Kafka概览
主要概念和术语#
Event(事件)是一个现实世界或业务中发生的事,也叫消息或记录,说白了就是你写入Kafka的消息。Event具有key、value和timestamp,这和其它的消息系统有点儿不一样。
Producer和Consumer不介绍了,官方文档有这么一句话:Producer从不需要等待Consumer,Kafka具有多种类似“只处理消息一次”的保证。这应该是说Kafka中没有类似ack这种确认机制,但是是有其它的机制来提供这些保证的。
Topic就是消息被存储的地方,它可以有零到多个Producer和零到多个Consumer。Kafka不会删除已经消费的消息,而是你来在每个Topic中定义消息会被保留多久,Kafka的性能和数据大小无关,所以可以在系统中长时间的保存数据。咋感觉这玩意儿有点特立独行。
Topic会被分区(partitioned)成多个桶到不同的Kafka Broker中,客户端可以并发的从多个Broker中读取数据,增加可扩展性。具有同样key的event会被投放到同一个分区中,Kafka保证分区中的消息按照写入顺序被读出。(相当于分片集群喽)
Topic分区可以被副本(建立主从),推荐使用3作为副本因子,你的分区数据总有3个拷贝。
主从延迟#
- AR(Assigned Replicas):分区所有副本
- ISR(In-Sync Replicas):与leader副本保持一定程度同步的副本
- OSR(Out-of-Sync Replicas):与leader副本同步滞后到一定程度的副本
,正常情况下,,
- HW(High Water):高水位,用来限制消费者能读到的消息内容
- LSO(Log Start Offset):0
- LEO(Log End Offset):日志文件中下一条代写入消息offset
假设向leader中写入两条offset为3和4的消息,现在两个follower需要同步这两条消息。
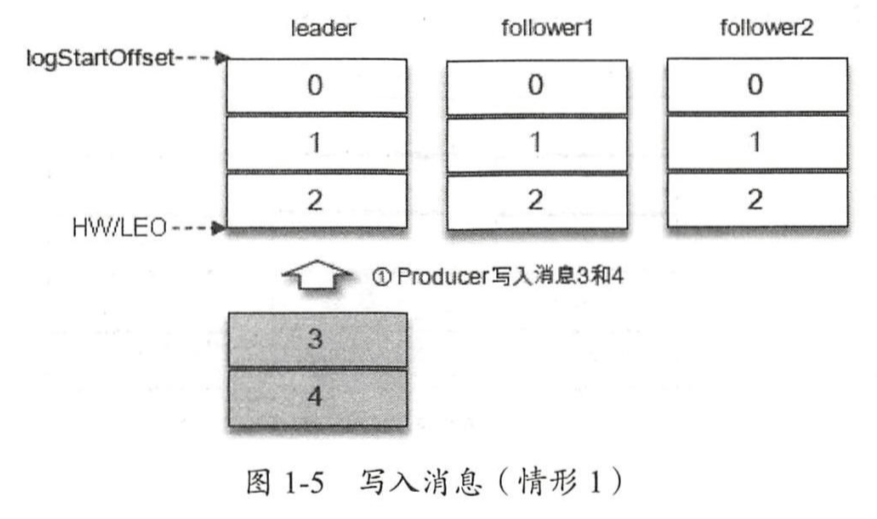
假设follwer1在一段时间后同步了3和4,但follwer2只同步了3,那么此时,HW为4,用户能读取到的最大消息offset为3。避免了由于主从消息同步延迟让用户读取到旧数据。
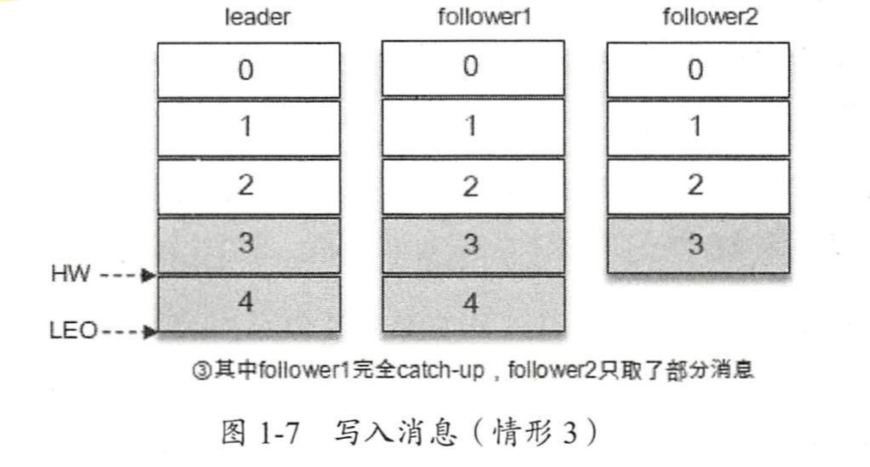
HW为在所有副本中都存在的最大消息offset+1,LEO为leader中最大消息offset+1
设计#
持久化设计#
Kafka不像其它消息队列,把消息先放到内存中,它直接把消息存到磁盘,一个持久化日志(persistent log)里。
官方给的理由大概就是:
- 如果都是顺序磁盘访问那性能可以接受
- 操作系统提供预读(read-ahead)和后写(write-behind)技术,在顺序磁盘访问情况下减少IO次数(减少频繁的小IO操作)
- 操作系统大都会将磁盘页尽可能多的缓存到内存中,没必要再自己建立个类似内存缓存的东西
- Java中Object对象的开销很大,并且对象越多GC压力越大(避免使用内存)
- 使用操作系统的页缓存,即使Kafka重启,缓存还是热的
总之,所有数据立即写入到文件系统的持久化日志中,并且不必须flush到磁盘里,这意味着它们将被传输到内核的页缓存中。
另外,Kafka使用日志形式的追加文件做消息队列,无论数据多大,对数据的读写操作都是O(1)的常量时间(B+树则需要O(logN))
效率#
为了避免小IO操作,Kafka的协议围绕“消息集合”(message set)建立,可以自然地将多个消息组合在一起,带来更大的网络包、更大的顺序磁盘访问以及相邻的内存块。所有这些都允许Kafka将突发的随机消息流变成线性的顺序消息流,流向消费者。
为了避免无用的字节拷贝,Kafka的Broker、Consumer和Producer都使用相同的格式来存储message log——以目录或者文件的形式存储,数据块可以在它们之间直接进行传输而无需任何修改,再配合上sendfile系统调用后,这些数据无需拷贝到用户内存,直接内核中进行传输。这好像就是传说中的零拷贝吧。
sendfile()在两个文件描述符之间拷贝数据。因为这个拷贝是在内核中发生的
sendfile()比组合使用read(2)和write(2)更加高效,后者需要向用户空间传送或从用户空间获取数据。
不用sendfile():
- OS从文件拷贝到pagecache
- app从pagecache调用read拷贝到用户空间
- app从用户空间调用write拷贝到内核socket缓冲区
- 内核从socket缓冲区拷贝到网卡的NICbuffer
最后一个不可避免,使用sendfile可以直接从文件的fd拷贝到socket的fd。
为了避免用户自行压缩造成的同类数据中的冗余结构(比如用户发送两次User对象,User对象具有相同的结构,但这个结构信息却要在每条独立消息间存在),Kafka支持批量格式化,即把一批数据压缩后发给服务器,并且它只会被消费者解压。
Consumer Pull模式#
消息队列中有两种消费模式,broker push给consumer和consumer向broker pull,它们各有优劣,pull的方式更适合Kafka。
- 不同消费者按照各自的处理能力进行pull,不会出现consumer被压倒的情况
- 能够推动消息的batch处理,消费者可以直接拉取多条数据,而在push-based的消费模式中,想实现这一点,broker必须在没有消费者处理能力的预备知识的情况下在内部积攒消息,这会引起额外的延时,而pull-based则没有这种延时
Pull请求中还可以设置参数,在broker中没有数据时阻塞,以免消费者不断轮询broker。
Consumer位置#
不像其它系统在发送消息后记录某些消息的元数据,然后等待Consumer的ACK,Kafka保证消息被Consumer成功接收的方式很不同。
它的Topic被分成了一系列完全有序的分区,每一个分区在一个给定时间只会被订阅的Consumer组中的一个确切Consumer消费,好像是Kafka并不记录任何消息是否被接收的信息,而是由Consumer自己维护一个offset,记录它自己需要读哪个位置的信息,并且允许自由设置这个offset到之前的位置。
具体我也没太搞明白,等大致看一下这个设计部分之后动手写一些代码再来深究原理。
消息递送的语义保证#
- At most once:消息可能会丢失但永远不会被重复传送
- At least once:消息永远不会丢失但是可能会被重复传送
- Exactly once:消息会被传送且仅会被传送一次
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16812812.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)
2021-10-21 实体联系模型