MySQL总结
架构
- 连接池:维护与客户端的连接的池子,达到线程重用
- SQL层:包括解析器、优化器、缓存
- 存储引擎:MySQL的存储引擎掌管着表、索引等如何被实际存储,它们是插件式的
- 文件系统:保存MySQL服务器和存储引擎产生的文件
MyISAM和InnoDB
InnoDB
- 支持ACID,行级锁,适合OLTP应用
- 使用MVCC多版本控制机制,使用更多空间保存数据的多个副本,降低事务回滚率
- 提供4种隔离级别
- 提供许多特色的优化,比如AIO、两次写,插入缓冲、自适应哈希索引
MyISAM
- 不支持事务,表锁,适合OLAP应用
InnoDB线程
- Master Thread:将缓冲池中的数据异步刷回磁盘
- IO Thread:用于处理InnoDB中的AIO请求
- Purge Thread:对于已提交数据,它的undolog就没用了,该线程用于清理这些数据
- Page Cleaner Thread:新版本中的线程,将脏页刷新从主线程中独立出来
InnoDB内存布局
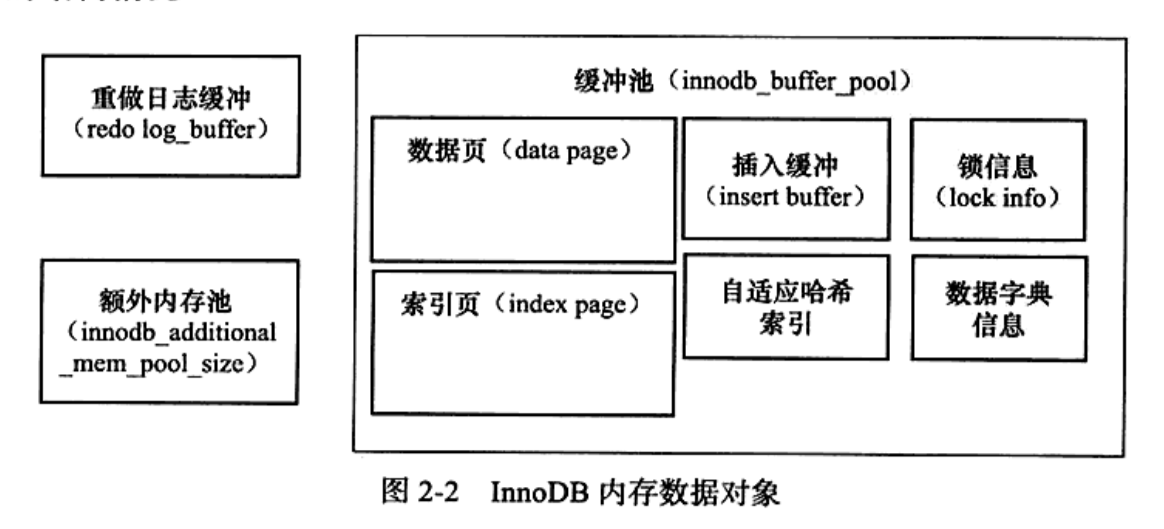
缓冲池
如图所示,缓冲池中不仅仅缓存表数据,还有锁信息、插入缓冲等...
# 查看缓冲池大小
SHOW VARIABLES LIKE 'innodb_buffer_pool_size'\G;
# 查看缓冲池实例个数
SHOW VARIABLES LIKE 'innodb_buffer_pool_instances'\G;
# 查看缓冲池状态
SELECT pool_id, pool_size, free_buffers, database_pages FROM information_schema.INNODB_BUFFER_POOL_STATS\G;
特有的LRU缓冲算法
InnoDB中的LRU算法不将新数据放到队首,而是放到midpoint(中间点,也是new和old数据的分界点),因为在全表扫描的情况下会产生大量的新数据,这会让new数据被挤到old区而被移出队列。
# 查看midpoint位置
SHOW VARIABLES LIKE 'innodb_old_blocks_pct'\G;
# 查看被加入到midpoint的数据多长时间后没被刷出,将它放到new端
SHOW VARIABLES LIKE 'innodb_old_blocks_time'\G;
CheckPoint——InnoDB
InnoDB重启时需要从redolog中恢复一些上次运行时已经发生但尚未被同步到磁盘中的操作,CheckPoint是redolog中已经被同步到磁盘的操作和需要进一步同步的操作的分界线。
CheckPoint产生时机(产生CheckPoint代表有一些数据要刷进磁盘了):
- LRU列表中需要弹出旧页面,其中可能存在需要刷回磁盘的脏页,此时强制产生检查点
- redolog的空间限制导致它无法容纳新日志时,强制产生检查点
- 主线程异步以某种间隔产生检查点
- ...
InnoDB部分特性介绍
InsertBuffer
对于插入顺序无序的索引来说,插入就意味着对索引文件的随机磁盘访问,Insert Buffer的目的是将这些插入先保存到缓存区中,稍后将它们按主键排序并执行,如果情况乐观的话,这样可以将一些随机磁盘访问优化成顺序磁盘访问。
前提:
- 索引是辅助索引
- 索引不是唯一的
因为唯一索引和非辅助索引都可能由于约束而插入失败,而且这个成功失败是插入后才知道的
InnoDB高版本中还提供了:Delete/Update/Insert Buffer
两次写
如果在刷新磁盘页时直接存到表文件中,在这过程中发生宕机,表文件会被损坏。
两次写技术是先将脏页复制到内存中的double write buffer,然后先将数据写到磁盘上的公共表空间,这次写入完成后再进行实际的磁盘页刷新,相当于先将完整的待写入数据备份一份,这样如果是在备份的过程中崩溃,原表文件没被损害,重做日志还可以对它重做,如果是在实际脏数据入表的过程中崩溃,共享空间中的备份可以帮助恢复。
MySQL分区表
根据一些规则将一个表分到多个物理文件中,降低对单文件查询的压力,并且可以在查询时直接将范围缩小到一个分区内。
对OLTP应用来说,分区带来的优化有限
分区类型:
RANGE分区:按照某个列值的连续区域划分LIST分区:Range的离散版本,对于每个区域给定一个列值的列表,对应列值在列表中的进入该分区HASH分区:根据用户自定义的表达式分区KEY分区:根据MySQL提供的HASH函数来分区
InnoDB对索引进行的优化
MRR 多范围查询合并

上面的语句即使在orderid上有索引,在MySQL的早期版本中也可能不走索引,因为:
- 无法用到覆盖索引,预示着对于每条符合要求的索引项都要回主表查一下
- 从辅助索引到主表的频繁跳入跳出会大大增加随机磁盘访问
MRR优化所做的是:
- 将读取到的辅助索引项缓存
- 按照主键ID排序
- 根据这个顺序访问主表
假设有(key_part1, key_part2)这个索引,早期MySQL可能也不会用到key_part2,MRR优化将它变成(1000, 10000)、(1001, 10000)...(1999, 10000)的查询,并将结果合并。

ICP 索引条件下放
对于索引明明能够覆盖查询条件,但在早期版本中由于无法用到最左前缀原则而放弃使用部分索引列转而去原表中fetch行后服务器层再用WHERE匹配条件(由于MYSQL的脑瘫)的情况,ICP可以将索引条件下放到存储引擎层,让这个过滤从存储引擎层得到解决,不用对无用数据fetch原表。
MySQL早期执行逻辑:
- 从索引中过滤那些可以直接应用最左前缀原则的列
- 对于每一条数据都去fetch原表,取出完整行(大量随机磁盘访问以及无用数据交换)
- 在服务器层应用WHERE条件,即使索引中已经有足够的过滤掉这些行的信息
ICP的执行逻辑
- 从索引中过滤那些可以直接应用最左前缀原则的列
- 对于每一条数据,直接在索引中过滤
- 如果满足条件才fetch原表
InnoDB中的锁
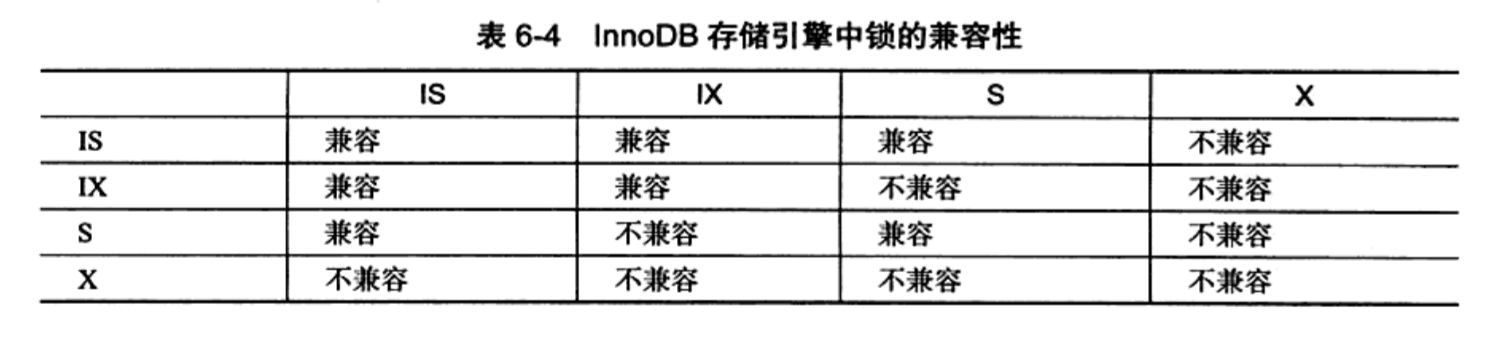
共享排它、意向锁
和大部分支持多粒度锁的数据库一样,MySQL提供了共享锁/排它锁和意向锁。如果一个事务在一个实例上添加了意向锁,代表它有意向在比该实例粒度更细的实例上上锁,比如表和行。

MVCC多版本控制机制
MVCC多版本控制机制又叫“一致性非锁定读”,它通过记录事务操作过程中一个数据的多个版本来避免加锁,在无阻塞的情况下保证了数据的一致性,且能降低事务回滚的次数。
- InnoDB在undo段上保存多版本控制机制的快照
- 不需要对快照数据进行上锁,因为它们已经被提交
- 在Repeatable Read下,事务T总是读取T开始时的快照版本
- 在Read Committed下,事务T总是读取最新快照版本
三种锁
- Record Lock:锁定单个记录
- Gap Lock:锁定一个范围而不是具体记录
- Next-Key Lock:锁定范围并锁定记录,1+2
范围锁解决的问题是在返回结果集有多条数据时可能发生的幻读情况,由于Record Lock只能锁定单条记录,所以可能出现幻影行。
当索引是非唯一索引:
- 等值查询:包含查询指定值的范围会被加上Next Key Lock,下一个范围会被加上Gap Lock。比如上面一个事务对10加锁,那么(−∞,10]会被加上Next Key Lock,(10,11]会被加上Gap Lock。
- 范围查询:where中指定的范围被加上Next Key Lock
当索引是一个唯一索引:
- 等值查询:Next-Key Lock会被降级成Record Lock,因为这时无法插入相同索引值的记录,所以无幻读现象,无需范围索引。
- 范围查询:where中指定的范围被加上Next Key Lock

 浙公网安备 33010602011771号
浙公网安备 33010602011771号