Kafka Consumer细节
poll
IO模型与内部线程
Consumer消费多个来自多个Topic的多个分区的数据,在新版本中,它使用类似select、epoll这种IO模型来达到用一个线程管理多个来源的数据的功能。
不过,Consumer内部还是分为两个线程:
- Heartbeat线程:定时向broker发送heartbeat请求
- 用户主线程:处理其它所有工作的线程,如:
poll、消息业务处理、rebalance相关逻辑、位移提交等操作都在该线程中处理
Kafka消费者线程不安全,除了wakeup方法可以在其它线程被安全地调用。
poll和wakeup
consumer.poll会阻塞,直到:
consumer已经获取到了足够大小的数据- 到达
poll中设置的timeout
timeout的设计主要是为了让消费者不一直阻塞,因为消费者除了poll消息,还可能做一些别的事,比如:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(TIMEOUT);
for (ConsumerRecord<String, String> record : records) {
consumeIt(record);
}
doSomething();
}
wakeup是主动结束poll的阻塞,poll方法会抛出WakeupException。
位移管理
- Consumer Group会在集群中选择一个broker做该消费者组的coordinator
- 使用内部topic来保存Consumer提交的位移值
如何保存位移信息
Consumer运行一段时间后,会向它所属组的coordinator提交位移,这会向__consumer_offset这个内部topic的对应分区上写入一条key为(group.id, topic, partitions)的元组,这样就能唯一定义一个消费者组对某个topic的某个分区的消费进度,而这条消息的value就是offset值。
提交位移不及时带来的重复消费
如果Consumer崩溃,那么它上次提交offset到它崩溃时的那些消息就会被rebalance后接替它消费该分区的Consumer重复消费,coordinator会认为这些消息尚未被消费过。
重复key的压实
由于Consumer会一直提交自己的位移,所以__consumer_offset中应该有很多相同的key,最后那个才是有效的,Kafka会使用压实策略来处理这种消息使用模式。
自动提交/手动提交
Kafka会在auto.commit.interval.ms的间隔内自动提交位移,这个间隔是五秒,这样是会造成重复消费的,如果想要在消息中间件层面最大程度的保证一条消息只会被消费一次,可以使用手动提交位移(当然,肯定还是有重复消费的可能,比如消费完成后手动提交前宕机)
- 设置
enable.auto.commit=false - 消费消息后使用
consumer.commitSync或consumer.commitSync
rebalance
组订阅的topic的每个分区只会分配给组内的一个consumer实例
触发条件
- 组内成员变更
- 组订阅topic变更(如使用正则)
- 组内订阅topic分区变更
分配策略
- range:没看懂是咋分的
- round-robin:将topic所有分区轮询分配给每个consumer
- sticky:粘性策略,保证最大限度平衡的情况下尽可能保证一个分区在重平衡后依旧由之前的consumer处理
- cooperative sticky:和
sticky一样的逻辑,但允许合作式的rebalance
默认是[range, cooperative sticky],即默认用range,但可以升级到cooperative sticky
rebalance generation
就每次rebalance后,该consumer group的generation就多1,相当于老了一代。那当rebalance后,如果rebalance前的offset提交请求由于网络延迟到达,该请求会被丢弃。
rebalance协议
rebalance是group与coordinator需遵循的一组协议。
1. JoinGroup
当一个Consumer启动时,它发送FindCoordinator请求来获取负责它的coordinator,然后,向它发起JoinGroup请求来rebalance。
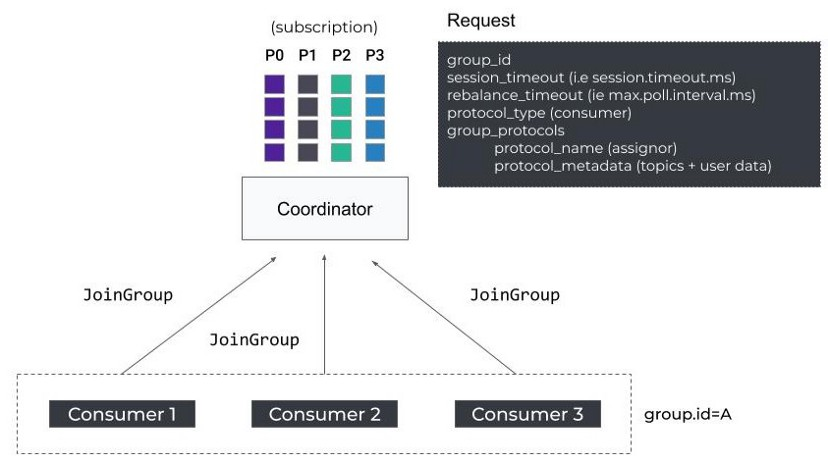
JoinGroup包含一些客户端配置,比如session.timeout.ms和max.poll.interval.ms,这用于coordinator在Consumer无响应时将它们踢出。
此外,请求还包含了一些协议组,比如上面说的分配策略列表(assignor)。
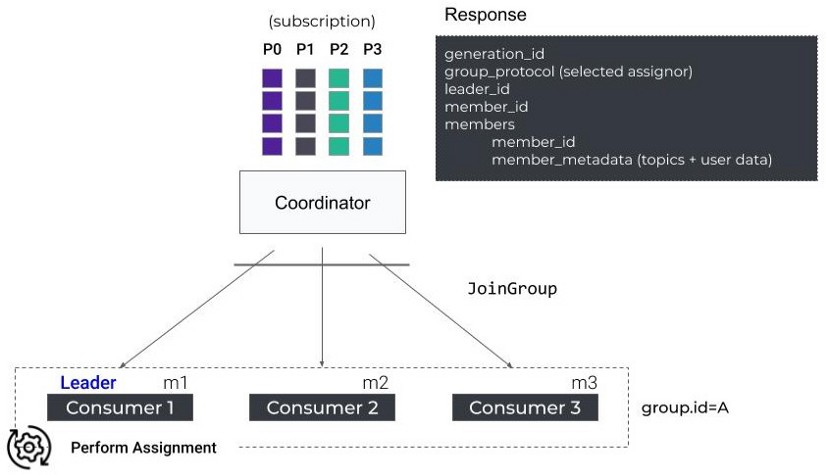
组中的第一个Consumer作为组leader会接收到当前活动成员的列表以及当前选中的分配策略,而其它的则接收到空返回,组leader负责在本地执行分区分配策略。
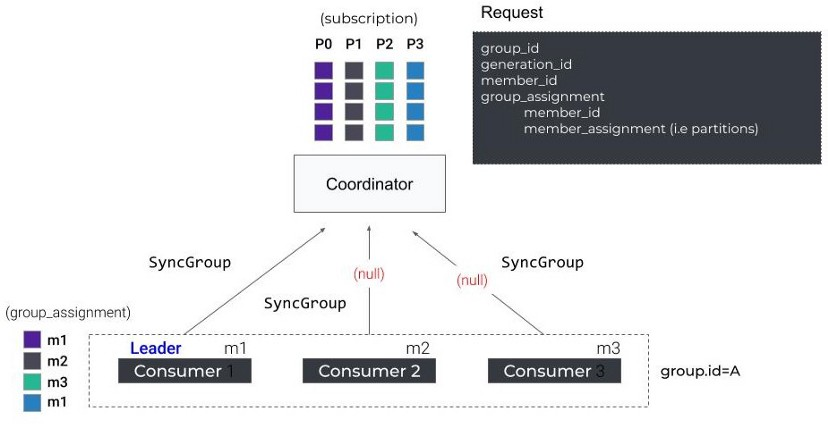
2. SyncGroup
然后,所有成员发送SyncGroup请求到coordinator,Group Leader会在其中附加一个计算好的分区分配信息,而其它的就发空请求。
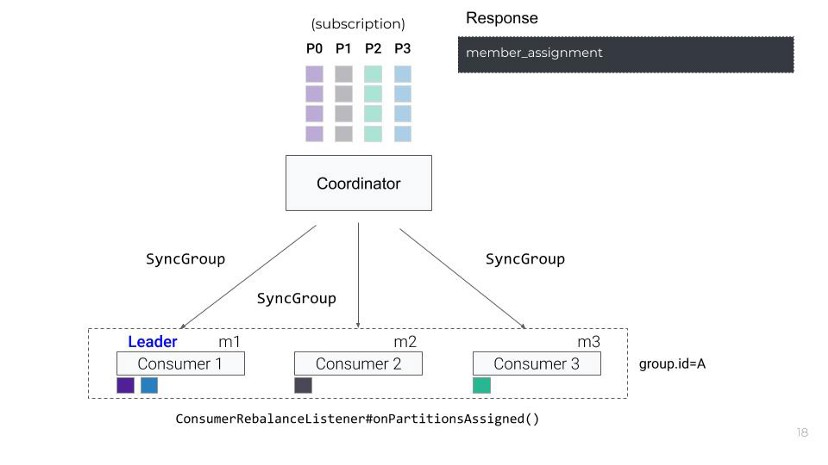
一旦coordinator响应所有的SyncGroup请求,每一个消费者就接收到了它们被分配到的分区
3. Heartbeat
Consumer周期性的给coordinator发送Heartbeat请求以维持会话。
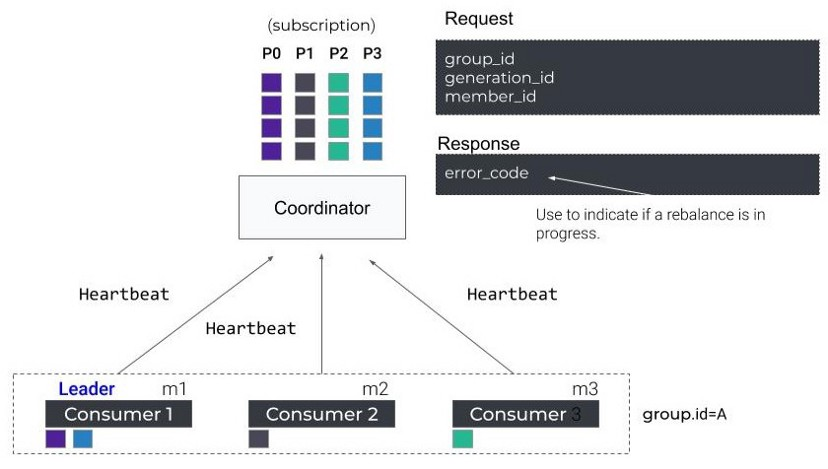
如果正在执行rebalance,coordinator发送一个Heartbeat响应来告诉Consumer,它们需要重新加入组。
4. LeaveGroup
Consumer通知coordinator主动离开组
rebalance流程
这一节会有些和上一节重复。
确定coordinator
Consumer Group决定rebalance后,它要确定它的coordinator所在的broker。
Math.abs(groupID.hashCode) % offsets.topic.num.partitions,就是hash后均匀分配到一个offsets topic的一个分区上,即选择一个保存组内成员offset的分区- 然后,找到这个分区的leader副本所在的broker,它就是当前组的coordinator
执行rebalance:加入组
找到coordinator后,组内全体Consumer加入组,它们发送JoinGroup请求,当集齐组内所有成员的JoinGroup请求后,coordinator选择一个作为Group Leader,并把所有成员以及它们的订阅信息(订阅了哪些topic)发给Leader。
执行rebalance:同步更新分配方案
leader将所有订阅的topic中的分区在组内成员内按照分配方案进行分配,并把分配结果通过SyncGroup发给coordinator,其它人发送空的SyncGroup请求,coordinator将每个人的分配方案抽取出来通过SyncGroup响应返回给各个Consumer。
从这一段中可以发现,Kafka的rebalance中的实际分区分配是在客户端完成的,这给分区分配带来了高度的扩展性和灵活性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号