IO多路复用模型以及select、poll、epoll系统调用
同步阻塞、同步非阻塞#
哪里阻塞?
考虑一个网络应用,通信双端需要交换数据,接收方能接到数据的前提是发送方发送了数据,下图中,发送方根本没法数据,接收方收个毛线?
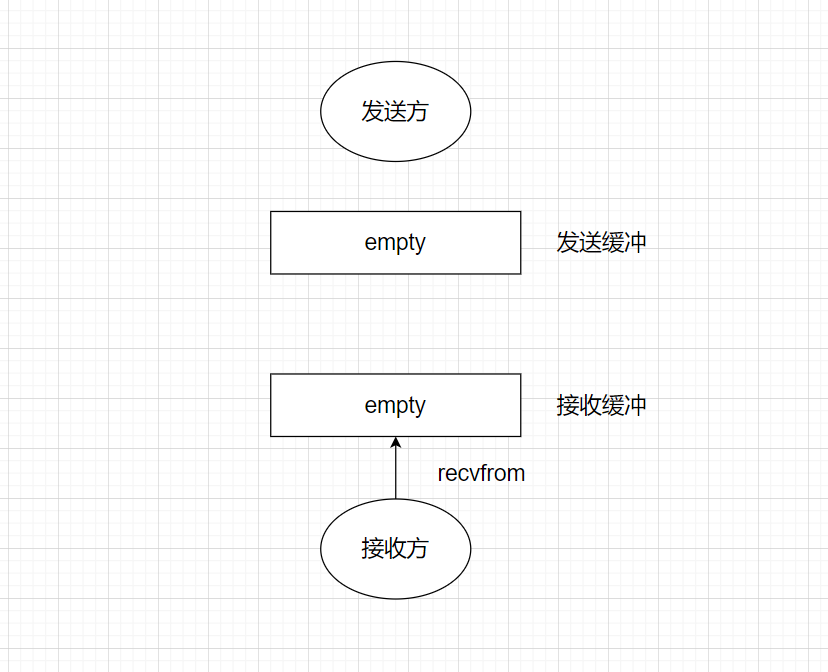
而这里的阻塞,说的就是当接收方调用recvfrom开始接收数据时,若没有数据到达TCP接收缓冲,接收方是否阻塞。
所以
- 同步阻塞:当调用
recvfrom时没有准备好的数据,调用线程阻塞在这 - 同步非阻塞:当调用
recvfrom时没有准备好的数据,调用线程直接返回,接到错误码
好处和坏处#
- 同步阻塞,线程需要进入阻塞状态
- 同步非阻塞:线程不需要进入阻塞状态,但需要不断轮询
recvfrom,占用CPU时间片
IO多路复用模型#
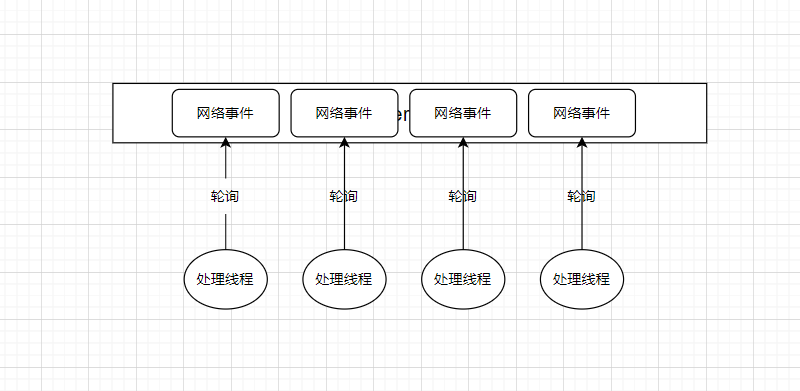
考虑非阻塞情况下,你使用多线程来开发网络应用,这些线程不断的调用recvfrom,向内核轮询是否有消息处理,占用大量CPU时间片。
如果转化成下面的形式,操作系统提供select系统调用,它是一个阻塞调用,它不断轮询所有关心的网络事件,若其中有任何一个有数据,就返回。
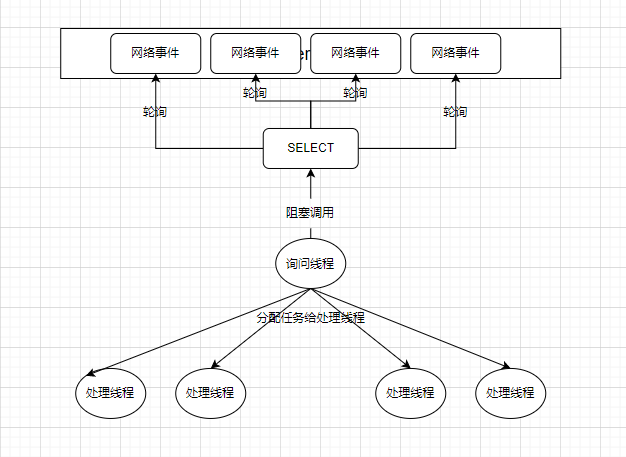
这样,我们只需要一个询问线程来阻塞在SELECT上,当有关心的网络事件,询问线程就会被唤醒,然后创建处理线程(或使用线程池)并分配这些任务给处理线程。用一个媒介来承载多种信号的传输,这种思想叫做多路复用,上面的例子不就是用一个SELECT调用来承载之前多个线程的数据轮询工作嘛。
- 和阻塞IO相比,不会存在大量由于等待数据而只能阻塞的线程(解决线程闲置)
- 和不使用IO模型相比,不会存在大量线程轮询CPU,只在有数据时创建必要线程(解决大量线程无意义占用CPU)
从网络事件到文件描述符#
Unix中的一个基本概念就是,一切皆文件。每一个进程都有一个文件描述符表,包含指向文件、socket、设备以及其它操作系统对象的文件描述符。
所以,在Unix中,网络连接也以文件描述符的形式呈现,无论是读取、写入,都是基于这个文件描述符操作。我们可以看出,socket编程中用于接收数据的recv的几个方法接受的第一个参数都是一个文件描述符(file discriptor,fd)。
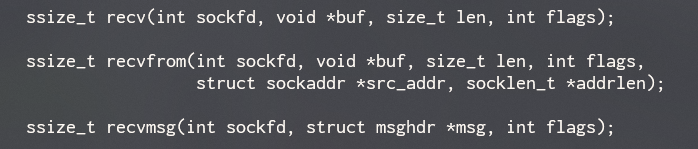
无论是select,还是经常被拿来横向比较的poll或是epoll,都是内核提供的一种机制,它接收一个关心的文件描述符集合,并且告诉内核,你关心这些文件描述符的什么事件,是读啊、写啊、亦或是异常啊。你使用一个线程去阻塞在这些方法上,直到有至少一个你关心的文件描述符以及对应的操作发生。
select模型的细节#
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
从select的函数签名中,大概就可以看出:
- 你可以分别传递你关心其读取、写入以及异常操作的文件描述符集合(
fd_set) - 你可以指定一个
timeout,即select的最大阻塞时间,如果在这个时间后还没有关心的事件发生对应操作,就停止阻塞
我们来用一下select,假设我们现在有一个服务器,它要服务5个客户端,5个客户端会不停的向它发送数据:
// 客户端代码
void child_process(void)
{
// ... 省略一些代码 ...
// 创建到本地,2000端口的socket TCP连接
sockfd = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// 连接
connect(sockfd, (struct sockaddr*)&addr, sizeof(addr));
printf("child {%d} connected \n", getpid());
while(1){
// 睡眠随机时间
int sl = (random() % 10 ) + 1;
num++;
sleep(sl);
// 生成发送的消息
sprintf (msg, "Test message %d from client %d", num, getpid());
// 向TCP连接的socket文件描述符写入消息
n = write(sockfd, msg, strlen(msg)); /* Send message */
}
}
// 服务器代码
int main() {
// 省略一些代码...
int fds[5];
// 读取的文件描述符集合
fd_set rset;
// 创建socket并绑定到本地的2000端口,监听本地端口
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof (addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd,(struct sockaddr*)&addr ,sizeof(addr));
listen (sockfd, 5);
// accept这五个客户端的连接
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
// 拿到到对应连接套接字的文件描述符,放到fds[i]中
fds[i] = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 维护max,让它保存五个客户端连接的文件描述符中最大的一个
if(fds[i] > max)
max = fds[i];
}
// 开始阻塞在select上
while(1){
// 将要读取的文件描述符集合清零
FD_ZERO(&rset);
// 将fds中的每个文件描述符都设置到rset中,我们关心这五个TCP连接的读取事件
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);
}
puts("round again");
// [+] 重点,调用select开始阻塞,将rset传入到关心读取的fd_set参数上
select(max+1, &rset, NULL, NULL, NULL);
// 只有当那五个TCP的sockfd有任意一个发来数据,select阻塞才解除
// 而关于具体哪个sockfd中有数据,我们只能通过`rset`知道
// 此时`rset`中包含的就是所有有数据的sockfd了
// 所以,我们要遍历所有我们关心的文件描述符,看它是否在fd_set中,若在就对它进行读取
for(i=0;i<5;i++) {
if (FD_ISSET(fds[i], &rset)){
memset(buffer,0,MAXBUF);
read(fds[i], buffer, MAXBUF);
puts(buffer);
}
}
}
return 0;
}
令我很好奇的是select调用的第一个参数,它的参数名是nfds,从名字理解起来像我们关心的文件描述符个数,但为啥这里我们实际传递的确实max+1(最大文件描述符+1)?
实际上,fd_set是一个32个integer的数组(32*32bit=1024bit,进程能打开的最大文件描述符数),为了得到你关心的文件描述符,select方法中需要遍历整个1024个位,但如果你给它一个最大值,它只需要遍历到最大值即可。但无论如何,也无法改变这是一个操作的事实。
select总结:
- 我们需要在每次调用时重新构建
fd_set - 它会以的复杂度检查所有位
fd_set需要不断的在内核和应用程序间复制- 我们还要迭代所有我们关心的文件描述符,判断它是否在返回的
fd_set中
况且,我们这才使用了监控读取事件的
rset,如果剩下两个也用上,想想都头痛。
当然,select还有好多更深层次的细节,以我目前的水平暂时理解到这儿。
更好的模型#
综上所述select的设计有很多地方还是不太优雅,有没有更优雅的系统调用?
poll#
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
从方法签名上看,就是将select针对不同操作的三个独立的fd_set参数整合成了一个,那它怎么判断针对每个fd要监控的事件?而且同一个fd有可能需要监控不同的事件。
pollfd的结构体定义了一个events和一个revents,它们也是两个位图,每一位代表一个事件,events代表监控的事件,revents代表返回时具有的事件,监控事件和返回事件分离的设计让我们不用像使用select一样,每次都重新构建fd_set
struct pollfd {
int fd;
short events;
short revents;
};
下面是用poll来重写上面服务器功能的代码:
// accept五个客户端的连接
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
// 向pollfd中设置文件描述符
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 向pollfd中设置关心的事件
pollfds[i].events = POLLIN;
}
sleep(1);
while(1){
puts("round again");
// 调用poll,无需重复准备`pollfds`
poll(pollfds, 5, 50000);
for(i=0;i<5;i++) {
// 判断返回的pollfds中是否有POLLIN事件,如果有,读取
if (pollfds[i].revents & POLLIN){
pollfds[i].revents = 0;
memset(buffer,0,MAXBUF);
read(pollfds[i].fd, buffer, MAXBUF);
puts(buffer);
}
}
}
poll总结:
pollfds并不是位图,我们要监控几个文件描述符,其中就有几个元素,这样的话,我们不用传递一个最大fd+1,poll也不用去遍历所有可能的fd- 因为第一点,所以对于较大的
fd,poll比select有性能优势 pollfd由于具有revent字段,所以我们可以在下次调用poll时复用之前的pollfdspoll要传递到内核的文件描述符数据结构(pollfds)是动态的,而select永远是32个integer
select比poll更加通用,一些unix系统不支持poll
epoll#
当我们使用select和poll时,我们在用户空间中管理所有事儿,并且我们在每次调用时都要发送所有关心的文件描述符到内核,如果我们想添加一个新的文件描述符,我们就要将它加到集合中并重新调用select和poll。
epoll帮助我们在内核中创建和管理上下文,(使用epoll)我们可以把任务分为三步:
- 使用
epoll_create在内核中创建一个上下文 - 使用
epoll_ctl向上下文中添加或移除文件描述符(和关心的事件) - 使用
epoll_wait等待上下文中的事件
使用epoll完成上面的代码:
// epoll事件列表
struct epoll_event events[5];
int epfd = epoll_create(10);
...
...
// accept五个客户端的TCP连接
for (i=0;i<5;i++)
{
// 创建一个epoll事件
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
// 设置文件描述符
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
// 设置关心的事件
ev.events = EPOLLIN;
// 添加事件到内核中的上下文
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev);
}
while(1){
puts("round again");
// 等待,返回值是事件发生了的fd数量,也就是说有数据到达的fd数量
nfds = epoll_wait(epfd, events, 5, 10000);
// 只需要遍历必要的fd数量即可
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
// 这里使用的events[i],应该是有事件发生的epoll_event会被内核重排序在前面
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
epoll总结:
- We can add and remove file descriptor while waiting
- epoll_wait returns only the objects with ready file descriptors
- epoll has better performance – O(1) instead of O(n)
- epoll can behave as level triggered or edge triggered (see man page)
- epoll is Linux specific so non portable
上面是原文给的总结,总结里的好多内容在原文里没有提到,而且,这篇文章可以作为一个很好的入门文章,但它讲的内容还是比较浅,所以我打算后面再研究研究,不过,最起码现在我们知道了
epoll在内核中维护文件描述符上下文,所以我们不用每次调用都向内核复制文件描述符列表epoll中,我们不需要遍历所有我们监控的fd,只需要遍历已经准备好的那些
参考文章#
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16735418.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)