缓存常见的问题
前言#
本篇文章只是看别人总结后的文章之后自己进行的梳理,所以内容和原文章基本没什么区别,参考的所有原文章在文末。
问题#
缓存穿透#
缓存穿透是指用户在访问一个并不存在于缓存中并且也并不存在于数据库中的数据,这样的数据无论访问多少次,最终还是会打到数据库上。
解决办法1:缓存NULL#
将从数据库中检索到的null存入缓存中,以防后面同样的访问再次进入数据库
需要注意,缓存穿透现象可能会很多,为了避免NULL缓存占用过多空间,需要设置合理的过期时间
解决办法2:布隆过滤器#
缓存穿透问题也可以转换为判断一个元素是否在集合中的问题,布隆过滤器用的时间复杂度(k是较小的一个常数)来解决这个问题。
使用一个具有位的底层比特数组以及个不同的均匀哈希算法,初始情况下,比特数组所有元素均为,对于每一个,使用个哈希算法分别计算哈希值,并将其作为比特数组的下标设置对应的位置为。
于是:
- 对应的比特位全为1 => 该可能可能在集合中
- 对应的比特位中包含0 => 该一定不在集合中
优点:
- 节省空间
- 时间复杂度低
缺点:
- 可能出现哈希冲突
- 无法从布隆过滤器中删除一个元素
- 存在假阳性,即可能认为一些本不在集合中的数据在集合中,前两点就是造成假阳性的条件
缓存击穿#
缓存击穿是指一个热点数据的缓存突然失效,大量的访问瞬间打到数据库中。
解决办法1:互斥锁#
对于缓存失效需要检索数据库的情况,可以使用一个互斥锁(在分布式情况下就是分布式锁),保证只有一个请求打到数据库中,其它的请求可以采取自行睡眠稍后再获取缓存;直接失败;自旋等各种方法
优点:
- 实现简单,一刀切
缺点:
- 降低系统的吞吐量
- 造成大量请求长时间等待(但也比让该情况堆积到数据库后再等待并承担数据库被击垮的风险好)
解决办法2:不失效缓存#
起码是对于热点数据,可以考虑不进行失效,或者使用一种更加缓和的失效策略
比如将缓存的失效时间存放到缓存value上,如果在访问时发现缓存过期了,就启动一个异步更新缓存的任务,同时在这段时间里,旧缓存仍能提供访问。
优点:
- 性能高,并发性好
缺点:
- 一致性较差
缓存雪崩#
缓存雪崩是指大量的缓存在同一时间过期,导致大量请求打到数据库。看起来和缓存击穿带来的结果差不多,但成因不同。
解决办法:
- 在过期时间上加或减固定范围的随机值,避免缓存在同一时间过期
- 不失效缓存
- 分布式锁
- 双层缓存
双层缓存策略中有两个缓存:
- 主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值
- 备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存
缓存更新策略#
缓存更新策略研究的是对于数据库和缓存,应该以什么样的顺序更新的问题。常见的缓存更新策略有:
- Cache aside
- Read through / Write through
- Write back(Write behind)
缓存更新策略并不能解决缓存不一致问题,只是关于如何操作DB和缓存数据的一些经验方法。
Cache aside#
读#
- 先读缓存
- 若命中,直接返回
- 否则,加载数据库并写入缓存,返回数据
关于它为啥叫Cache aside,或许就是如果缓存命中就可以直接从旁边开出一条捷径吧,如下图:
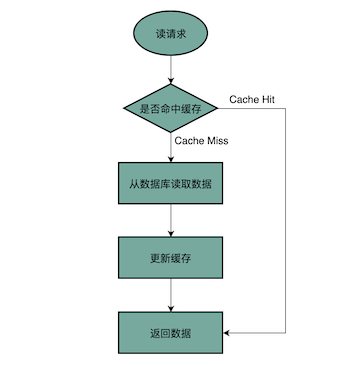
该图来自于原文章,文章链接在文末
写#
- 写数据库
- 删除缓存
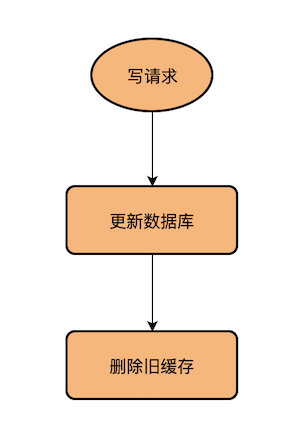
该图来自于原文章,文章链接在文末
为什么选择先写数据库再删缓存#
数据库发生更新时要更新缓存数据,此时有三条路可走:
先更新DB再直接更新缓存:
1. A更新DB => 1
2. B更新DB => 2
3. B更新缓存 => 2
4. A更新缓存 => 1
数据库和缓存发生了不一致
先删除缓存后更新DB
1. A删除缓存
2. B读取缓存未命中,打到数据库,得到 2
3. B设置缓存 => 2
4. A更新DB => 1
数据库和缓存发生了不一致
先更新DB后删除缓存
1. A读取缓存未命中,打到数据库,得到 1
2. B更新DB => 2
3. B删除缓存
4. A更新缓存 => 1
数据库和缓存发生了不一致
在上面三种方式上,都会发生缓存不一致问题,而Cache aside采用的先更新DB后删除缓存的方式出现不一致的几率相对较小,因为回写缓存的速度通常很快,也就是说上面第4步通常会在第2步前完成。
Read through/Write through#
没什么特别的,只是缓存和数据库的操作被集成到Cache Provider中,客户端API可以使用简单的接口。
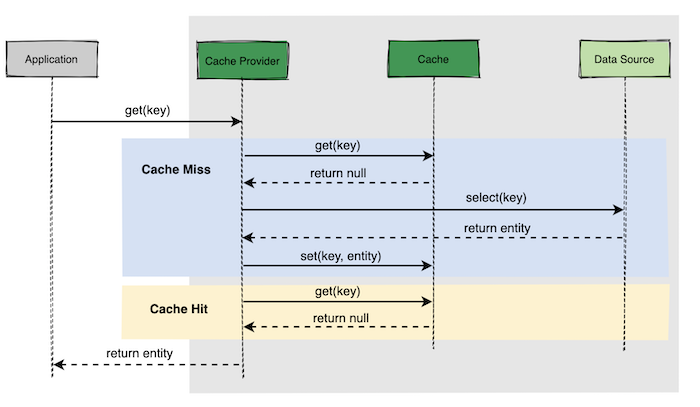
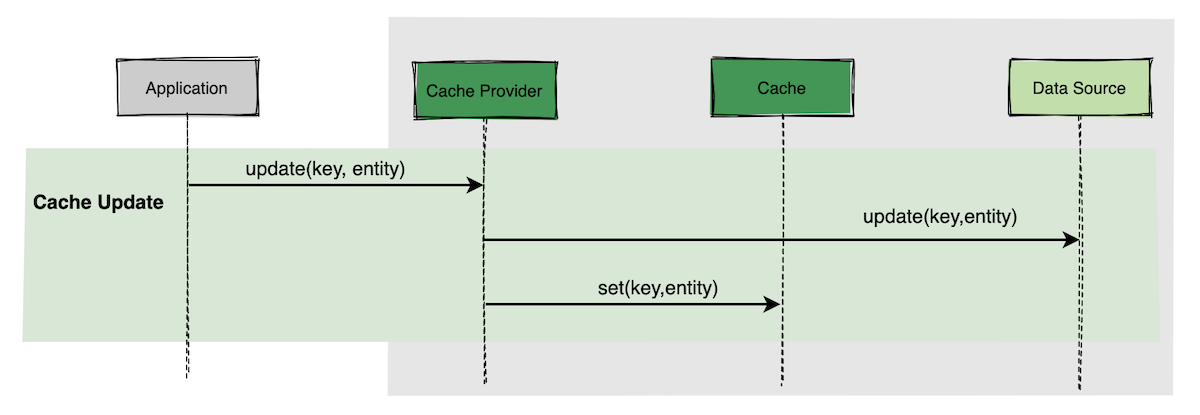
Write behind#
应用程序在更新时只更新缓存,Cache Provider在一定时间内批量将更新的缓存刷到数据库中。也称Write back、延迟写入。
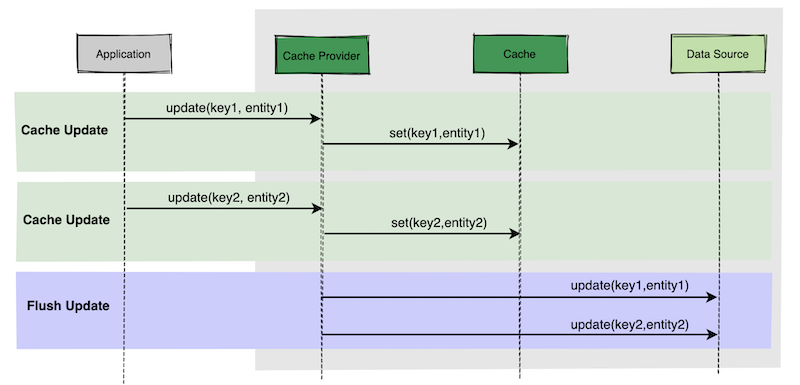
优点:
- 降低客户端复杂性
- 提升客户端写入速度
缺点:
- 缓存宕机会有一段时间的数据丢失
- 缓存和数据库没有保持强一致性
总结#
三种缓存更新策略都会造成缓存数据和数据库数据的不一致,无可避免,但若缓存设置了过期时间,缓存和数据库会达到最终一致。
解决DB和缓存不一致问题#
缓存的不一致问题来源于:
- 多个线程并发修改DB和缓存
- 即使是同个线程,修改DB和缓存的两个操作可能也只成功一个
在实际开发中,可以按对一致性的需求进行解决:
- 如果能承受短时间的不一致,那么只需等待缓存自然过期
- 否则,可以考虑在更新数据库的时候更新缓存或删除缓存,但无论怎么设计数据库和缓存的操作顺序,始终还是会产生不一致问题
- 如果必须要强一致,那么就使用分布式锁,或者使用负载均衡算法保证同一个请求被映射到同一个实例,然后在该实例上使用互斥锁或其它技术,如singleflight这种请求合并技术(保证同时只有一个线程修改DB和缓存)
使用一致性哈希算法进行负载均衡时,要考虑扩容、缩容时会导致key迁移到其它实例上,可能会带来不一致,可以选择禁用这些迁移key的缓存,或者先暂时不开启这些缓存,等一段时间后原始实例上这些key的请求处理完再开启。
参考#
作者:Yudoge
出处:https://www.cnblogs.com/lilpig/p/16725950.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎按协议规定转载,方便的话,发个站内信给我嗷~




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!