编译?汇编?链接?
前言
我还记得在我大一的时候上C语言课,老师的期末实验是用C语言写一个命令行的管理系统,本着模块化的思想,我很自然的想到系统中具有不同职责的模块应该分到不同的文件里去,但我真的不知道C语言该怎么做这种拆分,所以最后我用一个巨大无比的文件完成了实验。
现代编程语言经过层层抽象封装,绝大部分复杂的细节都被隐藏在简单的接口之下了,在使用Java、Python等编程语言时,你甚至不用考虑多个文件是如何被组织在一起的,你想用一个其它文件里的东西(符号),import它就好了,编译器(或解释器)会帮你做后面的一切工作,对于生产力来说,这是一个好事,但它的坏处就是,我们几乎从不考虑这中间发生了什么,所以,当我使用没有import的C语言时,哥们废了。
初学者可能以为
#include就是import(也许只有我一个初学者这么认为),但它们的语义完全不一样,#include只是告诉编译器在预编译阶段将某个文件里的内容粘贴过来。
在学习C语言时,老师一定都讲过下面几句话:
- C语言是高级语言,计算机不能直接执行,需要编译成机器代码才能执行在计算机上
- C语言的运行机制骤是:编辑、编译、链接、执行
- C语言程序的执行从
main开始,到main的最后一行语句结束
但是,对这些话,我们了解的又有多少?如果站在非C语言开发者的角度,而是机器的角度,这里面的某些话还合理吗?链接阶段到底是在干什么?什么是动态链接库?面试时候要背的“Java的类加载机制”其中的每一步骤的实际目的是?
本篇文章想尽量简单的向你回答这些问题,但它们涉及到的范围太广,如果要深入到最底层,甚至要了解很多硬件相关的知识。所以,我尽量站在一个应用软件程序员的角度来写这篇文章,并且希望在读完本篇文章后,上面这些问题在你心里都会有了清晰的答案。对于一些比较有经验的人,文章的前面某些部分可能显得啰嗦,那些你们都懂了!但是想想我在写实验时想分模块又无助的样子,我还是打算把这些简单的内容也写上,多担待啦!
如何阅读本文
为了阐明道理,本文会涉及到一些实际操作,比如我们会手动的对一个简单的C语言程序进行预编译、编译、汇编、链接等步骤;我们会手写汇编代码并尝试将它运行在机器上;后面我们可能还会利用Java提供的一些工具来研究并理解Java的类加载机制。
所以,如果你不想动手,只是跟着看看,可能看到一半你就已经不知道我在说什么了,因为你从没亲自体验我所说的东西,你也就错过了思考很多藏在暗处的细节的机会。
本文使用到的工具有gcc、gdb、objdump、hexdump、readelf等,可能还会有一些JDK中的工具,不要害怕,因为上面提到的大部分工具,在任何一个Linux发行版中都已经自带,就算没有,你也可以通过各种发行版上的包管理工具轻易获得,你几乎不用手动编译任何软件。
推荐使用WSL,也可以购买一台虚拟主机,并安装Linux系统,也可以使用VMWare等工具。
对于上面提到的每一个软件,如果你想掌握全部用法都需要花些时间去阅读手册,好在本文只用到其中的很少一部分功能,即使是这样,如果你脑袋里出现了“我又没有比文章里更简单的办法来完成相同的操作”这种念头,立即去阅读工具的官方文档或man page。
阅读文档是建立正确概念的最快途径。就用我在文章开头举的例子来说,当时我遇到了这个问题,我就去百度:“如何将C语言程序拆分成多个文件”、“如何在一个C文件中引用另一个文件的内容”。事情会有两个结果:
- 你跟着CSDN或者其它博客做了很久,终于成功了,但你并不理解发生了什么,如符号、预编译、链接、#include语义这些概念你并没有掌握,你也不知道为啥成功了(大部分情况下博文的编写者也没有掌握,只是盲目记录,尤其CSDN)。
- 大量的新名词(如第一点中提到的)涌向你,但却没人给你解释它们都是什么意思,你退缩了,选择在一个文件中编程
显然,在当时,我的结果是后者,但实际上,如果你去阅读官方文档,其中都清晰地解释了什么是预编译、当你#include后会发生什么等。把这些概念搞清楚可能需要花费一些时间,乍一看不划算,但你节省的是大量后续出了问题之后,因为你并不真正理解而盲目的花在百度和劣质博文上的时间。每一次百度,事情又会有上面那两种结果。
所以,请大胆阅读文档!
符号
第一个要引入的概念就是——符号。
我们的程序中有各种各样的符号,在下面这个短短的程序中就包含了三个符号,main、printf以及sum:
// main.c
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
所谓符号,就是人为定义的一个名字,通过main这个名字,我们能找到主函数,通过sum这个名字,我们能找到一个对两个数字执行加和并返回的函数,通过printf这个名字,我们能找到一个按照我们给定的格式进行控制台输出的函数。
这段代码中并没有给出sum和printf的定义,因此,若现在我们编译main.c,编译器肯定不知道printf和sum去哪里找:
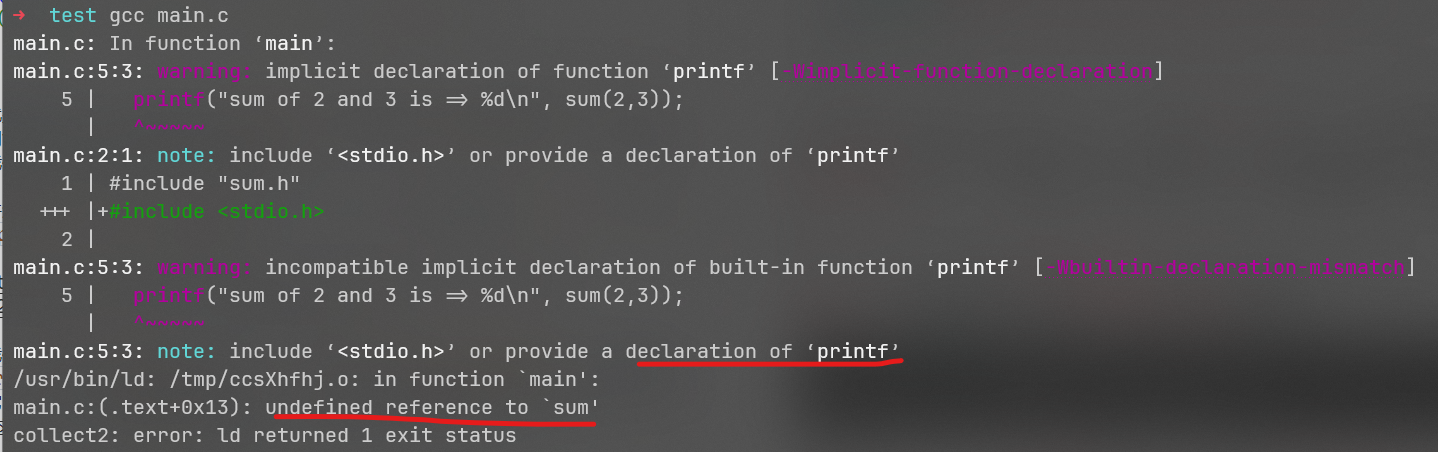
编译器告诉我们,对于printf这个符号,要么你就#include <stdio.h>,要么你就提供一个printf的定义。当然,由于printf太常用了,所以即使你什么都不做gcc也会正常的提供它(具体怎么提供我们后面会聊到),它只是给你一个警告告诉你你最好怎么做。但对于sum就没这么幸运了,编译器无情的告诉我们sum未定义,然后就退出了。
要想使该程序通过编译,那你就要提供这两个符号:
#include <stdio.h>
int sum(int a, int b) {
return a + b;
}
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
再次编译运行:
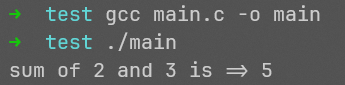
所以,如果你用gcc编译,你必须得让它知道源代码中的每个符号如何解析,gcc是一个智能的编译器,所以有些东西它默认就知道,但就算它本事再大,它也不知道由你定义的符号(比如sum)该怎么解析。
拆分多个文件
有了上面对于符号的理解,好像将项目拆分成多个文件进行开发也不是很难了。每一个文件中会定义一些符号,系统中的所有文件之间会相互调用,在使用gcc进行编译时,只要让gcc能够找到所有用到的符号就行。
比如我们把sum拆分到单独的文件——sum.c中:
// sum.c
int sum(int a, int b) {
return a + b;
}
// main.c
#include <stdio.h>
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
然后,把它们都喂给gcc就好啦!

虽然程序能够正确编译并运行,但gcc给我们弹了个warning,它说在main中的sum是隐式定义的。是的,对于main.c来说,sum是什么样的,接受什么类型的参数,返回什么类型的值,这些都没有明确的定义,虽然编译时恰好在sum.c中找到了一个sum符号,并完成了编译。
在C语言中,如果你调用一个函数,该函数的原型必须已经被定义了,所以,正确的做法是在main中定义sum函数的原型。
// main.c
#include <stdio.h>
int sum(int a, int b);
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
这样,该程序才算完整!
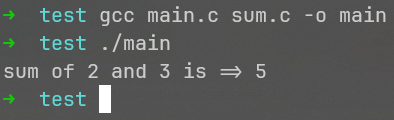
所以,什么是#include?
在进行C开发时,我们经常会遇到.h文件和.c文件,从本质上来看,它们都是文本文件,没有任何区别,只不过我们通常习惯用.h来保存所有的定义(当然包括函数原型定义),用.c来保存实际的代码文件。
前面我们知道了在C语言源文件中,你要想调用一个函数,它的原型必须在该文件中被定义过,考虑你在编写一个模块,其中有很多函数或功能要暴露给其它文件,这说明所有使用你模块提供的函数的文件都要将这些函数的原型重新定义一遍,就像我们在main.c中必须定义sum的原型才能消除编译器给的烦人的warning。.h的意义就在于此,它其中包含.c文件中想要暴露的所有内容,供其它文件直接#include,而不用重新定义一遍。
所以,我们可以将上面的例子转化成:
// sum.c
int sum(int a, int b) {
return a + b;
}
int sum3(int a, int b, int c) {
// 添加一个新的想要暴露给外界的函数
return a + b + c;
}
// sum.h
int sum(int a, int b);
int sum3(int a, int b, int c);
// main.c
#include <stdio.h>
#include "sum.h"
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
这样,不管有多少个文件想要使用sum.c中的函数,只需要#include "sum.h",就不再需要自己进行原型定义了。
至此,#include的功能也呼之欲出,它只是将指定文件中的内容复制到本文件中而已,上面main.c中的#include语句就是将sum.h中的两个原型定义复制到main.c中,sum.h并不实际参与编译。
像#include这种带#的指令叫做预编译指令,实际上,C语言程序在编译之前会经历预编译的步骤,我们后面会介绍,预编译阶段按照对应预编译指令的语义处理所有预编译指令,对于#include,就是复制其指定的文件中所有的内容到本文件中。
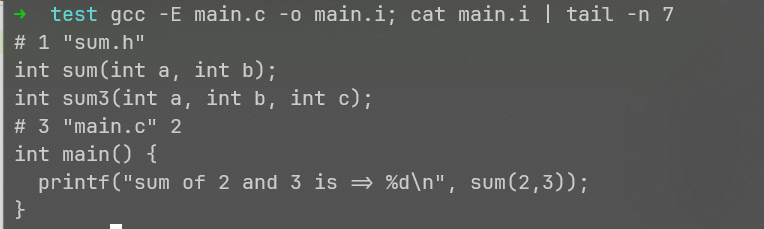
通过让gcc只做预编译步骤,我们获得了预编译后的文件main.i,并展示了它的最后七行,可以看到,一些为了后续阶段所留下的注释以及sum.h中的原型定义被拷贝到了生成的文件中:
常规之外的玩法
所以,知道了这些,你就可以突破常规了。
只改动main.c中的一个字符,如何让gcc main.c -o main通过编译,并让./main正常运行?
你只需要将#include "sum.h"改成#include "sum.c",让预处理时把sum.c中所有内容拷贝过来,预处理后的main已经包含了sum和sum2函数,我们已经不再需要sum.c了。
那我能不能#include点别的?
下面是一个普通的文本文件,文件名为content:
// content
"Hello, World!";
修改main.c:
// main.c
#include <stdio.h>
#include "sum.c"
char content[] =
#include "content"
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
printf("%s\n", content);
}
根据#include的复制粘贴语义,main.c在预编译后会变成这样:
char content[] =
"Hello, World!";
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
printf("%s\n", content);
}
执行:
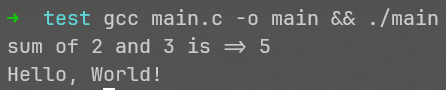
当然,如果你没有练过一龙的金钟罩的话,千万别这么写代码!!
编译整体流程!
ohh。。。本文叫“编译?汇编?链接?”,但直到现在,我们才开始进入实际的编译流程中!
对于大佬们来说,上面的内容可能有些啰嗦,但很多人(包括我在内)对概念其实并没有那么清晰,绝对有一半以上的人(若跟着一起操作)在经历了上面的阅读后会感叹:哦!竟然是这样!所以,在开始之前,我们必须把概念给纠正过来,若带着错误的概念去学习,会越学越懵逼。
对于C语言来说,至少是gcc来说,编译步骤如下图,图中肯定有一些步骤中的名词概念你还不理解,但无所谓,后面都会介绍,先有个印象就成:
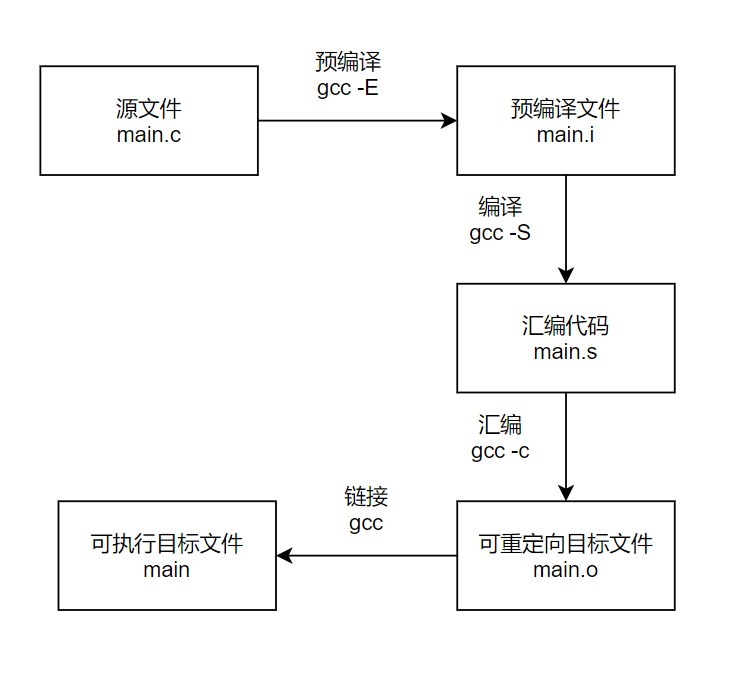
- 预编译:对于C中所有预编译指令,如
#include、#define和#ifdef,按照它们的语义对源文件进行修改 - 编译:将预编译后的文件编译成汇编代码
- 汇编:将汇编代码转换成二进制机器码
- 链接:汇编过程生成的可重定向目标文件中可能有来自其它目标文件的符号,链接过程就是将这些东西全都汇总在一起,生成一个可执行文件
下面,我们要用gcc来看看编译的整个流程,在对流程中的各种概念还没有充分认识的情况下,下面的内容可能会很枯燥,要跟上啊!能理解多少是多少就好。
在这之前,我们先恢复main.c:
#include <stdio.h>
#include "sum.h"
int main() {
printf("sum of 2 and 3 is => %d\n", sum(2,3));
}
然后执行gcc -E对main.c进行预编译:
gcc -E main.c -o main.i
main.c中有两条预编译指令,都是#include,所以stdio.h和sum.h中的内容将会被复制到预编译输出的文件中去:
经过预编译后的main.i有747行,其中包含一些以#开头的注释行,以及来自两个头文件中的函数原型、类型、结构体定义等内容。但实际上,我们只用到了printf以及sum,其它的都没用到。
下面,我们执行编译步骤,将它编译成asm代码:
gcc -S main.c -o main.s
生成的汇编代码如下,本文不要求你有x86汇编基础,所以,就看看就行:
.file "main.c"
.text
.section .rodata
.LC0:
; 我们代码中定义的字符串常量,处于.rodata段中
.string "sum of 2 and 3 is => %d\n"
.text
.globl main
.type main, @function
; main函数定义,以及其汇编代码
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $3, %esi
movl $2, %edi
call sum@PLT
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
在汇编代码中,符号还是字符串形式的符号呢!比如第22行,我们使用call sum@PLT来代表到sum的调用,第27行,我们使用call printf@PLT来代表到printf的调用,但实际x86的call指令并不认识这些符号,它只认识数字形式的地址!
@PLT中的PTL代表过程链接表(Procedure Linkage Table),具体含义可以去查查,在这里,它的意思就是先占位,后面会在合适的时机替换成实际的函数地址。
这说明编译器并不知道去哪里找printf和sum,毕竟我们通过#include导入的只有函数的原型。
继续,执行汇编,生成可重定向目标文件:
gcc -c main.c -o main.o
目标文件是ELF格式的二进制文件,无法直接通过文本编辑器阅读,不过可以通过以下三种工具进行阅读:
readelf:读取elf文件的信息objdump:读取目标文件的信息hexdump:以十六进制形式读取二进制文件
如下是我使用objdump对该可重定向目标文件进行读取后的结果,我对它的文本段和符号表进行了打印:
➜ test objdump -d -t main.o
main.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 main.c
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .rodata 0000000000000000 .rodata
0000000000000000 g F .text 0000000000000034 main
0000000000000000 *UND* 0000000000000000 sum
0000000000000000 *UND* 0000000000000000 printf
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: be 03 00 00 00 mov $0x3,%esi
d: bf 02 00 00 00 mov $0x2,%edi
12: e8 00 00 00 00 call 17 <main+0x17>
17: 89 c6 mov %eax,%esi
19: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 20 <main+0x20>
20: 48 89 c7 mov %rax,%rdi
23: b8 00 00 00 00 mov $0x0,%eax
28: e8 00 00 00 00 call 2d <main+0x2d>
2d: b8 00 00 00 00 mov $0x0,%eax
32: 5d pop %rbp
33: c3 ret
可以看到在符号表中,printf和sum都是UND的,意思是尚未定义,并且它们的地址也是0。而在文本段中,main的地址为0,它的代码都被翻译成了若干字节的数字,并且objdump为我们在右侧贴上了对应的汇编代码,这只是方便我们阅读,实际上在目标文件中并没有这些内容。它的两条call指令也并没有实际的参数,都是e8 00 00 00 00,e8代表call指令,参数代表要跳转到的地址,这里为0,和符号表中的printf和sum的地址对应。
下一步就是链接,我们已经看到了符号表中有未定义的符号,这些符号在其它目标文件中,我们需要将其它目标文件和main.o链接,得到最终的目标文件。我们还是通过gcc帮我们自动完成:
gcc main.c sum.c -o main
上面这条指令会分别将main.c和sum.c编译成可重定向目标文件,并将它们两个链接起来,这样,main.o中的sum符号就找到定义了!但是printf符号在哪呢?
printf函数并不由我们提供,它由glibc提供。C语言可以被拆分为两个部分,一个是语法标准,大部分课程会教你的都是这部分,即如何编写C语言程序。另一部分则是库,glibc是GNU C Library,即在Linux下的一个C语言核心库,其中提供了printf函数。gcc知道如何正确的链接它,实际上,如果你在执行gcc时加上-v参数,你会看到编译的整个全过程,这个过程是很复杂的,它帮我们做了很多事,其中就包括链接printf所在的目标文件:
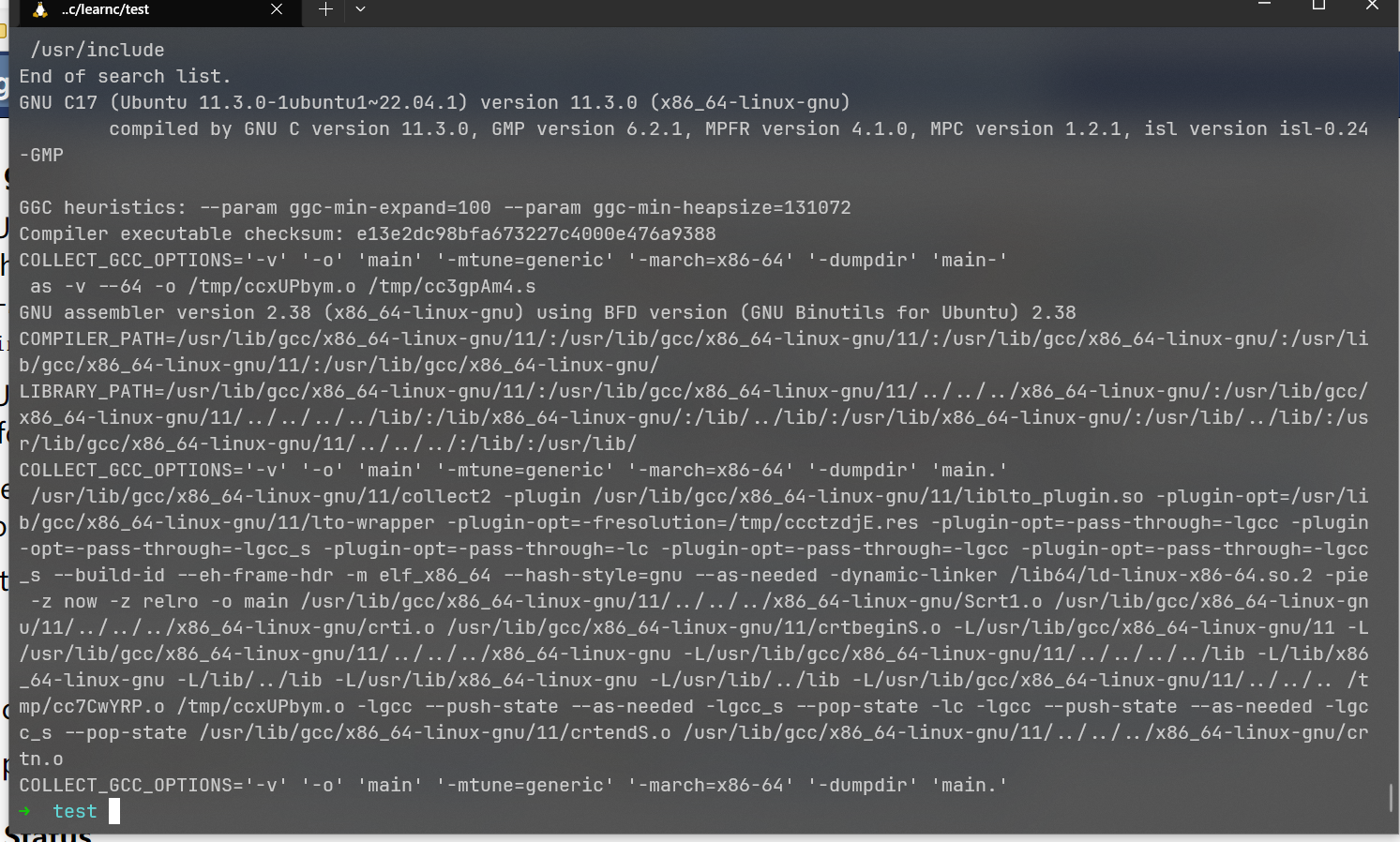
所以,即使是一个简单如上面的例子一般的C程序,编译后也足够复杂,如果你用objdump来查看编译后的可执行文件,你会发现输出的结果非常长,多了很多函数(或者现在说过程比较合适),符号表也膨胀到很大。
我们通过objdump以及grep过滤出了所有的函数(或者说过程),这里面有很多不认识的:
➜ test objdump -d -t main | grep --extended-regexp '[0-9a-f]+\s<.*?>:'
0000000000001000 <_init>:
0000000000001020 <.plt>:
0000000000001040 <__cxa_finalize@plt>:
0000000000001050 <printf@plt>:
0000000000001060 <_start>:
0000000000001090 <deregister_tm_clones>:
00000000000010c0 <register_tm_clones>:
0000000000001100 <__do_global_dtors_aux>:
0000000000001140 <frame_dummy>:
0000000000001149 <main>:
000000000000117d <sum>:
0000000000001195 <sum3>:
00000000000011b8 <_fini>:
并且它的符号表已经有这么大了:
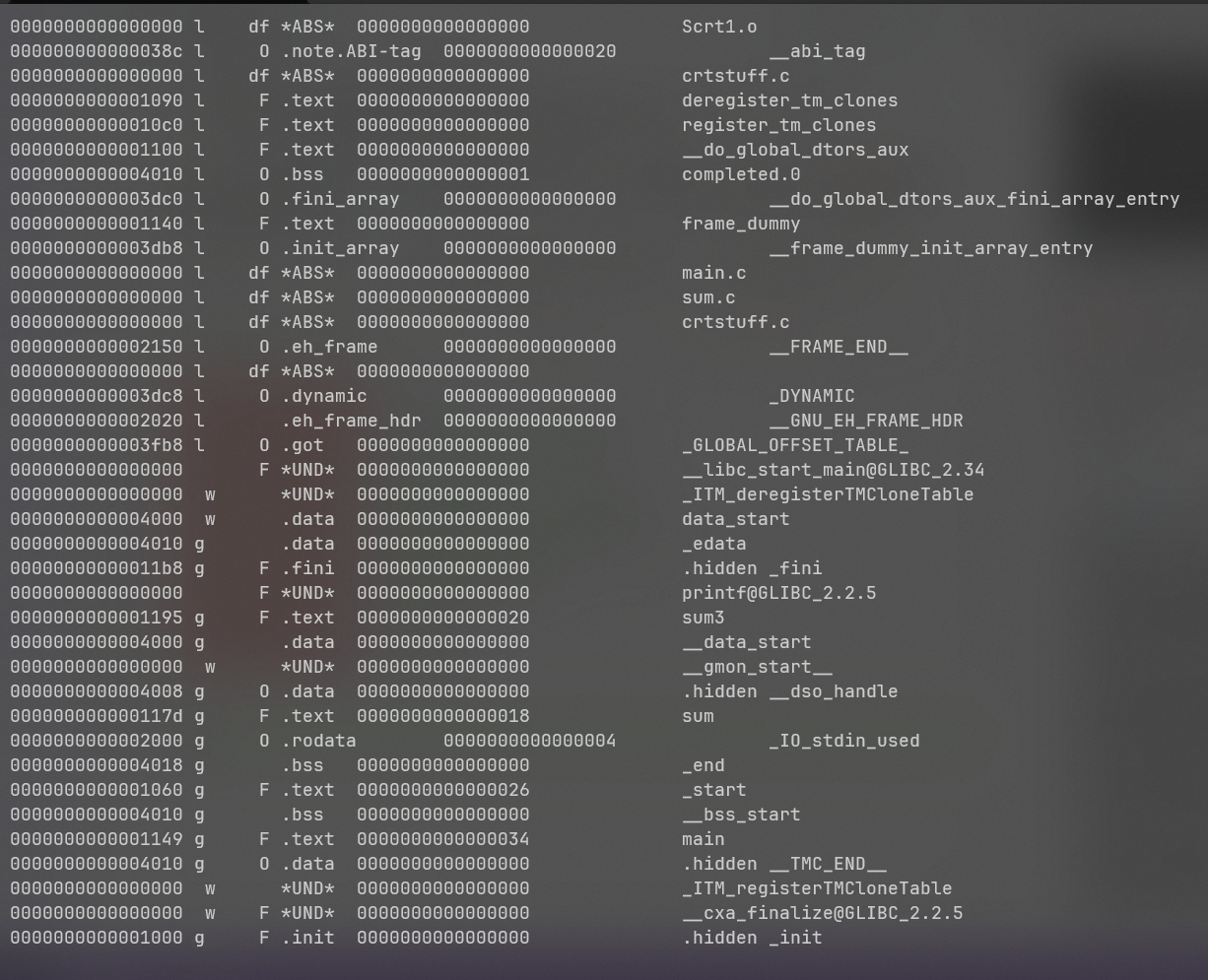
如果你足够仔细,还能看到可执行文件的符号表中仍然有UND的符号,而且printf@GLIBC_2.2.5这个就是UND,它貌似就是我们要调用的printf。这种技术叫动态链接,我们后面会提到。
计算机和程序的故事
程序中有什么?
我们每天为计算机编写程序,但我们有没有思考过程序是什么?为什么计算机能够跑我们编写的程序呢?
现在,我们讨论的程序是编译完成后的可执行程序,它只不过是一个普通的静态二进制文件而已。如果你了解数据库系统,不妨想想你的数据库系统为什么能解析表文件和索引文件?如果你存储过照片(除非你是原始人),不妨想想为何照片读取程序能够解析照片并绘制在屏幕上呢?
原因就是,有某种定义好的格式规范,按照这种规范,你就能解析出二进制文件中每一个字节的意思。对于数据库表,你可以按照规则解析出表中的数据,对于照片,你可以按照规则解析出每一个像素上的颜色。那么对于二进制程序呢?想想二进制程序中都会保存哪些东西?
- 代码!必不可少的就是代码!或者用机器的角度来说,可以说成是指令。
- 数据!程序中有一些全局变量,比如你在函数之外写了一行
int a = 12;,那么这个12必然需要保存起来,待你的计算机加载程序时读取。
虽然,各种可执行二进制文件中都并不只有这两种东西,但是核心的就是它们了——指令+数据。
不同的操作系统有不同的可执行程序文件规范,比如Windows下的exe,Linux下的elf。本文应该不会过多介绍这些,如果需要,请查阅相关文档。
如何执行程序
宏观上来将,计算机由CPU + 内存 + 外部设备组成,CPU的功能很有限,就是按照程序中的每条指令进行执行。程序会被加载到内存中,然后CPU从内存中读取程序的指令进行执行。
我没说谎,但是我却省略了很多细节。
比如:
- 程序是怎样被加载到内存中,被谁加载的,程序在内存中的空间是什么样的?
- CPU要执行程序的指令,它怎么知道从哪一条指令开始?
- ...
这些功能并不是由计算机硬件来完成,我说了,CPU功能有限,它只会傻傻的读指令并执行。这些功能是由操作系统来完成的。
操作系统是在硬件之上运行的程序,管理内存资源,操作外部设备,并且帮你加载程序到内存中,建立内存布局,并且跳转到你程序的第一条指令。操作系统在这中间能做很多事,比如:
- 不让你的程序直接访问内存,而是使用虚拟内存将进程间的内存隔离
- 不一次性将你的程序加载进内存
- 向你的程序提供访问硬件的接口,而不给它直接操作硬件的能力
- 多次打开一个程序时,只在内存中保留一份代码
- 系统中有些函数库可以做成运行时链接的,这样就不用在每一个程序文件中保存一份了,减少二进制文件大小。这种技术称为动态链接
- ...
由于本篇文章不是介绍操作系统的,所以我不说太多了,上面介绍的内容对于本篇文章的推进已经足够了,推荐MIT6.S081和南京大学jyy老师的操作系统课,B站都有。基础薄弱的可以先看MIT这门,再看jyy老师的。
所以,对于如何执行程序这一问题,不同的操作系统中的细节可能不同,但大体上都是差不多的,我这里以Linux中,你在shell下输入./main来执行我们的main程序的流程举例:
- shell会建立一个子进程,用于稍后加载我们的程序
- 子进程执行execve来加载我们的程序,它会按照ELF的规范读取程序的二进制文件,在内存中建立程序的空间,包括把代码复制到内存的文本段中,把数据复制到数据段中等
- 检查ELF是否是动态链接文件,如果是,需要从ELF中指定的动态链接器的代码开始执行,将动态链接库链接到进程的地址空间中
- 跳转到程序的二进制文件中给定的程序入口位置
通过readelf工具来查看操作系统视角的程序
ELF格式的二进制文件就是操作系统视角的程序,在linux下,readelf工具可以查看该文件的信息。
➜ test readelf -h main
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 14064 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30
通过readelf -h,我们查看了main文件的头信息。从Type: DYN来看,可以看出它是一个动态链接文件,操作系统需要先执行指定的动态链接器来将动态链接库映射到进程的地址空间中。Entry point address指定了该可执行程序的入口位置,稍后会让CPU跳转到这个位置上执行该程序的代码。
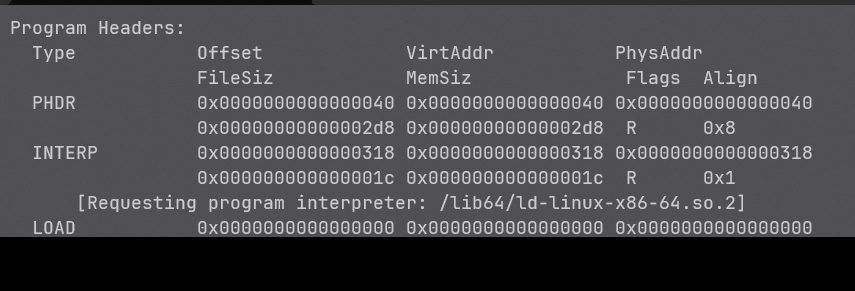
通过readelf --all,我们还在Program Header部分看到了该程序指定的动态链接器是: /lib64/ld-linux-x86-64.so.2:
什么?程序竟然不是从main开始执行的?!
上C语言课的时候,我们都听说过,C语言程序从main开始执行。这句话从C语言程序员的视角来看确实没错,但从操作系统的视角来看就不对了。计算机中充满了各种这样的事,比如系统的内存模型(比如JVM)会告诉你内存是什么样的,每个CPU具有一个本地缓存啥的,这个模型在你的视角来看是没错的,一切都按照模型中定义的“事实”来工作,但若你再往深一层,你会发现这个模型只是一个假象,在你原来的视角来看,这个假象完全没有问题,但假象后面的实际工作原理却大相径庭。
通过readelf,我们看到程序的入口地址是0x1060,如果C程序是从main开始执行的,那么这个入口地址应该就是main函数的定义。但我们通过objdump来查看程序文件中所有的函数地址:
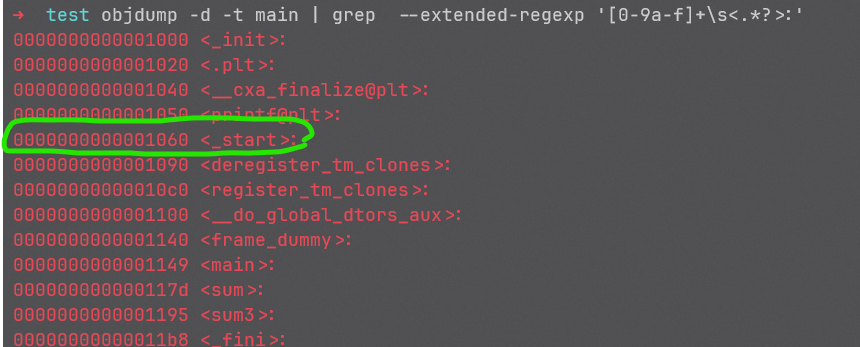
0x1060这个位置,是_start函数所在的位置。
_start函数是crt库提供的函数,用于对C语言的运行环境进行初始化,它随后会调用main。
那我们能不能通过hack ELF文件的入口位置的几个字节,跳过_start,将它改成main所在的0x1149?
通过阅读ELF格式的文档:I Executable and Linkable Format(ELF),我了解到在ELF文件的第24个字节处就是入口地址,它占用四个字节。也就是下图这四个字节吧:

所以,我们只需要把这里的60 10改成49 11即可,我通过hexedit将这里改成了49 11
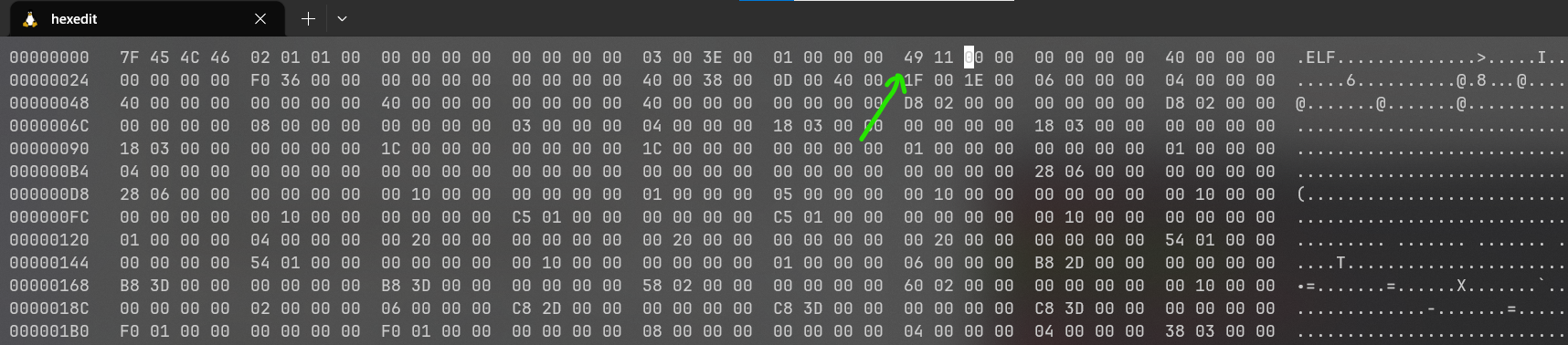
执行该程序,报了Segmentation Fault:

通过gdb调试发现确实进入了main,但是在printf输出时,调用到__vfprintf_internal中的一行movaps指令时发生了段错误。
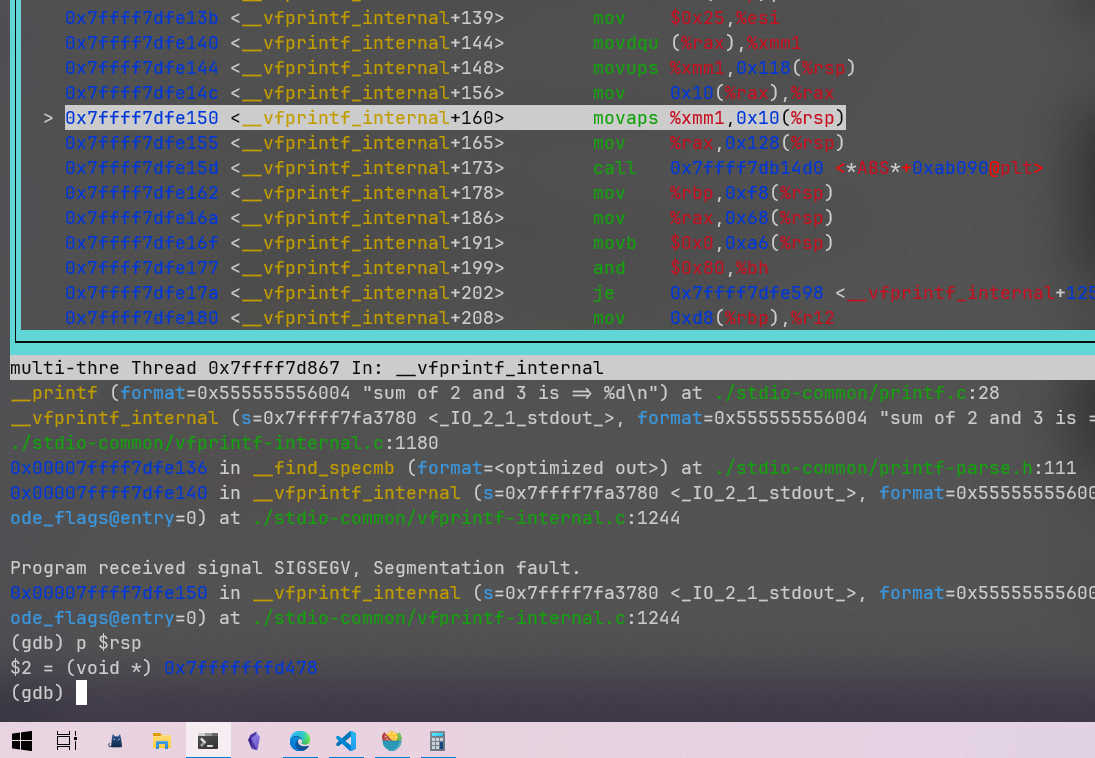
movaps指令要求内存地址16字节对齐,应该是这里的%rsp+0x10计算后没有16字节对齐,再具体的问题就不得而知了,应该是由于错过了glibc中的_start函数后,某些东西没有被正确的初始化导致的。
那我们来“手写”程序吧!
什么?难不成我以前是用脚写的???
不不不,我的意思是,我们已经知道了C语言程序从编译到执行的过程,那么我们能不能略过预编译和编译过程,直接从汇编代码写起,写一个可以运行的C程序呢?
既然你都从汇编代码写起了,那你怎么还能叫C程序呢?
我的意思是,我们编写的汇编代码仍然遵循C语言的那些规约,我们依然从
main开始编写,并且合适的时候可能会调用glibc中的库函数(比如printf)。
我们只写一个简单的程序,我们让CPU帮我们计算2+3的结果,然后输出到屏幕上。
先简单一点
为了不让一开始难度就那么大,我们先忽略输出这件事,因为调用printf是一件复杂的事。
编写main.s:
.section .text
.globl main
main:
movq $2, %rdi
movq $3, %rsi
addq %rdi, %rsi
ret
在这段简短的汇编代码中,我们向%rdi中写入了2,向%rsi中写入了3,然后调用addq将它们相加,结果保存到%rsi中。
我们通过as工具将这段代码汇编成目标文件:
as main.s -o main.o
objdump -d main.o
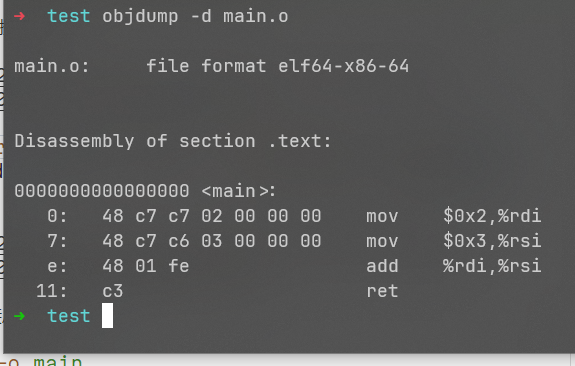
使用ld工具将它链接成可执行文件:

嘶,它说没找到符号_start,莫非ld会默认将_start作为链接后的可执行程序的entry point?通过在ld的man page(man ld)中搜索,找到-e参数可以设置entry point。

最后,使用这个命令成功链接成可执行文件:
ld -e main main.o -o main
通过对得到的程序进行objdump和readelf,可以看到该文件是一个EXEC类型的,并非DYN类型的,也就是程序启动时并不用任何动态链接器的辅助,直接从入口开始执行,也就是main(0x401000)处。
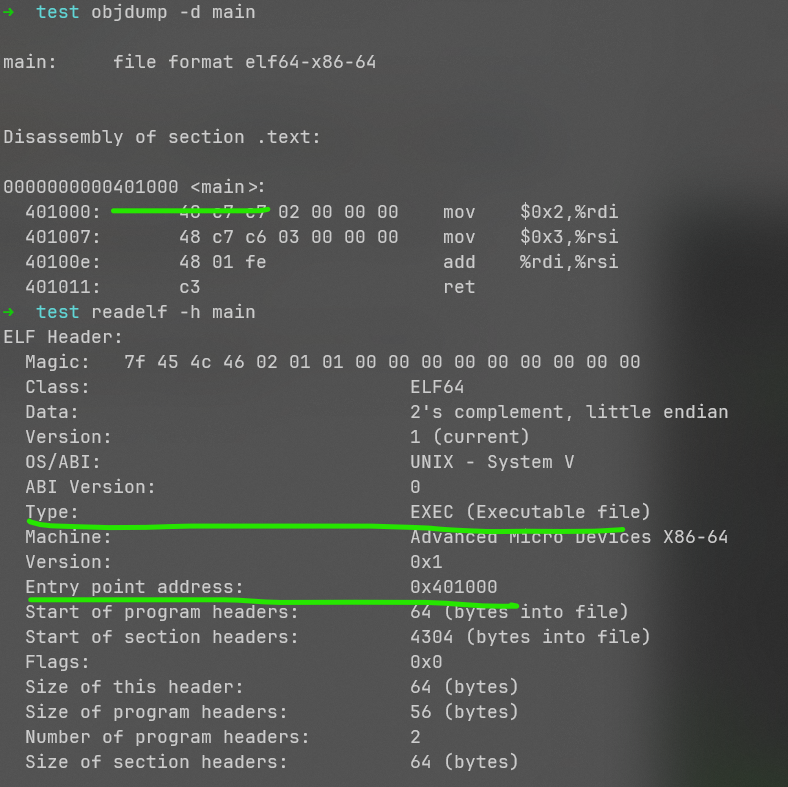
执行该程序,发现报了段错误:

通过gdb调试,查看哪条命令错了。可以看到,直到ret(尚未执行),程序都没有出错,并且%rsi中保存了2+3的结果——5。
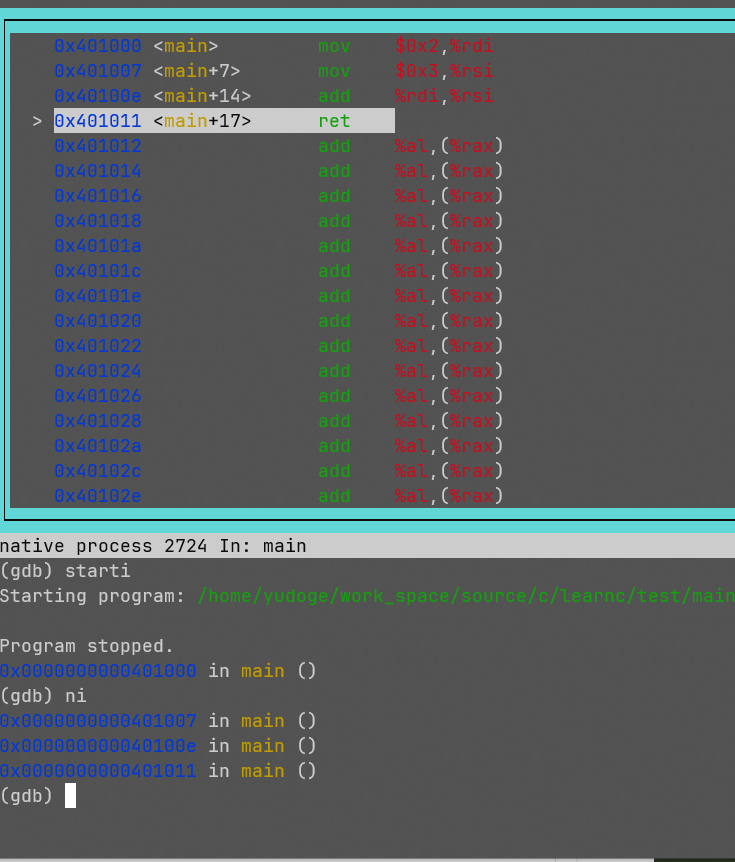
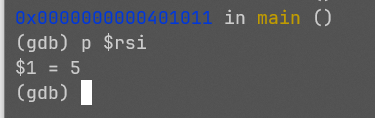
但当我们再次向下执行时,ret执行完成后,我们进入了??,再执行一行程序就报段错误了:
x86中ret指令的语义是从栈顶(也就是%rsp指向的位置)弹出一个值并跳转过去,所以C语言在进行函数调用时,都会将函数的返回地址压入栈中,为的就是ret指令执行时能弹出这个返回地址并跳回来。
但是,main我们唯一一个函数,我该跳到哪里呢?我该怎么让程序停下来?如果我删掉ret,程序就会一直顺序的向下取指令,可下面根本没有合法指令,所以我的结局还是段错误。
我们陷入了一个僵局,我们的程序不会结束自己。
系统调用!
jyy老师说过,程序就是一个状态机,它的每一步都只能做一些计算工作,然后迁移到下一个状态,再无其它。这样的话,除了有外力打断,否则我们的程序没有退出自己的能力!
程序运行在操作系统上,操作系统抽象出了进程的概念表示运行中的程序,操作系统还维护了进程之间的树型结构,同时,操作系统具有管理这些进程死活的能力!
一般系统都提供了exit系统调用用来让程序退出,所以,我们可以使用int指令来发起一个代表系统调用的软中断,并设置好exit对应的系统调用号和参数,程序就可以正常退出了。
这里如果没学过操作系统的可能会有些懵,嗨嗨。
.section .text
.globl main
main:
movq $2, %rdi
movq $3, %rsi
addq %rdi, %rsi
; $1是exit的系统调用号
movq $1, %rax
; 将%rsi中的数字(计算结果5)作为exit的参数
movq %rsi, %rbx
; 通过中断唤醒kernel执行系统调用
int $0x80
重新汇编、链接该程序,执行后正常退出程序,并且程序的状态码为5,也就是2+3的结果:
➜ test as main.s -o main.o
➜ test ld -e main main.o -o main
➜ test ./main
➜ test echo $?
5
在bash中,
$?代表上一个运行的程序退出时的状态码,0为正常退出。
但我们完全越过了glibc
是的,我们最开始的目标是要按照C语言的规范编写程序,这样才有助于我们理解C语言的编译过程,但我们现在通过将main设置为入口,完全越过了C语言那套东西,实际上,我们没有加载glibc提供的动态链接库,也没有在静态链接时使用任何和glibc相关的东西。
现在,我们去掉ld的-e参数,重新从这个错误处开始:
➜ test ld main.o -o main
ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
这个错误说我们没有定义_start,因为ld会把_start作为默认的入口符号,所以我们的程序中必须要有个_start符号。
在汇编代码中将main改为_start肯定是可行的,不过我们又一次绕过了glibc。我们在编写C语言程序的时候也没有编写_start函数啊,那就证明_start符号是被编译器自动添加进来的。
是的,如果你使用gcc,它会自动为你添加_start符号,下面我们使用gcc来链接这个目标文件,没有任何问题:
➜ test gcc main.o -o main_gcc
➜ test ./main_gcc
➜ test echo $?
5
是的,如果你使用objdump查看main_gcc的符号表或代码段的时候,你会发现它实际上为我们添加了很多东西,前文已经看过了,这里不多赘述。
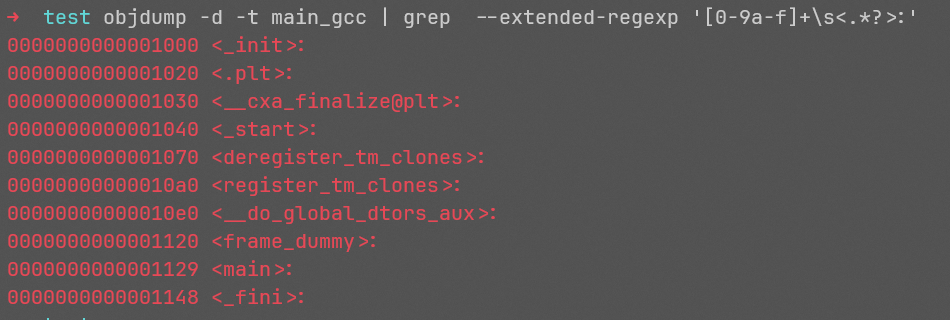
我们能不能自己通过ld来做gcc做过的东西呢?
手动链接glibc
实际上,我们要让我们的代码能够运行并不用做gcc做的那么多事,对于_start符号的问题,crt1.o这个可重定向目标文件中就包含了_start,gcc也是链接的它,它会初始化C语言的运行环境。
系统中有很多crt*.o,它们名字的含义就是C Runtime。C程序从main开始,到main的最后一条语句结束,main可以接收来自命令行的参数,并且可以通过返回值设置进程的退出状态,这些工作是谁做的?在我们手写main的时候,你也看到了,ret甚至不能直接用,因为没有地址可以让我们返回。这些准备工作都是crt*.o做的。
我们尝试手动链接crt1.o:
➜ test ld main.o /usr/lib/x86_64-linux-gnu/crt1.o -o main
ld: /usr/lib/x86_64-linux-gnu/crt1.o: in function `_start':
(.text+0x21): undefined reference to `__libc_start_main'
又报错了,说__libc_start_main没找到。通过查阅文档,好像_start调用了它,它在libc.so中。那就通过-lc参数链接glibc。
➜ test ld main.o /usr/lib/x86_64-linux-gnu/crt1.o -lc -o main
这下,成功链接,但是运行时肯定会报错:
这个错误挺奇怪的,第一次卡了我好久,后来STFW发现了,由于我们加了-lc,链接出的可执行程序已经变成了一个需要动态链接的文件,通过file main可以看出:
➜ test file main
main: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib/ld64.so.1, for GNU/Linux 3.2.0, not stripped
通过objdump可以看出,__libc_start_main这个符号确实是未定义的,需要运行时动态链接。
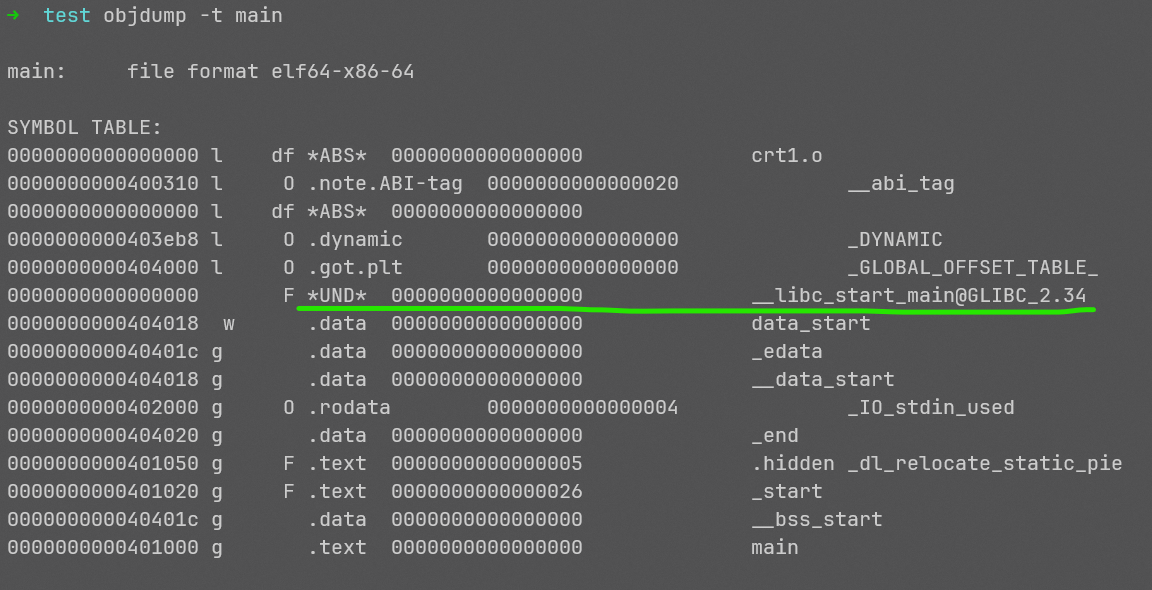
既然需要动态链接,一定需要动态链接器,默认的动态连接器,也是当前main程序中的动态链接器是/lib/ld64.so.1(可以通过readelf或file命令得到),我们的系统中并没有这个动态连接器。
实际上,若你之前跟着使用gdb对程序进行调试,你会发现即使我们将入口设置到了
main上,我们还是会进入_start。这一现象并不神奇,那个_start不是我们程序中的,我们的程序中都没有_start,它来自于我们程序的动态链接器中。所以,程序在执行时先会执行指定的动态链接器,动态链接步骤完成后才会执行程序。
通过给ld添加-dynamic-linker参数,可以指定动态链接器,下面,我们将动态连接器设置成了/lib64/ld-linux-x86-64.so.2,程序可以编译并执行:
➜ test ld main.o /usr/lib/x86_64-linux-gnu/crt1.o -lc -o main -dynamic-linker /lib64/ld-linux-x86-64.so.2
➜ test ./main
➜ test echo $?
5
调用printf
最后,我尝试将通过gcc编译的文件中的汇编代码拷贝到我们自己编写的main.s中以实现printf的调用,很多时候你会遇到段错误,这是因为你编写的代码不符合x86 C Calling Convention,RTFM。
.section .data
.LC0:
.string "2 + 3 = %d\n"
.section .text
.globl main
main:
pushq %rbp
movq $2, %rdi
movq $3, %rsi
addq %rdi, %rsi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
movq %rsi, %rbx
call printf@PLT
popq %rbp
ret
汇编、链接、执行!
➜ test as main.s -o main.o
➜ test ld main.o /usr/lib/x86_64-linux-gnu/crt1.o -lc -o main -dynamic-linker /lib64/ld-linux-x86-64.so.2
➜ test ./main
2 + 3 = 5
现在看Java类加载过程,好像有点降维打击...
Java的类加载机制是一道频繁出现的八股文,我讨厌八股文,我不想背,如果不理解,背有什么用。
我们就随便拿一张知乎上找的图吧,原文在这,如有冒犯随时换图。
你的C程序被编译成二进制可执行文件,其中包括数据和指令,而且还会有一张符号表保存程序中所有的符号,其中有一些动态链接的符号尚未定义,需要动态链接器来执行链接,将动态链接库中的内容映射到进程的地址空间,并替换该符号的地址。
你的Java程序何尝不是被编译成JVM的二进制可执行文件(class文件),其中包括数据和指令,而且还会有一张常量池表保存程序中所有的符号,其中有一些来自其它类的符号尚未定义,需要JVM来执行解析(动态链接)。
假设我们有A.java和B.java:
// A.java
package test;
import test.B;
public class A {
public static void main(String...args) {
System.out.println(B.message);
}
}
// B.java
package test;
public class B {
public static String message = "Hello, B!";
}
编译运行:
➜ learnc javac test/A.java test/B.java
➜ learnc java test.A
Hello, B!
使用javap查看字节码,我已经删除了不重要的部分:
➜ learnc javap -v test.A
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = Fieldref #18.#19 // test/B.message:Ljava/lang/String;
{
public static void main(java.lang.String...);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC, ACC_VARARGS
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: getstatic #3 // Field test/B.message:Ljava/lang/String;
6: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
9: return
LineNumberTable:
line 5: 0
line 6: 9
}
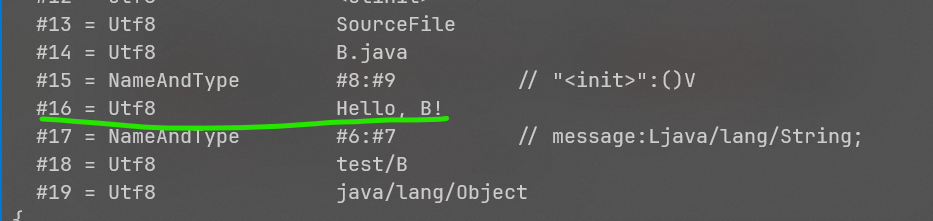
从常量池表中可以看到,#3是一个Fieldref,指向test/B.message,是一个String类型。而在main方法的代码中,地址3的getstatic指令取出了#3,也就是message。
可是在A.class中,并没有message的定义,这东西实际定义在B.class中:
A中只保存了它的符号引用,需要在JVM运行时进行解析,所以这个过程很像动态链接的过程。
考虑下
System.out.println其中的这些符号是不是都要动态链接呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号