Redis主从集群——分片集群
主从集群的问题
- 需要额外Sentinel节点
- 写操作过多导致的主节点压力过大的问题还是没法解决
- 内存的空间较小,无法应对海量数据存储的问题
分片集群
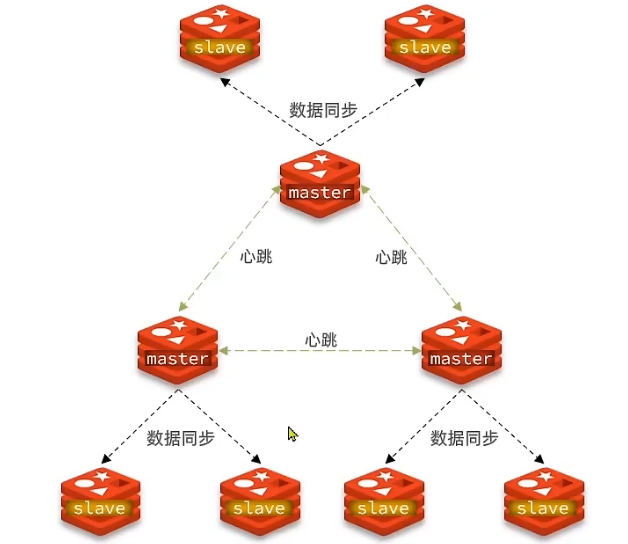
可以把分片集群堪称多个主从集群连接在一起了,但它有如下好处
- 海量数据可以被分片,并存储在其内部的每个主从集群中
- master之间通过心跳检测检测彼此存活,无需额外哨兵
- 客户端可以访问集群中任意节点,请求会被自动路由到正确的节点
docker compose搭建分片集群
下面使用docker compose搭建一个3主3从的分片集群,docker compose文件虽然很长,但很简单,六个节点的配置几乎完全相同,所以只需要看一个即可。
services:
master1:
image: redis
# 暴露redis端口和集群总线端口
ports:
- 6001:6379
- 16001:16379
# 配置卷,将配置文件和数据目录挂载到容器
volumes:
- ./conf/master1.conf:/usr/local/etc/redis/redis.conf
- ./master1/:/data/
# 使用自己的配置文件运行
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
master2:
image: redis
ports:
- 6002:6379
- 16002:16379
volumes:
- ./conf/master2.conf:/usr/local/etc/redis/redis.conf
- ./master2/:/data/
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
master3:
image: redis
ports:
- 6003:6379
- 16003:16379
volumes:
- ./conf/master3.conf:/usr/local/etc/redis/redis.conf
- ./master3/:/data/
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
slave1:
image: redis
ports:
- 8001:6379
- 18001:16379
volumes:
- ./conf/slave1.conf:/usr/local/etc/redis/redis.conf
- ./slave1/:/data/
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
slave2:
image: redis
ports:
- 8002:6379
- 18002:16379
volumes:
- ./conf/slave2.conf:/usr/local/etc/redis/redis.conf
- ./slave2/:/data/
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
slave3:
image: redis
ports:
- 8003:6379
- 18003:16379
volumes:
- ./conf/slave3.conf:/usr/local/etc/redis/redis.conf
- ./slave3/:/data/
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf"
上面的配置文件配置了6个节点,其中,主节点的端口为6001、6002、6003,根据redis的惯例,集群总线端口=端口+10000,所以,它们的总线端口为16001、16002、16003。集群通过这个端口进行通信,所以将它们暴露出来是必须的。
然后,为每个容器编写配置文件,其配置文件也都大同小异:
# conf/master1.conf
# 开启集群
cluster-enabled yes
cluster-config-file /tmp/nodes.conf
cluster-node-timeout 5000
bind 0.0.0.0
# 集群主机声明ip、端口、总线端口,这里需要填写真实的宿主机ip和端口,因为redis会根据这个建立集群
cluster-announce-ip 172.21.12.64
cluster-announce-port 6001
cluster-announce-bus-port 16001
protected-mode no
databases 1
其它的容器的配置文件也差不多,只有cluster-announce-port和bus-port不一样,不贴出来了。
最后,启动六个容器,使用redis-cli建立集群:
# 创建集群,指定集群中每个主节点托1个从节点
# 那么主节点和从节点数量就是1:1
# 前3个主节点,后3个从节点
redis-cli --cluster create --cluster-replicas 1 172.21.12.64:6001 172.21.12.64:6002 172.21.12.64:6003 172.21.12.64:8001 172.21.12.64:8002 172.21.12.64:8003
集群创建成功:
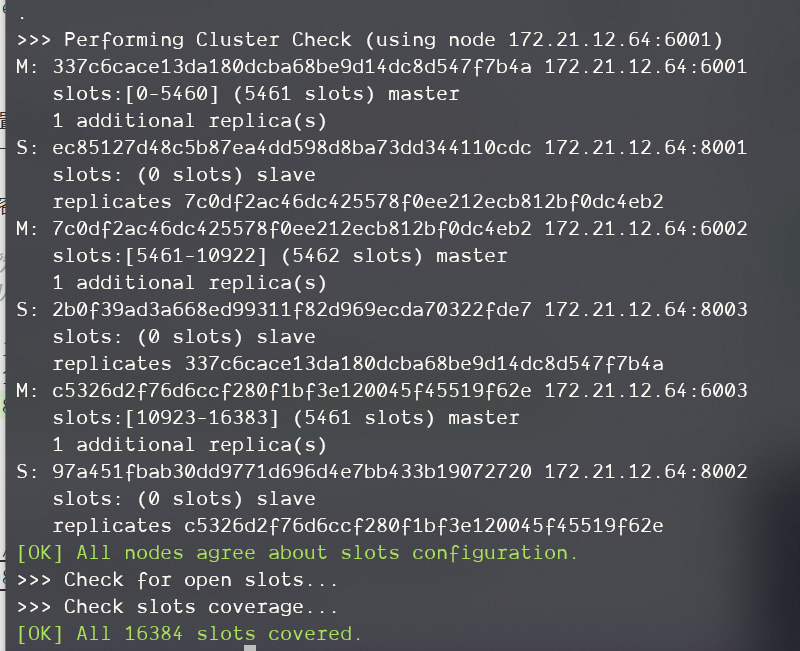
查看集群状态:
redis-cli -p 6001 cluster nodes

散列插槽
前面提到Redis会在你访问任意节点时将请求路由到正确的节点,这个路由时怎么实现的?
Redis中有16384个插槽,每个key会通过hash运算映射到一个插槽上,运算规则如下:
- 如果是数字就根据数字计算
- 如果是字符串,如果其中包含
{字符串},就使用{}内的字符串进行hash计算 - 否则根据全部字符串计算
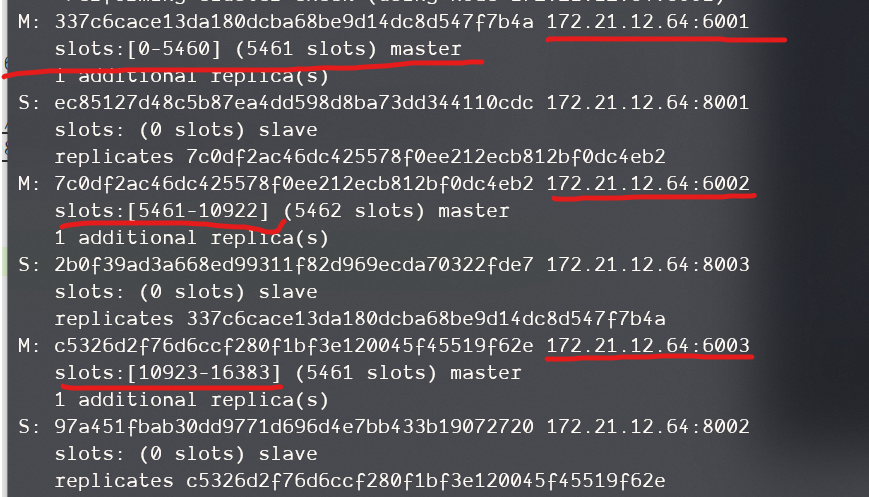
由下图可见,分片集群中每一个保存数据的主节点都绑定到一部分插槽上,这样,当你set或get一个数据时,根据key确定插槽,然后就能找到数据存在哪个机器上
从下图中可以发现,当我们设置num时,和平常并无二异,而当我们设置a时,a被映射到15495这个插槽上,而当前6003这个节点绑定在这个插槽上,所以数据在它身上,我们的请求被重定向到了这个机器
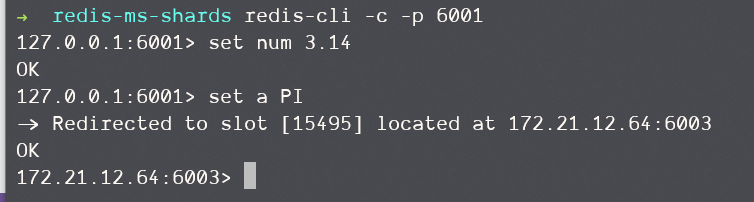
而当我们在6003上获取num时,我们会被重定向回去:

集群伸缩
分片集群给了redis在内存中存储海量数据的能力,同时也带来了一个新的重要需求,就是集群的动态伸缩。当系统数据突然激增时,我们需要快速的增加一些机器到集群中。
添加节点
向集群中添加一个节点可以使用redis-cli --cluster的add-node选项,下面是usage:
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
即需要一个新增节点的主机和端口以及待添加到的集群中的任意一个机器的ip和端口以便联系到这个集群。同时,如果希望新增节点作为slave存在的话,可以使用--cluster-slave和--cluster-master-id两个选项来配置。
将6379这台机器添加到集群中:
redis-cli --cluster add-node 172.21.12.64:6379 172.21.12.64:6001
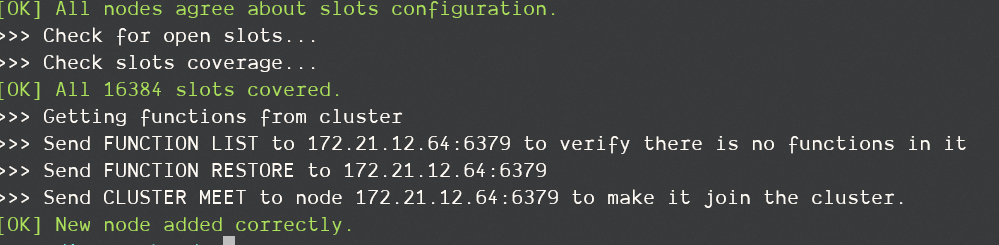
查看集群状态:
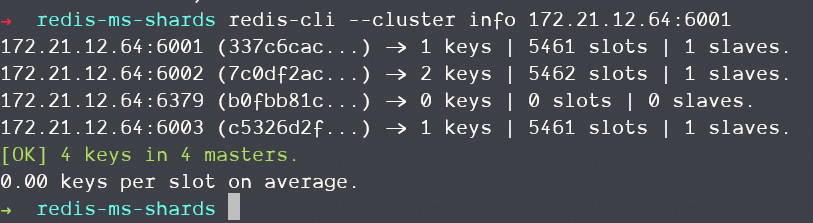
可以看到,6379中没有任何插槽,也就是说我们没法存数据进去。
重新分片(重分配插槽)
redis-cli的reshard子命令可以对集群进行重新分片
reshard host:port
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
将插槽0-3000的数据移动到新节点上,这里的cluster-from和cluster-to需要给的参数是节点ID,可以通过 redis-cli -p 6001 cluster nodes获得
redis-cli --cluster reshard 172.21.12.64:6379\
--cluster-from 337c6cace13da180dcba68be9d14dc8d547f7b4a\
--cluster-to b0fbb81c199cb3d82adae0ecb6f1325734a9fe2b\
--cluster-slots 3000\
--cluster-yes
执行命令后,移动数据开始:
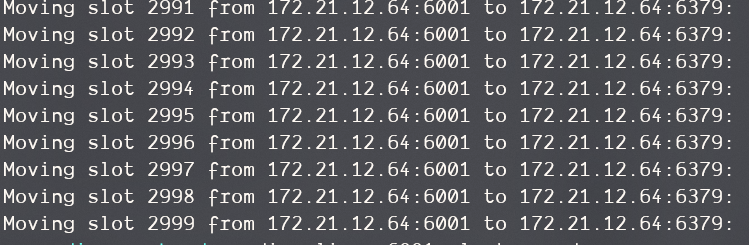
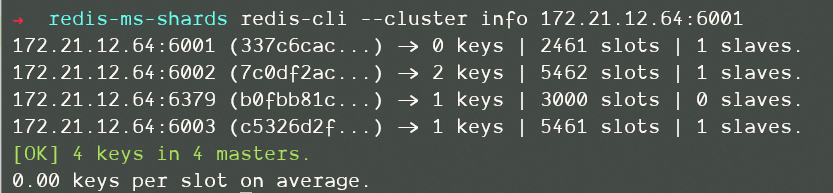
故障转移
Redis分片集群中的所有主节点会通过心跳检测完成自动的故障检测,转移,下面主要说下手动转移。
有时集群中可能会使用一些新的性能更好的节点替换一些旧的节点,此时我们就需要做手动的故障转移,将旧的节点拿走并将新的节点替换上去。
你需要让待替换节点作为被替换节点的子节点,然后执行CLUSTER FAILOVER指令。
现在8001是6002的slave,我们进到8001中执行CLUSTER FAILOVER
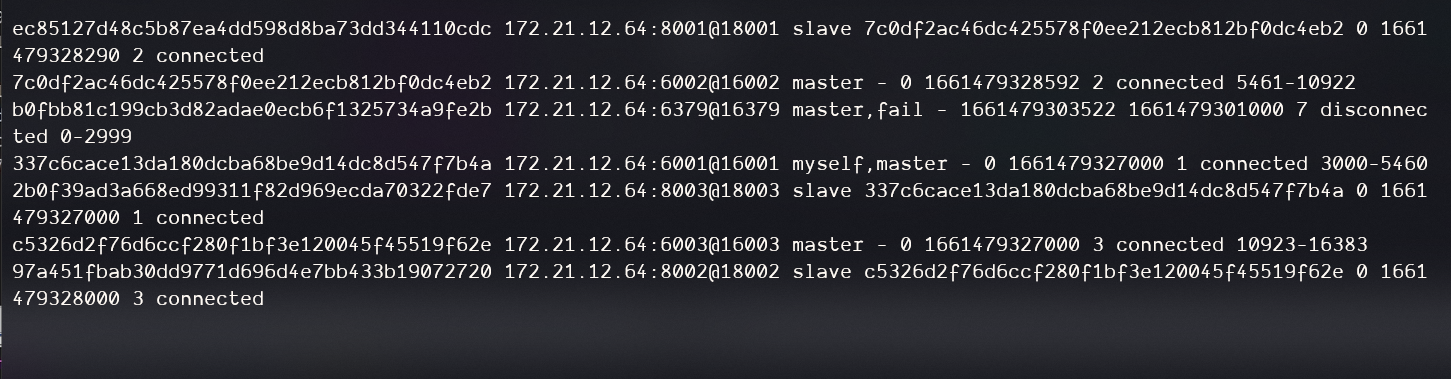
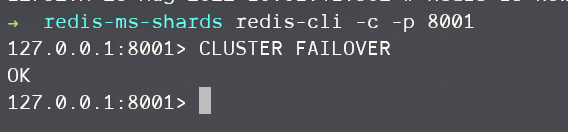
现在,8001变成master,6002变成slave

下面是故障转移步骤:
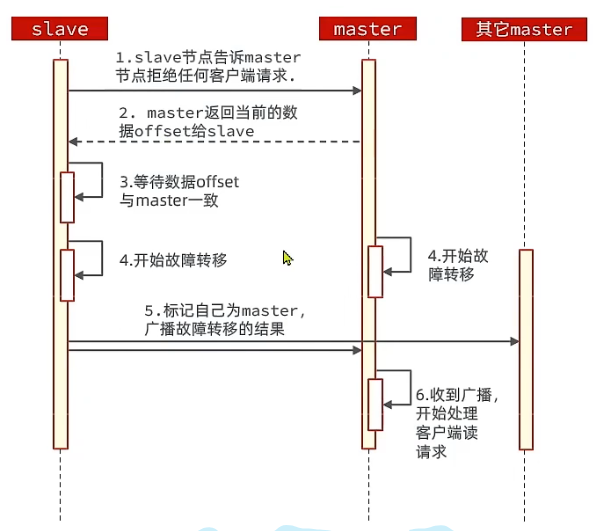
从流程中可以看到,故障转移的过程需要保证要迁移的master和待迁移的slave的数据同步,并且为了保证在这期间没有用户更改数据,还要告诉master拒绝任何客户端请求。
当然这只是默认情况下的流程,CLUSTER FAILOVER还有两个参数:
FORCE:不等待offset一致TAKEOVER:直接执行第5步,忽略master和其它master的意见
RedisTemplate访问分片集群
spring:
redis:
cluster:
nodes:
- 172.21.12.64:6001
- 172.21.12.64:6002
- 172.21.12.64:6003
- 172.21.12.64:8001
- 172.21.12.64:8002
- 172.21.12.64:8003
应该还要配一个从节点优先的读取策略
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {
return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号