文件系统的实现
本篇笔记记录了OSTPE中介绍的一种简单的文件系统VSFS的实现。
文件系统,就是一种关于如何在磁盘这种块设备中建立文件、文件夹概念的一套规范
块大小定义
为了方便,文件系统需要以一种单元来操作磁盘,这个单元就是块。VSFS选择常见的块大小——4KB,并且只使用这一种大小。比如,下面是一个具有256KB的磁盘的视图,我们把它分割成64个块:

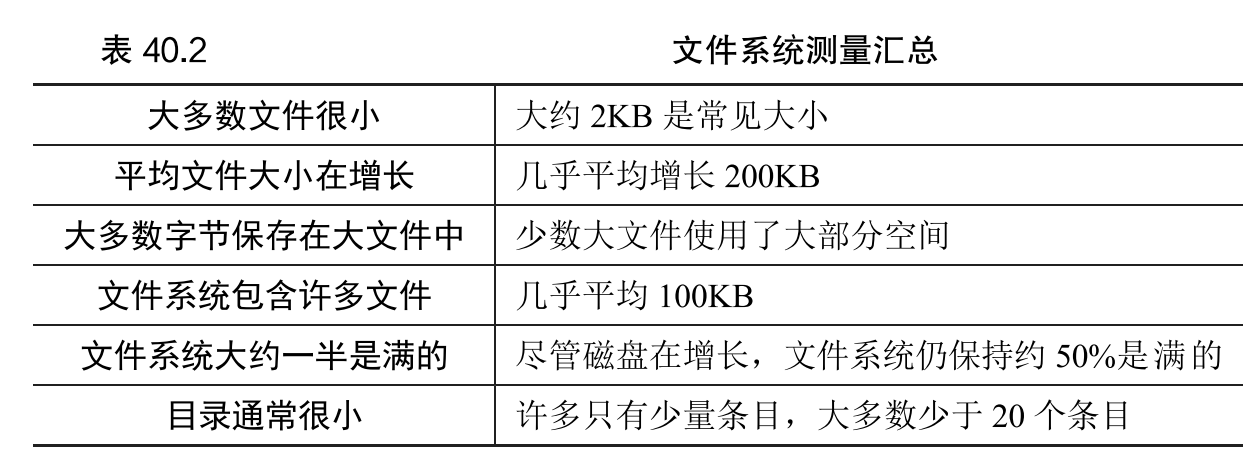
为了实现文件系统都要存什么额外的牛马?
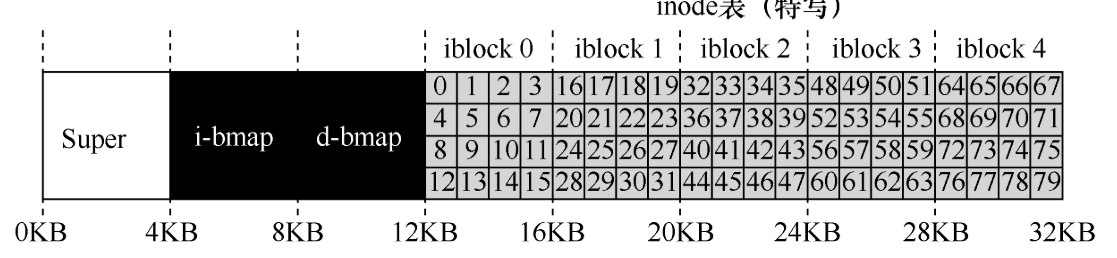
要落到物理磁盘上,就只有扇区、磁道的概念,你向上面写数据就是对一个单元的充磁和消磁操作,操作系统想要在这之上建立文件和文件夹的概念,首先就要在磁盘上组织出一些数据结构,来记录一些信息,比如用户定义的文件名与数据在磁盘上的物理位置的映射。下面是文件系统要考虑保存的一些东西
- 用户保存的数据(文件中的内容)
- 文件/文件夹的元信息(名字、创建修改时间、权限等),文件数据在哪些块中(文件系统通常使用
inode结构来保存一个文件的这些数据) - inode的表
- 记录哪些数据块和inode块已被分配
- 文件系统的元信息(比如有多少
inode、文件系统类型等)

上图中,一块块的D就是数据块,用来保存用户数据;小写d块是数据块的位图,用于保存哪些数据块的分配状态,I块中保存了若干inode节点,小写i是inode分配情况的位图,超级块S用于记录文件系统的元信息。
inode
inode列表,也就是下图这东西,其中保存了若干inode,若inode条目为256字节,那么5个4KB块就可以容纳4096/256*5=80个inode。
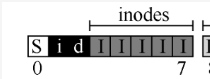
所以,我们系统中的80个inode可以被看作一个数组,它们的编号为0~79,每个inode可以保存一个文件或文件夹的信息,如下图:
一定要记住,
inode通过编号定位,每一个inode可以确定一个文件或文件夹的内容(怎么确定稍后再说),所以inode编号也被称作文件的低级名称
无论是对于文件还是目录,
inode都只保存其元信息,其内容信息保存在数据块中,稍后会看到如何通过inode确定数据块
本文讨论的只是文件系统的一种实现,不要拘泥于这个细节,而是学习它的思想。实际上,有的文件系统甚至没有
inode的概念
inode定位数据块的几种方式
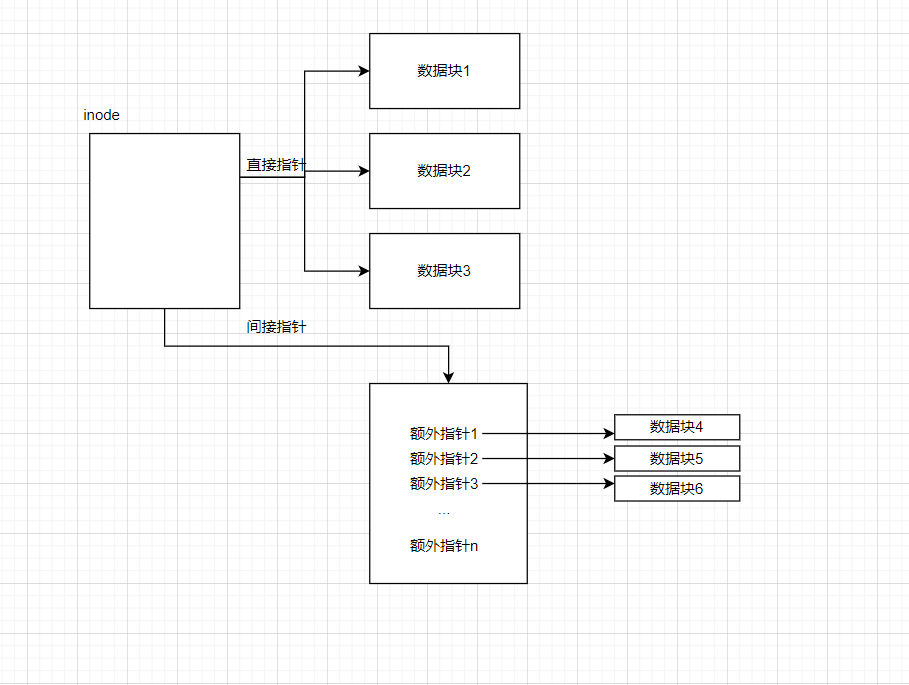
直接定位
inode中保存一个或多个直接指针,它们指向文件/文件夹对应的数据块。
缺点就是当文件/文件夹内容过大,超出指针数 * 块大小能保存的范围,就没法存了
二级索引(间接指针)
使用间接指针连接到某个数据块,然后使用数据块存储指针项,指向新的数据块。假设磁盘地址是4字节,一个4K块就能多出1024个额外数据块,文件最大大小增加到了(12 + 1024) * 4K = 4144KB。
多级索引
更大的文件可以使用一种不平衡树的多级索引形式。
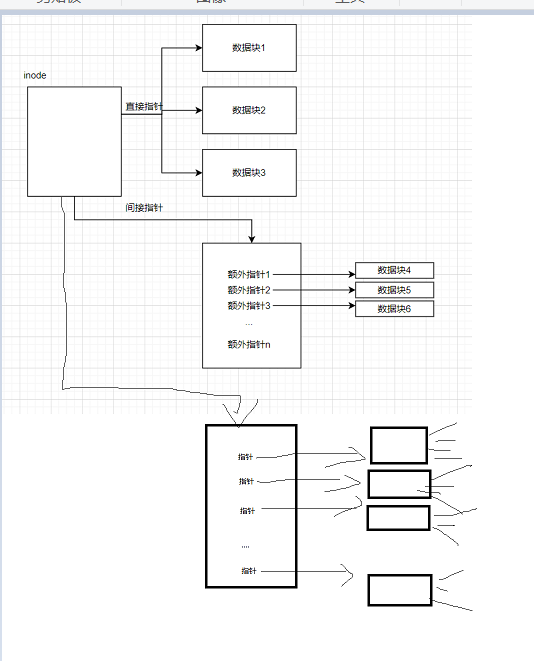
即上图中的额外指针不直接指向数据块,而是再指向具有很多额外指针的块,就是多了一级寻址,但是得到了指数级别的容量增长。
使用不平衡树的结构是因为经过统计发现多数文件都很小
其它方法
设计inode与数据块的映射并没有一个正确的办法,实际上还有基于范围、使用链表等方式,各有优缺点吧。
目录结构
对于目录来说,它的数据块中存储的就是目录结构,VSFS的目录组织很简单,就是一个(条目名称, inode号)的二元组,由于条目名称采用可变长度的,所以还引入了strlen表示名称的实际长度,reclen表示名称长度+剩余可用长度(貌似name长度的分配必须是2的次幂),下面是一个示例:

目录结构也不一定是线性表,XFS使用B树结构来维护目录信息
在目录中删除一个文件会使得目录中留下一块空白空间,可以考虑使用保留的
inum(如0)来标记该空间上的文件已经被删除,可以复用。
访问路径:读取和写入
读取文件
假设,fd = open('/foo/bar')
- 从根目录
/的inode开始访问,根的inode一定是众所周知的 - 访问根目录的一个或多个数据块,得到
foo的inode - 从
foo的inode开始,遍历它的一个或多个数据块,得到bar的inode - 将
bar的inode读入内存,在进程的打开文件表中为其分配一个文件描述符,返回给用户
其中每次访问inode可能还要进行权限检查等操作
然后read(fd),会从数据块中读取内容,并将进程内存里的打开文件表中的已读偏移量更新,下次读取就不会从0开始读。
close(fd)时,只释放内存中的文件描述符,没有IO操作。
创建并写入
假设我们创建一个/foo/bar并写入3个4KB数据
- 读取
inode位图,找到一个空闲位置,准备分配给bar - 更新
inode位图,让这个位置不再空闲 - 读写
bar的inode - 从根目录
/的inode开始访问 - 访问根目录的一个或多个数据块,得到
foo的inode - 读取
foo的inode,找到一个空闲位置(假设有空闲位置) - 将
bar的inode号与它的高级名称写入到foo的inode空闲位置上
下面开始写入数据
- 读取数据块位图,找到一个空闲位置
- 写入数据块位图
- 读写
bar的inode,这个目的是将新的数据块和bar的inode建立关联 - 实际写数据块
操作系统可以利用缓存来降低读写一个文件时或访问长路径时带来的IO次数。
性能问题的考虑:FFS(快速文件系统)介绍
现在将整个磁盘看作一个庞然大物,在其中放入超级块、inode位图、数据块位图以及若干inode块、数据块,这样做确实能建立一个文件系统,但有很多问题:
- 一个文件/文件夹的
inode和数据块在物理磁盘上极有可能是离散的 - 一个文件夹和它的文件的块在物理磁盘上极有可能是离散的
- 由于随机分配,随着使用时间的增加,磁盘碎片化将越来越严重
组织结构:柱面组
FFS从磁盘的物理结构考虑,将磁盘分为若干柱面组。一个磁盘有若干盘片,盘片上有一圈圈的磁道,多个盘片上的同一条磁道称为一个柱面。磁盘在一个柱面上操作,不需要寻道时间。(寻道时间是随机磁盘访问中占最大头的时间)
下图是G0~G9十个柱面组。

每个柱面组中有自己的超级块、inode和数据块以及它们的位图。

分配策略
目录分配:
- 分配数量少的柱面组优先,目的是尽量使组中的内容数量平衡
- 具有大量自由inode的柱面组优先,目的是随后能分配一堆文件
文件分配:
- 尽量将文件数据块分配到与其inode同一个柱面组中
- 尽量将位于同一目录中的所有文件放在与目录相同的柱面组中
- 对于大文件,它可能导致其它文件的数据块没法满足前两条,所以FFS将大文件分割放到不同的柱面组中(块越大花在传输上的时间比率越高,但太大就失去了分块的意义)
- 对于小文件,FFS具有子块的概念,避免一个小文件也要占用至少4KB(一个块大小)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号