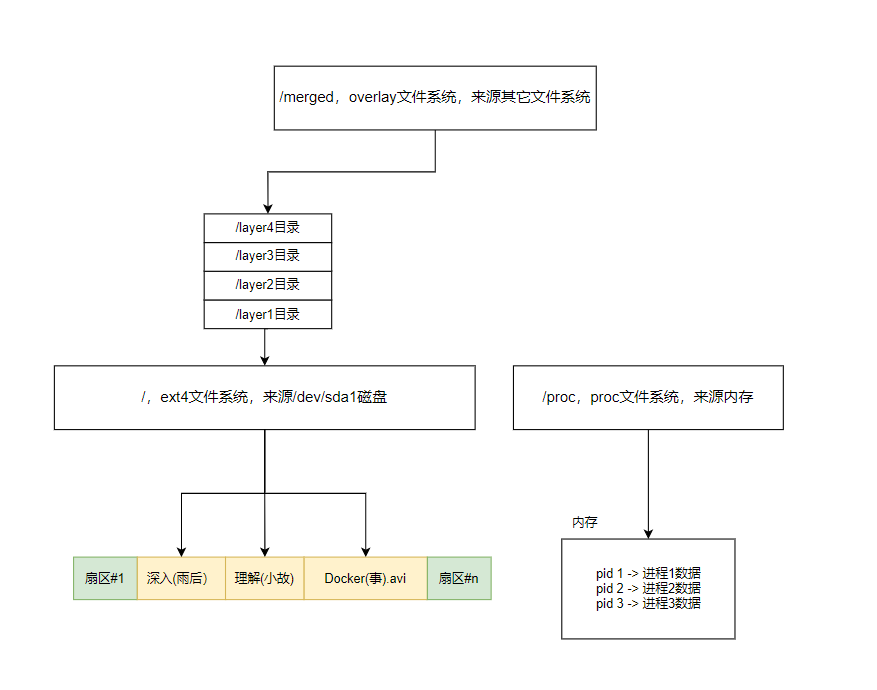
再大胆一点,文件系统数据的来源必须是磁盘吗?既然上层接口都一样,我们可不可以提供一种基于内存的文件系统,或许你看到的文件树只不过是你在数据结构课上写的很6的树结构?是的,linux中大名鼎鼎的procfs就是一个内存文件系统,它保存了所有和运行时进程相关的数据。
还有Docker依赖的OverlayFS,它通过镜像的层级目录以及一个上层容器目录来提供一个整合视图,使得容器能看见这些层级中的所有内容。本次分享也会使用overlayfs挂载文件系统,后续的分享我可能会做和overlayfs相关的,比如使用fuse实现一个用户模式下的层级文件系统。
Namespace API
Linux提供的和Namespace相关的API有三个:
clone:创建一个新进程,可以通过CLONE_NEW*flag来将进程限制在新的独立的namespace中unshare:让当前进程退出当前namespace,进入一个新的独立的namespace中setns:让进程进入指定的namespace
setns已经足够造一个轮子来在外部观察docker容器了
虽然我才讲了三句,但我不知道你有没有同样的感觉,我们或许可以用setns来做点什么,也许是...让我们自己的进程进入docker容器的namespace去偷窥一番?
setns的签名如下:
int setns(int fd, int nstype);
fd可以是多种文件的文件描述符,nstype根据fd种类的不同又有不同解释,这里我们只说它们的一种用法,具体的可以man 2 setns
在我们上面提到的procfs中,保存了每一个进程的多种namespace信息,就在/proc/PID/ns目录下。比如下面是PID为1的init进程的namespace信息:
➜ ~ sd ls -al /proc/1/ns
total 0
dr-x--x--x 2 root root 0 Sep 17 21:03 .
dr-xr-xr-x 9 root root 0 Sep 17 21:03 ..
lrwxrwxrwx 1 root root 0 Sep 17 21:03 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 net -> 'net:[4026531840]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Sep 17 22:07 uts -> 'uts:[4026531838]'
每一个文件都是一个符号链接,这个链接名中间的数字就是namespace的唯一标识,两个进程若某一个文件的标识相同,就说明它们在同一个namespace中。可以认为一个进程在procfs下的ns目录中的一个文件就定位了它所在的某个namespace。
setns的第一个参数可以是一个这种文件的文件描述符,第二个参数用于指定namespace的类型,主要用于系统进行校验,如果你清楚的知道fd代表的namespace类型,你可以直接把nstype填成0。
顺便提一嘴代表这些类型的flag常量,后面经常用到:
CLONE_NEWCGROUP:cgroup namespaceCLONE_NEWIPC:IPC namespaceCLONE_NEWNET:网络namespaceCLONE_NEWNS:mount namespace,因为它是linux支持的第一种namespace类型,所以这个命名是历史原因CLONE_NEWPID:pid namespaceCLONE_NEWTIME:time namespaceCLONE_NEWUSER:用户和组的namespaceCLONE_NEWUTS:主机名和域名的namespace
下面的程序使用setns加入用户指定进程的某个namespace,并执行用户指定命令,如果用户没有指定,默认执行/bin/sh,这使得我们可以启动一个shell,在指定的namespace运行想运行的指令:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include "utils.h"
char *runargv[] = {
"/bin/sh", NULL
};
void print_usage() {
printf("Usage. nsgo <pid> <type> [command. default to /bin/sh]\n");
}
int main(int argc, char *argv[]) {
if (argc < 3) {
print_usage();
exit(1);
}
char *path = join(join(join("/proc", argv[1]), "ns"), argv[2]);
printf("go to namespace %s\n", path);
int fd = open(path, O_RDONLY);
if (fd == -1) {
perror("open");
exit(1);
}
if (setns(fd, 0) == -1) {
perror("setns");
exit(1);
}
if (argc == 4) {
runargv[0] = argv[3];
}
if (execv(runargv[0], runargv) == -1) {
perror("execv");
exit(1);
}
return 0;
}
运行一个docker容器,并查看容器进程的pid:
➜ dogefs git:(master) ✗ docker run --name redis -d redis
046cfec2dc41bed63b6015397b4303af31c0f63b098219ffc10b8c6eab794321
➜ dogefs git:(master) ✗ ps aux | grep redis
999 2207 1.2 0.1 55452 13860 ? Ssl 22:21 0:00 redis-server *:6379
通过nsgo进入容器的mount namespace,并查看/usr/local/bin目录,我们看到了redis相关的一些程序和docker的启动脚本:
➜ dogefs git:(master) ✗ sudo nsgo 2207 mnt
go to namespaec /proc/2207/ns/mnt
# ls /usr/local/bin
docker-entrypoint.sh redis-benchmark redis-check-rdb redis-sentinel
gosu redis-check-aof redis-cli redis-server
所以,docker通过mount namespace为容器提供了一个独立于外层操作系统的rootfs文件系统视图,如果我们在外层操作系统中运行同样的命令,将得到截然不同的结果:
➜ dogefs git:(master) ✗ ls /usr/local/bin
choose-mirror cinf Installation_guide livecd-sound nsgo
clone——找找手撸容器的感觉
clone系统调用创建一个子进程,并可以指定子进程在哪些新的namespace中,没被指定的那些namespace继承旧的。
clone可以看作是fork的一个通用版本,fork创建子进程的行为硬编码在其内部,而clone可以通过flags控制。
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...);
fn是新进程的入口函数,新进程会从这个函数开始执行stack是新进程的栈flags允许你指定新进程的一些行为方式,比如为新进程创建哪些新的namespace- ...
我们使用clone创建一个uts namespace,并修改容器的hostname和domainname:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <syscall.h>
#include <linux/fs.h>
#include <stdlib.h>
#define STKSZ (1024 * 1024)
char stk[STKSZ];
int container_main() {
sethostname("inside container", 16);
setdomainname("inside container", 16);
system("/bin/bash");
}
int main() {
int childpid;
if ((childpid = clone(container_main, stk + STKSZ, CLONE_NEWUTS | SIGCHLD, NULL)) == -1) {
perror("clone");
exit(1);
}
waitpid(childpid, NULL, 0);
return 0;
}
我们创建了一个1MB的char数组来作为新进程的栈大小,由于栈自顶向下,所以我们要将它的尾指针传入clone,也就是stk + STKSZ,flag传入CLONE_NEWUTS,这样新创建的进程在一个新的,独立的uts namespace上,和主机隔离主机名和domainname信息,SIGCHID。
container_main作为新进程的入口函数,在其内部设置了主机名和域名,这并不会影响外部的namespace。最后使用system打开一个bash命令行,使得我们可以执行想要的指令观察效果。
编译运行:
➜ dogefs git:(master) ✗ gcc -o uts uts.c
➜ dogefs git:(master) ✗ sudo ./uts
[sudo] password for yudoge:
[root@inside container dogefs]# uname -a
Linux inside container 6.5.3-arch1-1 #1 SMP PREEMPT_DYNAMIC Wed, 13 Sep 2023 08:37:40 +0000 x86_64 GNU/Linu
从提示符就可以看到我们的主机名变成了inside container。而在该进程外部,操作系统默认的namespace中,我们的主机名是yudoge-arch:
➜ dogefs git:(master) ✗ uname -a
Linux yudoge-arch 6.5.3-arch1-1 #1 SMP PREEMPT_DYNAMIC Wed, 13 Sep 2023 08:37:40 +0000 x86_64 GNU/Linux
unshare
unshare放弃当前进程的某些namespace,创建新的namespace并加入其中。
下面是上一个程序的unshare版:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <syscall.h>
#include <linux/fs.h>
#include <stdlib.h>
int main() {
if (unshare(CLONE_NEWUTS)) {
perror("clone");
exit(1);
}
sethostname("inside container", 16);
setdomainname("inside container", 16);
system("/bin/bash");
return 0;
}
东西都给你了,可以撸个容器出来了吧
从刚刚的内容中,我们可以看出,容器类似于一个隔离的,全新的操作系统,其中有Linux的文件系统结构(rootfs),有必要的命令行工具(/bin/ls),有容器运行起来必要的软件(redis-server)。Docker通过将自己准备好的最小rootfs挂载到容器进程的Mount Namespace的/目录来做到这一点:
➜ ~ sudo nsgo 2205 mnt
go to namespaec /proc/2205/ns/mnt
# ls
bin data etc lib lib64 media opt root sbin sys usr
boot dev home lib32 libx32 mnt proc run srv tmp var
那么从哪里得到一个rootfs呢?
Busybox的RootFS
Busybox是一个集成了很多的UNIX命令到一个单一可执行程序的项目,我们可以用它构建出一个简单的rootfs。
下载busybox-1.36.1.tar.bz2,解压,进入源码目录,执行make menuconfig打开编译配置菜单:
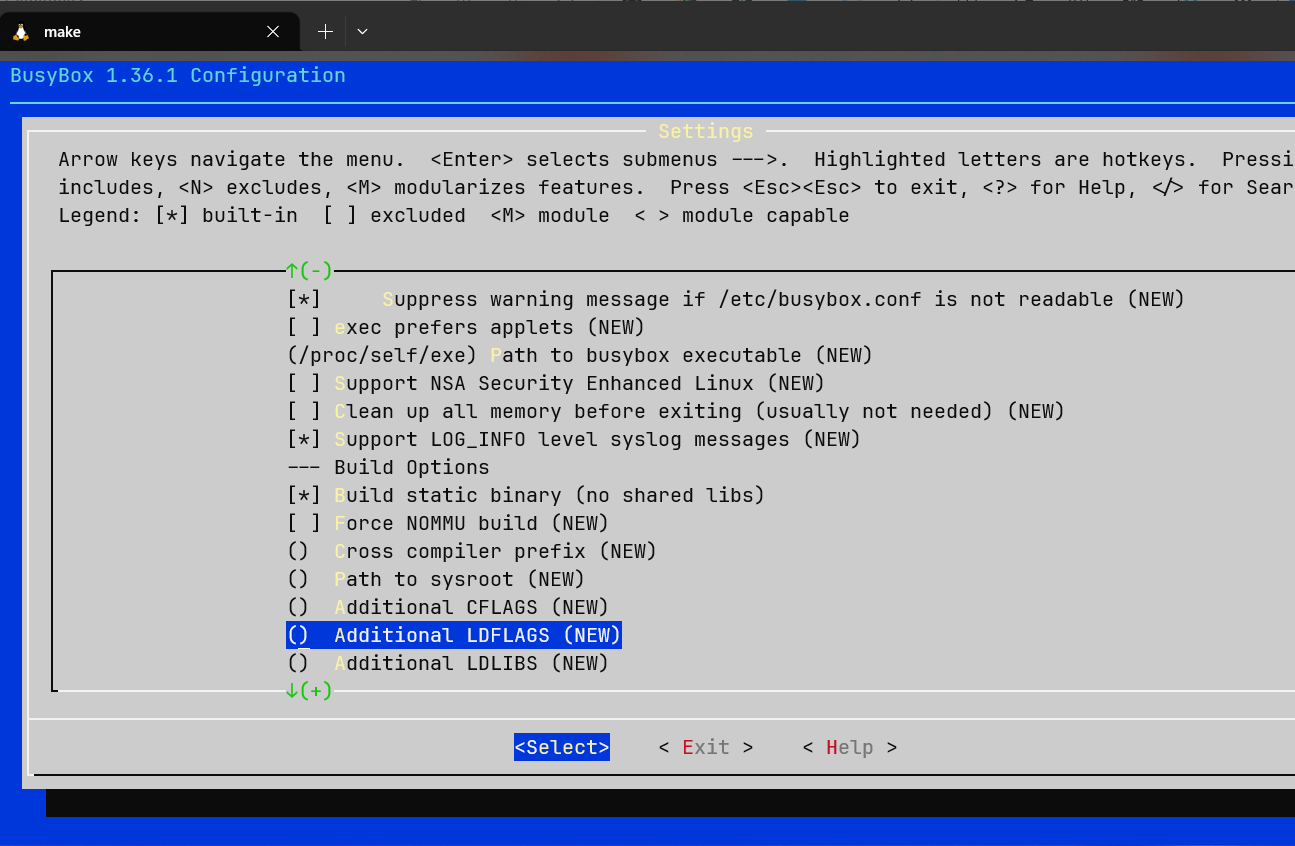
选择Build static binary,这样我们就可以构建出一个不依赖其它共享库的独立的rootfs。
make,然后make install CONFIG_PREFIX=./rootfs,这样我们就得到了一个干净的rootfs,我们cd进去,执行其中./bin目录下的一些程序:
➜ busybox-1.36.1 cd rootfs
➜ rootfs ls
bin linuxrc sbin usr
➜ rootfs ./bin/ls
bin linuxrc sbin usr
➜ rootfs ./bin/sh
~/tmp/busybox-1.36.1/rootfs $
创建一些基本的目录:
➜ rootfs mkdir dev etc home lib mnt proc root sys tmp var -pmkdir dev etc home lib mnt proc root sys tmp var -p
➜ rootfs ls
bin dev etc home lib linuxrc mnt proc root sbin sys tmp usr var
棒,现在已经有模有样了!
Mount Namespace,挂载RootFS
模板程序
下面是我们的模板程序,后面我们实现一个容器的过程都将在这个模板之上创建,需要注意的就是,我们通过try宏来包装Linux系统调用,处理异常,并在异常时关闭:
#define try(s, m) if ((s)==-1) {perror(m);exit(1);}
#define STACKSZ (1024 * 1024)
char container_stk[STACKSZ];
char* const runargs[] = {
"/bin/sh",
NULL
};
void container_exit() {
// container exit...
}
int container_main() {
atexit(container_exit);
// container entry...
}
int main() {
int container_pid;
try(container_pid=clone(container_main, container_stk + STACKSZ, CLONE_NEWNS | SIGCHLD, NULL), "clone");
waitpid(container_pid, NULL, 0);
return 0;
}
上面的clone代码就相当于:
if ((container_pid=clone(xx)) == -1) {
perror("clone");
exit(1);
}
container_main是容器进程的入口函数,container_exit是容器进程的结束函数,我们在入口通过atexit系统调用注册进程的退出钩子。
使用pivot_root挂载根文件系统
我们通过mount系统调用使用和Docker一样的overlayfs来挂载根文件系统,其最底层目录overlay/0即是我们刚刚编译的rootfs(我忽略了cp的步骤)
int container_main() {
atexit(container_exit);
int pid;
printf("container enter...");
try(mount("rootfs", "./mp", "overlay", 0, "upperdir=overlay/4,lowerdir=overlay/3:overlay/2:overlay/1:overlay/0,workdir=work"), "mount");
try(mount(NULL, "./mp", NULL, MS_PRIVATE | MS_REC, NULL), "mount make mp private");
try(mount(NULL, "/", NULL, MS_PRIVATE | MS_REC, NULL), "mount make rootfs private");
try(chdir("./mp"), "chdir");
try(mkdir("./putold"), "mkdir");
try(pivot_root(".", "putold"), "pivot_root");
try(pid=fork(), "forksh");
printf("forked pid => %d\n", pid);
if (pid == 0) {
try(execv(runargs[0], runargs), "execv");
} else {
waitpid(pid, NULL, 0);
exit(0);
}
return 0;
}
在我们上面的代码中,我们把rootfs挂载到./mp下,通过我们之前提到过的overlay文件系统,然后我们通过两个mount让./mp挂载点和/挂载点成为私有的,这是后面pivot_root系统调用的要求。
之后,我们进入./mp目录,在其中创建putold目录,然后使用pivot_root系统调用,它会将当前的rootfs挂载到第二个参数提供的目录上,然后把第一个参数作为新的rootfs挂载到/。由于我们在新的mount namespace,所以整个操作系统中的其它namespace的/挂载点并不受影响(况且我们已经将它make-private了)。
- 为什么不直接通过
mount来remount rootfs?pivot_root和chroot的区别?➜ dogefs git:(master) ✗ sudo ./container container enter...forked pid => 5134 container enter...forked pid => 0 / # ls /bin/sh: ls: not found / #
overlayfs是一个联合文件系统,它不提供真正的传统磁盘文件系统,而是将其它文件系统中的多个目录整合,比如这里将overlay目录下的
4,3,2,1,0整合,4作为顶层目录,其它的作为低层目录,文件系统展示这些层级的合并视图,顶层目录是可读可写的,所有低层目录的写入都要先将文件复制到顶层,再进行写入。这也是docker镜像的层级原理,下一次分享时我大概会分享overlayfs相关的,使用fuse编写一个自己的overlayfs。
现在编译运行,我们发现无法执行命令:
➜ dogefs git:(master) ✗ sudo ./container
container enter...forked pid => 5134
container enter...forked pid => 0
/ # ls
/bin/sh: ls: not found
/ #
/bin/sh告诉我们ls没找到,这是因为我们没有PATH环境变量,我们一会儿会修复它,现在我们先委屈一下,使用/bin/前缀。
你会发现确实由pivot_root系统调用所保证的那样,当前根目录变成了我们准备好的rootfs,也就是外部的./mp文件夹,而./mp/putold则被挂载成为了以前的rootfs。
/ # /bin/ls /
README.md etc lib proc sbin tmp
bin hello.txt linuxrc putold sys usr
dev home mnt root test.txt var
/ # /bin/ls putold
bin etc lost+found proc srv var
boot home mnt root sys version
d lib opt run tmp
dev lib64 out sbin usr
/ #
作为一个容器,我们肯定不希望外部的rootfs被容器内所见到,所以我们可以使用umount命令卸载掉它,也可以直接使用pivot_root(".", ".")。下面的示例中我们使用了第二种方式,并且少了一个mkdir系统调用:
int container_main() {
atexit(container_exit);
int pid;
printf("container enter...");
try(mount("rootfs", "./mp", "overlay", 0, "...省略..."), "mount");
try(mount(NULL, "./mp", NULL, MS_PRIVATE | MS_REC, NULL), "mount make mp private");
try(mount(NULL, "/", NULL, MS_PRIVATE | MS_REC, NULL), "mount make rootfs private");
try(chdir("./mp"), "chdir");
// [+] note this line
try(pivot_root(".", "."), "pivot_root");
try(pid=fork(), "forksh");
printf("forked pid => %d\n", pid);
if (pid == 0) {
try(execv(runargs[0], runargs), "execv");
} else {
waitpid(pid, NULL, 0);
exit(0);
}
return 0;
}
设置环境变量
刚刚我们进入容器时,由于没设置环境变量,导致所有命令无法执行,我们可以在pivot_root后通过setenv系统调用设置正确的环境变量:
try(pivot_root(".", "."), "pivot_root");
try(setenv("PATH", "/bin:/usr/bin:/usr/sbin:/sbin", 1), "setenv");
try(pid=fork(), "forksh");
printf("forked pid => %d\n", pid);
现在已经可以正确执行指令:
➜ dogefs git:(master) ✗ sudo ./container
container enter...forked pid => 5726
container enter...forked pid => 0
/ # ls
README.md etc lib proc sys usr
bin hello.txt linuxrc root test.txt var
dev home mnt sbin tmp
/ #
shared subtree机制带来的语句顺序问题
我们已经mount了./mp,在操作系统的默认mount namespace中这个挂载也是可见的:
➜ dogefs git:(master) ✗ mount | grep overlay
rootfs on /home/yudoge/workspace/learn/dogefs/mp type overlay (rw,relatime,lowerdir=/home/yudoge/workspace/learn/dogefs/overlay/3:/home/yudoge/workspace/learn/dogefs/overlay/2:/home/yudoge/workspace/learn/dogefs/overlay/1:overlay/0,upperdir=/home/yudoge/workspace/learn/dogefs/overlay/4,workdir=/home/yudoge/workspace/learn/dogefs/work)
➜ dogefs git:(master) ✗ cd mp
➜ mp ls
bin etc home linuxrc proc root sys tmp var
dev hello.txt lib mnt README.md sbin test.txt usr
这意味着在容器退出后,我们需要在外部的mount namespace中手动取消挂载(或者也可以在main函数的waitpid后使用程序清理),这是因为shared subtree机制,如果我们把之前代码的语句顺序调节一下,我先给/这个挂载点make private,然后再挂载mp,然后再给mp make private,外部就不会看到容器内部的挂载
try(mount(NULL, "/", NULL, MS_PRIVATE | MS_REC, NULL), "mount make rootfs private");
try(mount("rootfs", "./mp", "overlay", 0, "...省略..."), "mount");
try(mount(NULL, "./mp", NULL, MS_PRIVATE | MS_REC, NULL), "mount make mp private");
shared subtree又是一个很大的话题,本次分享无法囊括,不过可以知道的是docker显然没有让容器内部的rootfs挂载点对外部私有,我们可以在外部的namespace中观察这个挂载。
让容器拥有自己的进程视图——PID Namespace
挂载procfs
现在,进入我们的容器,你会发现执行ps aux时,什么也没有出现!
/ # ps aux
PID USER TIME COMMAND
还记得我们在利用busybox构建rootfs时所作的操作吗,我们创建了rootfs下的proc目录,它就是一个普通的目录,里面什么也没有。
procfs给出了进程的全部信息,很多系统工具的运行依赖procfs,所以若它没被正确挂载,ps无法正常工作是预期之内的,甚至还有很多其它东西也无法运行。我们先修改代码,将procfs正确挂载到/proc目录下
try(pivot_root(".", "."), "pivot_root");
try(setenv("PATH", "/bin:/usr/bin:/usr/sbin:/sbin", 1), "setenv");
+try(mount("proc", "/proc", "proc", 0, NULL), "mount procfs");
try(pid=fork(), "forksh");
编译运行,这时你再在容器中执行ps aux,你会发现,你看到了容器外部所有进程:
➜ dogefs git:(master) ✗ sudo ./container
container enter...forked pid => 7426
container enter...forked pid => 0
/ # ps aux
PID USER TIME COMMAND
1 0 0:01 {systemd} /sbin/init
2 0 0:00 [kthreadd]
3 0 0:00 [rcu_gp]
...省略...
这是正确的行为,因为我们的进程尚处于系统默认的PID Namespace,没有任何隔离,所以我们能看到和容器外部一致的进程树视图。我们不希望这样,所以要给clone系统调用添加新的flag来修正这一行为
隔离PID Namespace
// 加入 CLONE_NEWPID flag
try(container_pid=clone(container_main, container_stk + STACKSZ, CLONE_NEWNS | CLONE_NEWPID | SIGCHLD, NULL), "clone");
waitpid(container_pid, NULL, 0);
编译运行,重新进入容器,你会发现,我们在container main中调用fork后打印的日志中的pid都已经变了,原来它展示的是进程在默认PID Namespace中的PID,它有几千那么大,现在它展示的是容器内部新的PID Namespace中的进程号,是2。
➜ dogefs git:(master) ✗ sudo ./container
container enter...forked pid => 2
container enter...forked pid => 0
/ # ps aux
PID USER TIME COMMAND
1 0 0:00 ./container
2 0 0:00 /bin/sh
3 0 0:00 ps aux
我们用ps命令查看,可以看到现在有三个进程,PID分别为1、2、3,container是容器的父进程,它作为整个容器PID Namespace的根进程(init进程!),当出现孤儿进程时,也就是一个子进程的父进程突然挂了,它需要接管这个进程作为自己的子进程,所以我们的container想要完善,还要注册一些信号处理程序,但是这不是本次分享的范围。
/bin/sh是父进程创建出来的子进程,运行一个shell,而ps aux则是sh创建出来的一个子进程,运行/bin/ps程序。
一个进程居然有两个PID??
如果我们在容器外部观察容器进程(我们通过ps看到了它的pid是10095),你会看到不一样的进程树结构:
➜ dogefs git:(master) ✗ pstree -p 10095
container(10095)───sh(10096)
container在容器内部的PID Namespace中,PID为1,sh为2,而在容器外部的默认PID Namespace中,它的进程号为10095,sh的为10096。
我们看到了一个有趣的现象,一个进程具有两个PID,这取决于在哪个Namespace中观察。getpid和getppid系统调用永远以当前Namespace的为准。
如果你查看刚刚我们启动的docker容器——redis,你也会发现,它们在外部的Namespace中有其他的PID:
➜ dogefs git:(master) ✗ pstree -p 1831
redis-server(1831)─┬─{redis-server}(1865)
├─{redis-server}(1866)
├─{redis-server}(1867)
└─{redis-server}(1868)
这貌似就是redis的一个Work Thread,四个IO Thread?我也不知道,瞎说的。
给容器进行用户隔离——User Namespace
不得不说我们现在容器内部的用户权限是有问题的,这导致很多命令执行不了。当你在根目录下ls的时候,你会发现有些文件属于0,有些文件属于1000
/ # ls -al
total 1268
drwxr-xr-x 1 1000 1000 4096 Sep 22 15:12 .
drwxr-xr-x 18 0 0 4096 Sep 14 05:40 ..
-rw-r--r-- 1 1000 1000 292 Sep 4 05:59 README.md
drwxr-xr-x 1 1000 1000 4096 Sep 23 01:59 bin
drwxr-xr-x 2 1000 1000 4096 Sep 23 01:59 boot
drwxr-xr-x 2 1000 1000 4096 Sep 23 01:59 dev
如果容器没有创建新的User Namespace,那么这些uid和gid将按照系统默认的User Namespace来解释,0解释为root,1000解释为yudoge(也就是我的用户)。
我们不希望容器内部和外部共用一个User Namespace,所以需要给clone指定新的flag来隔离,但当你指定了CLONE_NEWUSER时,你发现你无法mount了!
// 加入新的 CLONE_NEWUSER
try(container_pid=clone(container_main, container_stk + STACKSZ, CLONE_NEWNS | CLONE_NEWUSER | CLONE_NEWPID | SIGCHLD, NULL), "clone");
➜ dogefs git:(master) ✗ sudo ./container
mount: Permission denied
container enter...container exit...%
WTF?? 我们把mount后的一系列操作注释掉,进入一个shell看发生了啥:
int container_main() {
atexit(container_exit);
int pid;
printf("container enter...");
// try(mount(NULL, "/", NULL, MS_PRIVATE | MS_REC, NULL), "mount make rootfs private");
// try(mount("rootfs", "./mp", "overlay", 0, "upperdir=/home/yudoge/workspace/learn/dogefs/overlay/4,lowerdir=/home/yudoge/workspace/learn/dogefs/overlay/3:/home/yudoge/workspace/learn/dogefs/overlay/2:/home/yudoge/workspace/learn/dogefs/overlay/1:overlay/0,workdir=/home/yudoge/workspace/learn/dogefs/work"), "mount");
// try(mount(NULL, "./mp", NULL, MS_PRIVATE | MS_REC, NULL), "mount make mp private");
// try(chdir("./mp"), "chdir");
// try(pivot_root(".", "."), "pivot_root");
// try(setenv("PATH", "/bin:/usr/bin:/usr/sbin:sbin", 1), "setenv");
// try(mount("proc", "/proc", "proc", 0, NULL), "mount procfs");
// try(pid=fork(), "forksh");
// printf("forked pid => %d\n", pid);
// if (pid == 0) {
try(execv(runargs[0], runargs), "execv");
// } else {
// waitpid(pid, NULL, 0);
// exit(0);
// }
return 0;
}
我们竟然变成了nobody!是这样,建立一个新的User Namespace过后,进程的用户就是nobody。
sh-5.1$ whoami
nobody
sh-5.1$ id
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody)
我们需要修正这一行为,/proc/${pid}/uid_map和/proc/${pid}/gid_map是两个关键文件,它代表了Namespace内部的uid如何映射到Namespace外部的uid。
有点绕,举个例子,我们通常希望容器内部以root运行,但我们又不想真的分配给它整个系统的root权限,万一出点什么漏洞,整个系统它都能越权操作了。这时我们就希望如果可以把容器外部的User Namespace中的一个非特权用户,映射到容器内部的root,让它在容器的Namespace中具有root的权限,在外部的Namespace中只具有普通用户的权限就好了。
/proc/${pid}/uid_map用于完成这件事,该文件可以包含多行,每一行表示外部uid与内部uid的一个范围的映射,由三个数字组成:
ID-inside-ns ID-outside-ns length
第一个是在namespace内部的uid起始,第二个是在namespace外部的uid起始,length是映射的范围,比如下面的uidmap就将外部的一个普通用户(uid=1000)映射到了内部的特权用户(uid=0)
0 1000 1
我们可以在容器的父进程中写入这俩文件:
void write_usernsfiles(int pid) {
char path[100];
snprintf(path, 100, "/proc/%d/uid_map", pid);
printf("pathis %s\n", path);
write_file(path, "0 1000 1");
snprintf(path, 100, "/proc/%d/gid_map", pid);
write_file(path, "0 1000 1");
}
int main() {
try(container_pid=clone(container_main, container_stk + STACKSZ, CLONE_NEWUSER | CLONE_NEWNS | CLONE_NEWPID | SIGCHLD, NULL), "clone");
write_usernsfiles(container_pid);
// ...
}
现在,容器和外部的写入uidmap操作是并发的,我们希望这个操作完成后再执行容器中的代码,一个简单的办法就是可以sleep两秒,但我们要玩就好好玩,我们创建一个pipe,用于父子进程之间通信,容器进程进入后阻塞在管道的读口上,父进程初始化后关闭管道的写口,这样子进程就会读到一个EOF,退出阻塞。
int main() {
int container_pid;
// 创建管道
try(pipe(pipefd), "create pipe");
// 关闭读口,用不到
close(pipefd[0]);
try(container_pid=clone(container_main, container_stk + STACKSZ, CLONE_NEWUSER | CLONE_NEWNS | CLONE_NEWPID | SIGCHLD, NULL), "clone");
write_usernsfiles(container_pid);
// 做完所有操作,关闭读口
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
return 0;
}
int container_main() {
atexit(container_exit);
int pid; char ch;
// 关闭写口,用不到
close(pipefd[1]);
// 阻塞在读口
read(pipefd[0], &ch, 1);
printf("container enter...\n");
// ...继续做后面的操作
}
重新编译执行:
/ # whoami
root
/ # id $(whoami)
uid=0(root) gid=0(root) groups=0(root)
尚不能解释的
- 为什么
..和proc的owner是nobody - 为什么root还有个
nobody组
观察Docker
查看docker containerd的pid
➜ dogefs git:(master) ✗ ps aux | grep containerd │ (Connection timed out)
root 100439 0.0 2.0 1283564 20568 ? Ssl Apr2│[pid 100445] epoll_pwait(4, <unfinished ...>
6 178:40 /usr/bin/containerd
100439,我们用strace attach到它,然后启动一个容器,观察系统调用。strace会输出到stderr上,我们把stderr重定向到out文件。
strace -p 100439 -f 2>out
run一个容器:
docker run --name redis -d redis
docker通过unshare创建了新的User Namespace,写入进程2106345到uid_map和gid_map,设置uid为0,然后又通过unshare创建了新的Mount、UTS、IPC、PID和Net Namespace
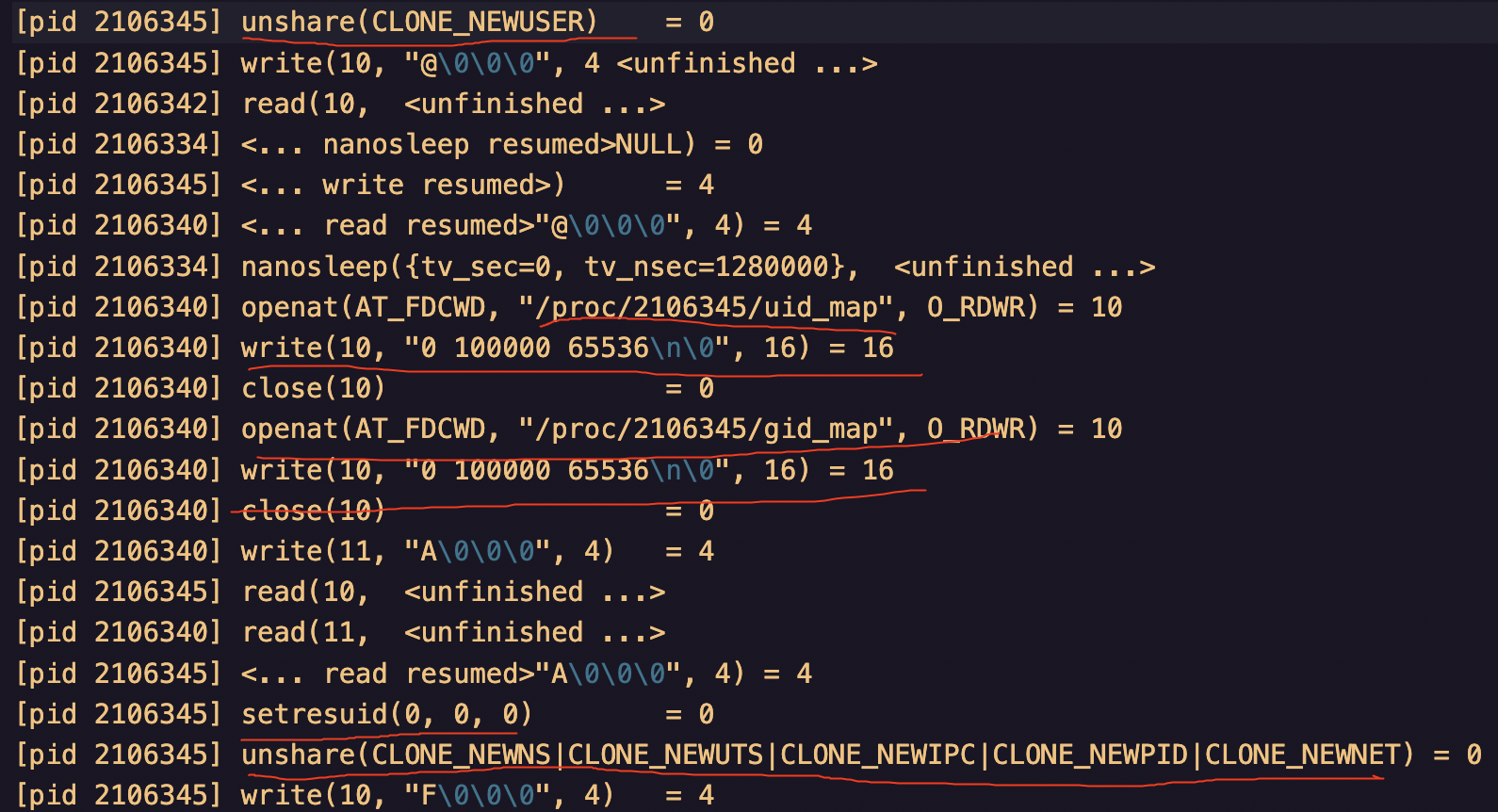
在外侧,我们可以看到新启动的redis容器进程的PID正是2106345

Docker默认不使用User Namespace,需要在
/etc/docker/daemon.json中写入:{ "userns-remap": "ubuntu" }
也有使用pivot_root重新挂载rootfs的代码:

