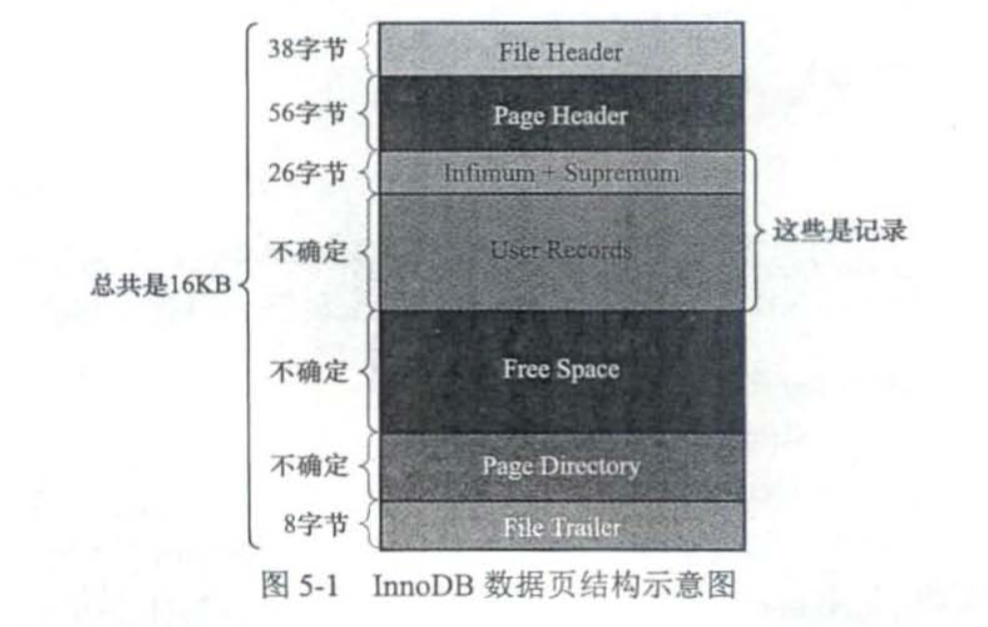
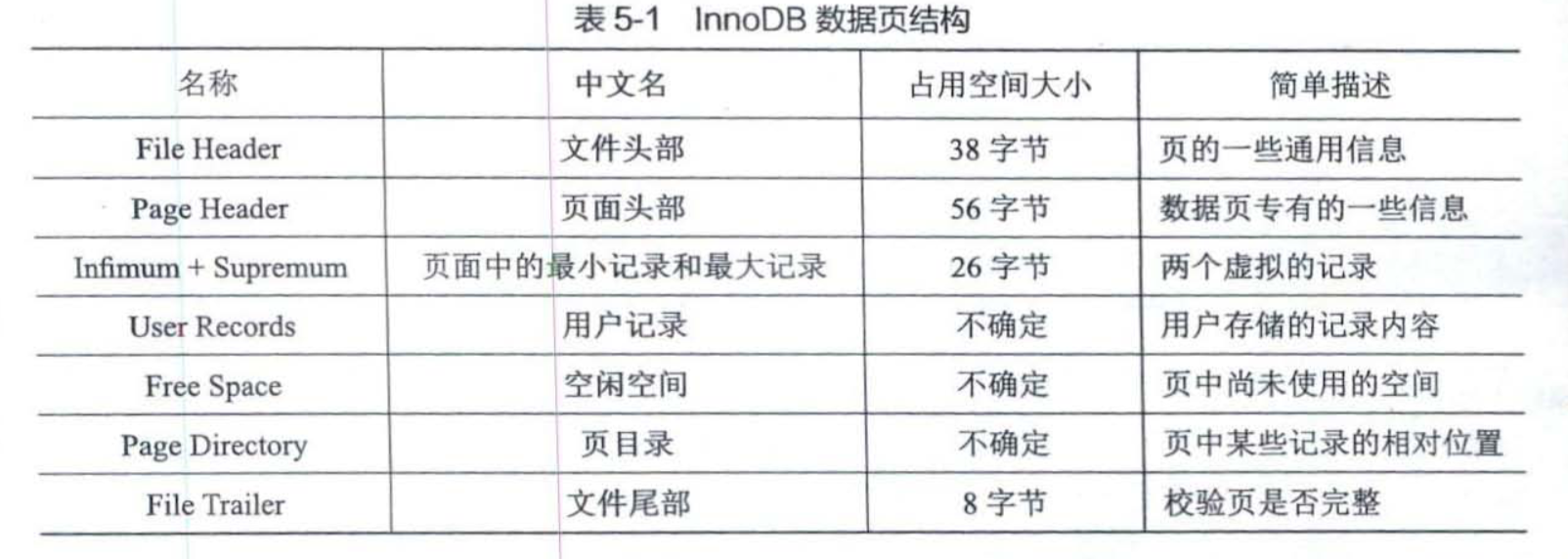
InnoDB数据页结构
InnoDB以页来管理磁盘文件,根据页的功能不同,有多种多样不同的页,比如用来记录undolog信息的undo页,用于存放数据的数据页。现在我们主要来了解下数据页的结构。
实际上,InnoDB采用索引组织表的表结构,所以实际上无论是表,还是在表上建立的索引,都是以索引形式存在的。所以InnoDB实际上没有
数据页一说,都是索引页,这里为了和原书《MySQL是怎样运行的》保持一致,用了数据页的说法。
数据页的结构如下:
以数据头中信息建立的优化#
InnoDB把实际的用户记录存储在User Records中,但不是就简单的堆在里面,InnoDB会在记录间建立一些结构,以及使用一部分空间建立辅助结构,以在各种方面进行优化。
要想在页中的数据见建立结构,就一定需要一些辅助的字段,这些辅助字段存在记录头中。
优化1. 逻辑删除#
页中紧凑的堆满了一些数据记录,如果想从中删除一个记录怎么办?重新排列该页中在它后面的记录吗?
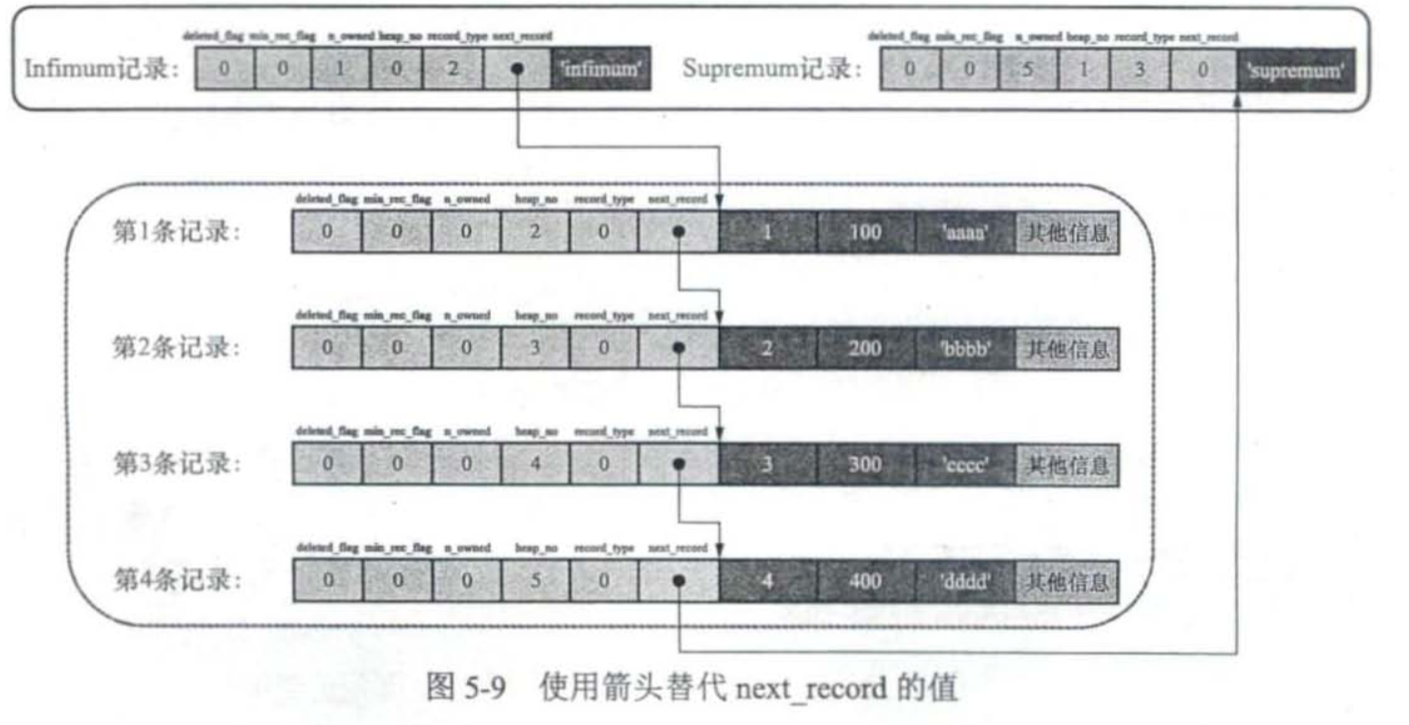
InnoDB在记录头中维护一个deleted_flag字段,当删除一个记录时,只需要将该字段置1,并不需要真的将它从磁盘页中摘除。所有这些垃圾记录会组成一个垃圾链表,以等待重用空间。
优化2. 有序链表#
记录头中的next_record字段将页面中每个记录按照主键顺序建立一个单向链表。可以理解为页面中的数据是逻辑上按照主键顺序排序的。
优化3. 记录分组 + 页目录 = 二分查找#
虽然有了按照主键排序的有序链表,但想要查找页内的一个id的时间复杂度还是很高的,最坏情况下需要遍历页面中所有的数据。
InnoDB的思路是将链表分成记录数量有限的若干个组,把查找操作的遍历页面优化成遍历组内的有限数据。
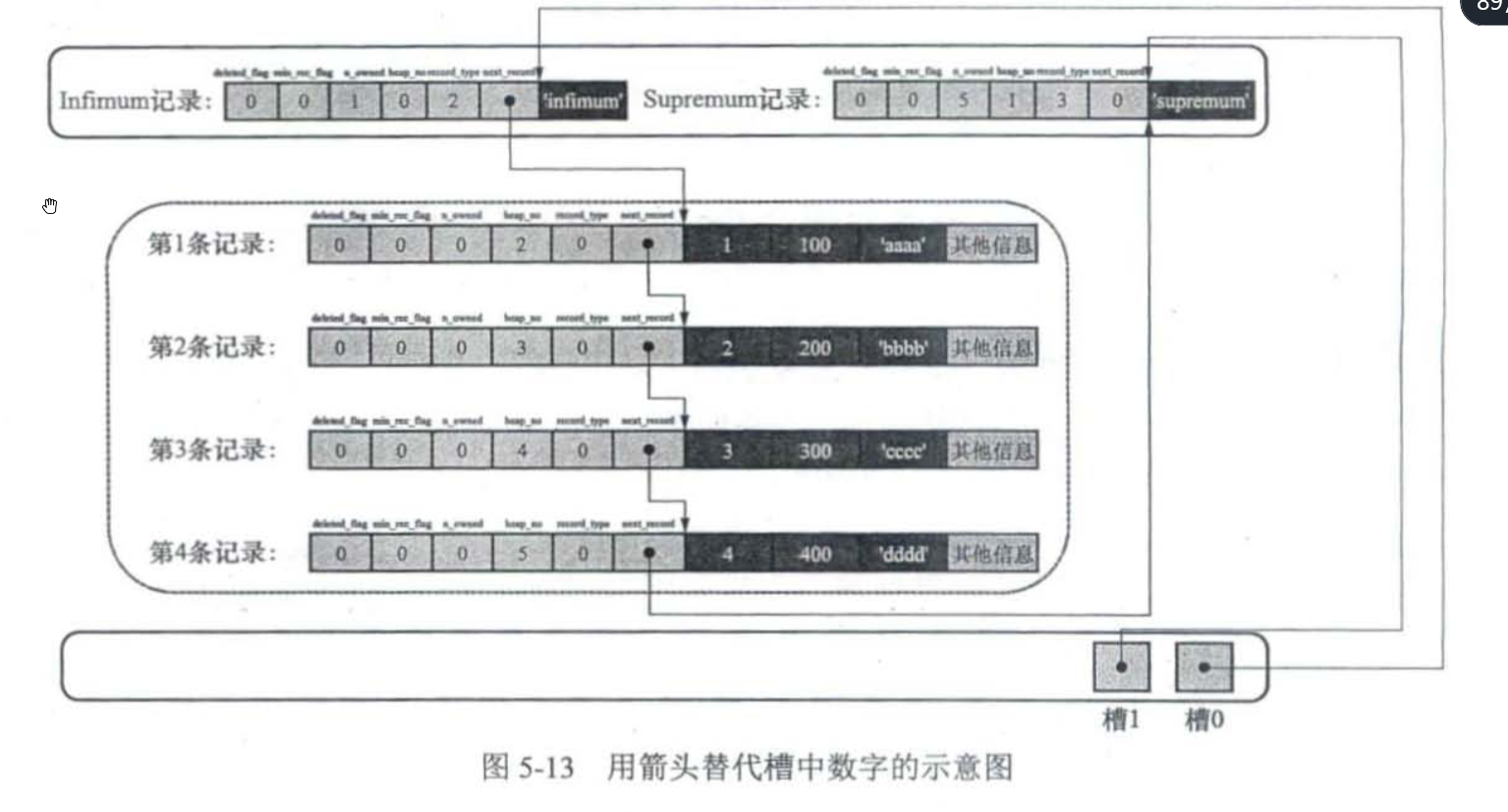
组内的最后一条数据是一个组的领头,它的n_owned属性为组内记录数量。
在页面尾部的Page Directory部分,也就是页目录部分,存储着该页中所有组的领头在页面中的偏移量。
有了分组和页目录,现在就可以根据id进行组内二分查找,定位指定id的记录所在的实际组。
页之间也是关联的#
页面File Header中有一些字段,用于描述每个页面都有的通用信息。比如下面两个:
FIL_PAGE_PREV:上一个页面的页号FIL_PAGE_NEXT:下一个页面的页号
前面已经说过,页内部的数据行会构成一个单向链表,从而保证数据的逻辑有序性。现在,页面之间也会通过这两个字段构建出一个双向链表,从而保证整体的顺序。
建立B+树索引#
现在,我们能做到的是在页面内部使用二分查找来快速定位具有某一主键值的数据,但是表文件中有很多页,我们还需要一种结构能在这些页中快速定位。这个思路和页目录的思路是差不多的,简单来说,它会把每个页中的第一条数据的主键和页号拿出来,建立一个连续结构,来用于二分查找。就称它为索引把。
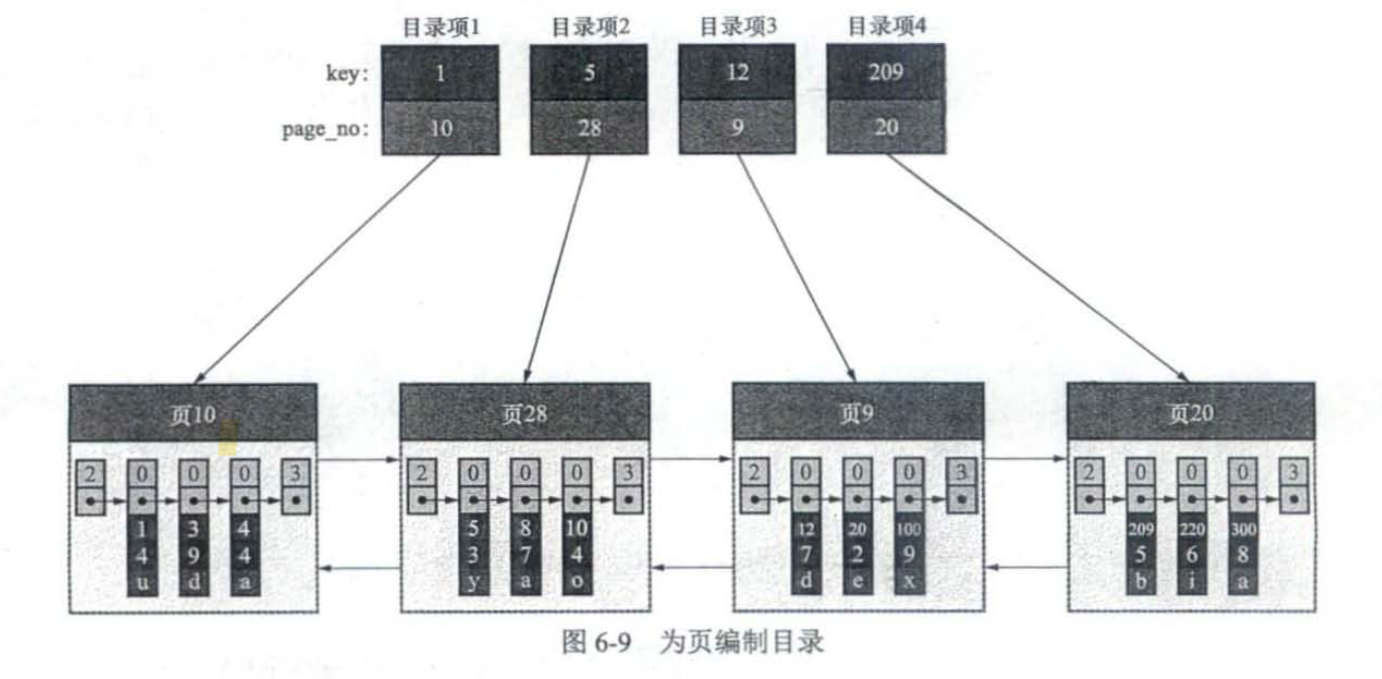
现在,我们可以在这个索引中进行二分查找,快速定位具有指定id的记录的所在页面,然后再在页面内部通过上文提到的二分查找来定位实际数据行。
但是问题依然没解决,随着页面变多,索引中的目录项也会变多,我们需要的连续空间越来越大,或许现在,是时候研究一种更加灵活的索引组织方式了。
InnoDB采用的办法是把索引项也放在普通的数据页面里,因为索引项就像只有两列的数据行,key和page_no。
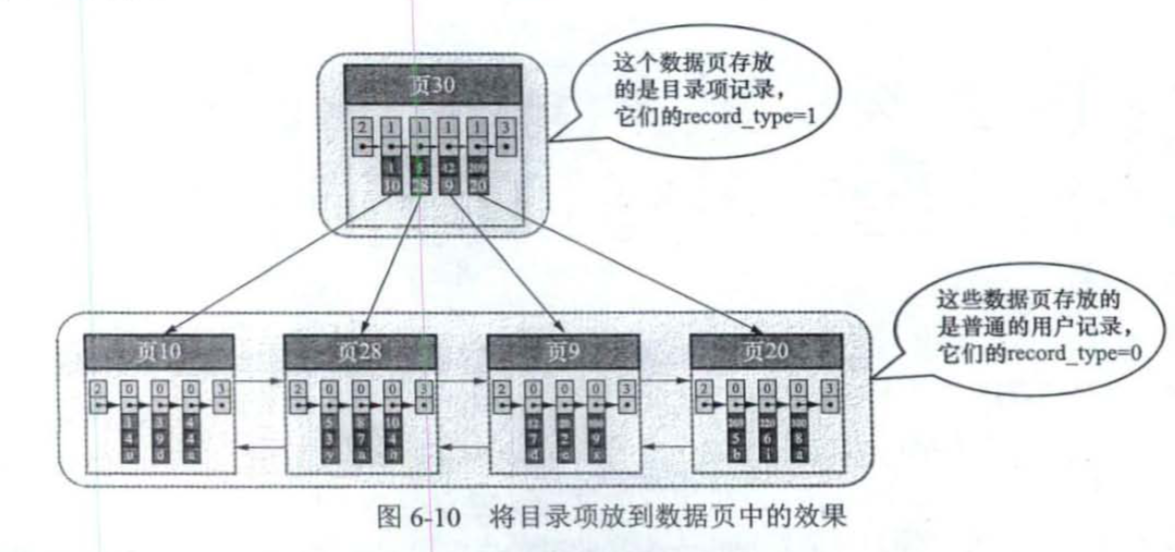
当一个页面无法容纳索引项时,可以建立多个页面。在多个页面中无法实行二分查找,所以可以建立索引页之间的索引。
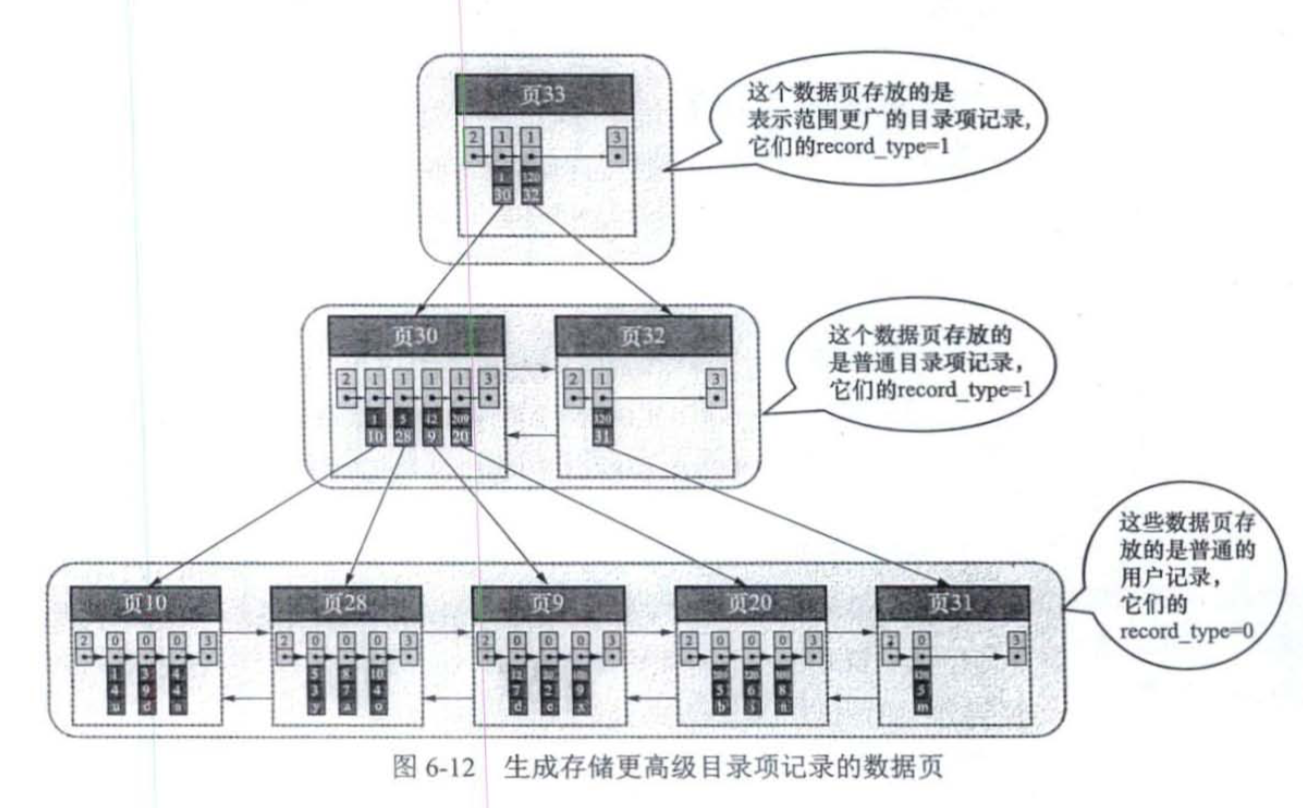
这个结构就是B+树。
上面所说的主键,只是举例,对于其它索引也是这样的。
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/17098524.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)