RabbitMQ与AMQP协议
帧
帧是AMQP服务器(如RabbitMQ,后面统一用RabbitMQ代指)以及客户端(生产者消费者)进行通信的单元。帧的发送并不是单向的,MQ服务器以及客户端都可以作为帧的发起者。
帧的组成部分:
- 帧类型
- 通道编号
- 帧大小
- 帧有效载荷
- 结束字节标记
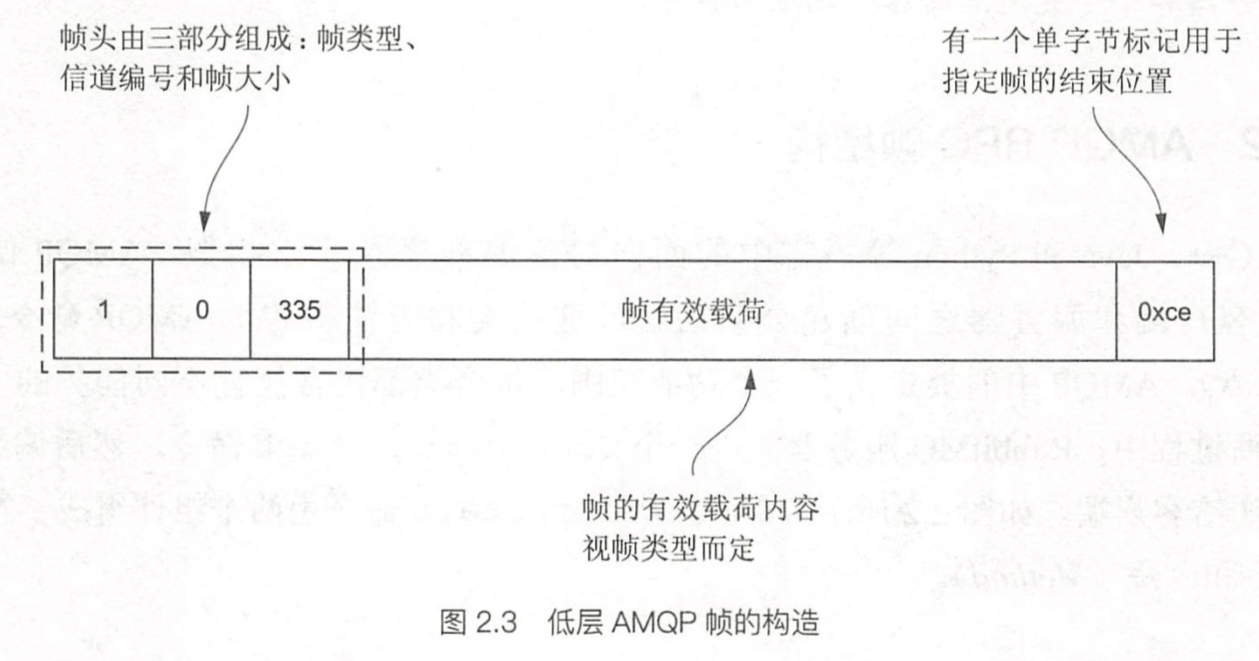
帧类型
- 协议头帧
- 方法帧
- 内容头帧
- 消息体帧
- 心跳帧
协议头帧
在连接RabbitMQ时用到,相当于一个问候语的作用
方法帧
一个完整的请求可能由许多个帧组成,方法帧则定义了该请求要做的事。比如,一个完整的消息发布请求包含方法帧、内容头帧和若干个消息体帧的有序序列。
AMQP的设计有点像面向对象编程中的方法调用,比如,一个在载荷部分包含Basic.Publish的方法帧,它的作用是发布一条消息。Basic就是类,Publish就是方法。
方法帧中除了有请求功能的类方法名描述,如果必要的话还有一些参数信息,比如Basic.Publish的参数中就有消息发布到的交换机名称和路由键值等参数。
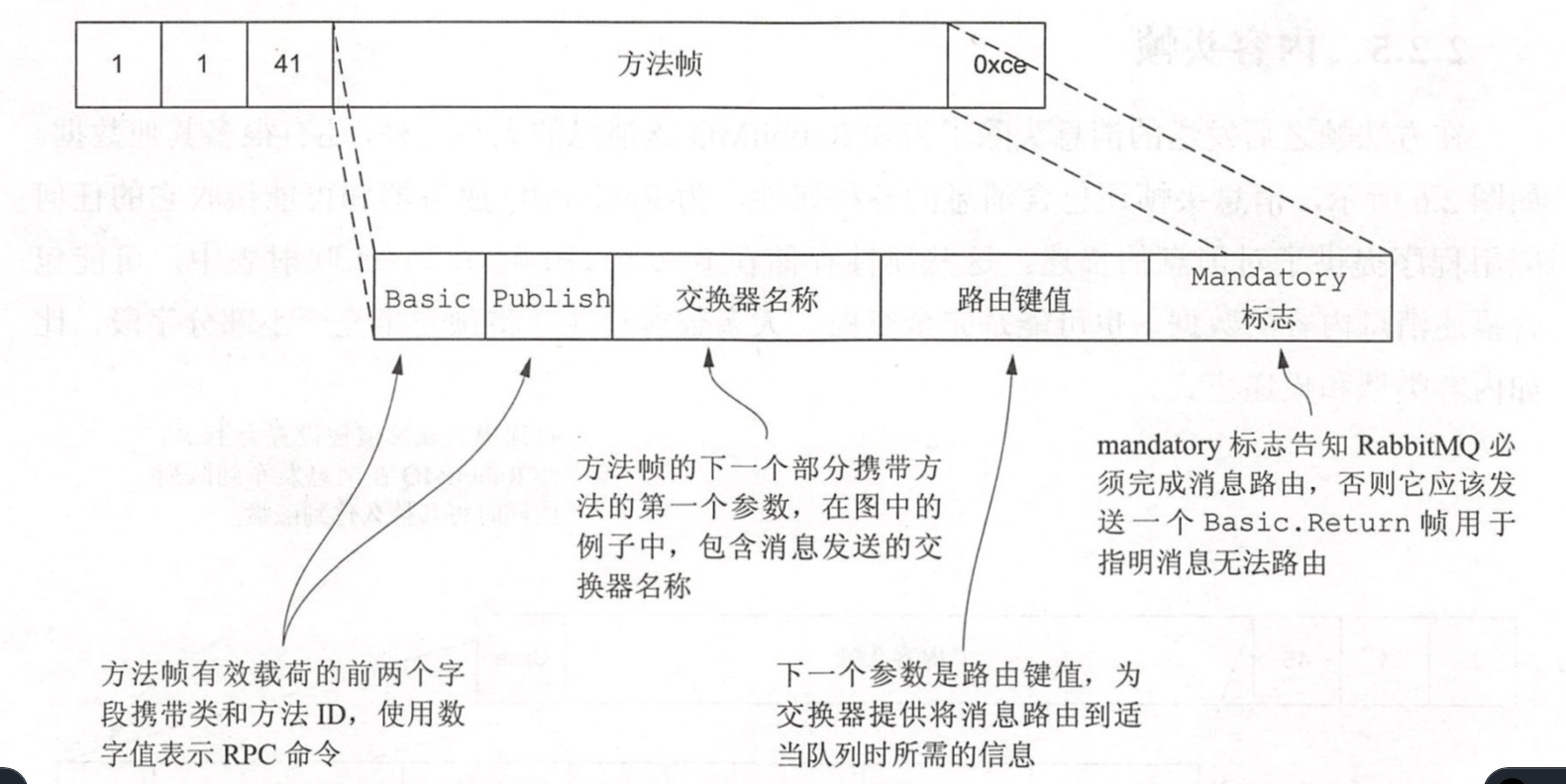
内容头帧
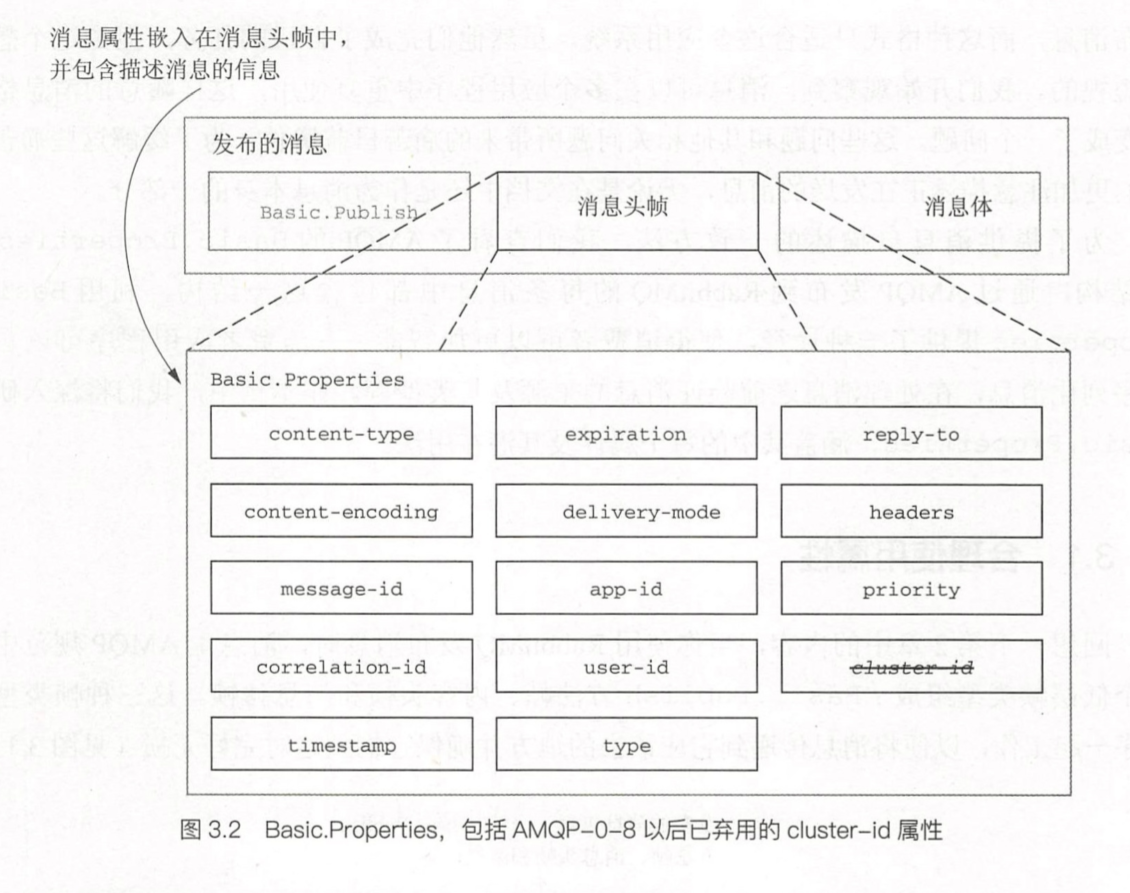
内容头帧描述了消息的一些元信息,比如消息大小、content-type、自定义头字段等。
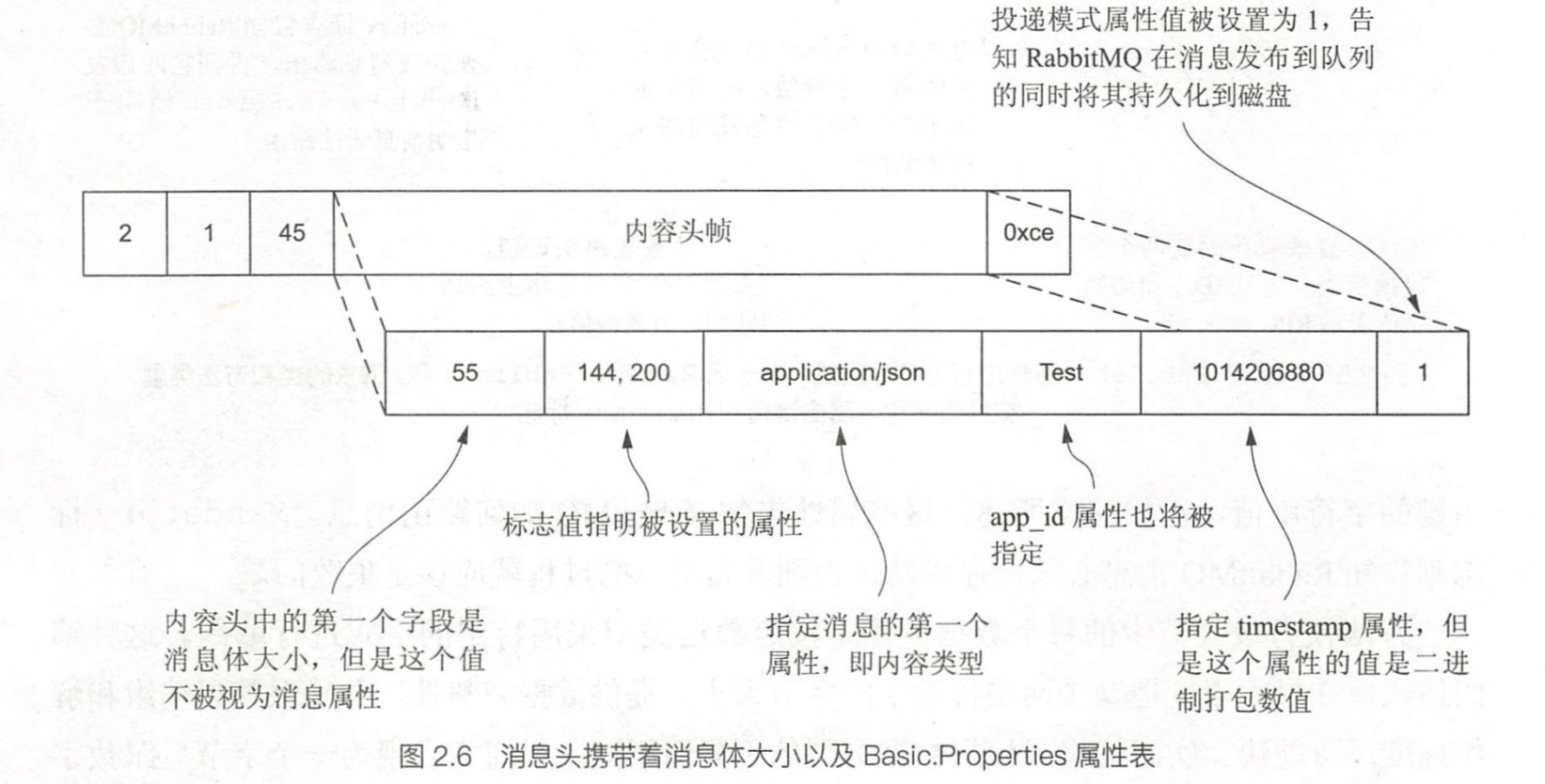
内容头帧中的可以包含的元信息属性在AMQP协议规范的Basic.Properties中被定义。
对于第三个参数,在内容头帧中添加了
Mandatory标志,那么当消息发送不成功时,MQ会向你发送一个Basic.Return命令来通知你。
消息体帧
消息体帧就是具体的消息内容,其内容对AMQP和RabbitMQ是不透明的,它们不对消息做任何处理,即使你声明了content-type。
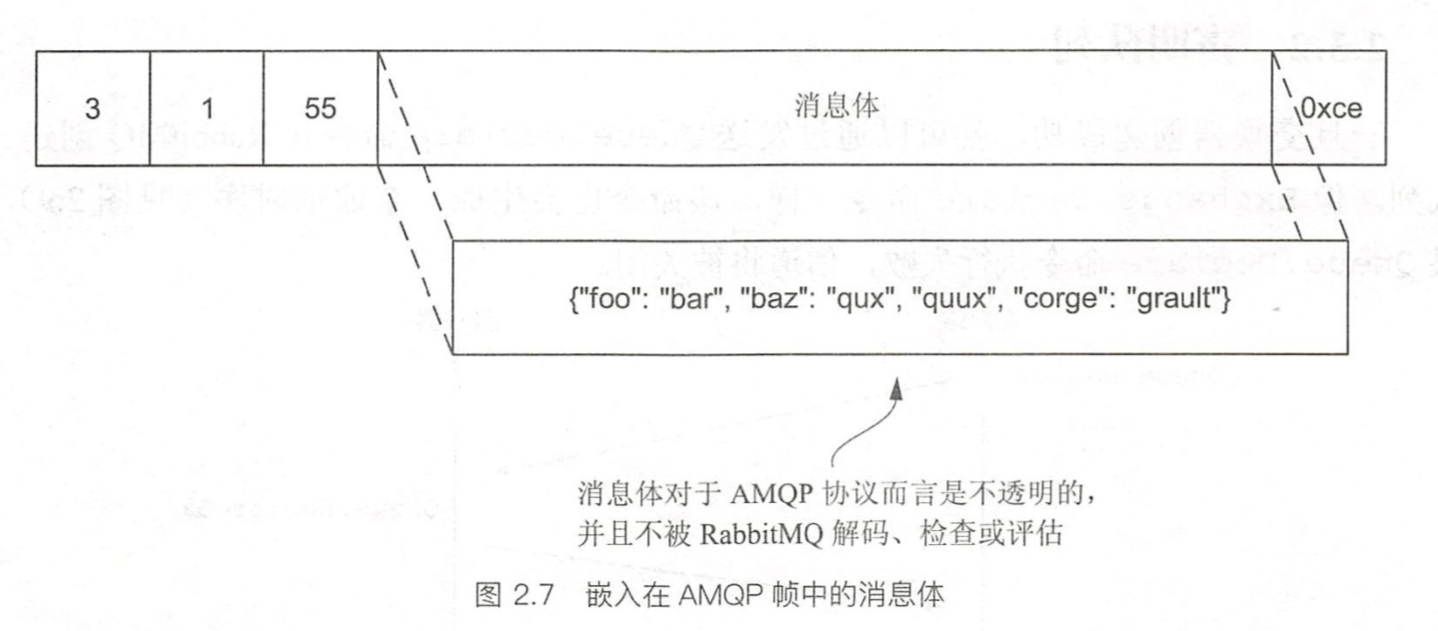
下面的图片足以见得,我们以content-type=application/json的方式发布消息,而消息的内容完全不是json,这也能发出去。可见,content-type只是消息发布者和消费者之间的一种协商,消费者(特别是使用框架的话)可能会根据这个值进行消息的预处理。
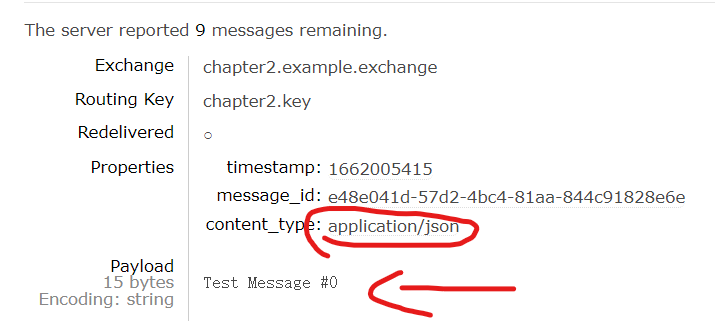
消息体是典型的不定长帧。默认帧大小为131KB,当超过这个上限,消息体可以被分割成多个帧进行发送。
当RabbitMQ接收到
Basic.Publish后,它匹配Exchange和路由键,得到要投放的队列,并将消息的引用放到队列中。这说明无论消息要被发送给多少个队列,消费者是否及时消费这个消息,消息的实例在内存中都只有一个
从MQ中消费消息
Basic.Consume
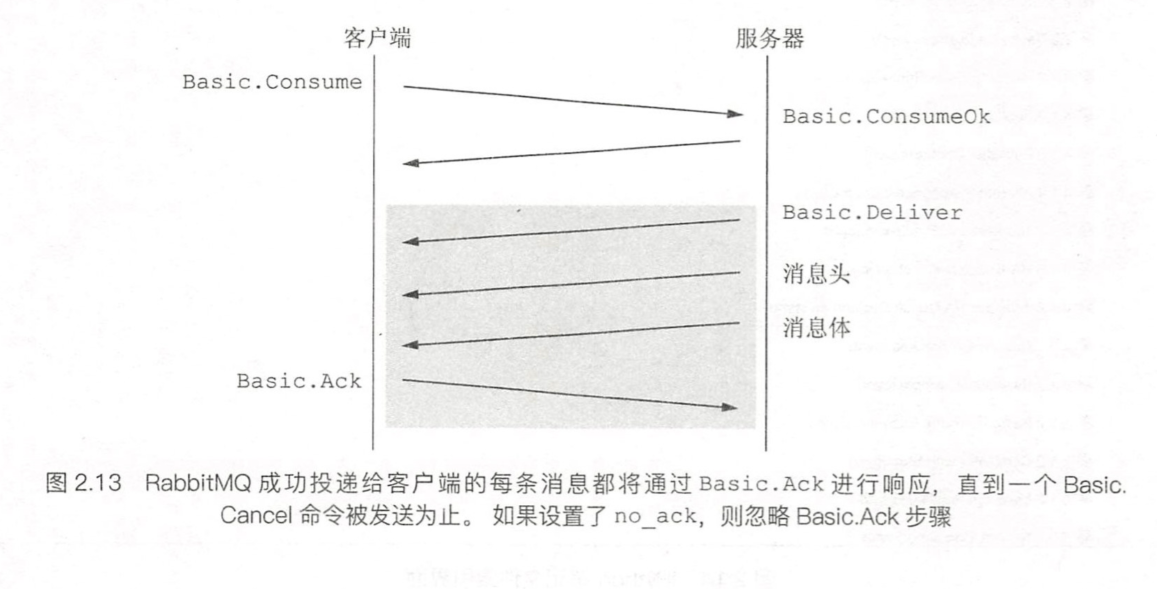
消费者通过Basic.Consume来通知MQ,它要订阅某个队列上的消息了,服务器则通过发起Basic.ConsumeOk来通知消费者,它即将要向你发送消息了。
可以设置
Basic.Consume的no_ack参数。当它为false时,客户端必须通过ACK来确认它收到的每条消息,只有被确认的消息才会被RabbitMQ从缓存中移除,因为客户端代码有可能在处理消息时出错。而当设置no_ack时,当消息发送后,RabbitMQ立刻从缓存中移除消息。
下面看一个例子:
# 提交10条消息
for number in range(0, 10):
message = rabbitpy.Message(chan,
'Test Message #%i' % number,
{'content_type': 'application/json'},
opinionated = True)
message.publish(exchange, 'chapter2.key')

# 正常消费10条,但不提交ack来确认消息
while len(queue) > 0:
msg = queue.get()
print('Message:')
print('\tID: %s' % msg.properties['message_id'])
print('\tTime: %s' % msg.properties['timestamp'])
print('\tBody: %s' % msg.body)
# msg.ack()

现在,有了10条unacked的消息,RabbitMQ不敢轻易扔掉它们,因为这可能代表消费者代码出错,并未正常处理这些消息,稍后可能还会获取。
# 使用no_ack模式获取消息
for msg in queue.consume(no_ack=True):
print(msg.body)
当我们使用no_ack模式时,我们不用去主动进行ACK请求,RabbitMQ不会保留这些消息为unack,但一旦客户端代码出错,消息就会有丢失的风险

Basic.Deliver
服务器使用Basic.Deliver来向消费者递送一个消息,消费者可以通过Basic.Cancel来取消消息的订阅。
Basic.Properties
content-type
说白了就是消息生产者和消费者之间的一个契约,这和MQ屁关系没有,前面也看到了,MQ不校验content-type和消息体帧载荷部分是否匹配。
content-type让消息具有自描述性,可以带来以下好处:
- 消费者可以根据
content-type来判断自己是否支持处理这个消息 - 消费者可以根据
content-type来解析和处理对应消息 - 具有不同序列化方式的消息可以被发送到同一个队列中
- 发送者不必再担心自己使用的序列化方式是否能被正确处理
content-encoding
用于指定content-type之外的消息编码格式,比如是否对原消息进行压缩,使用Base64编码等等,content-encoding的值是一个MIME内容编码,所以UTF-8不符合。有关MIME内容编码的知识可以看这篇文章
message-id和correlation-id
在AMQP规范中,它们是没有具体行为定义的两个属性,实现者可以用它们做任何事。
应用场景:
message-id:它可以用来记录消息的唯一标识,比如订单消息可能需要携带一个订单id,就可以在请求头中存储message-id来代表订单idcorrelation-id:常用来指定一个消息是另一个消息的响应。我不知道我的理解对不对,但在使用spring-amqp操作RabbitMQ时,会用它来实现publish-confirm的功能(即监测一个消息是否成功到达路由器,若没到,服务器会给你发一个nack的确认请求),监听器的监听方法中会有一个带有correlation-id的correlation-data参数,可以用来定位是哪个消息发生了问题)
timestamp属性
一个自定义行为的属性,没太搞懂实际用途
expiration属性
AMQP规范中,它的行为也是自定义的,它是一个最多255个字符的短字符串。
该属性用来指定消息的过期时间,RabbitMQ使用一个Unix时间戳字符串来实现它。
delivery-mode
一个整数,1代表非持久化消息,2代表持久化消息。对于持久化消息,MQ实现在接收到它时会先将它存储到磁盘上。
这和队列的持久性不同,如果你想持久化一个消息,你必须在消息头中单独设置
delivery-mode字段为2
app-id和user-id
app-id用于标记消息生产者,有如下应用场景
- 消费者可以过滤掉来源不明的消息
- 可以追踪恶意或问题消息的来源
- 收集统计数据
user-id用来标识MQ系统中的登录用户
type属性
又是一个没有规定行为的属性,有如下应用场景:
假设你使用一些不具有自描述性的消息序列化方式,比如Google
Protobuf,在这种序列化方式中,序列化和反序列化的方式都依赖一个proto文件来描述,如果没有这个文件,你是无法反序列化一条消息的。这类序列化工具通常能序列化出更小的数据,这意味着更好的性能,因为它们无需自描述。对于这种数据,type可以用来指定用于反序列化的proto文件名。
priority
用于指定消息的优先级,0~9之间的整数,越小优先级越高。
自定义头
除了AMQP规范中规定的头之外,你还可以自定义头,比如在RabbitMQ中使用DelayedExchange插件时,使用x-delay什么的头参数来指定消息的延迟时间。
未完...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号