传输层的多路复用与分解 & Socket究竟是啥
每天净背八股了,计网,操作系统这些知识早都忘光了,昨天被CVTE的面试官问住了,当时回答的比较乱,并且有些地方答错了。特此重新学习总结。
但是不得不说,CVTE的技术面试官好温柔好温柔。
什么是多路复用
网络层只能提供主机到主机的连接,而我们开发网络应用时,并不希望只是把消息传递到对应主机上,我们希望的是将消息传递到对应主机的对应进程上,这样,处于网络中不同主机上的我们的应用才能相互通信。
所谓传输层的多路复用,就是在网络层的基础上提供应用进程到应用进程的通信
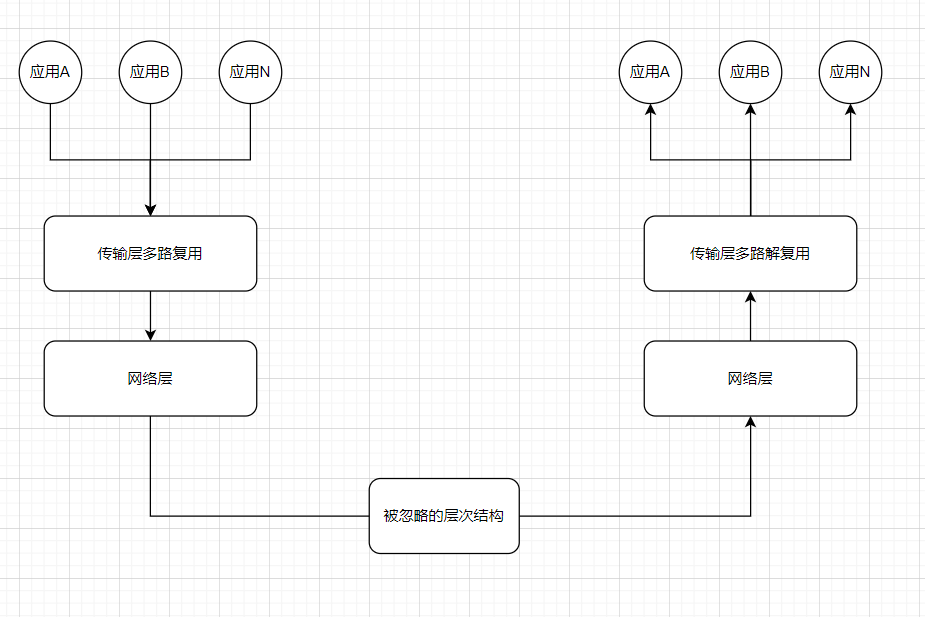
如何做到?
大家对端口号的概念肯定不陌生,你经常编写自己的Web应用并将它绑定在80端口上,然后你用浏览器或者什么东西访问你服务器的IP地址,加上80端口号,你的Web应用就会接收到请求。
所以,多路复用和分解是通过端口号实现的。下面展示的是一个简单的模型,其中还有很多细节没有提到,本篇文章会一步一步的揭示
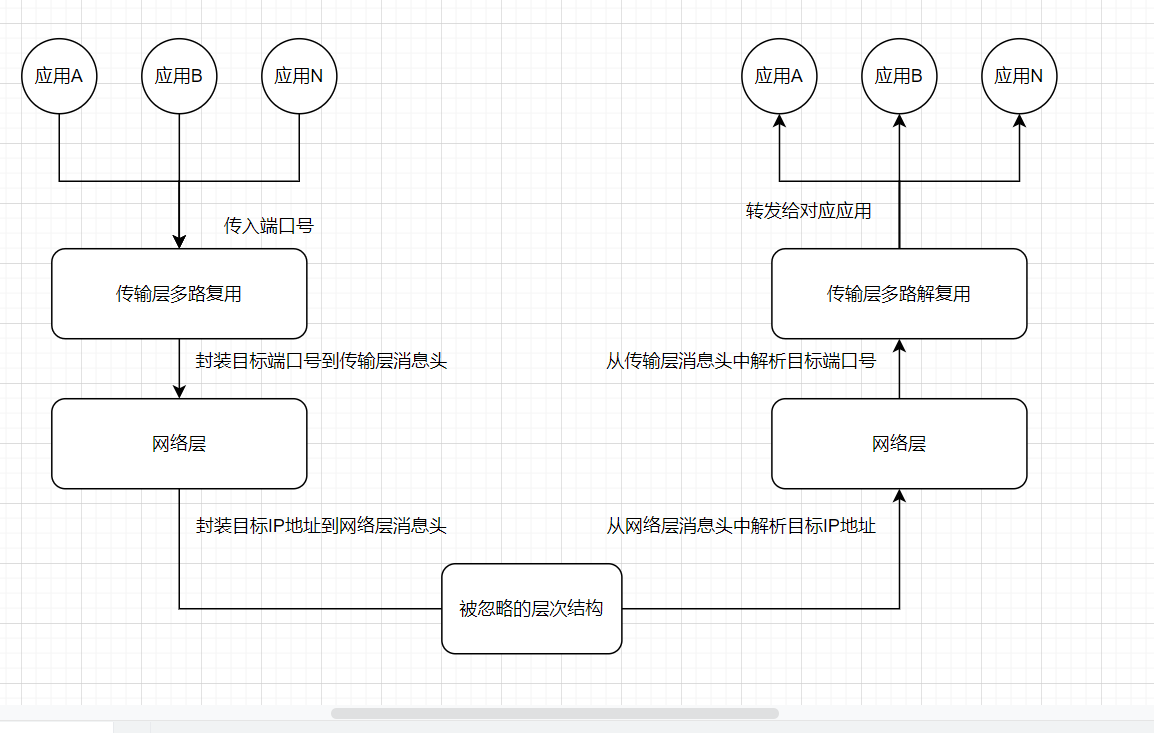
如何返回消息
上面的模型看起来很简单,很完美,但是,我们假设现在通信双方是主机A的应用A(以下简称应用A)以及主机B的应用B(以下简称应用B),按照上面的模型,应用B只是接到了应用A发到的消息,如果它想返回点数据给应用A,它需要知道应用A的地址和发信端口啊。
所以,发送方的传输层实体除了将目标端口号加入头,也要将源端口号加入头,而它的网络层除了要将目标IP加入头,也要将源IP加入头。
所以,可以看作(源IP,源端口, 目标IP, 目标端口)是标识一次双向通信的四元组。
所以,图片应该被改成这个样:
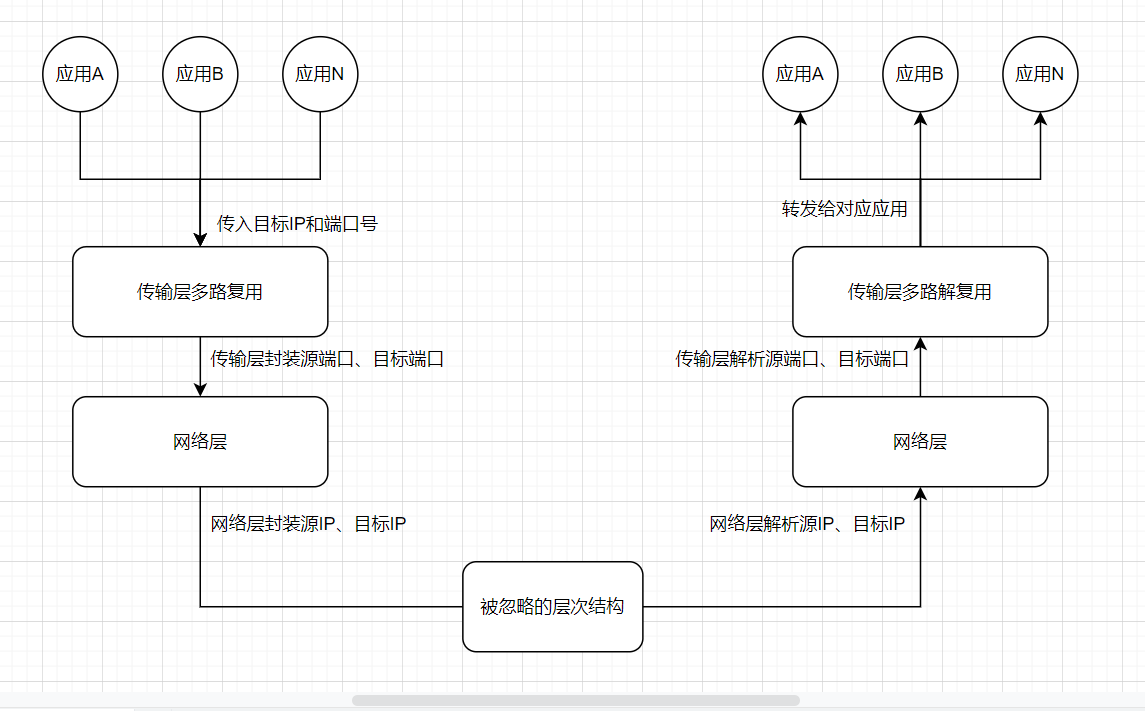
Socket、以及Socket表
你是一个应用开发者,对于你来说,你应该只关注于接消息,发消息,就像下面的伪代码一样:
// 将当前应用绑定在`127.0.0.1`的`9999`端口上
bind_and_listen(('127.0.0.1', 9999))
// 当接收到消息时
on_receive {sender, message =>
// 处理消息
result = handle_message(message)
// 将处理结果返回给发送者
sender.return_back(result)
}
你不应该陷入“如果我接到了一条消息,我要给消息的发送者也发回一些信息时,我要发到哪里”这种问题中。应该有一个对象可以代表网络通信中的一端的进程,就像上面的sender一样,应用代码可以直接通过它与对端通信。
Socket就提供了这样的抽象。Socket扮演的角色,就是网络通信中的一端的进程。
那么作为一个Socket,它应该具有(本地IP, 本地端口, 对端IP, 对端端口)这些属性。
在Linux中,一切皆文件,所以就像文件如何在程序中表示一样,Socket,在程序中,被表示为一个整数类型的文件描述符(socket_fd),操作系统中有一张记录所有Socket的表。表中的每一行就可以看作是一个由(socket文件描述符, 从属进程, 本地IP, 本地端口, 对端IP, 对端端口, 其它属性...)构成的元组。
可以通过ss命令来查看Linux中的Socket表。

回到刚刚那个接收端返回数据的例子,接收端无需了解发送端的任何细节,它只需要通过该连接的socket_fd,以及当前进程的pid(因为文件描述符是进程间独立的),就能去表中唯一定位一条数据,就知道返回消息该返回到哪里了。
【面试题】. 当TCP接收端accept了一个新连接后,会创建出一个新的socket,这个新的socket是否会使用新的端口?
当你不了解Socket是一个什么东西,进程如何通过它工作时,你就会懵,然后可能就会说“会使用新的端口”。我昨天就中了这个圈套。
实际结果是并不会。Socket并不是和端口一一对应的,当它accept了新连接,向Socket表中添加一行就行。
TCP的Socket
Welcome Socket
当你在TCP中使用Socket时,有两种Socket,一种是LISTEN状态的Socket,它不能发送实际数据,如下图所示:

该Socket的对端IP为0.0.0.0,这代表任意的IP,它的对端端口为*,这代表任意端口。当传输层接收到一条消息时,它会根据消息的源IP,源端口,目标IP,目标端口去Socket表中进行比对,如果全部匹配,才把这个消息给这个socket发过去。而这一条记录的意思是对于任意源IP、任意源端口、任意目标IP、目标端口号为9999的数据,都转发给我。
这个Socket称为Welcome Socket,它始终处于LISTEN状态。
Welcome Socket所匹配的源IP是我们可以在编程时指定的,我们指定的就是
0.0.0.0,所以我们可以通过编程指定Socket服务器只接收来自固定IP的数据。
Welcome Socket和你的accept方法有紧密的联系,我们都知道accept方法在有新连接时会创建一个新的socket,而这个功能的背后就是Welcome Socket在工作。它对于新来的连接,或者说此前没有建立过所以Socket表中不存在对应记录的连接,它都会接收,并且为其创建一个新的Socket,在Socket表里加入新的记录,此时accept解除阻塞,并接收到新记录的socket_fd,程序稍后可以通过这个socket_fd进行下一步操作。
其它Socket
TCP中的其它Socket都是经过Welcome Socket建立出来的,它们已经有了完整的(本地IP, 本地端口, 目标IP, 目标端口)信息,它们代表着一个实际的TCP连接。所以,在你的应用与传输层交互时(通过read、write系统调用),你只需要传入socket_fd以及要写入的buffer或者要读取到的buffer即可。
所以对于发送来说,传输层的TCP实体可以从socket中拿到本地端口和目标端口作为头部的源端口和目的端口,而网络层的IP实体可以从socket中拿到本地IP和目标IP作为头部的源IP和目的IP。
对于接收来说,传输层的TCP实体可以从TCP头和IP头中分别拿出源IP、源端口、目的IP和目的端口进入Socket表进行比对,将消息路由到对应的socket上。
传输层协议实体怎么能读到IP头呢?
根据咱们从学校里学的和书本上的知识,IP头应该在IP层被拆开扔掉了,传输层不会知道IP层的细节,那么它怎么能够从IP头中读取源IP和目的IP呢?
这个问题我也不知道,StackOverflow上有两个关于它的讨论,其核心思想都是说书本上为我们呈现的是理想状态下的清晰简洁的模型,实际上层间的交互的边界并没有那么清晰。
UDP的Socket
UDP并不是面向连接的,它的通信双方也没有建立虚拟连接的概念。
正因为它没有连接的概念,所以它的Socket中也没有对端端口的相关信息,如下图中第一行是我们创建的UDP服务器,第二行是我们创建的UDP客户端,客户端正在向服务器发送一条消息。

所以对于UDP的socket,它可以接收任意IP和任意端口的读写(当然你也可以调用bind限制IP)。UDP提供了sendto和recvfrom方法来在socket上进行写和读。在Python中,它们这样使用:
from socket import *
import time
# 创建UDP的socket
client = socket(AF_INET, SOCK_DGRAM)
# 调用`sendto`发送,直接指定目标IP和端口
client.sendto(b'hello', ('127.0.0.1', 19157))
# time.sleep(22)
# 调用`recvfrom`进行接收,同时将发送端的IP和端口通过`addr`返回给应用层
data, addr = client.recvfrom(4096)
print(data, addr)
然后,UDP若还想向对端返回数据,就可以继续:
client.sendto(data, addr)
所以,总结一下,正因为UDP没有连接的概念,所以:
在发送时:
- 向传输层传入
socket_fd外,还要传入发送的目标IP和端口,传输层从socket中拿源端口,从传入的参数中拿目标端口,写入UDP头 - 网络层从socket中拿源IP,从传入的参数中拿目标IP,写入UDP头
在接收时:
- 从IP头中拿目的IP,从UDP头中拿目的端口,去socket表中匹配
- 将消息发给socket,并且从IP头中拿源IP,从UDP头中拿源端口,返回给应用层。
注意,这里的动词“拿”可能有点过分,它并不代表网络层真的去
socket中拿IP了,而是说这些信息在socket中。而具体是IP层自己拿的,还是传输层给的,我就不知道了,我个人偏向于后者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号